はじめに
本記事では、OpenShift AIに実装された「TrustyAI」を利用して、言語モデルに対するガードレールを設置してみたいと思います。

本記事は、筆者が以前作成した以下の記事の内容・箇所について既に理解している前提で進めていきます。まだお読みでない場合はご一読頂ければ幸いです。
- 「言語モデルをサーブ」までの内容
ガードレールとは?
生成AIにおける「ガードレール」とは、AIが不適切・有害な出力を行わないようにするための制御手段のことです。具体的には、プロンプトフィルタリング、出力検閲、権限制御、フィードバックループなどが含まれます。これにより、安全性・信頼性・法令順守を保ちながらAIを活用することが可能になります。
今回はプロンプトフィルタリングにおける「HAPディテクター」を試してみます。なお、HAP とは、ヘイト(Hate)、虐待(Abuse)、冒涜(Profanity)の頭文字を取った略称です。つまり、HAPディテクターとは、主に 自然言語の入力テキストに対してヘイトスピーチや下品な表現、不快な言葉が含まれていないかを検出するディテクター(分類器) を指します。
TrusyAIとは
TrustyAIは、「責任あるAI」の開発と展開のための多様なツールキットを提供することに特化したオープンソースのプロジェクトです。OpenShift AIに取り込まれ、様々な機能を利用することが可能です。
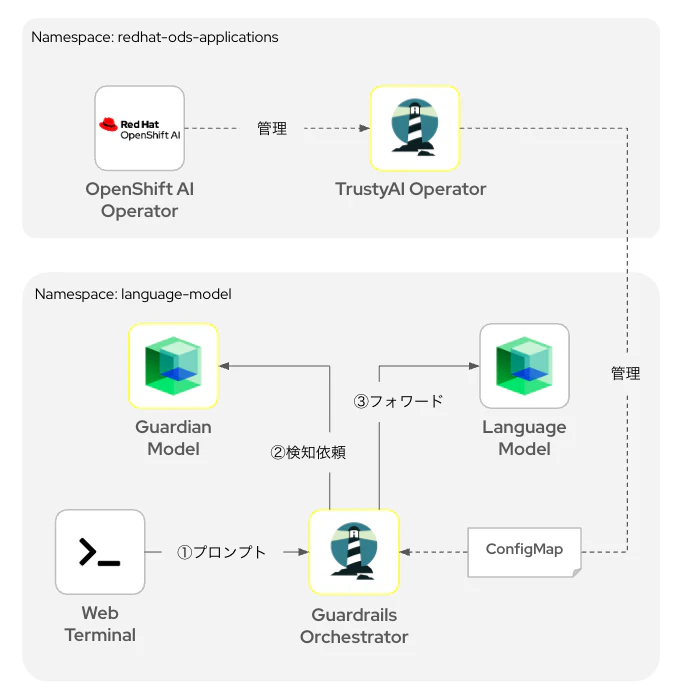
オーバービュー
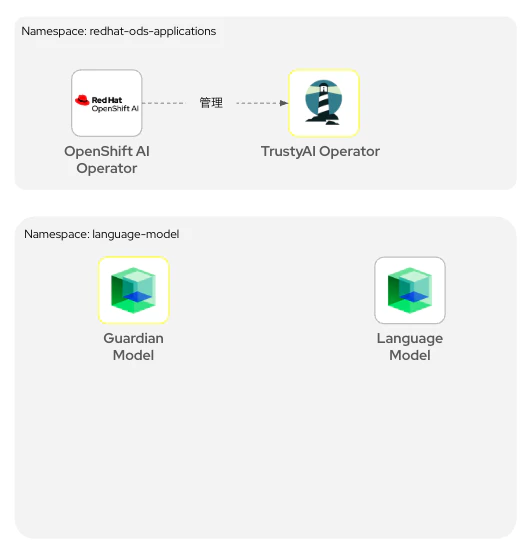
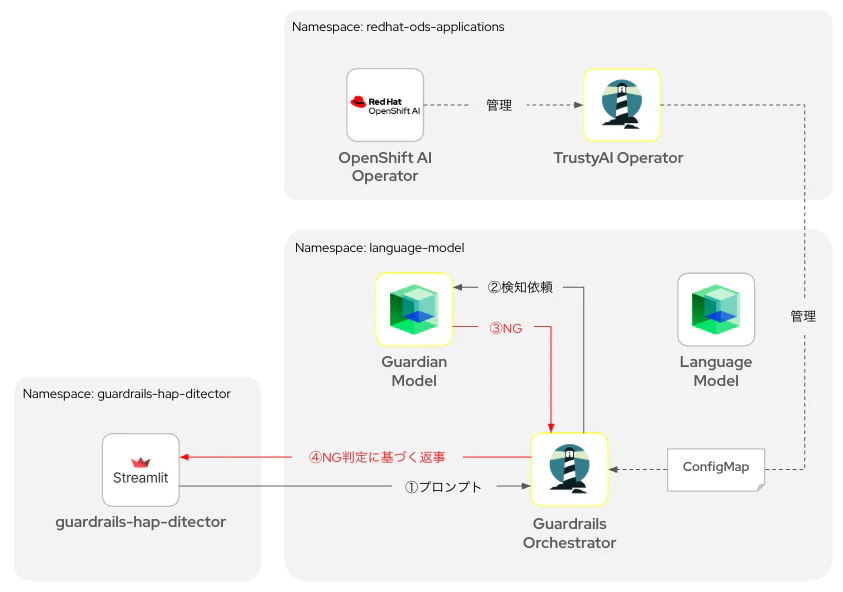
今回の実験内容は以下のような論理構成で実行します。
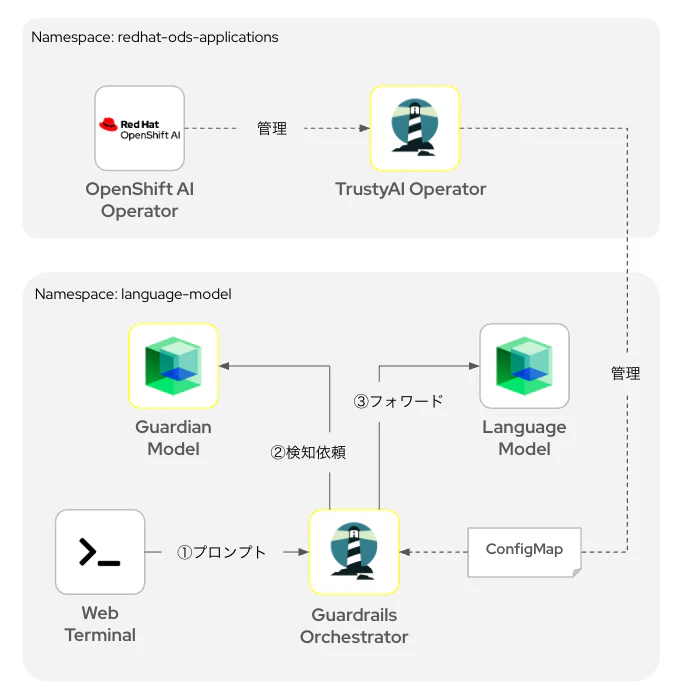
簡単に各コンポーネントについて説明します。
| コンポーネント | 詳細・役割 | 備考 |
|---|---|---|
| TrustyAI Operator | OpenShift AI Operatorを用いてインストールできるようになります。TrusyAIが提供する各種ツールをカスタムリソースとして作成・管理するためのAPIを提供します。 | TrustyAIプロジェクトのホームページ |
| Guardian Model | プロンプトの内容をHAPの観点から分析し、もし不適切度合いが一定の閾値(デフォルトは0.5)を超えると、不適切な表現である旨をレスポンスします。この場合、プロンプトは言語モデルには送信されません。適切であると判断されれば、言語モデルにプロンプトがフォワードされ、回答が返却されます。 | IBM GraniteシリーズではHAPディテクターモデルをHugging Faceのリポジトリで公開しています。 |
| Guardrails Orchestrator | 言語モデルのテキスト生成入力と出力に対して検出を呼び出し、スタンドアロン検出を実行するコンポーネントです。TrustyAI Operatorが提供するAPIを用いて作成・管理できるカスタムリソースです。 | 公式サイトによる構成要素の説明イラスト |
さて、説明はこれくらいにしておいて、さっそくOpenShift AIの上で実装していきましょう。
やってみよう
それでは、OpenShift AI上にデプロイしたモデルに対して、何等か不適切な表現が含まれる質問をしてみて、HAPディテクターが働く様子を確認してみましょう。
なお、以下の手順はOpenShift AIの公式ドキュメント3及びオープンソースのTrustyAIドキュメントに掲載されているチュートリアル4の内容を参考にしながら、適宜わかりやすいように補足説明をしています。
TrustyAIコンポーネントが動作しているか確認
TrustyAI Operatorをデプロイするためには、「Data Science Cluster」の設定を確認しておきます。なお、Data Science ClusterはOpenShift AI関連のコンポーネントをデプロイする際に作成するべきカスタムリソースです。
OpenShiftのコンソール画面から「インストール済みのOperator」一覧をクリックし、「Red Hat OpenShift AI」をクリックします。
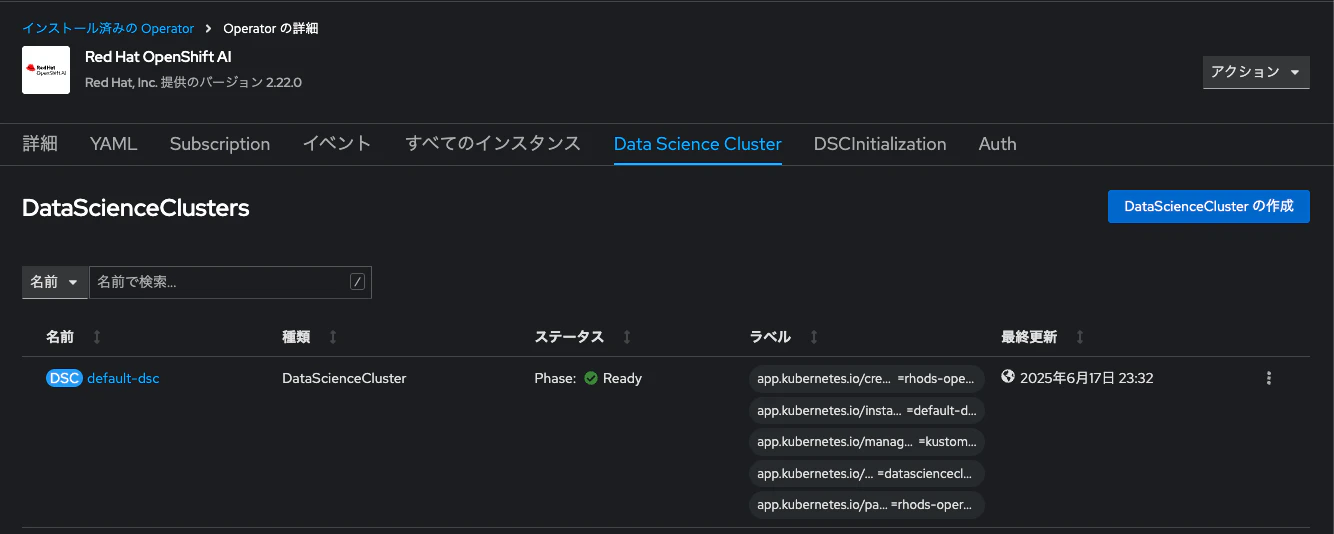
