お読みいただきありがとうございます!
本記事は[その4]となります。
以下4記事がまとめて3分で読める!
[3分で読める] 食べログとSNSの評価を比較してみた~ショート編~
簡単なあらすじ(リンク付き!)
-
(その1)ツイートの取得(SNSの調査)/カフェの選定
TwitterAPIを活用し、東京23区内の人気カフェ/スイーツ店のツイートを取得
取得した店舗のうち、総ツイート数が200件を超えている店舗10店舗を選定。 -
(その2)ツイートの前処理
ツイートには取得したい感想(評価)の他に、公式アカウントや引用ツイート、
お土産ランキングなど不要なツイートを削除。 -
(その3)感情分析にてツイートを得点化
「日本語評価極性辞書」と「単語感情極性値対応表」2つの辞書を活用し、得点の比較。
食べログの評価幅が[0~5]のため、正規化にて幅を[0~5]合わせる。 -
(その4)食べログ評価を取得/比較(本記事)
食べログの評価を取得し、評価の分布をグラフ化。
先ほど取得したツイートの点数との比較を行う。
5.食べログ評価の取得(2021年09月29日)
__コード一覧はこちら__
!pip install requests
!pip install beautifulsoup4
from bs4 import BeautifulSoup
import requests
import pandas as pd
import time
import matplotlib.pyplot as plt
import numpy as np
import traceback
data = []
base_url = 'https://tabelog.com/tokyo/A1306/A130602/13014316/dtlrvwlst/COND-0/smp1/?smp=1&lc=0&rvw_part=all&PG='
numb = 1
try:
while numb <= 50:
url=base_url+ str(numb)
res = requests.get(url)
# 文字化けしていない文字を抽出
res.encoding = res.apparent_encoding
soup = BeautifulSoup(res.text, "html.parser")
# 口コミ
time.sleep(1)
view = soup.find_all("div",class_ = "js-rvw-item-clickable-area")
for item in view:
rate_list = [(rate.text) for rate in item.find_all('b', class_='c-rating-v2__val')]
name_id = item.find("span",class_ = "lev").text
fre = item.find("span",class_ = "u-text-num").text
tmp = [[name_id,rate,fre]for rate in rate_list]
data += tmp
numb += 1
column =["id(sum)",'rate','frequency']
df = pd.DataFrame(data,columns = column)
#評価「-」の行を消去
norate = df[df['rate'] == "-"].index.tolist()
df = df.drop(norate)
df.index += 1
df["count"] = df.groupby(by = ['rate',"frequency"]).transform('count')
print(df.shape)
except:
print('error')
traceback.print_exc()
else:
print('no_error')
finally:
print('finish')
食べログをスクレイピング

