Pythonでデータ操作をやるにあたり、NumPyやPandasなどのライブラリを用いると作業を効率的にすすめることが出来ますが、いろんな書き方があるので全ての機能を使いこなすのはとっても大変です。
また、とある事情でテストデータを作ることになり、備忘とお勉強をかねて、NumPyやPandasでデータを作成してみました。書いておかないと忘れちゃうので、そのコードをメモっときます。
作りたいテストデータは、こんな感じ。
| 部屋番号 | 区分 | |
|---|---|---|
| 申し込み番号 | ||
| 1 | 603 | B |
| 2 | 503 | A |
| 3 | 803 | C |
| 4 | 402 | B |
| 5 | 1203 | C |
| 6 | 401 | C |
| 7 | 803 | B |
| 8 | 203 | C |
| 9 | 801 | C |
| 10 | 601 | D |
連番の申し込み番号を付与しつつ、(マンションの)部屋番号と、申し込み区分をつける、みたいなかんじです1。
部屋番号は、201〜206,301〜...,1101〜...,1306 と [階数(2〜13階)]+[番号(01〜06)] となってます。区分は[A,B,C,D]です。
テストデータは、部屋番号と区分をそれぞれ独立に無作為抽出します。
目次
- np.arange で連番を作成
- PandasのDataFrameで、文字列をフォーマットしつつ列を連結する
- np.ndarrayからDataFrameを作成する
- PandasのSeries のmap関数でデータを置換する
- DataFrameから列を削除する
- DataFrameをExcelに出力する
やってみる
環境・前準備、インストール
Pythonの分離環境の作成と使用するライブラリを入れておきます。
$ sw_vers
ProductName: Mac OS X
ProductVersion: 10.14.4
BuildVersion: 18E226
$
$ python --version
Python 3.7.1
$ python -m venv ./venv
$ source ./venv/bin/activate
(venv) $
(venv) $ pip install numpy pandas openpyxl
(venv) $
ちなみにopenpyxlはExcel出力する際に使用されるようです。
まずはnp.arangeで連番の素データ作成
np.arange で連番を作成します。また区分データを置換するために、key/valueを扱える dict型のインスタンスを作成します。
import numpy as np
# floor_set = np.array([2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]) コレと等価ですが
floor_set = np.arange(2, 14) # 2から14未満
room_set = np.arange(1, 4) # 1から4未満
order_set = np.arange(1, 5) # 1から5未満
order_json = ['A', 'B', 'C', 'D']
order_dict = dict(zip(order_set, order_json))
print(f'floor_set: {floor_set}')
print(f'room_set: {room_set}')
print(f'order_dict: {order_dict}')
print(type(floor_set))
print(type(room_set))
print(type(order_dict))
(venv) $ python sandbox.py
floor_set: [ 2 3 4 5 6 7 8 9 10 11 12 13]
room_set: [1 2 3]
order_dict: {1: 'A', 2: 'B', 3: 'C', 4: 'D'}
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
<class 'dict'>
(venv) $
参考:
素データからnp.random.choiceで無作為抽出
データから無作為抽出するには、np.random.choice を使用します。
trial_count = 10
# floor_set から無作為抽出。trial_count回の結果をnumpy.arrayで。
floor_sample = np.random.choice(floor_set, trial_count)
# room_set から無作為抽出。trial_count回の結果をnumpy.arrayで。
room_sample = np.random.choice(room_set, trial_count)
# order_set から無作為抽出。trial_count回の結果をnumpy.arrayで
order = np.random.choice(order_set, trial_count)
print(f'floor_sample: {floor_sample}')
print(f'room_sample: {room_sample}')
print(f'order: {order}')
(venv) $ python sandbox.py
... 割愛
floor_sample: [ 4 7 4 2 11 11 7 10 9 12]
room_sample: [3 2 1 2 2 3 1 2 3 2]
order: [3 3 3 2 4 4 3 1 3 2]
(venv) $
文字列をフォーマットして、区分値を変換して出力(Pandas未使用版)
Pandasとかを使わないで普通にPythonで書くと
print('部屋番号\t区分')
for i in range(trial_count):
print(f'{str(floor_sample[i])}{str(room_sample[i]).zfill(2)}\t{order_dict[order[i]]}')
こんな感じでフォーマッティングしながら文字列を連結すればよさそうです。結果は
部屋番号 区分
1302 B
302 A
301 D
503 D
1101 C
303 C
1003 A
1001 B
1103 D
602 C
こんな感じ。シンプルにコレでもOKなんですが、勉強もかねてpandasのDataFrameを使ってみます。
文字列をフォーマットして、区分値を変換して出力(np.ndarrayからPandasでDataFrameを作成する版)
...