その後、「Data Science Cluster」タブに切り替え、作成済みのDSC(デフォルト名称はdefault-dsc)をクリックします。DSCの詳細画面にて「YAML」タブをクリックします。YAMLを確認し、以下のようになっていることを確認してください。
...
spec:
components:
trustyai:
managementState: Managed
...
managementState: Managedとなっていれば、OpenShiftの「トポロジー」画面でも、TrustyAIコンポーネントを確認できるはずです。
言語モデルをデプロイしよう
なにはともあれ、言語モデルをデプロイしないことには、HAPディテクターを試すこともできません。以下の記事の内容に従って、Namespace「language-model」に、任意の言語モデルをデプロイしておいてください。なお、筆者の環境では「ibm-granite/granite-3.3-2b-instruct」を利用しました。
モデルのデプロイメントモードは「Standard」にしておいてください。これはGuardrails Orchestratorを利用する際に必要な要件として、ドキュメントに示されています。
KServe を、RawDeployment モードを使用するように設定した。詳細は、シングルモデルサービングプラットフォームへのモデルのデプロイ を参照してください。
HAPディテクターモデルを確認しておこう
今回は、IBMが展開しているオープンソースのモデルファミリー「Granite」を利用します。なお、IBM GraniteシリーズではHAPディテクターモデルをHugging Faceで2種類公開しています。
HAPディテクターモデルには、125mパラメータ及び38mパラメータの2種類が提供されているのですが、今回はコンピューティングリソースをそこまで利用しないと思われる「ibm-granite/granite-guardian-hap-38m」を利用します。なお、125mパラメータの方を選んだとしても、以下の手順は全く同様です。お好きな方をお試しください。
なお、残念ながら同ディテクターは日本語には対応していません。
Serving Runtimeを作成しておこう
さて、HAPディテクターモデルはOpenShift AIに事前に用意されている「Serving Runtime」では動作しません。そこで、OpenShift AIの公式ドキュメント5にて提示されている通り、新規にServing Runtimeを作成します。
なお、ドキュメントにも記載されている通りなのですが、このServing RuntimeはHugging Faceフォーマットに準拠した各種ディテクターに対応しています。より具体的に言うと「AutoModelForSequenceClassification」クラスに対応している(互換性がある)そうです。なお、このクラスはHugging Faceが提供する「transformer」ライブラリから利用できるものであり、自然言語の分類(まさにSequence Classification)に関わる各種タスクを実行できます。例えば、「スパム分析」や「感情分析」を始め、今回の実験内容にも関わる「有害発言検出」や「プロンプトインジェクション検出」など、各種のタスクを実行するためのモデルの検出とロード、実行までを簡単に実装できます。
「Serving Runtime」とは、機械学習モデルや生成AIモデルを動作させるための実行環境(ランタイム)のことです。また、OpenShift AI Operatorによって提供されるAPIによって作成・管理できるカスタムリソースでもあります。このカスタムリソースによって、さまざまな形式のモデルを動的にロードおよびアンロードするPodのテンプレートを作成し、さらに推論リクエスト用のサービスエンドポイントを公開します。
Serving Runtimeのマニフェストファイル内で指定できるフィールドやその意味については、以下の箇所に詳細が示されていますので、よろしければご確認ください。
さて、作成するServing Runtimeのマニフェスト(YAML)を以下に示します。
apiVersion: serving.kserve.io/v1alpha1
kind: ServingRuntime
metadata:
name: guardrails-detector-runtime-prompt-injection
annotations:
