はじめに
CVPR2025のBest Paper Honorable Mentionであるこちら
[1] A. Bar, et. al. "Navigation World Models" CVPR2025.
のまとめ
LeCun先生が共著者なので World Model という言葉が踊っている。
arXiv
https://arxiv.org/abs/2412.03572
project page
https://www.amirbar.net/nwm/
github
https://github.com/facebookresearch/nwm/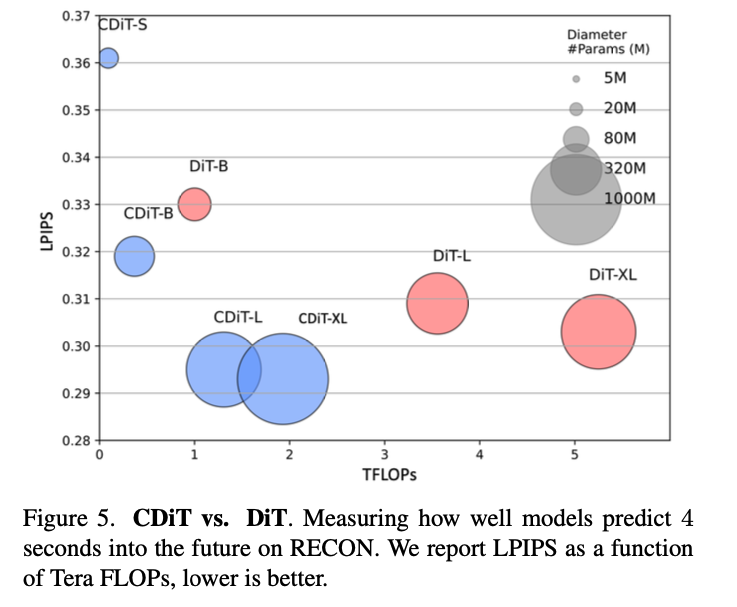
内容は順次追加します。
概要
- 移動物体から見た場合の将来のframeを生成するしくみ。「前に進め、左曲がれ」など conditionを与えて、その通りのシーンを生成する
- ネットワークのアーキテクチャはconditional diffusion transformer(CDiT) を用いる
- CDiTを用いたことで、既存手法と比べて演算量あたりの精度が大幅に改善された
下図において、左から移動物体(車・ロボット)から見た過去のframeと、今後移動する向きと距離をその右 Navigation world model に入力する。そうすると、その将来の視点から見たframeを予測して生成する。

(Figure1より)
見た感じ、かなりそれらしい画像が生成されている。しかもかなり高解像度。
そこでこの記事では「未来のframeを効率的に予測できるのはなぜか」という観点から以下の点に焦点を絞ってまとめる。
- ネットワークのアーキテクチャはどのようなものか。既存のものと何が違うのか
- 学習方法はどのようなものか。diffusionを用いない場合と何が違うのか
ネットワークのアーキテクチャ
以下ではネットワークのアーキテクチャに関して、
- DiTの登場以前
- DiT
- CDiT
とう順でまとめる。
DiTの登場以前
DiTが登場する以前のDDPMなどでは全体のアーキテクチャがU-Net構造で、その中のモジュールとしてtransformerが用いられていた。(下図)

DiT
しかしDiTではtransformerのみの多層構造に変わった。(下図)

DiTは画像の生成を想定したアーキテクチャだが、これを今回のような動画に用いる場合、若干の工夫が必要である。具体的には以下のようにinput tokensを「過去+将来」の画像にする必要がある。

しかし、このしくみでは演算量が多大になる。
具体的には、${\bf s_{\tau}} + s_{\tau +1} = (s_{\tau +1}, s_{\tau}, ..., s_{\tau -m})$ が Input Tokensとなるが、この場合フレーム数を $m$、 1フレームあたりのtoken数を $n$とすると、attention部分では queryの大きさが $m \cdot n$ 、keyの多いさが $m \cdot n$ となるので
O((mn)^2d) = O(m^2n^2d)
の演算量となる。
CDiT
本論文の核となるCDiTモジュールはこの問題点を解消するため、下図の右のようにinput tokensは将来frameだけとし、過去のframeは cross-Attention モジュールで注入する。

