本記事に関して
自身の練習用のページになります!
アドバイスがありましたら、よろしくお願いいたします!
はじめに
今回は、SQLとGoogl BigQueryの練習をかねて、
大混戦だったセリーグの優勝争いの勝敗を比較してみました!
始めてGoogl BigQueryを扱ってみました。
個人的ルールとして6時間という時間制限を設けてみました。
簡単なあらすじ
1.Pythonにて試合結果をスクレイピング
2.Googl BigQueryにてデータを抽出・加工
3.データポータルにて可視化
1.Pythonにて試合結果をスクレイピング
データ収集のために、試合結果の一覧サイトから以下のデータを取得!
中止試合などデータの加工もできましたが、最低限に抑えSQLで実行しております。
セリーグ6チーム対象
取得元のサイトはこちら!
__コードはこちら__
# インストール
!pip install requests
!pip install beautifulsoup4
import requests
from bs4 import BeautifulSoup
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
import datetime
import re
from google.colab import drive
drive.mount('/content/drive')
url = 'https://baseball-freak.com/game/giants.html'
dfs = pd.read_html(url,
header=0,
index_col= 0
)
dfs = dfs[0]
dfs = dfs.drop(["日付.1","先発投手","責任投手"],axis = 1)
dfs = dfs.reset_index()
dfs["勝敗"] = dfs["勝敗"].map({"-":3,"△":2,"○":1,"●":0})
dfs["日付"] = dfs["日付"].map(lambda x: "21-{}-{}".format(re.findall(r"\d+", x)[0], re.findall(r"\d+", x)[1]))
dfs["split"] = dfs["スコア"].str.split("-")
dfs["get"] = dfs["split"].str.get(0)
dfs["lost"] = dfs["split"].str.get(1)
dfs = dfs.drop("split",axis = 1)
dfs["team"] = "巨人"
dfs = dfs.rename(columns={'日付': 'date',
'勝敗':'game',
'スコア':'score',
'対戦相手':'vs',
'球場':'location',
'開始':'start'})
dfs.head()
dfs.to_csv("21_giatns.csv",encoding="utf_8_sig")
取得データ一覧
| 取得データ | 説明 |
|---|---|
| date | 試合日 |
| game | 試合結果を数値で表記 0 = 敗戦 1 = 勝利 2 = 引分 3 = 中止 |
| score | 結果スコア |
| vs | 対戦相手 |
| location | 試合球場 → home & away の判別 |
| start | 試合開始時間 |
| get | teamの得点 |
| lost | teamの失点 (vsの得点) |
| team | ~~チームのデータ |
↓サンプル↓
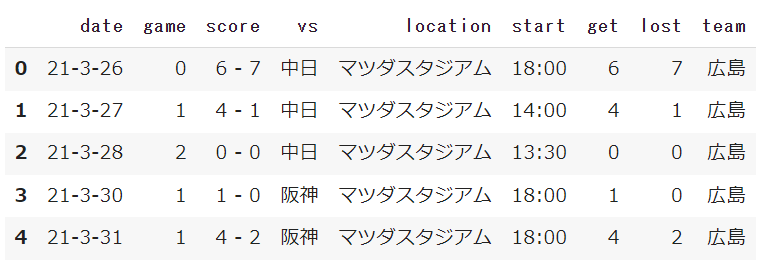
得点・失点からデータを確認するときのために、分けました。
また、この後データを1つにまとめるため、どのチームのデータなのか「team」にて表記。
2.Googl BigQueryにてデータを抽出・加工
Googl BigQueryの使い方にまず苦戦しました。
そのため、書籍『 集中演習 SQL入門 Google BigQueryではじめるビジネス データ分析 』を参考にさせて頂きました!!
抽出の前に先ほど6チーム分のデータをわざと1つのテーブルにまとめました!