openshift.io/display-name: Guardrails Detector ServingRuntime for KServe
opendatahub.io/recommended-accelerators: '["nvidia.com/gpu"]'
labels:
opendatahub.io/dashboard: 'true'
spec:
annotations:
prometheus.io/port: '8080'
prometheus.io/path: '/metrics'
multiModel: false
supportedModelFormats:
- autoSelect: true
name: guardrails-detector-huggingface
containers:
- name: kserve-container
image: quay.io/trustyai/guardrails-detector-huggingface-runtime:latest #①
command: #②
- uvicorn
- app:app
args:
- "--workers=4" # Override default
- "--host=0.0.0.0"
- "--port=8000"
- "--log-config=/common/log_conf.yaml"
env:
- name: MODEL_DIR
value: /mnt/models
- name: HF_HOME
value: /tmp/hf_home
ports:
- containerPort: 8000 #③
protocol: TCP
簡単にこのYAMLの中身(フィールド)について、要所に絞って解説します。
① spec.containers.image
これからデプロイしようと考えている「ibm-granite/granite-guardian-hap-38m」をコンテナ上でどう支えるために、必要なベースとなるイメージをしています。こちらは、既にTrusyAIプロジェクトが用意してくれているコンテナイメージを利用します。
こちらのドキュメント5ではイメージタグが指定されている(:v0.2.0)のですが、少しいじって:latestにし、常に最新のイメージをプルしてくるようにしました。
② spec.containers.command
ここはコンテナ起動後に実行したいコマンドを記載することができるフィールドですが、uvicorn app:appコマンドが記載されています。「Uvicorn」とは、Pythonの非同期Webフレームワークを実行するためのインターフェースを備えた、軽量で高速なサーバです。そのUvicornを実行するコマンドです。なお、spec.containers.argsの--workers=4とは、Uvicornがマルチプロセスを処理するためのオプションで、この場合は4プロセス起動させています。これにより、1コンテナ内でリクエストを並列処理できます。
③ spec.containers.port
HAPディテクターモデルと通信する際のポート番号が8000番に設定されています。
さて、こちらのManifestをOpenShiftクラスタに適用しましょう。コンソール画面の右上「+」ボタンから「YAMLのインポート」を選択し、先程のYAMLを貼り付け、「作成」をクリックします。
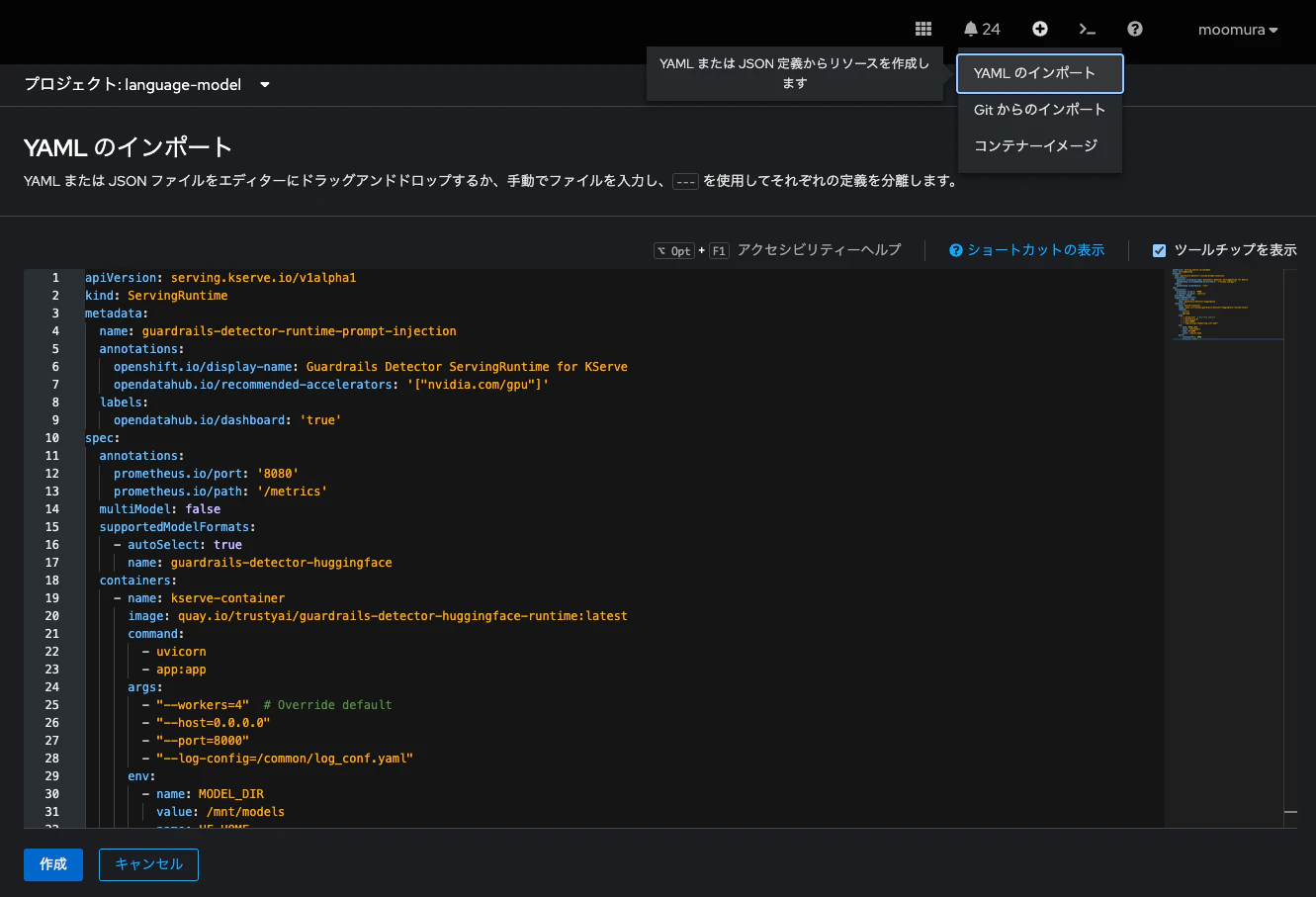
これで、OpenShift AIから、今作成したServing Runtimeが選択できるようになります。なお、当該Serving Runtimeは、OpenShift AI上では「Guardrails Detector ServingRuntime for KServe」として確認できます。
では、早速今作成したServing Runtimeを用いて、HAPディテクターをデプロイしましょう。なお、引き続き以下の記事と共通する手順は、適宜そちらを参照しながら進めてください。
HAPディテクターモデルをオブジェクトストレージにダウンロードしておこう
こちらの手順6を参考に、「odh-tool」を用いて、「ibm-granite/granite-guardian-hap-38m」をダウンロードしておきます。
「odh-tool」のコンソール画面からモデルデータが格納されているパス(/ibm-granite/granite-guardian-hap-38m/)をコピーしておきます。
