お読みいただきありがとうございます!
本記事は[その3]となります。
以下4記事がまとめて3分で読める!
[3分で読める] 食べログとSNSの評価を比較してみた~ショート編~
簡単なあらすじ(リンク付き!)
-
(その1)ツイートの取得(SNSの調査)/カフェの選定
TwitterAPIを活用し、東京23区内の人気カフェ/スイーツ店のツイートを取得
取得した店舗のうち、総ツイート数が200件を超えている店舗10店舗を選定。 -
(その2)ツイートの前処理
ツイートには取得したい感想(評価)の他に、公式アカウントや引用ツイート、
お土産ランキングなど不要なツイートを削除。 -
(その3)感情分析にてツイートを得点化(本記事)
「日本語評価極性辞書」と「単語感情極性値対応表」2つの辞書を活用し、得点の比較。
食べログの評価幅が[0~5]のため、正規化にて幅を[0~5]合わせる。 -
(その4)食べログ評価を取得/比較
食べログの評価を取得し、評価の分布をグラフ化。
先ほど取得したツイートの点数との比較を行う。
4.ツイートデータの感情分析
感情分析
感情分析を行う上で現在、ネット上には様々な辞書が公開されています。
今回はよく目にする、単語感情極性値対応表と日本語評価極性辞書を用いてPN値を計測していきます!
「単語感情極性値対応表」
「単語感情極性値対応表」を利用してみます!
__コード一覧はこちら__
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
import json
import pandas as pd
import numpy as np
import re
import csv
import MeCab
import matplotlib.pyplot as plt
import traceback
from google.colab import drive
drive.mount('/content/drive')
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
# 岩波国語辞書のダウンロード
import urllib.request
import zipfile
# URLを指定
url = "https://storage.googleapis.com/tutor-contents-dataset/6050_stock_price_prediction_data.zip"
save_name = url.split('/')[-1]
# ダウンロードする
mem = urllib.request.urlopen(url).read()
# ファイルへ保存
with open(save_name, mode='wb') as f:
f.write(mem)
# zipファイルをカレントディレクトリに展開する
zfile = zipfile.ZipFile(save_name)
zfile.extractall('.')
# MeCabインスタンスの作成.引数を無指定にするとIPA辞書になります.
m = MeCab.Tagger('')
# テキストを形態素解析し辞書のリストを返す関数
def get_diclist(text):
parsed = m.parse(text) # 形態素解析結果(改行を含む文字列として得られる)
lines = parsed.split('\n') # 解析結果を1行(1語)ごとに分けてリストにする
lines = lines[0:-2] # 後ろ2行は不要なので削除
diclist = []
for word in lines:
l = re.split('\t|,',word) # 各行はタブとカンマで区切られてるので
d = {'Surface':l[0], 'POS1':l[1], 'POS2':l[2], 'BaseForm':l[7]}
diclist.append(d)
return(diclist)
# 形態素解析結果の単語ごとのdictデータにPN値を追加する関数
def add_pnvalue(diclist_old, pn_dict):
diclist_new = []
for word in diclist_old:
base = word['BaseForm'] # 個々の辞書から基本形を取得
if base in pn_dict:
pn = float(pn_dict[base])
else:
pn = 'notfound' # その語がPN Tableになかった場合
word['PN'] = pn
diclist_new.append(word)
return(diclist_new)
# 各ツイートのPN平均値
def get_mean(dictlist):
pn_list = []
for word in dictlist:
pn = word['PN']
if pn!='notfound':
pn_list.append(pn)
if len(pn_list)>0:
pnmean = np.mean(pn_list)
else:
pnmean=0
return pnmean
df_tw = pd.read_csv('/content/drive/MyDrive/aidemy/ブログ_食べログ/tweet/csv after/(216)銀座ウエスト.csv',
usecols=['text', 'name','created_at'])
df_tw = pd.DataFrame(df_tw)
df_tw.index +=1
df_tw = df_tw[["text"]]
# 岩波国語辞書の読み込み
pn_df = pd.read_csv('./6050_stock_price_prediction_data/pn_ja.csv', encoding='utf-8', names=('Word','Reading','POS', 'PN'))
# word_listにリスト型でWordを格納
word_list = list(pn_df['Word'])
# pn_listにリスト型でPNを格納
pn_list = list(pn_df['PN'])
# pn_dictとしてword_list, pn_listを格納した辞書を作成
pn_dict = dict(zip(word_list, pn_list))
# means_listという空のリストを作りそこにツイートごとの平均値を求めてください。
means_list = []
for tweet in df_tw["text"]:
dl_old = get_diclist(tweet)
dl_new = add_pnvalue(dl_old, pn_dict)
pnmean = get_mean(dl_new)
means_list.append(pnmean)
df_tw['pn'] = means_list
結果として下記のようにPN値が取れました!