import pandas as pd
index = np.arange(1, len(floor_sample) + 1) # keyとなるindex作成
df = pd.DataFrame({'階': floor_sample, '番号': room_sample, '区分key': order}, index=index)
df.index.name = '申し込み番号'
### ココまでで、
#
# 階 番号 区分key
# 申し込み番号
# 1 2 1 2
# 2 10 3 2
# 3 11 2 4
# 4 11 3 4
# ...
### みたいなデータが作成できた
df['部屋番号'] = df['階'].map(lambda x: str(x)) + df['番号'].map(lambda x: str(x).zfill(2))
df['区分'] = df['区分key'].map(order_dict)
df = df.drop(['区分key', '階', '番号'], axis=1)
print(df)
実行結果は、
| 部屋番号 | 区分 | |
|---|---|---|
| 申し込み番号 | ||
| 1 | 802 | D |
| 2 | 1301 | C |
| 3 | 503 | A |
| 4 | 702 | A |
| 5 | 1101 | D |
| 6 | 1302 | C |
| 7 | 701 | C |
| 8 | 601 | C |
| 9 | 1201 | B |
| 10 | 801 | A |
となりました。
NumPyの配列np.ndarrayから、Pandasの表(DataFrame)を作成する
上記のコードを順番にみてみましょう。
index = np.arange(1, len(floor_sample) + 1) # keyとなるindex作成
df = pd.DataFrame({'階': floor_sample, '番号': room_sample, '区分key': order}, index=index)
df.index.name = '申し込み番号'
で、1〜10のindexを作成し、DataFrameを作成します。データはJSON形式(dict形式)で渡すことが出来るようですね。
PandasのSeries のmap関数でデータを置換する
つづいて、
df['部屋番号'] = df['階'].map(lambda x: str(x)) + df['番号'].map(lambda x: str(x).zfill(2))
df['区分'] = df['区分key'].map(order_dict)
です。df['列名'].map(関数) で、元データをその関数の戻り値に置換します。ココでは無名関数(lambdaのとこね)を使ったり、先ほど作成したorder_dict というkey/value データで置換する事も出来ます。
DataFrameから列を削除する
最後に、
df = df.drop(['区分key', '階', '番号'], axis=1)
で、不要な列を削除しています。axis =1で列方向の削除であることを指定しています。
参考:
Excelに出力する。
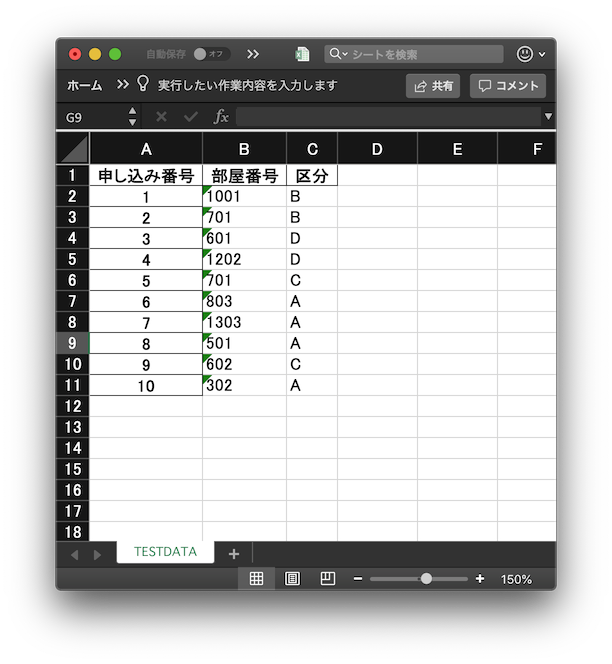
最後にExcelに出力します。
....
df.to_excel('./test_data.xlsx', sheet_name='TESTDATA')
簡単ですね。Excelに出力することができました。
参考:
最終的なコード全体
五月雨に出したコードを整理するとこんな感じです。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import sys
def main(args):
# 素データ作成
floor_set = np.arange(2, 14) # 2から14未満
room_set = np.arange(1, 4) # 1から4未満
order_set = np.arange(1, 5) # 1から5未満
order_json = ['A', 'B', 'C', 'D']
order_dict = dict(zip(order_set, order_json))
# 素データからnp.random.choiceで無作為抽出
trial_count = 10
# floor_set から無作為抽出。trial_count回の結果をnumpy.arrayで。
floor_sample = np.random.choice(floor_set, trial_count)
# room_set から無作為抽出。trial_count回の結果をnumpy.arrayで。
room_sample = np.random.choice(room_set, trial_count)
# order_set から無作為抽出。trial_count回の結果をnumpy.arrayで
order = np.random.choice(order_set, trial_count)
# DataFrameを作成
index = np.arange(1, len(floor_sample) + 1) # keyとなるindex作成
df = pd.DataFrame({'階': floor_sample, '番号': room_sample, '区分key': order}, index=index)
df.index.name = '申し込み番号'
### ココまでで、
#
# 階 番号 区分key
# 申し込み番号
# 1 2 1 2
# 2 10 3 2
# 3 11 2 4
# 4 11 3 4
# ...
# map関数でデータ置換
df['部屋番号'] = df['階'].map(lambda x: str(x)) + df['番号'].map(lambda x: str(x).zfill(2))
df['区分'] = df['区分key'].map(order_dict)
df = df.drop(['区分key', '階', '番号'], axis=1)
print(df)
# Excel出力する
df.to_excel('./test_data.xlsx', sheet_name='TESTDATA')
if __name__ == "__main__":
main(sys.argv)
おつかれさまでしたー。
関連リンク
- pandas.DataFrameに列や行を追加(assign, appendなど)
- pandasで任意の位置の値を取得・変更するat, iat, loc, iloc
- pandas.DataFrame の列の抽出(射影)および行の抽出(選択)方法まとめ
-
実はマンションの駐輪場の申込み・抽選で、抽選をPythonで自動化しようとしてまして。。:-) ↩