- AIでデータ分析-データの前処理(20)-欠損処理:グループ単位での代表値代入③
- 用いるデータの紹介
- AIの活用
- まとめ

AIでデータ分析-データの前処理(20)-欠損値処理:グループ単位での代表値代入③
このノートは、データ分析においてAIを使って何ができて何ができないかを検証するために、実際に試した結果をまとめたノートです。
今回はデータの前処理でよく行われるチェックリスト(20)-欠損値処理:グループ単位での代表値代入③ をAIを用いて行ってみたいと思います。
AIを用いることでいかに効率化できるのか、体験していただければと思います。
所要時間は10分ほどとなっています。
それでは、さっそく始めていきましょう!
データの紹介
今回用いる前処理練習用のcsvデータです。
サンプルデータはこちらから、チェックリストはこちらからダウンロードできます。
1行が1訪問を表すデータになっています。

AIの活用:geminiを活用
20-欠損値処理:グループ単位での代表値代入③


まずは欠損値の状況をヒーマップと棒グラフで確認します。

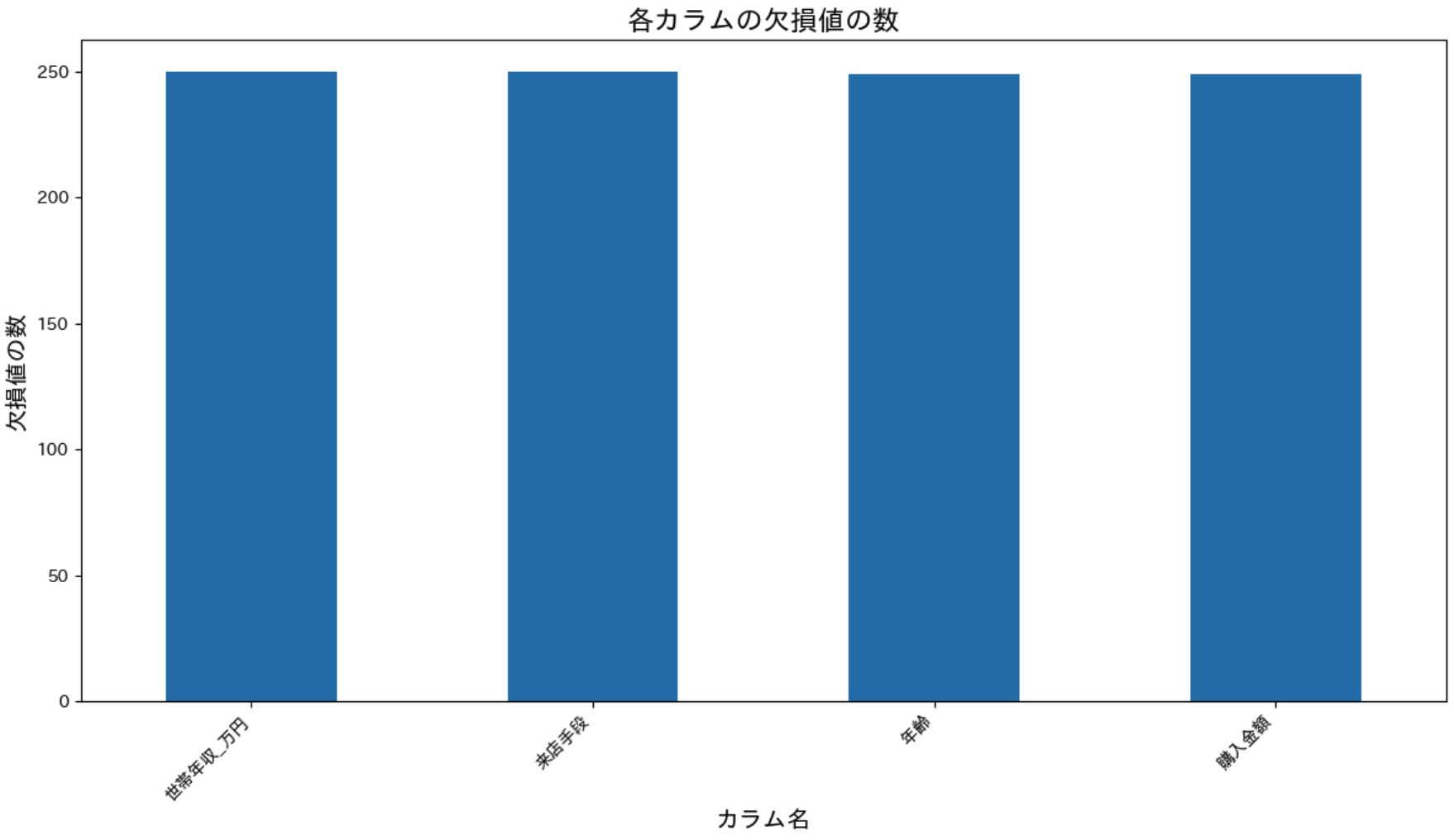
欠損値が残っている列、それぞれ約250行ずつ欠損値が発生していることが確認できます。
欠損値の埋め方を考えるにあたり、欠損値のある列のデータ型・分布を確認します。
・"年齢"列

