はじめに
CVPR2019より以下の論文
[1] J. Deng, et. al."ArcFace: Additive Angular Margin Loss for Deep Face Recognition". CVPR2019
のまとめ
CVF open access:
https://openaccess.thecvf.com/content_CVPR_2019/html/Deng_ArcFace_Additive_Angular_Margin_Loss_for_Deep_Face_Recognition_CVPR_2019_paper.html
official なcode:
https://github.com/deepinsight/insightface
書きかけ
概要
- 顔認証を行うモデル
- ArcFace(Additive Angular Margin Loss)なるlossを導入し、高い精度を達成
背景
顔認証を行うモデルのlossは主に以下の2つ
- softmaxで多くの人を分類する
- triplet lossを使いembedする
それぞれ以下のような欠点がある。
1. softmaxで多くの人を分類する
欠点1:学習する人の数が増えると最後の全結合層における行列演算が線形に増える
欠点2:学習した特徴量はより多くの人に汎化する時にうまくいかない
2. triplet lossを使いembedする
欠点1:学習する人の数が増えるとtripletな組み合わせが階乗爆発的に増え、学習に時間がかかる
欠点2:semi-hard sample miningは学習が難しい
手法
本論文の主題は ArcFace loss だが、概要はこちら
https://qiita.com/masataka46/items/e069384c2622f3b722f9
MobileFaceNetの記事に書いたので、そちらを参照してください。
ここでは数式で中身を追っていく。
まず
$x_i \in \mathbb{R}^d$ : i番目サンプルの特徴量で、d 次元を想定
$y_i$ : i番目のサンプルが屬するクラス
$W \in \mathbb{R}^{d \times n}$ :最後の重み
$W_j \in \mathbb{R}^d$ :その重みの j 番目の列
として、バイアスを無くせば、softmax lossは
L_1 = - \frac{1}{N} \sum^N_{i=1} \log \frac{e^{W^T_{y_i} x_i}}{\sum^n_{j=1} e^{W^T_{j} x_i}} \tag{1}