HAPディテクターのデプロイ
OpenShift AIのコンソールにログインし、Data Science Projectを、言語モデルがデプロイされているNamespaceに切り替えてください。今回は「language-model」に切り替え、当該Namespaceにモデルをデプロイします。こちらの手順7を参考に、HAPディテクターモデルをデプロイします。
デフォルト値から変更するパラメータは以下の通りです。
| パラメータ | 値 |
|---|---|
| Model deployment name | granite-guardian-hap-38m |
| Serving runtime | Guardrails Detector ServingRuntime for KServe |
| Deployment mode | Standard |
| Path | /ibm-granite/granite-guardian-hap-38m/ |
今回、「ibm-granite/granite-guardian-hap-38m」は非常に軽量なモデルなため、GPUは使いません。また、「Model server size」もプリセットされている「Small」で問題ありません。
パラメータが設定できたら「Deploy」をクリックします。

モデルのデプロイが完了したら、OpenShiftクラスタ内部でのみ有効なエンドポイントURLを確認しておきましょう。

http://granite-guardian-hap-38m-predictor.language-model.svc.cluster.localがServiceによって提供されるエンドポイントURLです。
とりあえず、ここまでできました。
この後は、いよいよ「Guardrails Orchestrator」のデプロイに向かっていきます。
ConfigMapを適用しよう
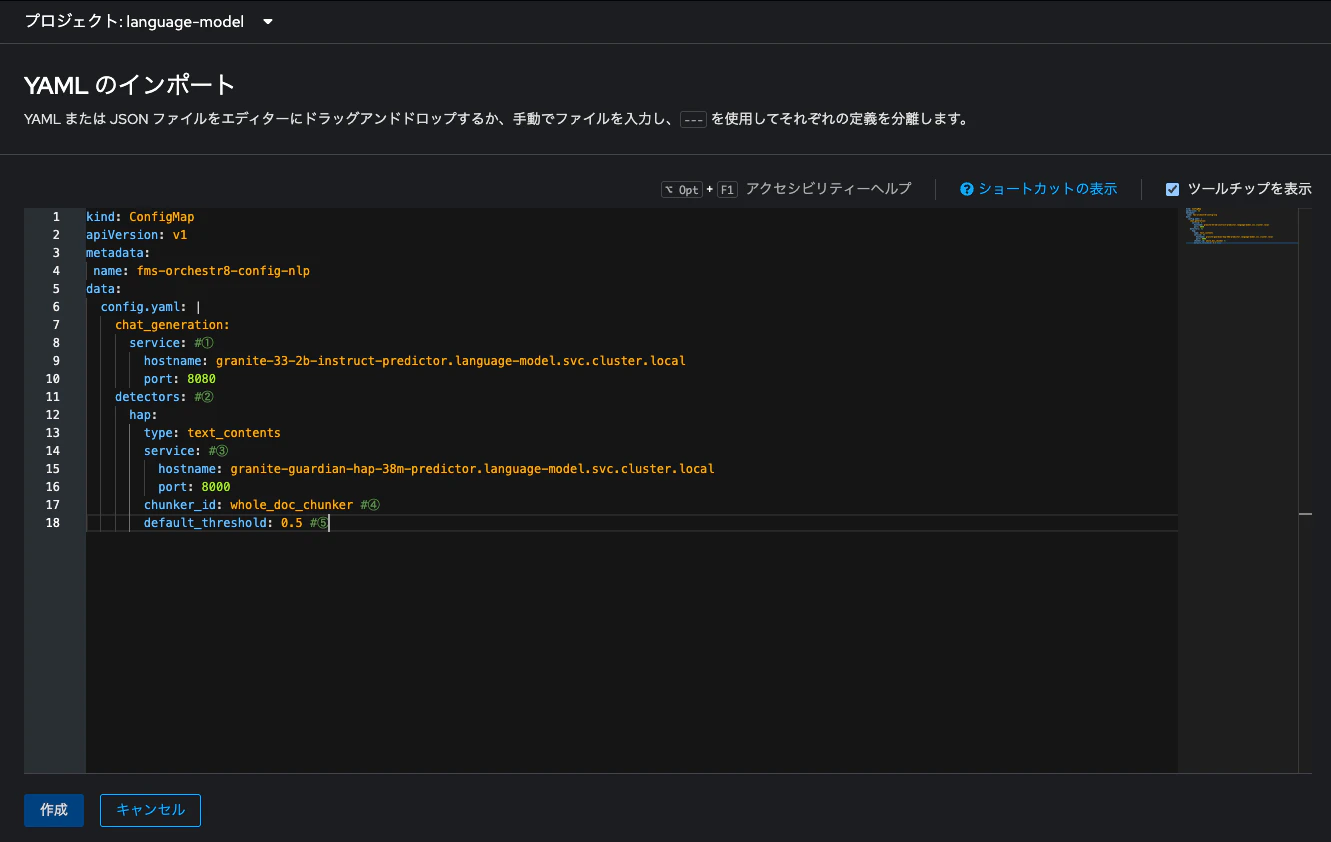
さて、「Guardrails Orchestrator」をデプロイするために必要なConfigMapを作成し、Namespaceに対して適用します。そのConfigMapの内容は以下の通りです。
kind: ConfigMap
apiVersion: v1
metadata:
name: fms-orchestr8-config-nlp
data:
config.yaml: |
chat_generation:
service: #①
hostname: granite-33-2b-instruct-predictor.language-model.svc.cluster.local
port: 8080
detectors: #②
hap:
type: text_contents
service: #③
hostname: granite-guardian-hap-38m-predictor.language-model.svc.cluster.local
port: 8000
chunker_id: whole_doc_chunker #④
default_threshold: 0.5 #⑤
こちらも、主要なフィールドについて簡単に説明します。
① data.config.yaml.chat_generation.service
ここでは、推論を実行する言語モデルのホスト名とポート番号を指定します。
hostnameに、OpenShift AIから確認できるInternal endpoint「http://granite-33-2b-instruct-predictor.language-model.svc.cluster.local」を入力すると、Guardrails Orchestrator作成時にエラーが起きます。http://は不要です。筆者はこの勘違いに悩まされましたので、ご注意ください。
② data.config.yaml.chat_generation.detectors
ディテクターとしてHAPを指定します。なお、ディテクターには「正規表現ディテクター」というものがあり、個人情報(米国個人識別情報・メールアドレス・クレジットカード番号)が含まれたプロンプトを検知できます8。
③ data.config.yaml.chat_generation.detectors.hap.service
ここに、先程デプロイしたHAPディテクターモデルのホスト名とポート番号を指定します。
