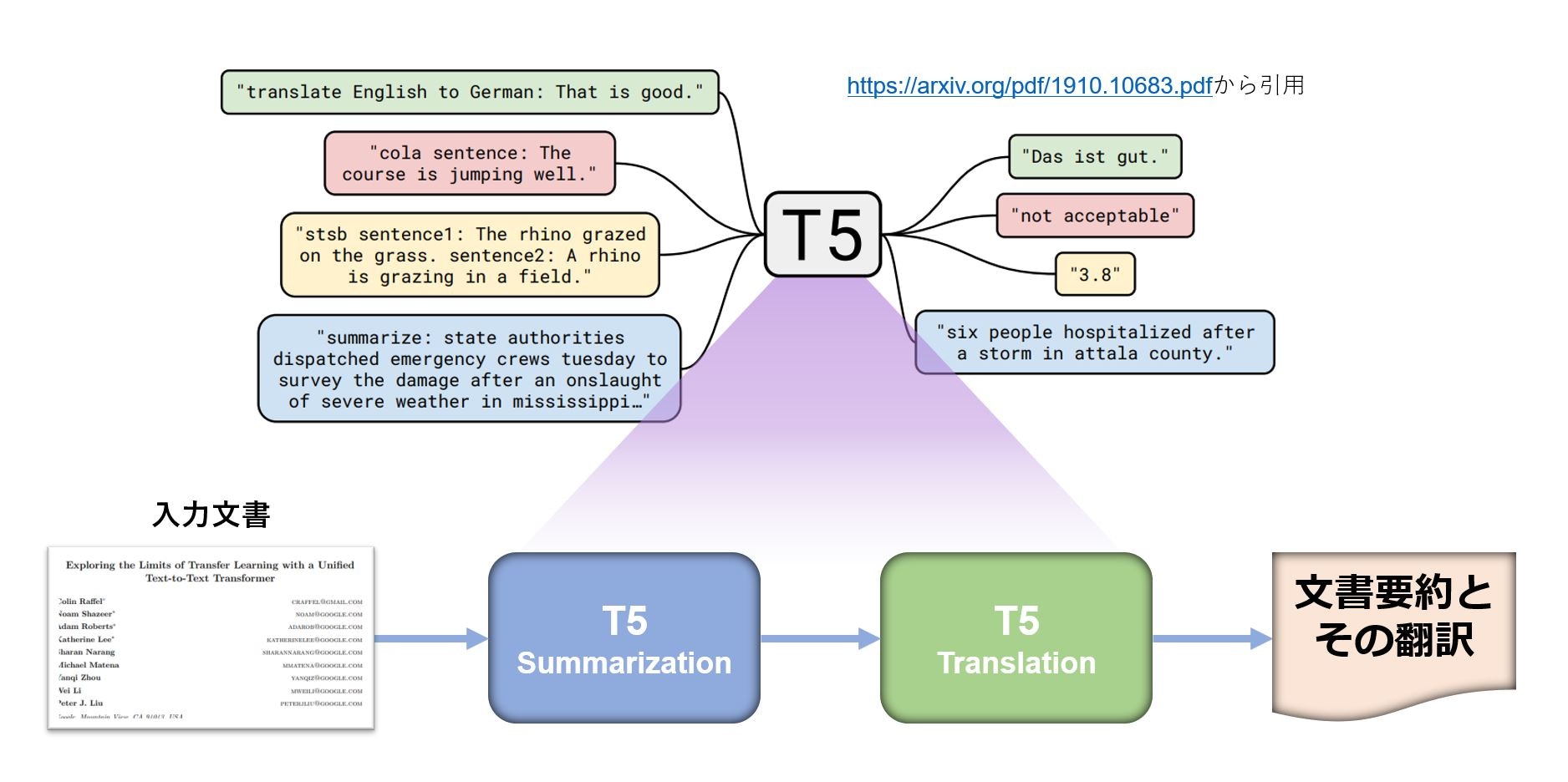
GoogleがT5(Text-to-Text Transfer Transformer)を発表したのは2019年ですが、transformers からも実装コードが公開され、事前学習モデルでは大きいもの(t5-11b)は110億パラメータ、小さいもの(t5-small)は6000万パラメータと、さまざまなスケールのものが公開されています。筆者の AI 実行環境は Colab なので、大きなモデルは敬遠してきたのですが、GPUメモリ使用量削減手段をみつけ、触り始めました。評判通りパラメータ数が多いほど事前学習モデルでの推論結果も妥当性が高いと感じています。また、T5 は異なるタスクを一つのフレームワークでこなせるマルチタスク性がありますので、一つの事前学習モデルを一度ロードすると、複数のタスクを同じモデルで実行することができ、実行環境リソースの節約にもなります。
T5 が身近で動いたら使い出がありそうだと思い、なるべく大きな T5 をマルチタスクでColab無償版とPro版で動かしてみました。そうしたところ、28億パラメータ T5 (t5-3b)がPro版では動作可能であること、また、Colab無償版でも少し限定的なやり方になりますが、同じく t5-3b が動作可能なことがわかりました。
そこでこの記事では、28億パラメータ T5 (t5-3b)を使った マルチタスクの Colab での実行について記載します。NLP タスクとしては、要約タスクや翻訳タスクを用い、その処理のためのGPUメモリ使用量を確認していきます。
準備
実行環境と対象モデル
T5では以下のスケールの事前学習モデルが提供されています。
| 事前学習モデル | サイズ |
|---|---|
| t5-11b | 11B parameters |
| t5-3b | 2851.6M parameters |
| t5-large | 737.7M parameters |
| t5-base | 222.9M parameters |
| t5-small | 60.5M parameters |
Colab Pro版、Colab無償版それぞれで実行を推奨する T5 事前学習モデルはそれぞれ t5-3b、t5-large です。これは t5-3b ではモデルロード時にメモリを25GB近く(後で紹介する torch_dtype=torch.float16 でも18GB弱)使用するため、Colab Pro版では賄えますが、Colab無償版の12.68GBでは足りないためです。110億パラメータの t5-11b では、Colab Proでもモデルロードの際にクラッシュ(メモリ無し)します。
なお、一旦モデルロードが完了すると、メモリはあまり使いませんので、t5-3b がロード可能な環境で事前学習モデルをロードした後、torch.save(model, PATH) を使ってセーブし、それをColab無償版で torch.load() でロードすることで、t5-3b が使えるようになります。ただし、PyTorch ではこのセーブ・ロードは推奨されておらず、state_dict を使ったセーブ・ロードが推奨されています。なお、 state_dict を使った正統的なやり方では、メモリを多く使いますのでColab無償版では t5-3b のロード対策としては使えません。
| メモリ | GPU | 実行可能なT5 事前学習モデル | |
|---|---|---|---|
| Colab Pro版 | 25.46 GB | Tesla P100-PCIE (16280MiB GPU Memory)、 Tesla T4 (15109MiB GPU Memory)など |
t5-3b あるいはそれ以下 |
| Colab無償版 | 12.68 GB | Tesla T4 (15109MiB GPU Memory)など |