そして、全試合のデータが含まれた21テーブルを作成
# すべてのテーブルを縦に結合
SELECT * FROM `baseball-331309.2021.carp` AS `21`
UNION ALL
SELECT * FROM `baseball-331309.2021.dragons`
UNION ALL
SELECT * FROM `baseball-331309.2021.giants`
UNION ALL
SELECT * FROM `baseball-331309.2021.swallows`
UNION ALL
SELECT * FROM `baseball-331309.2021.tigers`
UNION ALL
SELECT * FROM `baseball-331309.2021.yokomaha`
様子
そして、メインとして4つのデータを抽出しました!(全て1チーム毎のデータ)
1.シーズン勝敗データ (勝利・敗北・引き分け) / 中止を除く
2.locationごとの勝敗
3.ホームゲームの勝敗
4.アウェイゲームの勝敗
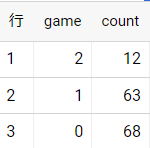
1.シーズン勝敗データ (勝利・敗北・引き分け) / 中止を除く
必要なデータのみ抽出
中止ゲームは振替日にてゲームを行うために除く
0,1,2のグループで試合結果が表記されるが、そのカウントをcountとして表記。
SELECT
game,
COUNT(*) AS `count`
FROM `baseball-331309.2021.21`
WHERE
team = "広島" #広島の場合
AND
game != 3
GROUP BY
game;
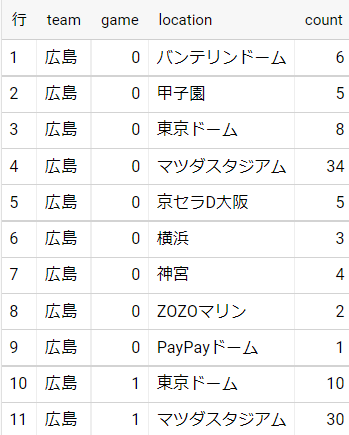
2.locationごとの勝敗
試合を行った球場ごと、そしてhome&awayについて確認するため。
ある記事ではスポーツにおけるホームゲームでの勝率はアウェイより高いらしい!
SELECT
team,
game,
location,
COUNT(*) AS `count`
FROM `baseball-331309.2021.21`
WHERE
team = "広島" #広島の場合
AND
game != 3
GROUP BY
team,
game,
location
ORDER BY game ASC;
3.ホームゲームの勝敗
ホームゲームでの勝敗の差を調べる。
そのため、条件にホーム球場の名前を記載
SELECT
game,
location,
COUNT(*) AS `count`
FROM `baseball-331309.2021.21`
WHERE
team = "広島" #広島の場合
AND
location = "マツダスタジアム" #広島の場合
AND
game != 3
GROUP BY
game,
location
ORDER BY game ASC;
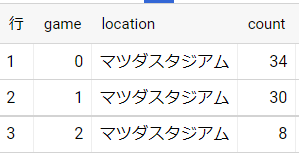
4.アウェイゲームの勝敗
最後にアウェイの試合を調査。
先ほどとは反対に!=にてホーム球場以外のデータを調査
SELECT
game,
COUNT(*) AS `count`
FROM `baseball-331309.2021.21`
WHERE
team = "広島" #広島の場合
AND
location != "マツダスタジアム" #広島の場合
AND
game != 3
GROUP BY
game
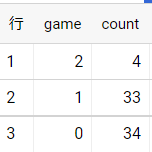
3.データポータルにて可視化
結果を示す!
今回は、1位のヤクルト2位のタイガース、そして応援しているカープの3データ
取得したデータをそれぞれテーブルに保存
保存データをもとにデータポータルにて可視化してみた!
