やりたいこと
- Gmailの受信フォルダから指定した条件の情報を取得し、txtファイルにまとめます。
- 今回は、「ゆうちょデビット」の通知メールに対し、利用日時、店舗、金額のデータを集計します。
ゆうちょデビットの通知メール
- ゆうちょ銀行のデビットカードの「ゆうちょデビット」ですが、決済が完了すると、以下のメールを即座に登録したメールアドレスに送信してくれます。
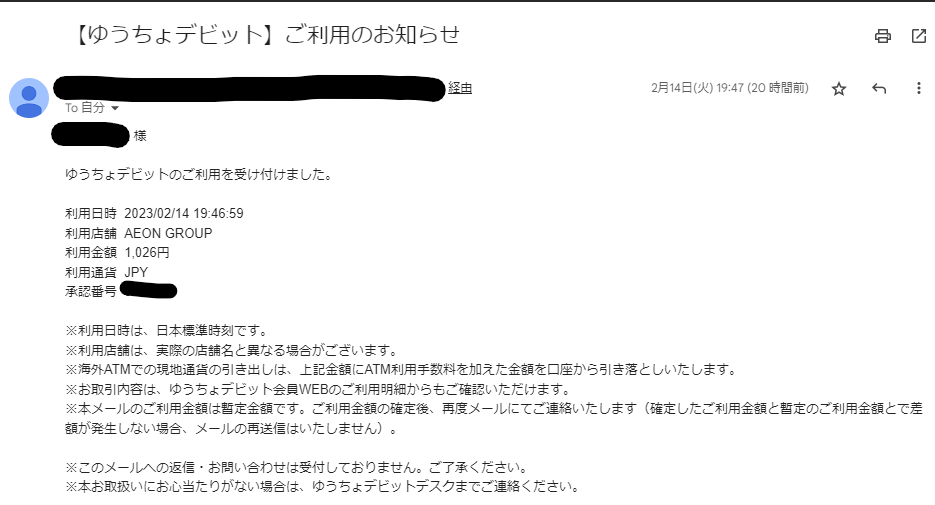
- 毎回の利用金額を手元ですぐに確認できるのは便利なのですが、「週にいくら使ったのか?」などの情報をまとめられると便利ですよね。
- この中の、「利用日時」、「利用店舗」、「利用金額」をこれまでに受信したメールから抽出します。そしてそれを集計したファイルを作成します。
参考にした記事
APIやOAuthに関すること
- 今回は、APIやOAuthの認証などは扱いません。先ほど挙げた2の参考記事がものすごく詳しく解説しているので、まずは、以下の記事を読んで準備を整えてからPythonでの処理に移行してください↓↓。
Pythonでの処理
必要なライブラリ
- google-api-python-client
- google-auth-httplib2
- google-auth-oauthlib
実行に必要なファイル
- 全部で4つのPythonファイルと、OAuthで認証した際にダウンロードしたjsonファイルを使用します。全部同じディレクトリに保管してください。
- auth.py
- client.py
- util2.py
- main5.py
- .jsonファイル(ファイル名はclient_id.jsonにしてください)
認証(auth.pyファイル)
- 初回の認証では、ウェブサーバーを用いて認証を行います。二回目からは、初回の認証を行った際に作成される"token.pickle"を用いて認証が行われるので、人間が認証の手続きをする必要はありません。
auth.py
import pickle
import os.path
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from google.auth.exceptions import GoogleAuthError
os.chdir('このファイルがあるディレクトリまでの絶対パス')
def authenticate(scope):
creds = None
# The file token.pickle stores the user's access and refresh tokens, and is
# created automatically when the authorization flow completes for the first
# time.
if os.path.exists('token.pickle'):
with open('token.pickle', 'rb') as token:
creds = pickle.load(token)