t5-large あるいはそれ以下 (torch.save(model, PATH) でセーブした t5-3b をロードできれば動作可) |
使用するNLPタスク
同じ T5 事前学習モデルで要約タスクと翻訳タスクを順次実行します。T5 事前学習モデルの翻訳タスクでは英語からはドイツ語、フランス語、ルーマニア語への翻訳が提供されているようですが、ここではドイツ語とフランス語への翻訳を行います。
コード
パッケージインストール
必要なパッケージをインストールします。
%%bash
pip install transformers[torch] > /dev/null
pip install datasets > /dev/null
pip install sentencepiece > /dev/null
pip list | grep -e 'transformers' -e 'torch' -e 'sentencepiece'
# sentencepiece 0.1.96
# torch 1.11.0+cu113
# torchaudio 0.11.0+cu113
# torchsummary 1.5.1
# torchtext 0.12.0
# torchvision 0.12.0+cu113
# transformers 4.20.1
tokenizer、model のロード
model_name への設定として、 Colab Pro版では 't5-3b'、Colab無償版では 't5-large' がお勧めです。 torch_dtype=torch.float16 を指定することで、GPUメモリ使用量が削減できます。この指定をしないと、Tesla P100-PCIEであっても 't5-3b' ではあまり長い文章を処理できません。
tokenizer は model に応じたものをロードします。model_max_length=2048 は入力として読み込む文章の最大トークン数よりも大きい値として設定しています。対象文章のトークン数に応じて model_max_length を適切に設定する必要があります。
from transformers import T5Tokenizer, T5ForConditionalGeneration, pipeline
import torch
model_name = 't5-3b' # 't5-small', 't5-base', 't5-large', 't5-3b'
tokenizer = T5Tokenizer.from_pretrained(model_name, model_max_length=2048)
model = T5ForConditionalGeneration.from_pretrained(model_name, torch_dtype=torch.float16)
model_size = sum(t.numel() for t in model.parameters())
print(f"{model_name} size: {model_size/1000**2:.1f}M parameters")
# t5-3b size: 2851.6M parameters
要約タスクと翻訳タスクの定義
pipeline() を使って要約タスクを設定します。
翻訳タスクは prefix として "translate English to German: " や "translate English to French: " をテキストに加えてトークン化したものを model.generate() に入力して実行します。
device = torch.device(f"cuda:{0}") if torch.cuda.is_available() else torch.device("cpu")
summarizer = pipeline(
'summarization', model=model, tokenizer=tokenizer, device=device
