導入
世の中には、なんとなく「ありそう」な響きだけれど実際には「ない」言葉が存在します。
例えば飲み会の山手線ゲーム、あるいは制約付きのしりとり勝負でも思い浮かべてください。時間に追われ、ぽろっと誰かが溢した一言に、一瞬「よく絞り出したな」と見逃し、ややあってから「冷静に考えるとそんな言葉なくないか?」と咎めるような場面があります。このときその人は、他ならぬ「ありそうでない言葉」を発したのだと考えられます。
では何がその言葉を「ありそう」たらしめているのかというと、それはおそらく「言葉の発音のしやすさ」、敢えて抽象的な表現に言い換えるのなら「言葉の響き」だと言えるのではないでしょうか。「まいせんかん」はどことなくありそうな雰囲気を醸していますが、「ぺりいしみび」はきっとないことでしょう。裏を返せば、その言葉が実在するかどうかは、単語の「響き」のみによってある程度判断がつく、ということになります。
そこで本記事では、単語の響きだけで言葉の実在・非実在を識別する機械学習モデルを考えます。まず「実在する単語」および「ランダムに生成した実在しない単語」にそれぞれのラベルをつけた訓練データで学習を行い、次に未知の単語に対する識別性能を調べることで上記の仮説を検証します。
さらに、単語の「ありそう度」を出力するモデルを構築できれば、その出力結果を元に、ランダムに生成した言葉がどれくらい「ありそう」かを求めることが可能になります。そこで、「ありそうでない言葉」をたくさん生み出す、というのを今回の目標に掲げます。
「偽」の単語生成
2文字から8文字の(主に)名詞を集めた、クロスワード制作用の辞書「豚辞書」をデータベースとし、まず存在する単語の特徴についてざっくりと調べます。
辞書の読み込み
豚辞書をダウンロードし、言葉の一覧を配列wordlistに格納します。
import codecs
f = codecs.open('buta014.dic','r', 'Shift_JIS', 'ignore')
data1 = f.read()
f.close()
lines1 = data1.split('\n')
wordlist= []
for line in lines1[:-1]:
wordlist.append(str(line[:-1]))
print(len(wordlist))
201092
実に20万語を超える数の単語が収録されているようです。また、「つ」と「っ」など小文字と大文字の区別がないという特徴があります。これは少し不都合ですが、他に良いデータベースが見つからなかったので今回は甘んじて受け入れることとします(使い勝手の良い辞書のテキストファイルがあったら教えてください!)。
単語の長さの分布
単語の長さがどのように分布しているかを確認します。
import collections
words_len = []
for word in wordlist:
words_len.append(len(word))
len_count = collections.Counter(words_len)
print(len_count)
Counter({4: 42814, 5: 41205, 6: 40045, 7: 34639, 8: 24683, 3: 15674, 2: 2032})
単語の長さには(ありうる組み合わせを考えれば当たり前ですが)かなりの偏りがあるようです。偽の単語の長さも、この分布に従って決めることにします。
使用される文字の分布
それぞれの文字がどれくらいの頻度で現れるかを確認します。登場回数上位5つと下位5つを表示すると、次のような結果となりました。
letter_frequency = collections.Counter(''.join(wordlist))
all_letters = list(letter_frequency.keys())
print(letter_frequency.most_common()[:5])
print(letter_frequency.most_common()[-5:])
[('ん', 87478), ('う', 75534), ('い', 70666), ('し', 49582), ('く', 39132)]
[('ぬ', 1718), ('を', 1398), ('ぴ', 1301), ('ぺ', 1099), ('ぢ', 158)]
「ん」が最頻というのはやや意外でしたが、概ね予想通りの頷ける結果です。偽の単語の生成する際にも、使用される文字はこの分布に従うものとします。これは、「ぬ」という珍しい文字が入っているから偽物だ、というような「ずるい」識別法を許さないようにするためです。
偽の単語ジェネレーター
文字の出現頻度と単語の長さは実在する言葉の分布に従うとして、基本的にはランダムに文字を並べることによって偽物の単語を生成します。ただし、出来上がった単語が「実際には存在しないこと」と「『ん』、『ー』、『を』のいずれかで始まらないこと」だけはチェックし、その条件した単語を出力することにします。
実際に10個ほど単語を生み出してみましょう。
import random
def generate_fake_word():
length = random.choices(list(len_count.keys()),k=1,weights = list(len_count.values()))[0]