であるが、
W^T_{j} x_i = \| W_j\| \| x_i \| \cos \theta_j \tag{C1}
において重みも特徴量も正規化して入力すると(C1)式は
\frac{W^T_{j}}{\| W_j\|} \frac{x_i}{\| x_i \|} = \cos \theta_j \tag{C2}
なので、(1)式は
\begin{eqnarray}
L_2 &=& - \frac{1}{N} \sum^N_{i=1} \log \frac{e^{s \cos \theta_{y_i}}}{\sum^n_{j=1} e^{s \cos \theta_j}} \\
&=& - \frac{1}{N} \sum^N_{i=1} \log \frac{e^{s \cos \theta_{y_i}}}{e^{s \cos \theta_{y_i}} + \sum^n_{j=1, j≠y_i} e^{s \cos \theta_j}} \tag{2}
\end{eqnarray}
となる。正解のクラスに対して角度ベースで m のマージンを与えると(2)式は
L_2 = - \frac{1}{N} \sum^N_{i=1} \log \frac{e^{s \cos (\theta_{y_i} + m)}}{e^{s \cos (\theta_{y_i} + m)} + \sum^n_{j=1, j≠y_i} e^{s \cos \theta_j}} \tag{3}
となる。これがArcFace loss。
以下は softmax と ArcFaceとの比較図。
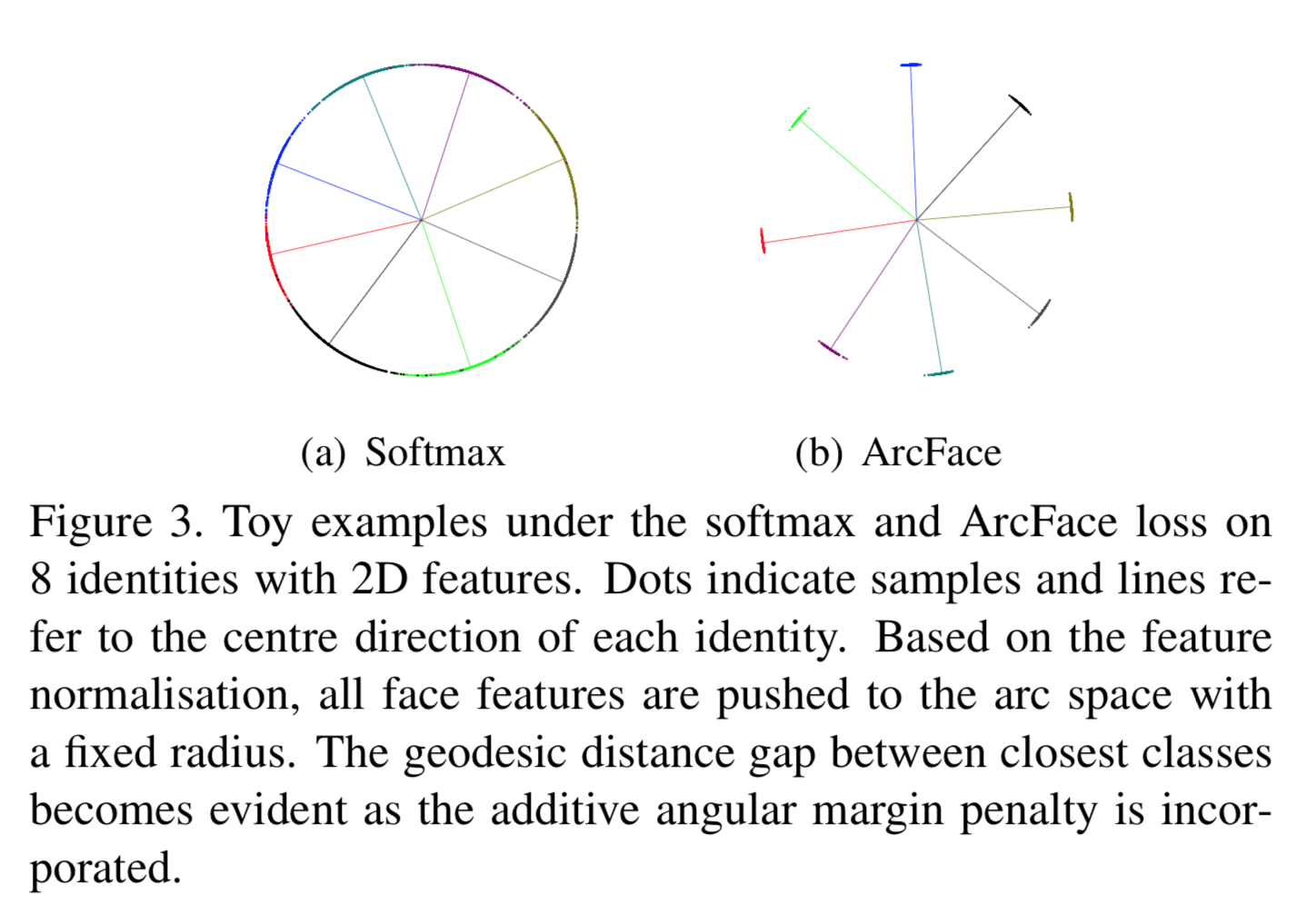
8クラス分類で2次元の特徴量とした場合の両lossの特徴量空間(の正規化後)
以下、この図の解釈。
まず特徴量 $x_i$ を2次元と考えると、それぞれ以下の薄い紫や薄い青のように分布しているだろう。
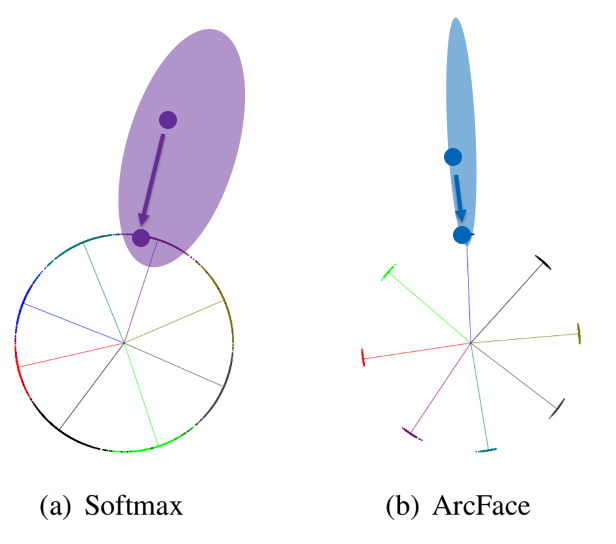
これを正規化すると、矢印のように大きさ1の円上に移動させればこのようになるだろう。
さて、右のArcFace loss の場合を考える。正規化され移動した青点と各クラスの代表ベクトル(を正規化したもの)とのコサイン類似度をいったん求める。これにsoftmaxを作用させると、コサイン類似度が最も高いクラスが選択される。
ここでmargin m を角度ベース加えると、より角度に対して近目の位置に分布が制約されるだろう。そうすると、上図の薄い青の分布のようになると考えられる。