)
def translation(text, lang):
# 翻訳タスクは一文ごとに処理します。
prefix = "translate English to %s: "
translated_list = list()
for sentence in convert2sentencelist(text):
input_ids = tokenizer(prefix%lang + sentence, return_tensors="pt").input_ids
translated = model.generate(input_ids.to(device))
translated_list.append(tokenizer.decode(translated[0], skip_special_tokens=True))
translated_text = ' '.join(translated_list)
return translated_text
なお、翻訳タスクも pipeline() を使って以下のコメント化したロジックのように設定したかったのですが、先に定義した summarizer() の動作がおかしくなるため、 pipeline() の使用は要約タスクのみとしました。pipeline() は一つしか使えないのかも知れません。
# en_de_translator = pipeline(
# 'translation_en_to_de', model=model, tokenizer=tokenizer, device=device
# )
ヘルパー関数の定義
check_gpumemory() でGPUメモリ使用量をチェックし、表示します。
check_words_tokens() は文章に含まれるワード数、トークン数をカウントします。
また、翻訳タスクは一文ごとに実行しますので、その入力とするために summarizer() の出力を convert2sentencelist() で一文ごとに要素化したリストに変形します。
import subprocess
def check_gpumemory():
# GPUメモリ使用量をチェックし、表示します。
# nvidia-smiの出力形式に依存しています。
nvidia_smi_out = subprocess.run("nvidia-smi",capture_output=True, text=True)
gpumemory = list()
for word in nvidia_smi_out.stdout.split(' '):
if word[-3:] == 'MiB':
gpumemory.append(word)
print(f"GPUメモリ使用量:{gpumemory[0]} / 総GPUメモリ量:{gpumemory[1]}")
def check_words_tokens(text, tokenizer):
# textのワード数、tokenizerによるトークン数を返却します。
tokens = tokenizer(text, return_tensors="pt").input_ids[0]
return len(text.split(' ')), len(tokens)
def convert2sentencelist(text):
# 翻訳タスクは一文ごとに処理するため、要約タスクの出力を文ごと分割しリスト化します。
sentencelist = list()
sentences = text.split(' .')[:-1]
for sentence in sentences:
sentence = sentence.lstrip()
txt = ''
for word in sentence.split(' '):
txt += word + ' '
sentencelist.append(txt + ' .')