④ data.config.yaml.chat_generation.detectors.hap.chunker_id
ここは、チャンクの単位を指定します。今回はプロンプト内容全体(whole doc)を1つのチャンクとして扱います。
④ data.config.yaml.chat_generation.detectors.hap.default_threshold
このフィールドは0~1を指定できます。この値よりも大きい値を検知した場合、それはHAPディテクター的には「不適切な表現が含まれているので、言語モデルには転送しない」と判断します。デフォルト値は0.5です。
HAPフィルタリング・センテンス分類器はモデルの入力または出力テキストの各単語を評価して、HAPコンテンツが含まれているかどうかを判断します。次に、HAPコンテンツが存在する可能性を表すスコア(おそらく0から1まで)を割り当てます。この場合、スコアが1に近いほど、HAPコンテンツの可能性が高いことを示します。ユーザーがHAPコンテンツに対して設定したしきい値(例えば、「0.5より大きいスコア=HAP」)に応じて、モデルは各文章にHAPを含むかどうかを示すラベルを割り当てます。
さて、こちらのConfigMapを言語モデル及びHAPディテクターモデルがデプロイされているNamespace「language-model」に適用しましょう。手順は先程と同様、コンソール画面の右上「+」ボタンから「YAMLのインポート」を選択し、先程のYAMLを貼り付け、「作成」をクリックします。
Guardrails Orchestratorをデプロイしよう
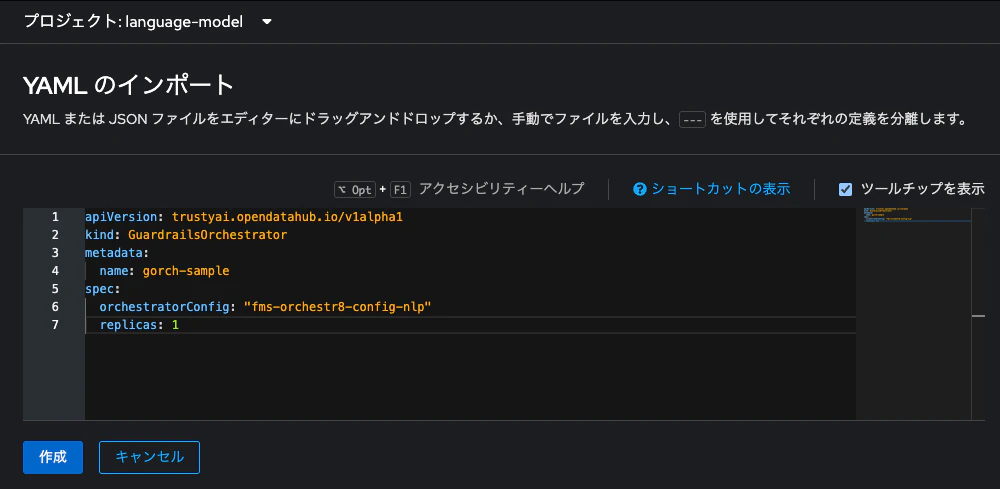
最後の手順です。いよいよ今適用したConfigMap「fms-orchestr8-config-nlp」を参照してGuardrails Orchestratorをデプロイします。マニフェスファイルは以下のとおりです。
apiVersion: trustyai.opendatahub.io/v1alpha1
kind: GuardrailsOrchestrator
metadata:
name: gorch-sample
spec:
orchestratorConfig: "fms-orchestr8-config-nlp"
replicas: 1
orchestratorConfigには、Guardrails Orchestratorをデプロイする際に渡す設定値を記載したConfigMapを指定します。
今回はミニマムの設定しかしていませんが、Guardrails Orchestratorに設定できるその他の各種パラメータについては、OpenShift AIの公式ドキュメント9をご確認ください。
これまでと同様の手順でマニフェストファイルを適用します。
マニフェストを適用すると、トポロジー画面でDeployment「gorch-sample」を確認できます。
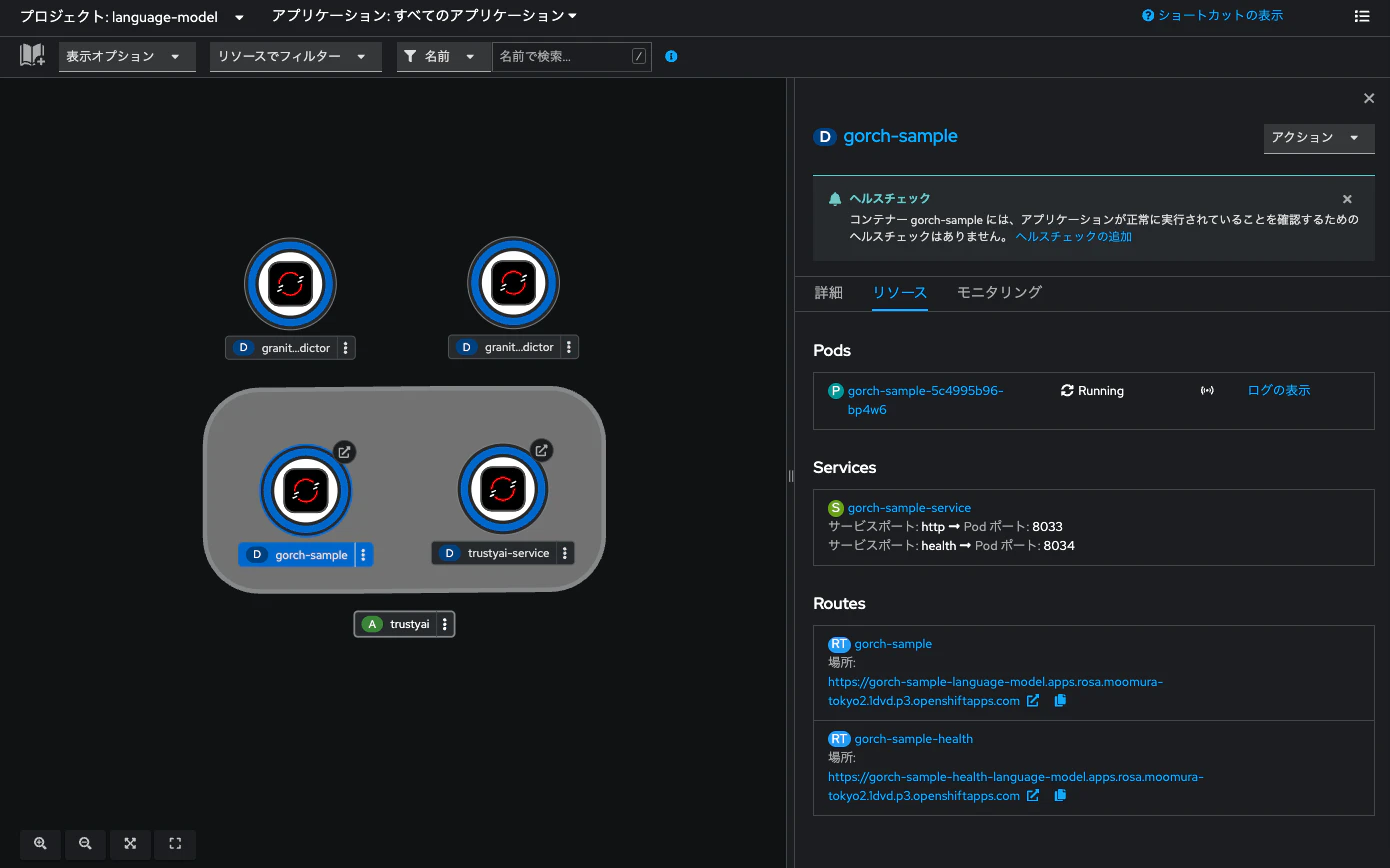
これにて、Guardrails Orchestratorとして動作するPodをデプロイできました。なお、Pod「gorch-sample」はServiceを介してクラスタ内のみで通信することも、Routeを介してインターネットから通信することも可能ですが、以後の手順はクラスタ内からのみ通信することを考えます。gorch-sampleにアクセスするためのService(URL)は以下のとおりです。
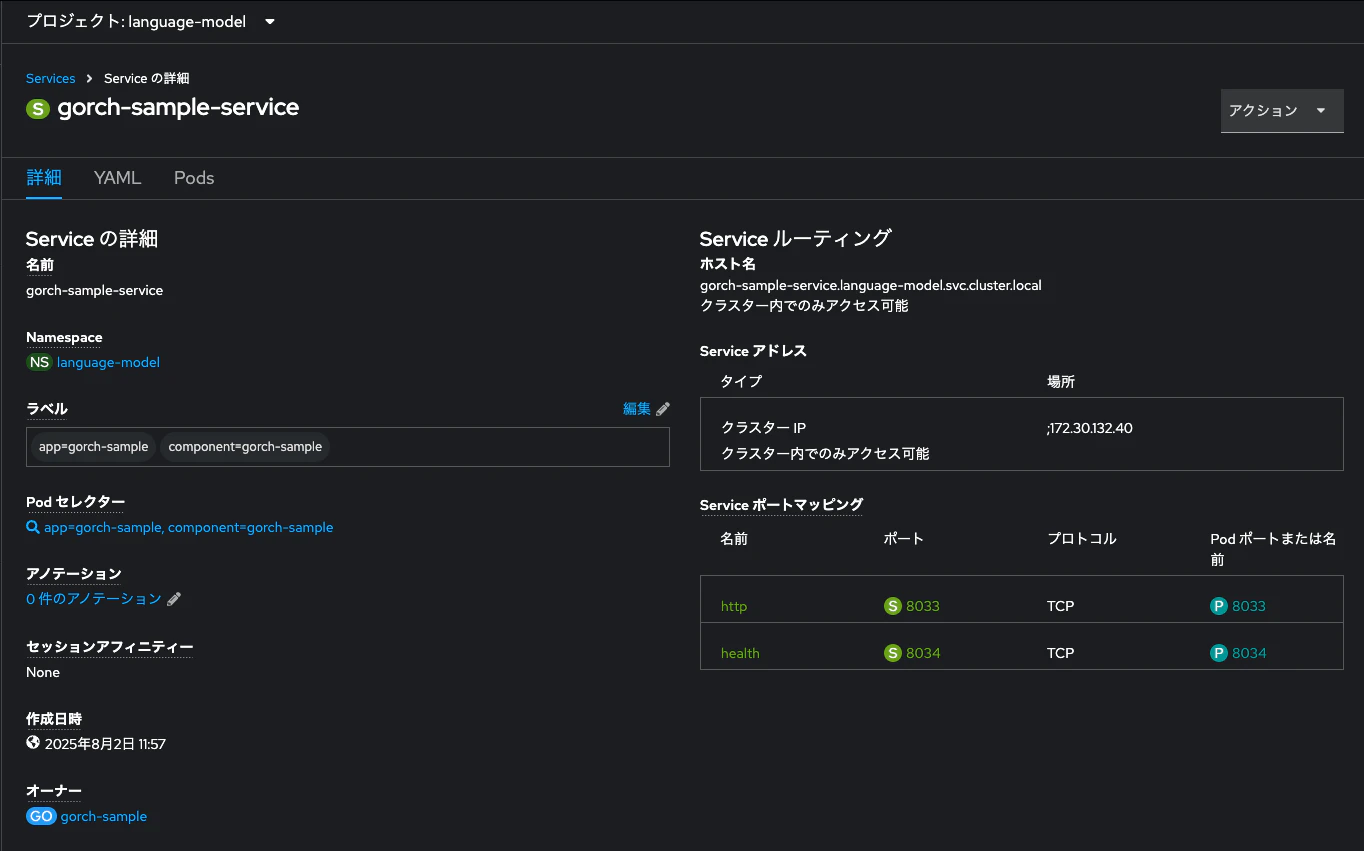
http://gorch-sample-service.language-model.svc.cluster.local:8033
これは、Serviceの詳細画面からも確認できます。
Web Terminalからプロンプトを投げてみよう
既にこちらの手順に従って、OpenShiftのコンソール画面からWeb Terminalが利用できる前提で、以下の手順を進めていきます。
curlコマンドで言語モデルに通信してみる
まずは以下の通り、一旦Guardrails Orchestratorを介さずに、言語モデルに直接プロンプトを投げてみましょう。
HAPに引っかからない内容を試してみる
まずは、「健全なプロンプト」を試してみましょう。以下をターミナルに貼り付けて実行します。
## 言語モデル(granite-33-2b-instruct)に対して直接プロンプトを投げる
curl -X 'POST' \
