chiVe, chiTra の利用を考えているが、そもそも単語分散表現や事前学習済みモデルとは?という方向けに、単語分散表現や事前学習モデルのイメージをつけていただくシリーズのPart2です。
Part1で、計算機で単語の "意味" を扱うイメージをつけるために、one-hotベクトル と 共起頻度行列 を取り上げました。
共起頻度行列によって単語の "意味" を捉えられそうだが、語彙数分の次元が必要になるなど実利用の上では課題がありそうだというお話をしました。
Part2では、chiVe が利用している word2vec を取り上げます。
Part1:単語の "意味" を計算機で扱うイメージをつける
Part3:BERT
word2vec
word2vecは2013年にMikolovらによって提案されました(元論文:Efficient Estimation of Word Representations in Vector Space)。
理論の詳細に関してはより詳しい解説記事や元論文を追っていただくことにして、本記事ではイメージをつけていただくことを目標とします。
word2vecには CBOW と Skip-gram という二つのアーキテクチャが存在し、以下の図(元論文から拝借)のように示されます。
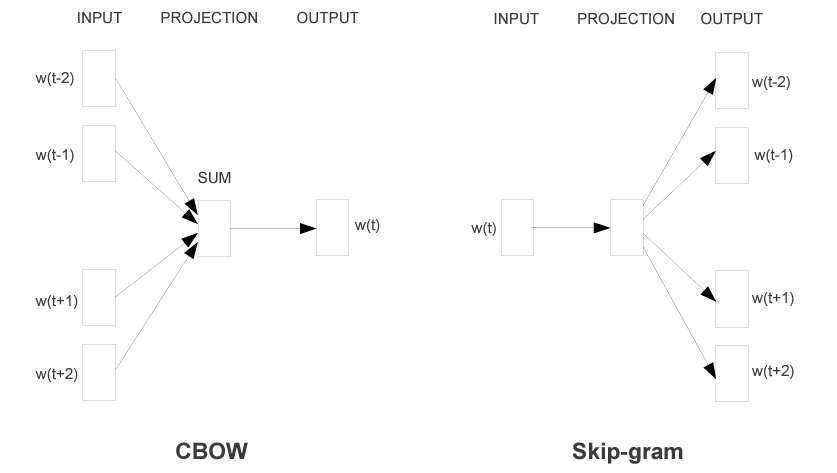
CBOW は、周辺語(図左のINPUT側; w(t-2), w(t-1), w(t+1), w(t+2))から対象語(図左のOUTPUT側; w(t))を推定する過程で単語の "意味" を埋め込んだベクトルを獲得する手法です。
Skip-gram は、対象語(図右のINPUT側; w(t))から周辺語(図右のOUTPUT側; w(t-2), w(t-1), w(t+1), w(t+2))を推定する過程で単語の "意味" を埋め込んだベクトルを獲得する手法です。
例えば、以下のような一部が ??? で隠された3文があった場合、word2vec(CBOW)は周辺語から ??? に入る語を推定し、その過程で "意味" を埋め込んだベクトルを獲得します。

word2vec のよさ
様々あると思いますが、ここでは2点紹介します。
固定次元に密に情報が埋め込まれている
前回の記事で、共起頻度行列による単語ベクトルは、文書中に出現する 単語-単語 間の全ての共起頻度を持つ必要があるため、多くの値がゼロというスパースな状態で一単語を表すのに巨大な次元が必要(chiVe v1.2 mc5の語彙数とすると300万次元!)となり、非現実的であるというお話をしました。
word2vecでは、密に値が埋め込まれており、chiVeの場合は300次元で与えられます。共起頻度行列などと比べ、格段に使いやすくなっています。
更新が容易
共起頻度行列などでは、新語への対応をしたいと思った際には全単語-単語間の共起頻度を再計算し直す必要があり、更新が煩雑でした。
word2vecにおいて、新語への対応を行うには、それを含む文を与えて推定を行えば対応する事ができます。
具体的な方法を知りたい方は、gensimでの再学習法のドキュメントである こちら などをご参照ください。
word2vecの課題
一方で課題もあります。ここでは、2点紹介します。
学習時に見られる文脈の限界
word2vecの学習では、周辺語(文脈)の情報を利用して対象語のベクトルを獲得しますが、入力文全体は見ておらず、窓幅(以下図では 窓幅 = 2 )を指定して、その範囲の単語を語順を考慮せずに利用し推定するものとなっています。
そのため、本当は推定に有用であろう語が、対象語から離れた位置にあるために学習に考慮されないということが起こりそうです。

多義性を考慮できない
word2vecでは、1単語に1つのベクトルが付与されます。
そのため、多義語に対しても1つの "語義" しか表現する事ができません。
ここで、ワークスが開発している chiVe 上で多義語の挙動を確認してみましょう。
モデルを こちら からダウンロードし(ここでは、v1.2 mc90 のモデルを利用します)、gensimというライブラリで読み込んでtargetの語の近傍を見てみます。
# モデルのロード
# (gensimというライブラリが必要です。インストールされていない場合は `pip install gensim` でインストールしてください。)
import gensim
vectors = gensim.models.KeyedVectors.load("chive-1.2-mc90_gensim/chive-1.2-mc90.kv")
# targetの語の近傍を検索
target = "マック"
vectors.most_similar(target)
# [('マクド', 0.7141627073287964),
# ('マクドナルド', 0.6885151863098145),
# ('モスバーガー', 0.6016820669174194),
# ('ロッテリア', 0.5896010994911194),
# ('MAC', 0.5882739424705505),
# ('ハンバーガー', 0.5843257308006287),
# ('バーガー', 0.5826560258865356),
# ('ミスド', 0.5790222883224487),
# ('フレッシュネス', 0.5472289323806763),
# ('デニーズ', 0.5406960844993591)]
chiVeで "マック" という単語(マクドナルドとしての "マック" と Apple製品としての "マック" を想定)と類似度の高い単語上位を見てみると、マクドナルドとしての "マック" の意味が強いことがわかります。
これは、学習コーパスであるNWJC内にマクドナルドの意として多く出現しているためと考えられます。
この多義性を捉えられないことは、実利用をする上で問題となることがあるでしょう。
Part2. まとめ
「chiVe / chiTra 利活用に向けて」の Part2 として、word2vecを紹介しました。
共起頻度行列において問題として挙げた、次元数の問題や新語への対応の煩雑さを解決し、利用しやすくなっていることがわかりました。
一方で、学習方法の課題や多義性を捉えられない実用上の問題などがあることもわかりました。
次回のPart3では、word2vecの約5年後に登場し、現在の深層学習の流れに大きく影響を与えたBERTを紹介します。
Part3 はこちら