このままの状態だと、全体的にネガティブにPN値が偏ってしまっているため標準化を行います。
また、今回食べログと比較するため評価を0~5の間で行うため
正規化にて値を0~5に設定します。
# 標準化
st = StandardScaler()
df_tw["pn_st"] = st.fit_transform(df_tw[["pn"]])
# 正規化(0-5)
sc = MinMaxScaler([0,5])
df_tw["pn_sc"] = sc.fit_transform(df_tw[["pn_st"]])
# 並び替え
df_tw = df_tw.sort_values(by='pn_sc', ascending=False)
そして、それぞれが得た評価が以下のようになります。
左から初期PN値、標準化PN値、正規化PN値
x軸にrate(評価)、y軸がcount(数)となっています。
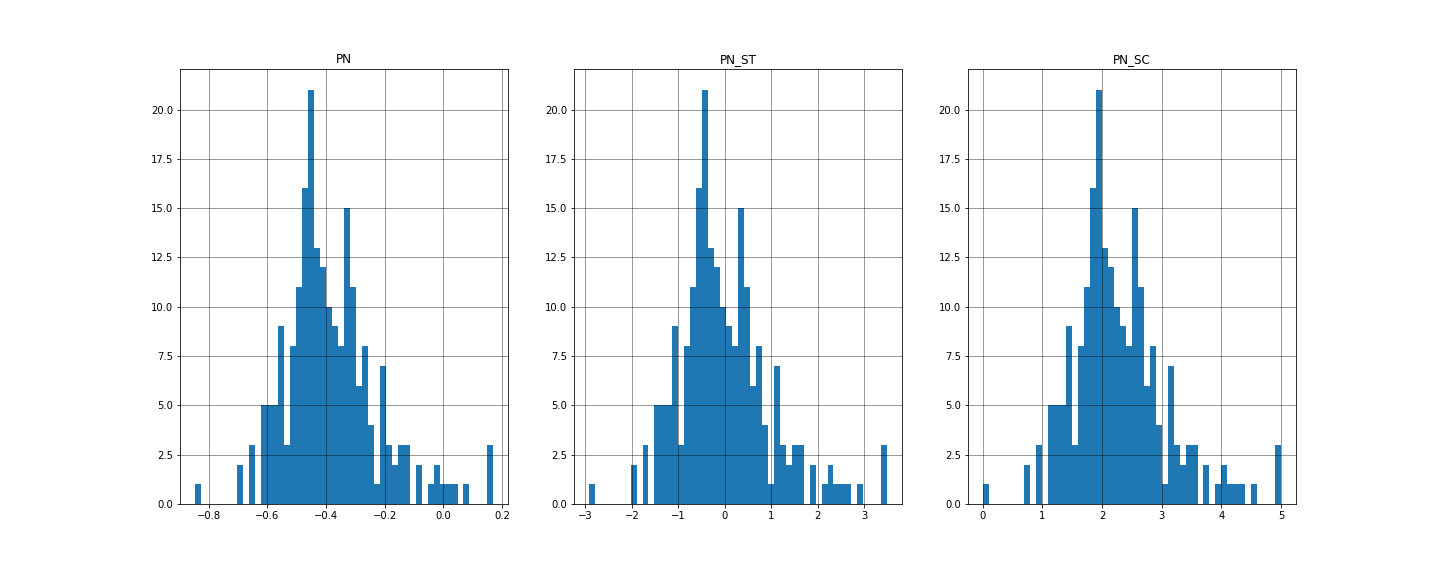
まさかのグラフの形に変化はありませんでした。
しかし、それぞれの平均値を求めると以下のようになり、
標準化したpn_stは限りなく0の値に近いため正しい値と評価しました。
pn = -3.824546e-01
pn_st = -7.812681e-16
pn_sc = 2.280216e+00
ツイート評価
これを全ての店舗に行った結果を以下に記載します。
※最終評価のみ食べログに合わせ、小数点第2位まで
| 店名 | ツイート数 | PN | PN_ST | PN_SC |
|---|---|---|---|---|
| キル フェ ボン | 1914 | -3.642925e-01 | -5.508191e-16 | 1.59 |
| ピエール・エルメ | 786 | -3.908941e-01 | 8.864834e-16 | 1.52 |
| ブルーボトルコーヒー | 565 | -3.901178e-01 | -1.493397e-17 | 1.53 |
| ケンズカフェ東京 | 567 | -3.918743e-01 | 1.918904e-16 | 1.53 |
| マリアージュフレール | 429 | -3.826067e-01 | -3.592050e-16 | 1.55 |
| ひみつ堂 | 303 | -4.918648e-01 | -2.139836e-16 | 1.62 |
| 資生堂パーラー | 308 | -4.918648e-01 | -2.139836e-16 | 1.62 |
| 和栗や | 265 | -4.077040e-01 | -1.675808e-17 | 1.68 |
| アンリ・シャルパンティエ | 226 | -3.617992e-01 | 3.320844e-16 | 1.62 |
| 銀座ウエスト | 216 | -3.824546e-01 | -7.812681e-16 | 2.28 |
なんということでしょう!
軒並み評価が1点台、Twitterには厳しい評価が多いのでしょうか?
ツイート数によって評価に変化もないので、テキストを取り出して見てみます。
テキストの確認
事例1
「秋だし和栗やのモンブラン食べに行くかー」
こんなにも常連を匂わせるツイートが0点です。。。
{'Surface': '秋', 'POS1': '名詞', 'POS2': '一般', 'BaseForm': '秋', 'PN': -0.9467959999999999}
{'Surface': 'だ', 'POS1': '助動詞', 'POS2': '*', 'BaseForm': 'だ', 'PN': 'notfound'}