return sentencelist
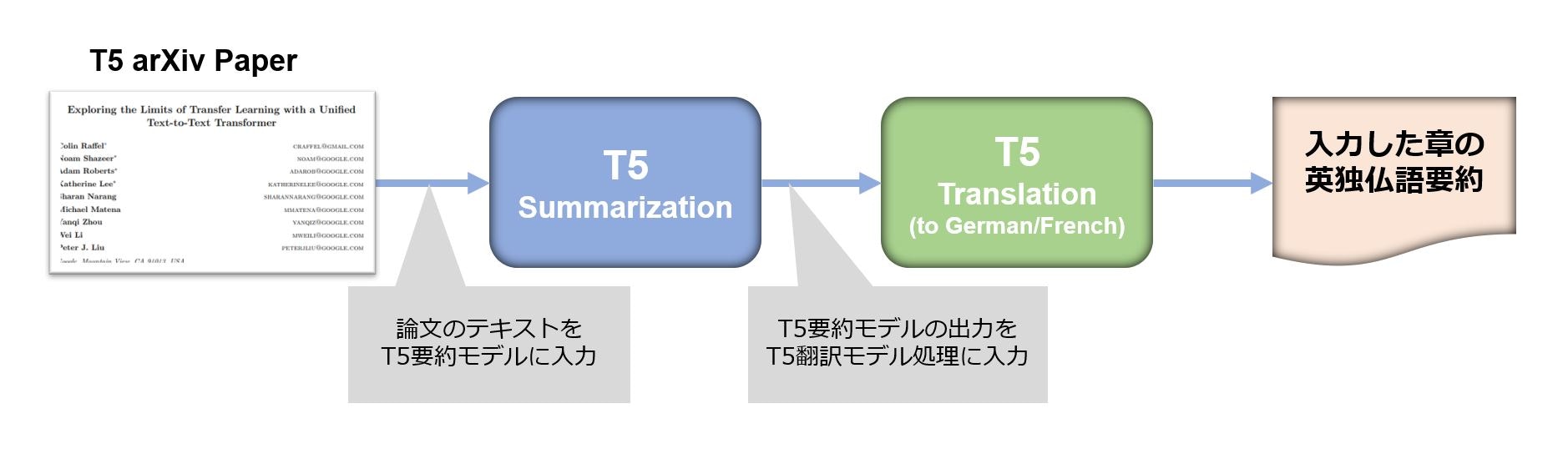
入力文書
英語で書かれているT5論文の以下の章を入力テキストとして使用するため、ダウンロードして所定の場所においてください。
| 章 / タイトル |
|---|
| 1. Introduction |
| 2.1 Model |
| 2.4 Input and Output Format |
| 3.2.1 Model Structures |
| 3.2.2 Comparing Different Model Structures |
run() の定義
指定したディレクトリ配下のファイルを読み取り、順次要約タスクと翻訳タスクを実行する処理として、run() を定義します。
import glob
def run(docs_path):
# 指定されたディレクトリ配下の各ファイルに対し、以下の処理を行います。
# ・ファイルから文章をとりだし、ワード数、トークン数を計算
# ・要約タスクにより取り出した文章の要約を作成
# ・その要約文書を翻訳タスクで独仏語に翻訳
# ファイルリスト作成
file_list = sorted(glob.glob(docs_path + '/*.txt'))
for file_path in file_list:
with open(file_path) as fd:
# GPUメモリ使用量チェック
check_gpumemory()
# ファイルから文章の読み込み
txt_list = list()
for line in fd:
if line[:2] == '# ':
continue
txt_list.append(line)
txt = ''.join(txt_list).replace('\n', ' ')
# 読み込んだ文章のワード数、トークン数をカウント
word_count, token_count = check_words_tokens(txt, tokenizer)
# 要約タスク
summarized = summarizer(txt, num_return_sequences=1)
summarized_text = summarized[0]['summary_text']
# 翻訳タスク:独語への翻訳
german_text = translation(summarized_text, 'German')
# 翻訳タスク:仏語への翻訳
french_text = translation(summarized_text, 'French')
# 結果出力
print('\n>>> {:s}'. format(file_path.split('/')[-1].split('.txt')[0].replace('_', ' ')))
print(" ワード数 / トークン数: {:d} / {:d}". format(word_count, token_count))
print(" 要約:", summarized_text)
print(" 独語:", german_text)
print(" 仏語:", french_text)
print('\n')
# GPUメモリ使用量チェック
check_gpumemory()
実行
run() の実行
./docs 配下に処理対象のファイルが置いてあるとして、実行します。GPUは Tesla P100-PCIE を使っています。
docs_path = './docs'
run(docs_path)
# GPUメモリ使用量:7063MiB / 総GPUメモリ量:16280MiB
#
# >>> 1. Introduction
# ワード数 / トークン数: 948 / 1510
# 要約: a great deal of recent work has developed transfer learning methodology for NLP . in this paper, we leverage a unified approach to transfer learning that allows us to systematically study different approaches and push the current limits of the field . we evaluate performance on a wide variety of english-based NLP tasks, including question answering, document summarization, and sentiment classification .