データ型はfloat64型(数値型)となっています。

分布は40代前後が最も多いようです。

箱ひげ図を見ると年齢にも関わらずマイナスの値(異常値)が含まれていることが確認できます。
欠損処理の方針と同じように変換できるよう、一度マイナスの値を欠損値に変換しておきます。


異常値を除くと平均値と中央値はほとんど変わらないため、外れ値の影響は少ないことが分かります。
従って
年齢は数値型で外れ値の影響が少ないため平均値を代表値とします。
また属性の特徴を反映して欠損値を埋められるよう、性別単位でグループ分けし欠損値を埋めるようgeminiに依頼します。
結果を確認します。

コードと出力された結果を見ると、指定した方法で欠損値が埋められていることが確認できます。
・"世帯年収_万円"列
データ型を確認します。

float64(数値型)であることが確認できました。
箱ひげ図で分布を異常値・外れ値の有無を確認します。

外れ値が含まれていることが確認できます。
平均値と中央値を比較して確認します。

平均値が外れ値の影響を強く受けていることが確認できます。
1.5IQRで統計的な外れ値を確認します。

異常値の基準に1.5IQRを基準として考えると"世帯年収_万円"1275万円以上は異常値として扱われることになります。
データ数としては152存在することが確認できました。
世帯年収が1275万円は一般的に考えられるため、今回は統計的な基準で外れ値を除外するのは適切とは言えなそうです。
さらに箱ひげ図から読みとれる2000万円以上の極端な外れ値について、ヒストグラムで確認してみます。

9999万円が10人いることが確認できます。
データの取得方法としてそれ以上の選択肢の項目がなかったことが推察されますが、世帯年収が約1億円以上の層も当然一般社会でありえるため、削除してしまうと現実のデータが持つ情報(高額所得者層の行動パターンなど)を失ってしまいかねません。
従って今回は外れ値を除外しない方向で進めていくことにしたいと思います。
以上を踏まえつつ、サンプルの特徴をなるべく反映させることを目的として、今回"世帯年収_万円"列の欠損値の埋め方は下記のような考え方で欠損を埋めるようgeminiに依頼します。
①(性別と年齢(→年代に変換)は年収と相関が強いことが想定されるため、似通った属性情報を欠損値の埋め方に反映させることを目的に、)性別と年齢でグループ分けを行う。
②(統計的には外れ値であっても現実社会で高所得者層は存在するため、外れ値として除外しないものの、欠損の埋め方には外れ値の影響を受けにくい)中央値を代表値に用いる
結果を確認します。


コードと出力結果から、"世帯年収_万円"の欠損が埋まったことが確認できます。
まとめ
今回は前処理練習用のデータに対し、前処理チェックリスト(20)-グループ単位での代表値代入③ をAIを用いてできるか試しました。
結果はAIで代替できることを確認することができました。
AIでできることとできないことを把握し、うまく活用することで、データ分析もかなり効率化できそうですね!
AIでデータ分析-データの前処理(20)-欠損処理:グループ単位での代表値代入③ は以上となります!