{'Surface': 'し', 'POS1': '助詞', 'POS2': '接続助詞', 'BaseForm': 'し', 'PN': 'notfound'}
{'Surface': '和栗', 'POS1': '名詞', 'POS2': '固有名詞', 'BaseForm': '和栗', 'PN': 'notfound'}
{'Surface': 'や', 'POS1': '助詞', 'POS2': '並立助詞', 'BaseForm': 'や', 'PN': -0.278384}
{'Surface': 'の', 'POS1': '助詞', 'POS2': '連体化', 'BaseForm': 'の', 'PN': 'notfound'}
{'Surface': 'モンブラン', 'POS1': '名詞', 'POS2': '固有名詞', 'BaseForm': 'モンブラン', 'PN': 'notfound'}
{'Surface': '食べ', 'POS1': '動詞', 'POS2': '自立', 'BaseForm': '食べる', 'PN': -0.9683370000000001}
{'Surface': 'に', 'POS1': '助詞', 'POS2': '格助詞', 'BaseForm': 'に', 'PN': 'notfound'}
{'Surface': '行く', 'POS1': '動詞', 'POS2': '自立', 'BaseForm': '行く', 'PN': -0.961267}
{'Surface': 'か', 'POS1': '助詞', 'POS2': '副助詞/並立助詞/終助詞', 'BaseForm': 'か', 'PN': 'notfound'}
{'Surface': 'ー', 'POS1': '名詞', 'POS2': '固有名詞', 'BaseForm': '*', 'PN': 'notfoundn'}
事例2
「和栗やさんのモンブラン本当に美味しかったよねええ」
今度は逆に高得点(3.65)のテキストです。
{'Surface': '和栗', 'POS1': '名詞', 'POS2': '固有名詞', 'BaseForm': '和栗', 'PN': 'notfound'}
{'Surface': 'や', 'POS1': '助詞', 'POS2': '並立助詞', 'BaseForm': 'や', 'PN': -0.278384}
{'Surface': 'さん', 'POS1': '名詞', 'POS2': '接尾', 'BaseForm': 'さん', 'PN': -0.598002}
{'Surface': 'の', 'POS1': '助詞', 'POS2': '連体化', 'BaseForm': 'の', 'PN': 'notfound'}
{'Surface': 'モンブラン', 'POS1': '名詞', 'POS2': '固有名詞', 'BaseForm': 'モンブラン', 'PN': 'notfound'}
{'Surface': '本当に', 'POS1': '副詞', 'POS2': '一般', 'BaseForm': '本当に', 'PN': 'notfound'}
{'Surface': '美味しかっ', 'POS1': '形容詞', 'POS2': '自立', 'BaseForm': '美味しい', 'PN': 0.99136}
{'Surface': 'た', 'POS1': '助動詞', 'POS2': '*', 'BaseForm': 'た', 'PN': 'notfound'}
{'Surface': 'よ', 'POS1': '助詞', 'POS2': '終助詞', 'BaseForm': 'よ', 'PN': 'notfound'}