この場合、cross-attentionで queryの大きさは予測するframeのみのlatentである $n$ 、keyの大きさは過去のlatentである $m \cdot n$ となるので、
O((m \cdot n) \cdot n) = O(mn^2d)
の演算量となり、大幅に削減される。
コードを見ると、実際には CDiT モジュールがこんな感じで28個連なっている。

学習
学習に関しては定式化を行なった上で、diffusionを用いない場合との比較でまとめる。
定式化
$s_i \in {\rm enc}_{\theta}(x_i)$: $i$ frameの latent
${\bf s}_{\tau} = (s_{\tau}, \cdots, s_{\tau-m})$: 過去 $m$ frameの latent 群
$a_{\tau} = (u, \phi)$ : $\tau$ frameからの移動($u$)と回転($\phi$)
とし、目標は $a_{\tau}$ 移動・回転した将来frameにおける latent $s_{\tau + 1}$ を パラメータ $\theta$ のニューラルネット $F_{\theta}$ を用いて 予測すること。
s_{\tau + 1} \sim F_{\theta} ( s|_{\tau + 1} | {\bf s}\_{\tau}, a\_{\tau})
diffusionを使わない場合の学習
これを今回のような diffusion 的仕組みを使わず学習する場合から考える。以下のように

modelに過去のframe(のlatent) ${\bf s}_{\tau}$ と次frameへのaction $a_{\tau}$ を入力とし、次frame(のlatent)を推定させる。これと実際の次frame(のlatent) $s_{\tau+1}$ との差を計算して学習させるだろう。
diffusion的な学習
一方で本論文ではdiffusion的な学習を採用している。以下のように

まずtarget(のlatent) $s_{\tau+1}$ にnoiseを付与し $s_{\tau+1}^{(t)}$ 、それと過去frame(のlatent) ${\bf s}_{\tau}$ と次frameへのaction $a_{\tau}$ とをmodelに入力する。modelからはdenoiseした次frame(のlatent)を出力し、実際のtarget $s_{\tau+1}$ とでlossを計算する。
推論時は以下のように完全なnoiseを入力して次frame(のlatent)を推定させる。

目的関数
目的関数はこの予測値 $F_{\theta} ( s|_{\tau + 1} | {\bf s}_{\tau}, a_{\tau})$ と対応する正解値 $s_{\tau + 1}$ とのMSEを計算する。
\mathcal{L}_{\rm simple} = \mathbb{E}_{s_{\tau + 1}, a_{\tau}, {\rm s}_{\tau}, \epsilon, t} [ \| s_{\tau + 1} - F_{\theta} (s_{\tau + 1}^{(t)} | {\rm s}_{\tau}, a_{\tau}, t) \|^2_2 ].
noiseの付与方法
timestamp $t$ に相当する noiseの付与方法は一般的なdiffusionのそれと同様に標準正規分布からサンプリングした $\epsilon \sim \mathcal{N}(0, I)$ を用いて
s_{\tau + 1}^{(t)} = \sqrt{\alpha_t} s_{\tau + 1} + \sqrt{1 - \alpha_t} \epsilon
としている。
実験と結果
以下は RECON datasetを用いて DiTモデルとLPIPSを比較した結果。

横軸が TFLOPs、縦軸が LPIPS。本論文のCDiTモデルの方がより左下によっていて、演算量の割に精度がよいと言える。
感想
- CDiTを用いることで低い演算量にも関わらず高い精度を出せている。これによってモデルを大きくでき、その結果最高精度が上がったと解釈できる
- world modelとして考えた場合、大量のデータセットが必要となるだろう。その場合
- 本モデルは動画とカメラの軌跡があればよいので、google mapの車みたく、カメラと計測器を搭載したもので大量収集すればデータがあつまるか?
- diffusion部分をVAR(vision autoregressive transformer)系のモジュールに変えると、スケール則に従ってどんどん精度がよくなるか?
Reference
[2] William Peebles and Saining Xie. Scalable diffusion mod- els with transformers. In Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 4195–4205, 2023.