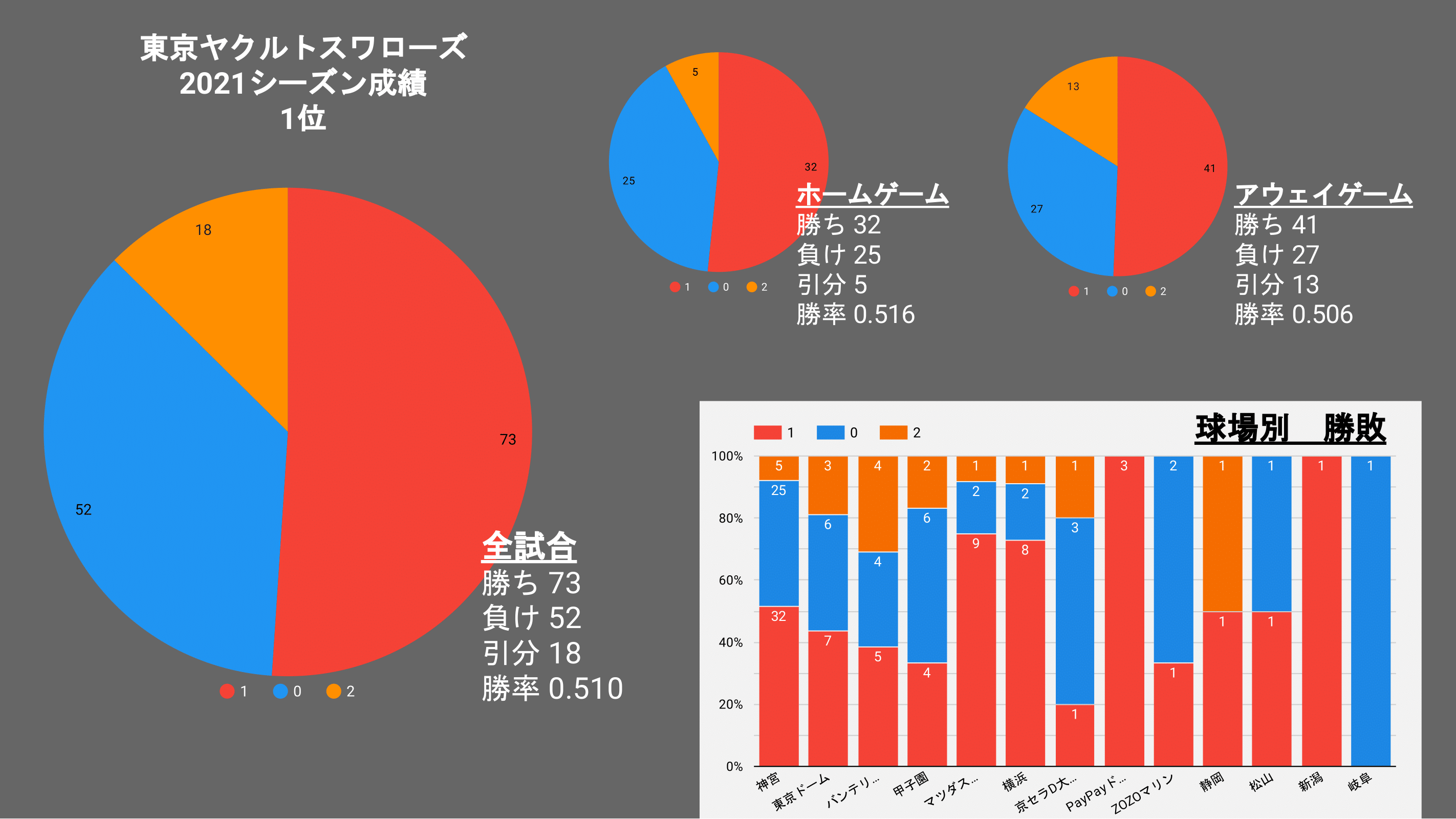
ヤクルト
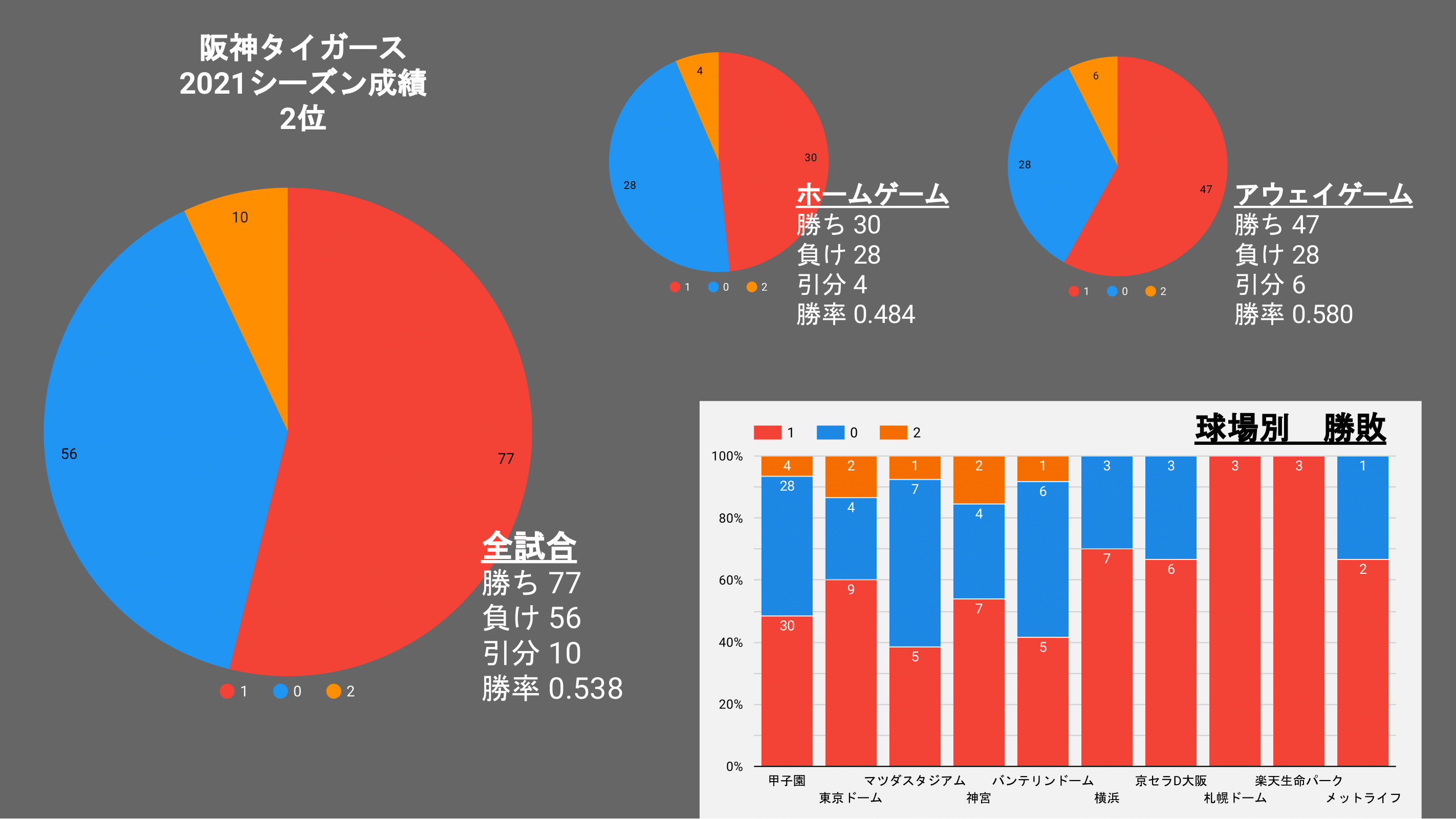
タイガース
カープ
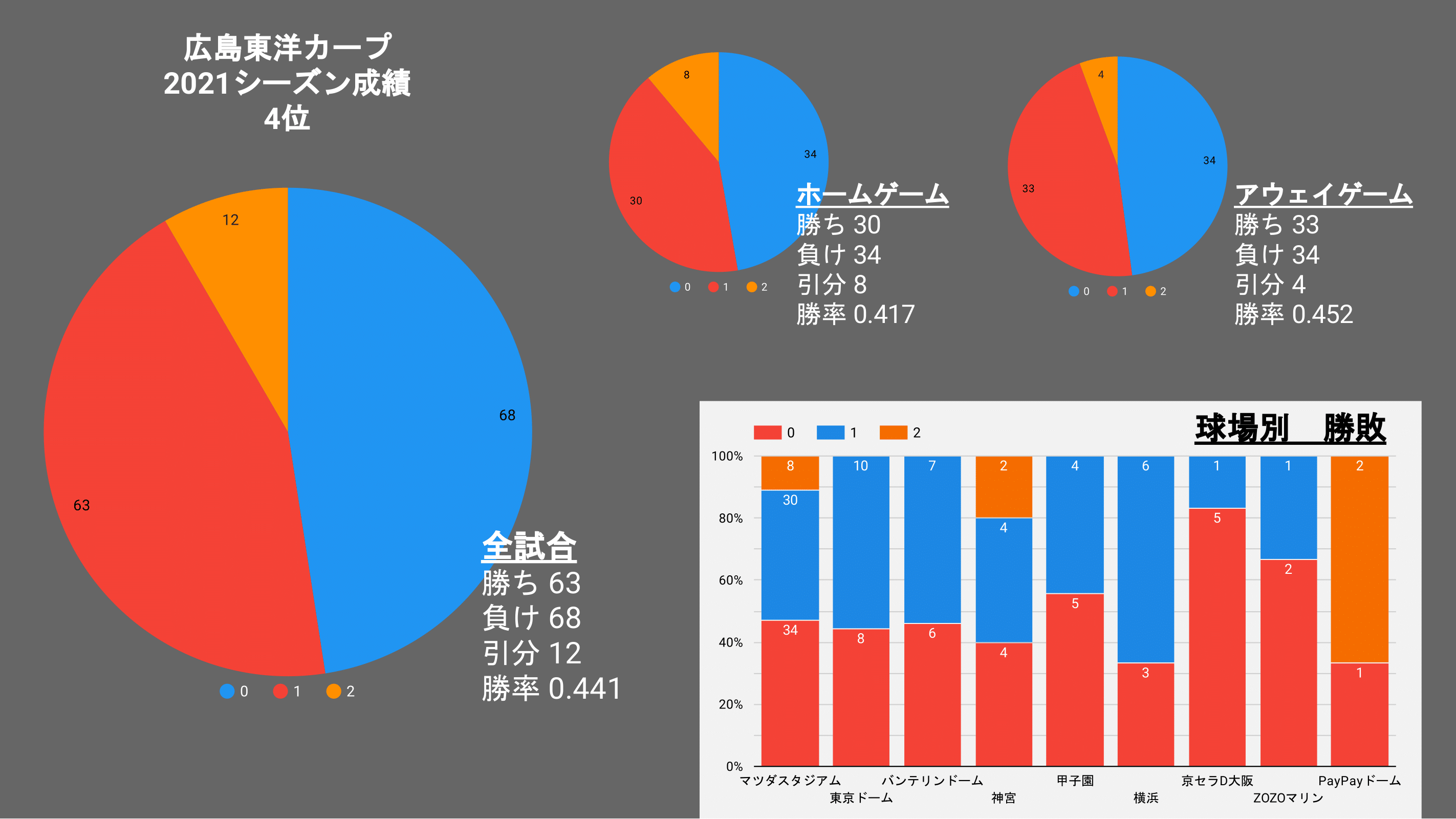
1位のヤクルト2位のタイガースを比較してみて
特出すべきなのは、引き分けと負けの数だろうか、
2位タイガースの方が勝利数が多いのだ!
ヤクルトは負けそうな試合を引き分けに持ち込み、勝ち点を伸ばしたようだ。
また、ヤクルトは下位チームである、「カープ」「横浜」「中日」から勝ち点を多く上げている。
これは、偶然か戦力か判断は難しいが、勝てるチームいは勝つという年間的な戦略なのか!?
また、2位のタイガースがホームゲームで勝率が5割を切っているように
応援が禁止されていた今シーズン
ホーム球場がホームチームにとって戦いやすいことには変わりないが、
ホームで力が出る(アドバンテージ)のようなものは少なかったのかもしれない。
Python、SQLを比較して
Pythonには自由度が高いと感じた!自由にデータを書き替えられ調整も容易い一方コードが複雑。
SQLはデータの誤操作が少なく、社内で人のコードを見る分には便利そうだ!