[その1]で選定したお店の評価をスクレイピングします。
取得情報
column =["id(sum)",'rate','frequency']
食べログから取得するのは
- id
- rate(評価)
- frequency(来店回数)
口コミ数
base_url = 'https://tabelog.com/tokyo/A1306/A130602/13014316/dtlrvwlst/COND-0/smp1/?smp=1&lc=0&rvw_part=all&PG='
numb = 1
try:
while numb <= 50:
url=base_url+ str(numb)
res = requests.get(url)
食べログの口コミ1ページには20人分の評価が記載されています。
今回取得する口コミの最大数が1000件未満だったため、
50ページ分の情報を取得できるように設定しました。
評価なし
# 評価「-」の行を消去
norate = df[df['rate'] == "-"].index.tolist()
df = df.drop(norate)
口コミの中には、文章のみ記載し、評価をしていない方もいます。
rateにstr型の"-"が含まれている場合、エラーが発生してしまうので事前に処理しておきます。
結果をプロット
~2種類のグラフを作成~
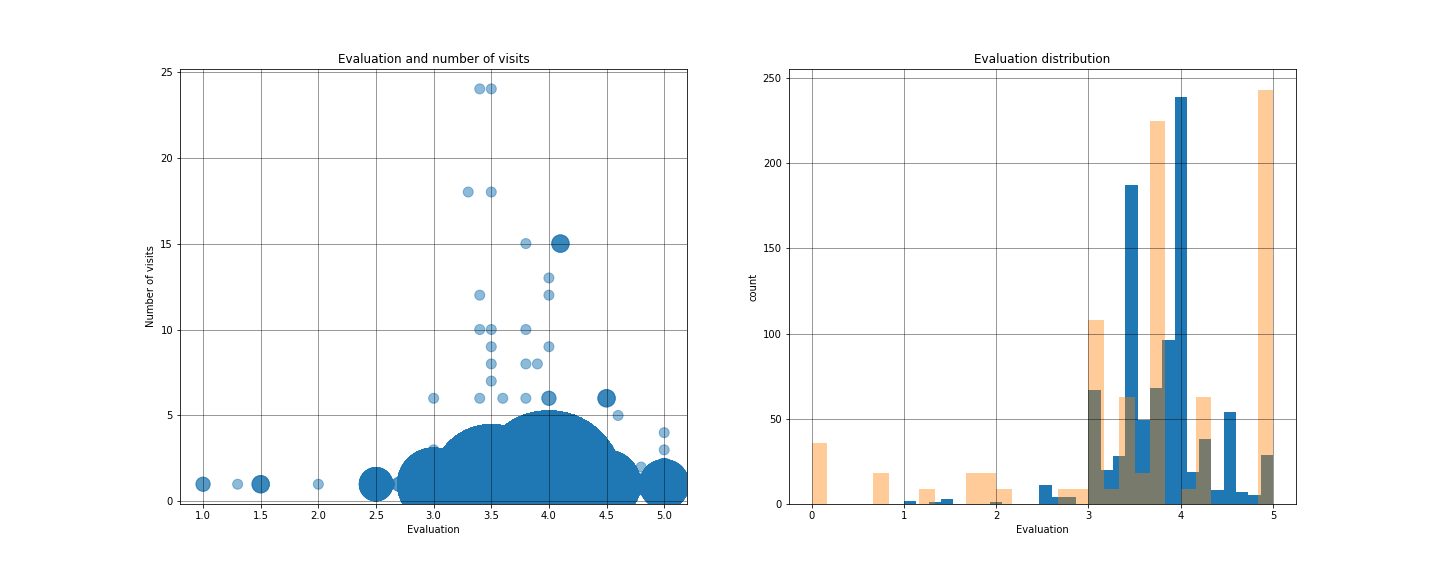
Evaluation and number of visits
__(グラフ左)__が「訪問回数と評価」を可視化。
x軸にrate(評価)
y軸にfrequency(訪問回数)
丸が大きいほど同じ評価が多いことを表し、来店回数における評価の変化を可視化。
x軸が上昇するほど、再来店(リピーター)の評価となる。
Evaluation distribution
__(グラフ右)__が「評価の分布」を可視化
x軸にrate(評価)
y軸にcount(同じ評価を付けた人の数)
棒グラフにより、どのあたりの評価が多いのかを可視化。
それぞれ、棒グラフの数(ビン数)を30に設定。
「青棒」 = 食べログでの評価
「オレンジ棒」= Twitterでの評価
10店舗の一覧は以下
「「表示方法」」
「食べログ」= 食べログ評価 / 件数
「Twitter」= Twitter評価 / 処理後の件数 (行った倍数)
※()内はツイートを複製し棒グラフを伸ばした回数 = 数を合わせるため
ケンズカフェ
「食べログ」= 3.92 / 735件
「Twitter」= 3.41 / 606件 (2)

ピエールエルメ
「食べログ」= 3.89 / 841件
「Twitter」= 3.60 / 1005件 (3)

資生堂パーラー銀座
「食べログ」= 3.81 / 432件
「Twitter」= 3.60 / 420件 (3)