# If there are no (valid) credentials available, let the user log in.
if not creds or not creds.valid:
try:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
'client_id.json', scope)
creds = flow.run_local_server(port=0)
except GoogleAuthError as err:
print(f'action=authenticate error={err}')
raise
# Save the credentials for the next run
with open('token.pickle', 'wb') as token:
pickle.dump(creds, token)
return creds
Google APIを使用したメールの取得(client.py)
- 上で作成したAPIを使用し、1) 受信トレイのメールのリストと、2) 対象メールの件名および 3) 本文を取得します。
client.py
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
import util
class ApiClient(object):
def __init__(self, credential):
self.service = build('gmail', 'v1', credentials=credential)
def get_mail_list(self, limit, query):
# Call the Gmail API
try:
results = self.service.users().messages().list(
userId='me', maxResults=limit, q=query).execute()
except HttpError as err:
print(f'action=get_mail_list error={err}')
raise
messages = results.get('messages', [])
return messages
def get_subject_message(self, id):
# Call the Gmail API
try:
res = self.service.users().messages().get(userId='me', id=id).execute()
except HttpError as err:
print(f'action=get_message error={err}')
raise
result = {}
subject = [d.get('value') for d in res['payload']['headers'] if d.get('name') == 'Subject'][0]
result['subject'] = subject
# Such as text/plain
if 'data' in res['payload']['body']:
b64_message = res['payload']['body']['data']
# Such as text/html
elif res['payload']['parts'] is not None:
b64_message = res['payload']['parts'][0]['body']['data']
message = util.base64_decode(b64_message)
result['message'] = message
return result
追加処理 (util2.py)
- base64 エンコーディングされた本文をデコードする処理と取得したメッセージを保存する処理です。
util2.py
import base64
import os
def base64_decode(b64_message):
message = base64.urlsafe_b64decode(
b64_message + '=' * (-len(b64_message) % 4)).decode(encoding='utf-8')
return message
def save_file(base_dir, file_name, message):
os.makedirs(base_dir, exist_ok=True)
file_path = os.path.join(base_dir, file_name)
with open(file_path, mode='w') as f:
f.write(message)
メインの動作(main5.py)
- 参考資料をもとに、今回の目的に合うように変更しています。上の3つのファイルは、【1】とほとんど変わりませんが、ここからは今回の目的に合わせてかなり変更を加えました。変更点は以下の3点です。したがって、ゆうちょデビットではないメールから任意の情報を抽出したい場合、僕が以下で変更した点は用途に合わせて修正してください。
変更点1. ゆうちょデビットから送られてきたメールおよび、件名に「【ゆうちょデビット】ご利用のお知らせ」を含んだメールのみを対象に検索するように指定した
変更点2. メール本文すべてではなく、指定したデータのみを抽出するため、正規表現でデータを加工してからtxtファイルに加工した
変更点3. 抽出したすべてのデータを一つのtxtファイルにまとめた
main5.py
from __future__ import print_function
import auth
from client import ApiClient
import util2
import re
# If modifying these scopes, delete the file token.pickle.
SCOPES = ['https://www.googleapis.com/auth/gmail.readonly']
MAIL_COUNTS = 1000 # 検索するメールの数
# 変更点 1===================================================================================
SEARCH_CRITERIA = {
'from': "送信元のメールアドレスにここを置き換えてください",
'to': "受信したメールアドレスにここを置き換えてください",
'subject': "【ゆうちょデビット】ご利用のお知らせ"
}
#============================================================================================
BASE_DIR = 'mail_box'
def build_search_criteria(query_dict):
query_string = ''
for key, value in query_dict.items():
if value:
query_string += key + ':' + value + ' '
return query_string
def main():
creds = auth.authenticate(SCOPES)
query = build_search_criteria(SEARCH_CRITERIA)
client = ApiClient(creds)
messages = client.get_mail_list(MAIL_COUNTS, query)
if not messages:
print('No message list.')
else:
total_datas = ''
for message in messages:
message_id = message['id']
# get subject and message
result = client.get_subject_message(message_id)
# 変更点 2============================================================================================
# この範囲は、目的に応じて変更する。
## 必要なデータの加工
## 使用した日時
pattern_date = r'\d{4}/\d{2}/\d{2}\s+\d{2}:\d{2}:\d{2}'
strings_date = re.search(pattern_date, result['message'])
matched_string_date = strings_date.group()
#text_without_slash_date = re.sub(r'/', '', matched_string_date) # remove slashes
#text_without_space_date = re.sub(r' ', '_', text_without_slash_date)
#text_without_colon_date = re.sub(r':', '', text_without_space_date) # remove colons
## 使用した金額
pattern_money = r"利用金額\s+([\d,]+)円"
strings_money = re.search(pattern_money, result['message'])
matched_string_money = strings_money.group()
### 数値だけ取得するために必要ない値を削除
text_without_space_money = re.sub(r'利用金額 ', '', matched_string_money)
text_without_space_money2 = re.sub(r'円', '', text_without_space_money)
text_without_space_money3 = re.sub(r',', '', text_without_space_money2)
## 使用した店舗
pattern_store = r"利用店舗\s+(.*)"
strings_store = re.search(pattern_store, result['message'])
matched_string_store = strings_store.group()
### 店舗名だけ取得するために必要ない値を削除
text_without_space_store = re.sub(r'利用店舗\s', '', matched_string_store)
#============================================================================================
# 変更点 3 ===================================================================================
file_name = f"{result['subject']}.txt"
datas = f"{matched_string_date}\t{text_without_space_money3}\t{text_without_space_store}"
total_datas += datas
util2.save_file(BASE_DIR, file_name, total_datas) # save file
#============================================================================================
if __name__ == '__main__':
main()
実行結果
- 実行に使用したファイルと同じディレクトリに、「mail_box」というフォルダが作成されたと思います。その中に「【ゆうちょデビット】ご利用のお知らせ.txt」というファイル名でデータをまとめたtxtファイルが格納されています。中身は以下の通りです(もちろん情報は実際の僕の履歴から改変しています)。
- 見やすいようにタブ区切りで出力しました。
- 一番左の列から、「利用日時」、「利用店舗」、「利用金額」となっています。

今後やりたいこと
- 最終的には、使用金額のレポートをGmailに送信できるようになりたいです。
(今回) 利用日時、店舗、金額を集計する
(次回) 週ごとの利用状況をまとめたレポートを作成
(最終) そのレポートをGmail経由でメールアドレスに送る