{'Surface': 'ねえ', 'POS1': '助詞', 'POS2': '終助詞', 'BaseForm': 'ねえ', 'PN': 'notfound'}
{'Surface': 'え', 'POS1': 'フィラー', 'POS2': '*', 'BaseForm': 'え', 'PN': 'notfound'}
この2つを比較し、キーポイントとなりそうな点がnotfoundです。
SNSから取り出した文章のため、話言葉が多く、ほとんど認識ができていません。
認識されたものの中で、
高得点のテキストには「'美味しい', 'PN': 0.99136」
低得点のテキストには「'秋', 'PN': -0.9467959999999999」「 '食べる', 'PN': -0.9683370000000001」
があり、評価が正当かと言われるとあまりそのような気がしません。。。
参考までに、ネットの情報では「単語感情極性値対応表」は
ポジ:ネガ=1:9でネガティブに著しい偏りがあるとのことでした。
算出された結果も納得できます。
「日本語評価極性辞書」
続いて「日本語評価極性辞書(名詞偏)」を利用して調査してみます。
参考にした記事を記載しておきます!
3. Pythonによる自然言語処理 5-4. 日本語文の感情値分析[日本語評価極性辞書(名詞編)]
__コード一覧はこちら__
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
import json
import pandas as pd
import numpy as np
import re
import csv
import MeCab
import matplotlib.pyplot as plt
import traceback
from google.colab import drive
drive.mount('/content/drive')
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
# カラム名と値の位置ずれを制御
pd.set_option('display.unicode.east_asian_width', True)
pndic_1 = pd.read_csv('/content/drive/MyDrive/aidemy/ブログ_食べログ/tweet/pn.csv.m3.120408.trim', names=['word_pn_oth'])
# 区切り文字で展開
pndic_2 = pndic_1['word_pn_oth'].str.split('\t', expand=True)
# 感情極性値のノイズを削除
pndic_3 = pndic_2[(pndic_2[1] == 'p') | (pndic_2[1] == 'e') | (pndic_2[1] == 'n')]
# 感情極性値を数値に置換
pndic_4 = pndic_3.drop(pndic_3.columns[2], axis=1)
pndic_4[1] = pndic_4[1].replace({'p':1, 'e':0, 'n':-1})
word_list = list(pndic_4[0].tolist())
pn_list = list(pndic_4[1].tolist())
pn_dict = dict(zip(word_list, pn_list))
# MeCabインスタンスの作成
m = MeCab.Tagger('')
# テキストを形態素解析し辞書のリストを返す
def get_diclist(text):