ひみつ堂
「食べログ」= 3.76 / 940件
「Twitter」= 3.65 / 864件 (9)
和栗や
「食べログ」= 3.73 / 522件
「Twitter」= 3.61 / 477件 (3)

銀座メゾンアンリ・シャルパンティエ
「食べログ」= 3.71 / 579件
「Twitter」= 3.90 / 618件 (6)

銀座ウエスト銀座店
「食べログ」= 3.68 / 480件
「Twitter」= 3.73 / 420件 (3)

キルフェボン.銀座
「食べログ」= 3.66 / 607件
「Twitter」= 3.60 / 781件

マリアージュフレール銀座
「食べログ」= 3.62 / 405件
「Twitter」= 3.71 / 470件 (2)

ブルーボトルコーヒー清澄白河
「食べログ」= 3.32 / 429件
「Twitter」= 3.78 / 528件 (2)

考察
左)散布図(食べログ)に関して
- 来店回数が増えれば増えるほど、5ではなく4または4.5の評価が集まる(常連は5をつけない)
- 初来店(1回目)の評価は3 ~ 4.5の間が多い
- 0点の評価はなし
- 両端(1と5)では1 < 5の評価が多く見られる
右)ヒストグラムに関して
- 食べログは4周辺の評価が多いが、Twitterでは0または5の両極端も目立つ
- Twitterでは喜びや期待または、怒りのどちらかでしか感想をツイートしないと予測
- 結果として似た総合評価を得ているが、分布は全く異なる
6.比較
以下に食べログの評価とTwitterの分析を比較してみました。
| 店名 | 食べログ | ツイート | 食べログ - ツイート |
|---|---|---|---|
| キル フェ ボン | 3.66 | 3.60 | 0.06 |
| ピエール・エルメ | 3.89 | 3.60 | 0.29 |
| ブルーボトルコーヒー | 3.32 | 3.78 | -0.46 |
| ケンズカフェ東京 | 3.92 | 3.41 | 0.51 |
| マリアージュフレール | 3.62 | 3.71 | -0.09 |
| ひみつ堂 | 3.76 | 3.65 | 0.11 |
| 資生堂パーラー | 3.81 | 3.60 | 0.21 |
| 和栗や | 3.73 | 3.61 | 0.12 |
| アンリ・シャルパンティエ | 3.71 | 3.90 | -0.19 |
| 銀座ウエスト | 3.68 | 3.73 | -0.05 |
- 食べログ平均点 = 3.71
- ツイート平均点 = 3.66
- どちらにもそれほど大きな差はなく、面白い結果となった
- 分布が全く異なるのにも関わらず、総合評価はあまり変わらないのは面白い結果となった
終わりに
今回の結果より、SNSの情報は良い意見、厳しい意見ともに多かった。
SNSは自分の意見をつぶやくため、指定(店の人)が見てない想定で本音を記入するからだろうか?
ともかく、最終評価はあまり変わらなかったが、それぞれの評価の分布が可視化でき、
SNSの一面を可視化することができたのではないかと思いました。
そのため、利用方法としては、食べログで自分が行きたいお店を探し、
来店して後悔がないよう、SNSで本音を確認してお店を決めると失敗は少ないかもしれません。
今回は好きなカフェを調べてみました。
しかし、カフェの情報はInstagramに写真付きで発信する人が多いのかなと思いました。
私自身もカフェ情報はInstagramから調べます。
Instagramはスクレイピングが禁止されているため難しいですが、できたら面白いのではないでしょうか?
Pythonにて、さまざまな情報を取得し可視化を行い一番思ったのは
前職では広告の効果分析のためExcelに視聴率や離脱率、クリック数など手入力を行っていました。
その時できなかったことを短時間で可能とできるPythonは便利でもっと学んでみたいと感じました。
誤っていることも多々あるかと思いますが、ここまでお読みいただきありがとうございました。