# 独語: Eine Vielzahl neuerer Arbeiten hat die Methodik des Transfer Learning für NLP entwickelt (Transfer Learning Methodology for NLP ). in diesem papier, nutzen wir einen einheitlichen Ansatz zum Transfer Lernen, dass es uns erlaubt, systematisch zu studieren verschiedene Ansätze und drücken die gegenwärtigen Grenzen des Bereichs. Wir evaluieren die Leistung bei einer Vielzahl von englischsprachigen NLP-Aufgaben, einschließlich Fragebeantwortung, Dokument-Summarisierung und Sentiment-Klassifizierung.
# 仏語: Un grand nombre de travaux récents ont mis au point une méthodologie d'apprentissage par transfert pour le PNL. Dans cet article, nous utilisons une approche unifiée du transfert de l’apprentissage qui nous permet d’étudier systématiquement différentes approches et de repousser les limites actuelles du domaine. Nous évaluons la performance sur un large éventail de tâches NLP basées sur l'anglais, y compris la réponse à des questions, la synthèse de documents et la classification des sentiments.
#
#
# GPUメモリ使用量:12315MiB / 総GPUメモリ量:16280MiB
#
# >>> 2.1 Model
# ワード数 / トークン数: 932 / 1476
# 要約: the Transformer architecture was originally proposed by Vaswani et al. (2017) . it consists of an encoder and a decoder, each of which has two subcomponents . the encoder uses a form of self-attention, which replaces each element by a weighted average of the rest of the sequence . in our study, we explore the scalability of the Transformer model as it grows in parameters and layers .
# 独語: die Transformer-Architektur wurde ursprünglich von Vaswani et al. (2017) vorgeschlagen, wobei dieser Vorschlag von vielen anderen Entwicklern übernommen wurde. Es besteht aus einem Encoder und einem Decoder, wobei jeder von ihnen zwei Unterkomponenten hat. Dabei handelt es sich um ein kompliziertes Verfahren, bei dem die einzelnen Komponenten aufeinander gesetzt werden. der Encoder verwendet eine Form der Selbstabhängigkeit, die jedes Element durch einen gewichteten Mittelwert des Rests der Sequenz ersetzt. in unserer Studie erforschen wir die Skalierbarkeit des Transformer-Modells, wie es in Parametern und Schichten wächst.
# 仏語: L'architecture Transformer a été proposée à l'origine par Vaswani et al. (2017).. il se compose d'un encodeur et d’un décodeur, chacun ayant deux sous-composantes. le codeur utilise une forme d'auto-attention, qui remplace chaque élément par une moyenne pondérée du reste de la séquence. Dans notre étude, nous explorons la scalabilité du modèle Transformer à mesure qu'il croît en paramètres et couches.
#
#
# GPUメモリ使用量:12319MiB / 総GPUメモリ量:16280MiB
#
# >>> 2.4 Input and Output Format
# ワード数 / トークン数: 1170 / 1747
# 要約: we cast all of the tasks we consider into a “text-to-text” format . to specify which task the model should perform, we add a task-specific (text) prefix to the original input sequence before feeding it to the model . for text classification tasks, the model simply predicts a single word corresponding to the target label . we provide full examples of preprocessed inputs for every task in Appendix D .
# 独語: werfen wir alle von uns erwogenen Aufgaben in ein „Text-zu-Text“-Format um.. um zu spezifizieren, welche Aufgabe das Modell ausführen soll, fügen wir ein task-spezifisches (Text) Präfix zu der ursprünglichen Eingabesequenz hinzu, bevor wir sie an das Modell übergeben. für Text-Klassifizierungsaufgaben wird einfach ein einzelnes Wort prognostiziert, das dem Ziel-Label entspricht. geben wir in Anhang D vollständige Beispiele von vorverarbeiteten Eingaben für jede Aufgabe an, z.B. für die Erstellung eines Graphens.