parsed = m.parse(text)
lines = parsed.split('\n')
lines = lines[0:-2]
diclist = []
for word in lines:
l = re.split('\t|,',word)
d = {'Surface':l[0], 'POS1':l[1], 'POS2':l[2], 'BaseForm':l[7]}
diclist.append(d)
return(diclist)
# 形態素解析結果の単語ごとのdictデータにPN値を追加
def add_pnvalue(diclist_old, pn_dict):
diclist_new = []
for word in diclist_old:
base = word['BaseForm']
if base in pn_dict:
pn = float(pn_dict[base])
else:
pn = 'notfound'
word['PN'] = pn
diclist_new.append(word)
return(diclist_new)
# 各ツイートのPN平均値
def get_mean(dictlist):
pn_list = []
for word in dictlist:
pn = word['PN']
if pn!='notfound':
pn_list.append(pn)
if len(pn_list)>0:
pnmean = np.mean(pn_list)
else:
pnmean=0
return pnmean
# ツイートの読み込み
df_tw = pd.read_csv('/content/drive/MyDrive/aidemy/ブログ_食べログ/tweet/csv after/(786)ピエールエルメ.csv',
usecols=['text', 'name','created_at'])
df_tw = pd.DataFrame(df_tw)
df_tw.index +=1
df_tw = df_tw[["text"]]
# ツイートごとの平均値
means_list = []
for tweet in df_tw["text"]:
dl_old = get_diclist(tweet)
dl_new = add_pnvalue(dl_old, pn_dict)
pnmean = get_mean(dl_new)
means_list.append(pnmean)
df_tw['pn'] = means_list
# 標準化
st = StandardScaler()
df_tw["pn_st"] = st.fit_transform(df_tw[["pn"]])
# 正規化(0-5)
sc = MinMaxScaler([0,5])
df_tw["pn_sc"] = sc.fit_transform(df_tw[["pn_st"]])
# 並び替え
df_tw = df_tw.sort_values(by='pn_sc', ascending=False)
先ほどと異なる点は、先に辞書をダウンロードして、CSVを呼び出している点です。
得られた結果は下記。
※先ほど同様に「銀座ウエスト」のツイートを使用
左から初期PN値、標準化PN値、正規化PN値
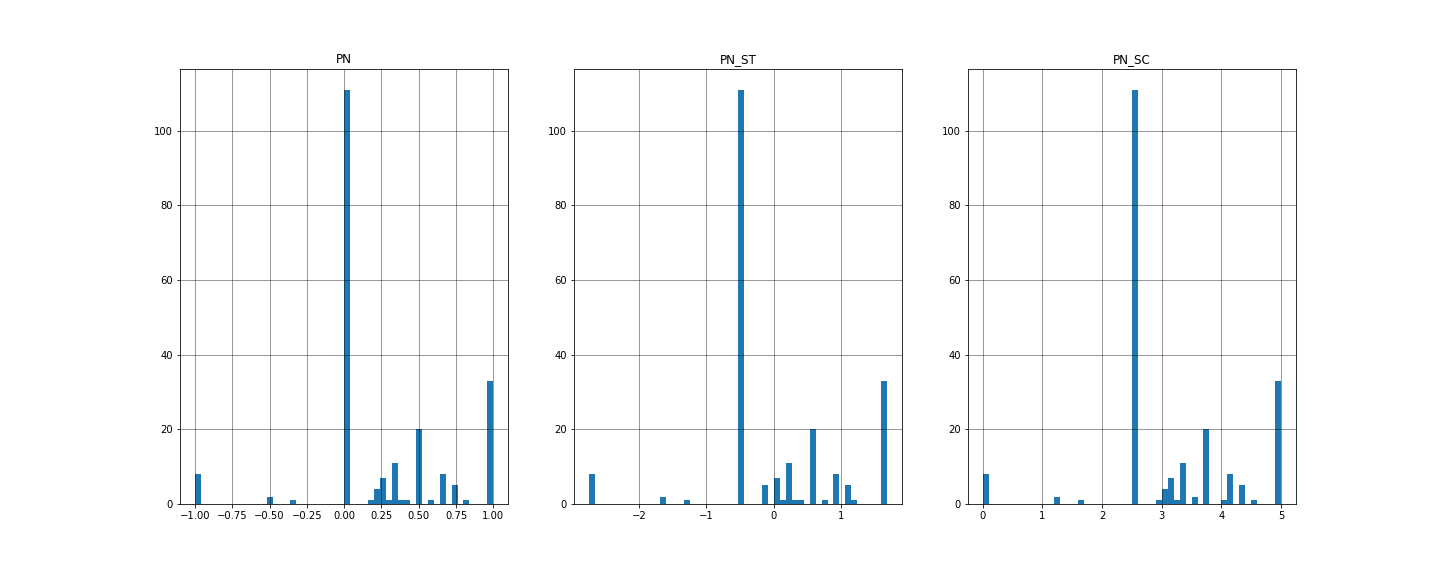
先ほど同様、標準化したpn_stは限りなく0の値に近いため正しい値と評価しました。
pn = 2.391093e-01
pn_st = -9.457455e-17
pn_sc = 3.097773e+00
先ほどよりかなりポジティブな評価が増え、比較対象になりそうです!