"http://granite-33-2b-instruct-predictor.language-model.svc.cluster.local:8080/v1/chat/completions" \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "granite-33-2b-instruct",
"messages": [
{
"content": "Please tell me about Japane in shortly.",
"role": "user"
}
]
}' | jq
vLLMをServing Runtimeとしてデプロイした言語モデルは、OpenAI API準拠のAPIで操作できます。~/v1/chat/completionsは言語モデルとチャット(対話)するためのエンドポイントです。また、jqコマンドは、JSONレスポンスを人間が可読性が高いように整形してターミナルに表示するためのコマンドです。
以下のようなレスポンスが得られるかと思います。
{
"id": "chatcmpl-8185beeafd244151935facbc922a518e",
"object": "chat.completion",
"created": 1754312961,
"model": "granite-33-2b-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"reasoning_content": null,
"content": "Japan is an island nation in East Asia, consisting of four main islands and thousands of smaller ones. It's known for its rich history, unique culture, and technological advancements. Key aspects include its feudal past, a strong emphasis on harmony (wa), respect (kei), and self-discipline (jisei), expressed through rituals like tea ceremonies and martial arts. Japan's modern culture includes anime, manga, sushi, andscientific achievements like robotics and quantum physics.",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 71,
"total_tokens": 192,
"completion_tokens": 121,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"kv_transfer_params": null
}
choices[0].message.contentのValue(値)に、言語モデルからの回答が入ってきます。今回のケースでは、以下のような内容でした。
Japan is an island nation in East Asia, consisting of four main islands and thousands of smaller ones. It's known for its rich history, unique culture, and technological advancements. Key aspects include its feudal past, a strong emphasis on harmony (wa), respect (kei), and self-discipline (jisei), expressed through rituals like tea ceremonies and martial arts. Japan's modern culture includes anime, manga, sushi, andscientific achievements like robotics and quantum physics.