# 仏語: nous faisons toutes les tâches que nous considérons dans un format « text-to-text » (« texte-à-texte »). pour spécifier la tâche que le modèle doit exécuter, nous ajoutons un préfixe (texte) spécifique à la séquence d'entrée originale avant de la soumettre au modèle. pour les tâches de classification de texte, le modèle prédit simplement un seul mot correspondant à l'étiquette cible. Nous fournissons des exemples complets d'entrées prétraitées pour chaque tâche à l'annexe D.
#
#
# GPUメモリ使用量:12921MiB / 総GPUメモリ量:16280MiB
#
# >>> 3.2.1 Model Structures
# ワード数 / トークン数: 1197 / 1778
# 要約: a major distinguishing factor for different model structures is the “mask” used by different attention mechanisms in the model . the first model structure we consider is an encoder-decoder Transformer, which consists of two layer stacks: The encoder and the decoder . in this architecture, the encoder uses a “fully-visible” attention mask, which allows a self-attention mechanism to attend to any entry of the input sequence . a causal mask is then used to prevent the model from attending to the
# 独語: Ein wesentlicher Unterscheidungsfaktor für unterschiedliche Modellstrukturen ist die „Maske“, die von verschiedenen Aufmerksamkeitsmechanismen im Modell verwendet wird. Die erste Modellstruktur, die wir betrachten, ist ein Encoder-Decoder Transformator, der aus zwei Ebenenstapeln besteht: Der encoder und der decoder. in dieser Architektur verwendet der Encoder eine „vollständig sichtbare“ Aufmerksamkeitsmaske, die es einem Selbst-Ansichtsmechanismus erlaubt, sich auf jeden Eintrag der Eingangssequenz zu beziehen.
# 仏語: l’un des principaux facteurs de différenciation entre les différentes structures du modèle est le « masque » utilisé par les différents mécanismes d’attention du modèle. la première structure de modèle que nous considérons est un encoder-décoder Transformer, qui consiste en deux stacks de couches: L'encodeur et le décodeur. Dans cette architecture, l'encodeur utilise un masque d'attention « pleinement visible », qui permet à un mécanisme d’auto-attention de se pencher sur n'importe quelle entrée de la séquence entrée.
#
#
# GPUメモリ使用量:13697MiB / 総GPUメモリ量:16280MiB
#
# >>> 3.2.2 Comparing Different Model Structures
# ワード数 / トークン数: 482 / 696
# 要約: encoder-decoder models have approximately the same number of parameters as a language model with 2L layers . however, the same L + L encoder decoder-model will have about the same computational cost as an L-layer language model . to provide a reasonable means of comparison, we will consider multiple configurations for our encoder model with different number of layers and parameters .
# 独語: Encoder-Decoder Modelle haben ungefähr die gleiche Anzahl von Parametern wie ein Sprachenmodell mit 2L Schichten. Allerdings hat das gleiche L+L-Encoder-Dekodier-Modell ungefähr die gleichen Rechenkosten wie ein L-Layer-Sprachmodell. Um einen vernünftigen Vergleich zu ermöglichen, werden wir mehrere Konfigurationen für unser Encoder-Modell mit unterschiedlicher Anzahl von Schichten und Parametern berücksichtigen.
# 仏語: Les modèles d'encoder-décoder ont approximativement le même nombre de paramètres qu'un modèle linguistique avec 2L couches. Cependant, le même modèle d'encodeur et de décodeur L + L aura à peu près le même coût de calcul qu'un modèle linguistique de couche L. pour fournir un moyen de comparaison raisonnable, nous considérerons plusieurs configurations pour notre modèle d'encodeur avec différents nombres de couches et de paramètres.