しかし、今回の結果はグラフ中央の「pn_sc = 2.5」の値が大半を占めています。
調べてみましょう!
テキストの確認
事例1
「秋だし和栗やのモンブラン食べに行くかー」
{'Surface': '秋', 'POS1': '名詞', 'POS2': '一般', 'BaseForm': '秋', 'PN': 0.0}
{'Surface': 'だ', 'POS1': '助動詞', 'POS2': '*', 'BaseForm': 'だ', 'PN': 'notfound'}
{'Surface': 'し', 'POS1': '助詞', 'POS2': '接続助詞', 'BaseForm': 'し', 'PN': 'notfound'}
{'Surface': '和栗', 'POS1': '名詞', 'POS2': '固有名詞', 'BaseForm': '和栗', 'PN': 'notfound'}
{'Surface': 'や', 'POS1': '助詞', 'POS2': '並立助詞', 'BaseForm': 'や', 'PN': 'notfound'}
{'Surface': 'の', 'POS1': '助詞', 'POS2': '連体化', 'BaseForm': 'の', 'PN': 'notfound'}
{'Surface': 'モンブラン', 'POS1': '名詞', 'POS2': '固有名詞', 'BaseForm': 'モンブラン', 'PN': 'notfound'}
{'Surface': '食べ', 'POS1': '動詞', 'POS2': '自立', 'BaseForm': '食べる', 'PN': 'notfound'}
{'Surface': 'に', 'POS1': '助詞', 'POS2': '格助詞', 'BaseForm': 'に', 'PN': 'notfound'}
{'Surface': '行く', 'POS1': '動詞', 'POS2': '自立', 'BaseForm': '行く', 'PN': 'notfound'}
{'Surface': 'か', 'POS1': '助詞', 'POS2': '副助詞/並立助詞/終助詞', 'BaseForm': 'か', 'PN': 'notfound'}
{'Surface': 'ー', 'POS1': '名詞', 'POS2': '固有名詞', 'BaseForm': '*', 'PN': 'notfound'}
事例2
「和栗やさんのモンブラン本当に美味しかったよねええ」
{'Surface': '和栗', 'POS1': '名詞', 'POS2': '固有名詞', 'BaseForm': '和栗', 'PN': 'notfound'}
{'Surface': 'や', 'POS1': '助詞', 'POS2': '並立助詞', 'BaseForm': 'や', 'PN': 'notfound'}
{'Surface': 'さん', 'POS1': '名詞', 'POS2': '接尾', 'BaseForm': 'さん', 'PN': 'notfound'}
{'Surface': 'の', 'POS1': '助詞', 'POS2': '連体化', 'BaseForm': 'の', 'PN': 'notfound'}
{'Surface': 'モンブラン', 'POS1': '名詞', 'POS2': '固有名詞', 'BaseForm': 'モンブラン', 'PN': 'notfound'}
{'Surface': '本当に', 'POS1': '副詞', 'POS2': '一般', 'BaseForm': '本当に', 'PN': 'notfound'}
{'Surface': '美味しかっ', 'POS1': '形容詞', 'POS2': '自立', 'BaseForm': '美味しい', 'PN': 'notfound'}
{'Surface': 'た', 'POS1': '助動詞', 'POS2': '*', 'BaseForm': 'た', 'PN': 'notfound'}