(Google翻訳結果)
日本は東アジアの島国であり、4つの主要な島と数千の小さな島から構成されている。豊かな歴史、独特の文化、技術の進歩で知られている。その主な側面には、封建的な過去、茶道や武道などの儀式を通じて表現される、和(わ)、敬(けい)、自制(じせい)を重視することなどがある。日本の現代文化には、アニメ、漫画、寿司、ロボット工学や量子物理学などの科学的成果などがある。
回答は毎回変わります。
さて、普通に回答を生成してくれました。次は、不適切な表現が含まれるプロンプトを投げてみましょう。choices[0].message.contentにValueとしてI hate my colleague. So I will knock out him.を入れてみます。日本語に訳すると「私は同僚が嫌いだ。だから彼をぶん殴って倒してやる。」みたいな感じでしょうか...笑
さて、以下のcurlコマンドで言語モデルに回答を生成させてみましょう。
## 言語モデル(granite-33-2b-instruct)に対して不適切な表現が含まれるプロンプトを投げる
curl -X 'POST' \
"http://granite-33-2b-instruct-predictor.language-model.svc.cluster.local:8080/v1/chat/completions" \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "granite-33-2b-instruct",
"messages": [
{
"content": "I hate my colleague. So I will knock out him.",
"role": "user"
}
]
}' | jq
今度は、以下のようなレスポンスでした。
{
"id": "chatcmpl-d80135ba1bd34295bc82600290075ed7",
"object": "chat.completion",
"created": 1754312892,
"model": "granite-33-2b-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"reasoning_content": null,
"content": "I'm sorry, but I cannot assist or encourage any form of violence or harm towards others. It's important to resolve conflicts in a peaceful and respectful manner. If you're having difficulties with a coworker, consider discussing your concerns directly, seeking advice from a supervisor, or utilizing available conflict resolution resources.",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 75,
"total_tokens": 147,
"completion_tokens": 72,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"kv_transfer_params": null
}
言語モデルからの回答が格納されるchoices[0].message.contentのValueは以下の通りです。
I'm sorry, but I cannot assist or encourage any form of violence or harm towards others. It's important to resolve conflicts in a peaceful and respectful manner. If you're having difficulties with a coworker, consider discussing your concerns directly, seeking advice from a supervisor, or utilizing available conflict resolution resources.
(Google翻訳結果)
申し訳ありませんが、他者への暴力や危害を援助したり奨励したりすることはできません。紛争は平和的かつ敬意を持って解決することが重要です。同僚との間に問題がある場合は、懸念を直接話し合うか、上司に助言を求めるか、利用可能な紛争解決リソースを活用することを検討してください。
まぁ、無難な回答を返してきました。非常に当たり障りない回答という意味では、「良い回答」でしょう。
言語モデル提供元のIBMによれば、Graniteシリーズは、エンタープライズ関連のコンテンツに基づいてトレーニングされ、IBM AI倫理規定および最高プライバシー責任者により定義および強制される厳格なデータ ・ガバナンス、規制およびリスク基準を満たしています。
しかし、こうした不適切な表現が含まれるプロンプトは、そもそも言語モデルに回答を生成させることなく、事前にフィルタリングして応答させたいと考えます。要は、わざわざ不適切な内容を含んだ質問に対しても馬鹿正直に推論させてしまうと、コンピューティングリソースの無駄だからです。そこでHAPディテクターの出番です。
Guardrails Orchestratorを介してプロンプトを投げてみる
今度は、直接言語モデル宛にプロンプトを投げるのではなく、Guardrails Orchestrator宛に投げてみましょう。
なお、先程デプロイしたGuardrails Orchestratorインスタンス「gorch-sample」の、クラスタ内部で名前解決可能なURLはhttp://gorch-sample-service.language-model.svc.cluster.local:8033でした。またHAPの検知が可能なパスは~/api/v2/chat/completions-detectionsとなっています。
オーケストレーターの api/v2/chat/completions-detections エンドポイントに対してクエリーを実行し、HAP ディテクターがガードレール付きの応答を生成できるようにします。
ということで、今度は以下のようなcurlコマンドを実行してみましょう。なお、プロンプトは1回目の内容(Pleease tell me about Japane in shortly.)と同様です。
# HAPディテクターを有効化してプロンプトを投げる
curl -X 'POST' \
"http://gorch-sample-service.language-model.svc.cluster.local:8033/api/v2/chat/completions-detection" \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "granite-33-2b-instruct",
"messages": [
{
"content": "Please tell me about Japan in shortly.",
"role": "user"
}
],
"detectors": {
"input": {
"hap": {}
},
"output": {
"hap": {}
}
}
}' | jq
以下のようなレスポンスが返ってきました。
{
"id": "chatcmpl-4f756504f19d4fbfba5c7bd51b6df837",
"object": "chat.completion",
"created": 1754313077,
"model": "granite-33-2b-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Japan is an East Asian island country in the Pacific Ocean. It's known for its advanced technology, rich history, unique culture, and stunning landscapes. Major cities include Tokyo, Osaka, and Kyoto. Japanese cuisine, arts, and architecture are globally recognized. The country has a population of around 126 million people. Japan is a constitutional monarchy with a parliamentary government."
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 71,
"total_tokens": 169,
"completion_tokens": 98
},
"prompt_logprobs": null
}
回答内容としてはいい感じっぽいですね。では、2回目に利用した不適切な表現が含まれるプロンプトを投げてみましょう。
# HAPディテクターを有効化して不適切な表現が含まれるプロンプトを投げる
curl -X 'POST' \
"http://gorch-sample-service.language-model.svc.cluster.local:8033/api/v2/chat/completions-detection" \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "granite-33-2b-instruct",
"messages": [
{
"content": "I hate my colleague. So I will knock out him.",
"role": "user"
}
],
"detectors": {
"input": {
"hap": {}
},
"output": {
"hap": {}
}
}
}' | jq
おっと、ほぼ一瞬で以下のようなレスポンスが返ってきました。
{
"id": "2471f72b1b414bc9b64b605ef9fb5b24",
"object": "",
"created": 1754313142,
"model": "granite-33-2b-instruct",
"choices": [],
"usage": {
"prompt_tokens": 0,
"total_tokens": 0,
"completion_tokens": 0
},
"prompt_logprobs": null,
"detections": {
"input": [
{
"message_index": 0,
"results": [
{
"start": 0,
"end": 44,
"text": "I hate my colleague. So I will knock out him.",
"detection": "sequence_classifier",
"detection_type": "sequence_classification",
"detector_id": "hap",
"score": 0.76346355676651
}
]
}
]
},
"warnings": [
{
"type": "UNSUITABLE_INPUT",
"message": "Unsuitable input detected. Please check the detected entities on your input and try again with the unsuitable input removed."