#
#
# GPUメモリ使用量:13697MiB / 総GPUメモリ量:16280MiB
結果確認
要約・翻訳結果の確認
以下は「1. Introduction」を処理して作成した、文章の要約、およびその独仏語翻訳です。この妥当性をみるため、右欄に市販ソフトを使って日本語対訳をつくりました。市販ソフト出力結果に手は加えていません。こうしてみると、要約、翻訳それぞれ妥当な内容になっているように思います。
| タスク | 処理結果 | 市販ソフトによる日本語対訳 |
|---|---|---|
| 英語要約 | a great deal of recent work has developed transfer learning methodology for NLP . in this paper, we leverage a unified approach to transfer learning that allows us to systematically study different approaches and push the current limits of the field . we evaluate performance on a wide variety of english-based NLP tasks, including question answering, document summarization, and sentiment classification . | 最近、多くの研究が NLP のための転移学習の方法論を開発してきた。 この論文では、異なるアプローチを系統的に研究し、この分野の現在の限界を押し上げることを可能にする、転移学習への統一的なアプローチを利用する。 質問応答、文書要約、感情分類など、英語ベースの様々なNLPタスクで性能を評価する。 |
| 独語翻訳 | Eine Vielzahl neuerer Arbeiten hat die Methodik des Transfer Learning für NLP entwickelt (Transfer Learning Methodology for NLP ). in diesem papier, nutzen wir einen einheitlichen Ansatz zum Transfer Lernen, dass es uns erlaubt, systematisch zu studieren verschiedene Ansätze und drücken die gegenwärtigen Grenzen des Bereichs. Wir evaluieren die Leistung bei einer Vielzahl von englischsprachigen NLP-Aufgaben, einschließlich Fragebeantwortung, Dokument-Summarisierung und Sentiment-Klassifizierung. | 近年、多くの研究が行われ、NLPのための転移学習法が開発された。 本論文では、異なるアプローチを体系的に研究し、この分野の現在の境界を押し広げることを可能にする、転移学習への統一的なアプローチを使用します。 質問応答、文書要約、感情分類など、様々な英語NLPタスクで性能を評価する。 |