{'Surface': 'よ', 'POS1': '助詞', 'POS2': '終助詞', 'BaseForm': 'よ', 'PN': 'notfound'}
{'Surface': 'ねえ', 'POS1': '助詞', 'POS2': '終助詞', 'BaseForm': 'ねえ', 'PN': 'notfound'}
{'Surface': 'え', 'POS1': 'フィラー', 'POS2': '*', 'BaseForm': 'え', 'PN': 'notfound'}
単語感情極性値対応表の際にも調べたテキストです。
今回はどちらも同様の評価(pn_sc = 2.5)をつけていました。
理由としては、認識できる名詞がなく、ほとんど「notfound」となっていました。
唯一認識された「秋」は「0」の評価のため、認識できるものは正しく判別していると評価しました。
※単語感情極性値対応表の際は「-0.9467959999999999」
しかし、「pn_sc = 2.5」が増えてしまうと結果が2.5付近に偏ってしまう可能性があります。
そのため、今回は「2.5 = notfound」とみなし、全て消去します。
結果は以下になります。
pn = 0.491882
pn_st = 0.560676
pn_sc = 3.729705
標準化後の数値が少し、正に偏りがありますが、今回は無視します。
他の店舗の結果は以下。
※pn_st/pn_scの値は「notfound」を消去する前の値を記載
比較
| 店名 | ツイート数 | PN | PN_ST | 処理前_SC | 処理後_SC | 単語感情極性値対応表使用時 | 後 - 前 |
|---|---|---|---|---|---|---|---|
| キル フェ ボン | 1914 | 1.79E-01 | 3.89E-15 | 2.95 | 3.60 | 1.59 | 0.65 |
| ピエール・エルメ | 786 | 1.87E-01 | -1.84E-15 | 2.97 | 3.60 | 1.52 | 0.63 |
| ブルーボトルコーヒー | 565 | 2.39E-01 | 2.68E-15 | 3.10 | 3.78 | 1.53 | 0.68 |
| ケンズカフェ東京 | 567 | 1.94E-01 | 2.96E-15 | 2.99 | 3.41 | 1.53 | 0.42 |
| マリアージュフレール | 429 | 2.65E-01 | -2.13E-15 | 3.16 | 3.71 | 1.55 | 0.55 |
| ひみつ堂 | 303 | 1.45E-01 | 1.38E-15 | 2.86 | 3.65 | 1.62 | 0.79 |
| 資生堂パーラー | 308 | 2.00E-01 | -1.25E-15 | 3.00 | 3.60 | 1.62 | 0.60 |
| 和栗や | 265 | 2.66E-01 | -1.79E-15 | 3.16 | 3.61 | 1.68 | 0.45 |
| アンリ・シャルパンティエ | 226 | 2.55E-01 | -7.86E-17 | 3.14 | 3.90 | 1.62 | 0.76 |
| 銀座ウエスト | 216 | 2.39E-01 | -9.46E-17 | 3.10 | 3.73 | 2.28 | 0.63 |
結果よりわかること
- 全数値「notfound処理後」数値上昇したことにより「notfound」によって低い評価に影響されていた
- ツイート数と「notfound」の関係はなし
- 単語感情極性値対応表より店舗ごとの評価に差ができた
- グラフから分かるように「日本語評価極性辞書」の方が明らかに「notfound」が多い。これは適当に評価を下していないこととともに、認識できる名詞が少ないことが言える。
各々の分布は次回[その4]に記載あり。
今後の展望として、今回使用した「日本語評価極性辞書」には用言編もあるため
「notfound」として判別されなかったものはこちらで評価できるのか試してみたい。
続く!
[その4]
5.食べログ評価の取得(2021年09月29日)
6.比較