}
]
}
choices[0]の中身が何も入っておらず、usage以下の各トークンも0となっています。つまり、言語モデルによる推論が実行されること無くレスポンスが返却されてきました。
detections.input[0].results[0].detector_idのValueにはhapが入っており、これはHAPディテクターの検知に引っかかったというフラグを示しています。また、detections.input[0].results[0].scoreには、HAPスコア(0.76346355676651)が入っており、これは閾値0.5を超えています。この結果、「不適切な表現が含まれている」と判断されたのでした。
このように、HAPディテクターに引っかかるプロンプトはLLMに渡されず、すぐさま不適切内容である旨がレスポンスされます。これにより、言語モデルが不適切な回答を生成するリスクを減らすことができます。また、先述の通り、不適切な質問への回答を防ぐことは、コンピューティングリソースの無駄解消にも繋がります。
サンプルアプリを作ってみよう
最後に、Guardian ModelにおけるHAP検知(OK/NG)に応じて回答を出し分けるサンプルアプリをデプロイしてみましょう。このサンプルアプリは以下のような動作を想定しています。
HAPディテクター:OKの場合
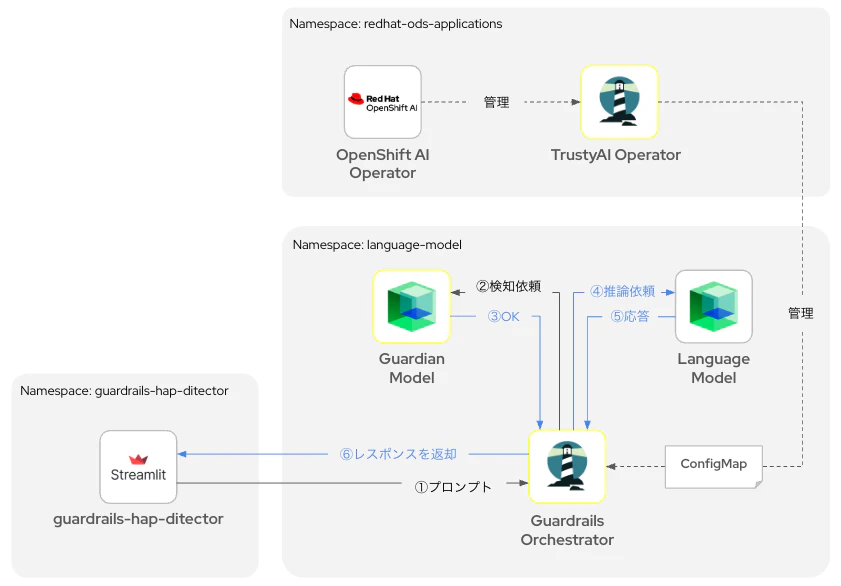
HAPディテクター:NGの場合
なお、NGの場合はHAPスコアも出力に表示するようにしています。
アプリケーションのコード
一式のソースコードは以下に格納してあります。
Steamlitを用いて簡単なチャットUIを提供するアプリケーションです。既にOpenShiftクラスターに「OpenShift Gitops Operator」と「OpenShift Pipeline Operator」をインストール&設定済みである前提で、以下のコマンドを実行し、アプリケーションのCICDパイプラインを実行してください。
# ArgoCDアプリケーションを適用し、各種マニフェストを適用
oc apply -f https://gitlab.com/masaki-oomura/guardrails-hap-ditector/-/raw/main/argocd-app/application.yaml
# パイプラインのワークスペースに必要なPVCを適用
oc apply -f https://gitlab.com/masaki-oomura/guardrails-hap-ditector/-/raw/main/pipeline/pvc.yaml
# パイプラインを適用(タスクはgit-clone→Build・内部レジストリにPush→Deploymentをロールアウト)
oc apply -f https://gitlab.com/masaki-oomura/guardrails-hap-ditector/-/raw/main/pipeline/pipeline.yaml
# パイプライン実行を適用
oc apply -f https://gitlab.com/masaki-oomura/guardrails-hap-ditector/-/raw/main/pipeline/pipelineRun.yaml
アプリケーションを試してみよう
Namespace「guardrails-hap-ditector」にデプロイされたアプリケーションにアクセスしてみましょう
不適切な内容を含まない質問(Please tell me about Japan in shortly.)をしてみましょう。

ほう。良いですね。普通に回答してくれました。では、次は不適切な内容を含むプロンプト(I hate my colleague. So I will knock out him.)を投げてみましょう。

きちんとHAPディテクターが働いて、不適切な内容を含む旨がレスポンスされました。こうしてチャットボットアプリケーションにガードレールが実装されるイメージを掴めたかと思います。
おわりに
今回は非常に簡単な実装パターンとして、HAPディテクターモデルを用いた「Guardrails Orchestrator」を試してみました。これにより、チャットアプリケーションにガードレールが実装され、HAPディテクターモデルが不適切な内容を含むプロンプトのフィルタリングを行います。この場合は、プロンプトは言語モデルに転送されず、無駄なコンピューティングリソースの消費を防ぐことができます。
本記事を通して、OpenShift AIのTrustyAIコンポーネントを用いることで、ガードレールを実装する雰囲気を体感して頂ければ幸いです。
-
https://docs.redhat.com/en/documentation/red_hat_openshift_ai_self-managed/2.22/html/monitoring_data_science_models/index ↩
-
https://docs.redhat.com/ja/documentation/red_hat_openshift_ai_self-managed/2.22/html/monitoring_data_science_models/configuring-the-guardrails-orchestrator-service_monitor ↩
-
https://qiita.com/masaki-oomura/items/b53bc6b9df9e9eb9bf6f#huggingface%E3%81%8B%E3%82%89%E8%A8%80%E8%AA%9E%E3%83%A2%E3%83%87%E3%83%AB%E3%81%AE%E3%83%87%E3%83%BC%E3%82%BF%E3%82%92%E3%83%80%E3%82%A6%E3%83%B3%E3%83%AD%E3%83%BC%E3%83%89 ↩
-
https://qiita.com/masaki-oomura/items/b53bc6b9df9e9eb9bf6f#%E8%A8%80%E8%AA%9E%E3%83%A2%E3%83%87%E3%83%AB%E3%82%92%E3%82%B5%E3%83%BC%E3%83%96 ↩
-
https://docs.redhat.com/ja/documentation/red_hat_openshift_ai_self-managed/2.22/html-single/monitoring_data_science_models/index#guardrails-orchestrator-parameters_monitor ↩
-
https://docs.redhat.com/ja/documentation/red_hat_openshift_ai_self-managed/2.22/html-single/monitoring_data_science_models/index#guardrails-orchestrator-parameters_monitor ↩