| 仏語翻訳 | Un grand nombre de travaux récents ont mis au point une méthodologie d'apprentissage par transfert pour le PNL. Dans cet article, nous utilisons une approche unifiée du transfert de l’apprentissage qui nous permet d’étudier systématiquement différentes approches et de repousser les limites actuelles du domaine. Nous évaluons la performance sur un large éventail de tâches NLP basées sur l'anglais, y compris la réponse à des questions, la synthèse de documents et la classification des sentiments. | 最近の多くの研究は、NLPのための転移学習の方法論を開発している。本論文では、異なるアプローチを体系的に研究し、この分野の現在の境界を押し広げることを可能にする、転移学習への統一的なアプローチを使用します。質問応答、文書要約、感情分類など、英語ベースの自然言語処理タスクの性能を幅広く評価する。 |
GPUメモリ使用量の確認
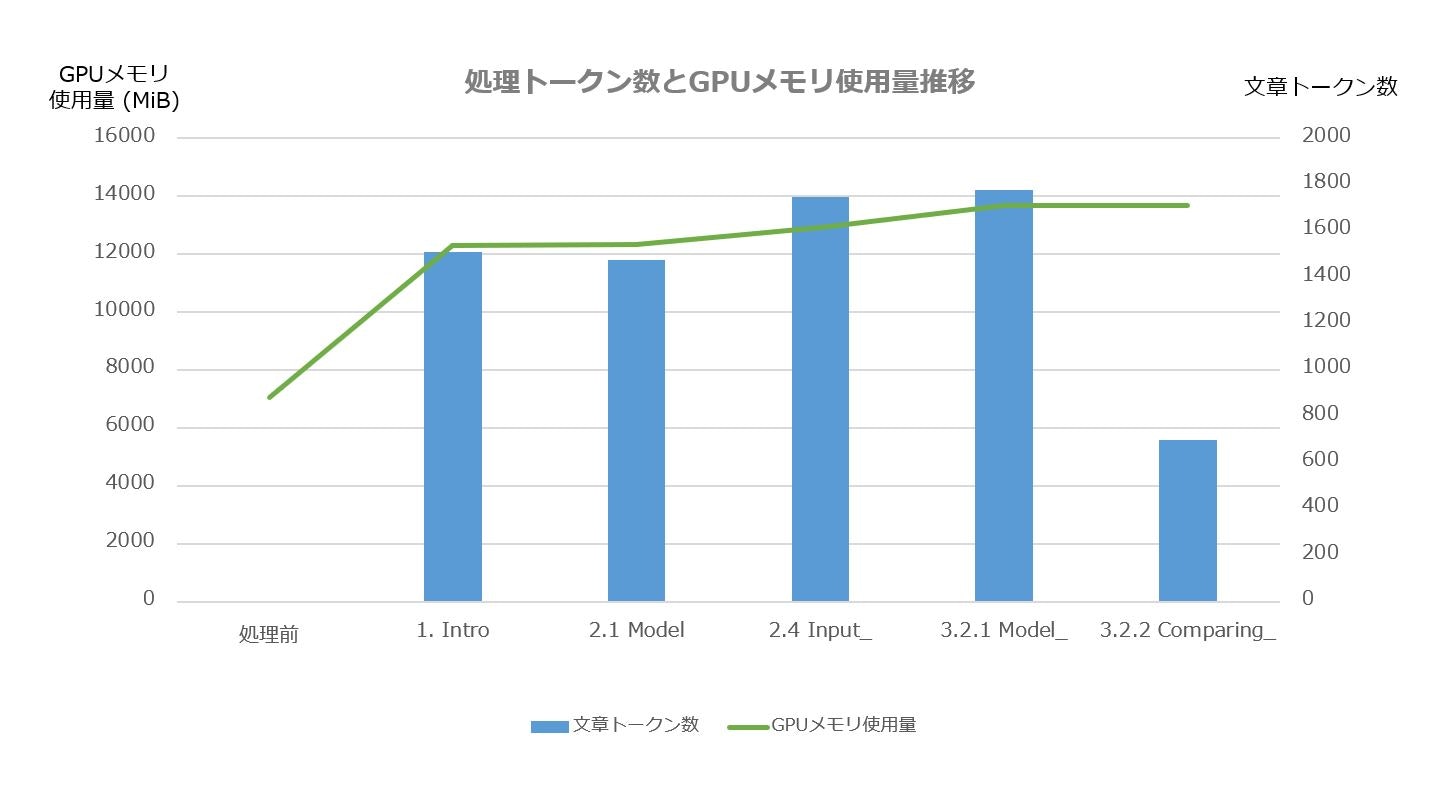
入力文書の5つの章を処理した際のGPUメモリ使用量の推移をグラフ化しました。GPUメモリ使用量は最もトークン数の多い文章処理で決まるようです。それまで処理したトークン数よりも多い場合GPUメモリ使用量は増え、それまでよりも少ないとGPUメモリ使用量は変わりません。ここでの最大トークン数1778のところで GPU メモリ使用量も最大の13697MiB となりました。その後、同じ処理をもう一度やってみても、このGPUメモリ使用量のまま変わりませんでした。
ここでは、Tesla P100-PCIE を使っていますが、ここで使った入力の場合は GPU メモリ使用量が14000MiB 未満ですので、GPU メモリ容量が15109MiB の Tesla T4でも動作します。
まとめ
以上により、モデルロード時に torch_dtype=torch.float16 を指定することで、t5-3b で要約タスクと翻訳タスクをマルチタスクで動作させてもトークン数が2048以下程度であれば、GPU メモリは余裕をもって動作できることが確認できました。
出力の妥当性については、要約タスクでは 3.2.1 Model Structures に対する出力が途中で切れたり、翻訳タスクでは 2.4 Input and Output Format に対する独語翻訳が一部おかしかったりと、完ぺきとは言えません。しかし、例えば、t5-3b の要約タスクを英語論文読みの助けに使うように、作業の補助としてなら使えそうに思いました。
例として、T5論文のAppendixと図表以外を上記要約タスクで要約した T5論文要約版をつくりました。元の論文18761ワードが要約版で2045ワードになったので約10分の1のサイズになりました。一部完全な文章になっていない箇所がありますが、この要約版であたりをつけて元論文を読むといった活用もできそうです。