while True:
fake_word = ''.join(random.choices(all_letters,k=length,weights = list(letter_frequency.values())))
if fake_word[0] in ["ん","を","ー"]:
continue
if fake_word not in wordlist:
return fake_word
for _ in range(10):
print(generate_fake_word())
わーごこちくさ
うんがあう
ゆそんせい
すきかりいいしご
こじまにうて
ちうきれしん
しばじけ
るくーかよ
わこよーかふつせ
やくきはだきた
確かに、どこからどう見てもこの世に存在しない単語たちが産み落とされました。これらが、今回学習させるモデルにおけるラベル0の教師データとなります。
RNNによるクラス分類
今回作りたい機械学習モデルは、文字列を入力とし、それが実在する単語であればラベル1、実在しない単語であればラベル0を割り当てる識別器です。文字列を構成する「文字」が不連続な入力であること、入力の長さが一定でないこと、また文字の並ぶ順番に分類のために必要な情報が秘められている(と思われる)ことから、文字をOne Hot Vectorによりエンコードした文字レベルのRecurrent Neural Network(RNN)を採用します。実装には、PyTorchのチュートリアルNLP FROM SCRATCH: CLASSIFYING NAMES WITH A CHARACTER-LEVEL RNNが大変参考になりました。
モデルの構造
文字列を文字の系列データと見なし、隠れ状態にそれ以前の文字の情報を残して伝えていく基本的な構造のRNNをそのまま採用します。
import torch
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
n_letters = len(all_letters)
n_categories = 2
n_hidden = 128
rnn = RNN(n_letters, n_hidden, n_categories)
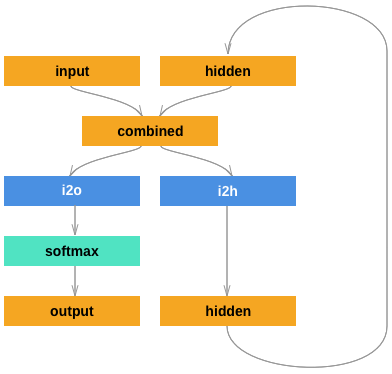
outputとして最終的に得られるのは、ラベル0に分類される予測確率とラベル1に分類される予測確率(厳密には、それらの対数をとったもの)を並べたものとなります。
データ作成
訓練用データ集合と検証用データ集合を別々に用意します。どちらにも本物の単語と偽物の単語を1:1の割合で含め、それぞれ教師ラベル「1」「0」を割り当てます。また、訓練用データ集合は検証用データ集合の4倍の大きさとします。また、訓練用データ集合と検証用データ集合に教師データの重複は起きないようにします。
訓練用に80000個の本物単語と80000個の偽物単語、検証用に20000個の本物単語と20000個の偽物単語を用意しました。
train_size = 80000
test_size = 20000
train_X = []
train_Y = []
test_X = []
test_Y = []
select_words = random.sample(wordlist, train_size+test_size)
for word in select_words[:train_size]:
train_X.append(word)
train_Y.append(1)
for word in select_words[train_size:]:
test_X.append(word)
test_Y.append(1)
for _ in range(train_size):
fake_word = generate_fake_word()
train_X.append(fake_word)
train_Y.append(0)
for _ in range(test_size):
fake_word = generate_fake_word()
test_X.append(fake_word)
test_Y.append(0)
モデルは訓練用データのみで学習を行い、検証用データに対してどれくらいの分類精度を示すかを見ることで学習の成否を測ります。当然、モデルに日本語の知識なんて備わっていません。訓練用データによる学習が少しでも検証用データに対する性能を向上させるなら、それはある意味言葉の響きだけで単語が存在するかどうかを判定できることの証明になると言えます。
学習
ネットワークの入力とするために、単語の各文字をOne Hot Vectorによりエンコードした後テンソルに変換します。
def letterToIndex(letter):
return all_letters.index(letter)
def letterToTensor(letter):
tensor = torch.zeros(1, n_letters)
tensor[0][letterToIndex(letter)] = 1
return tensor
def lineToTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li, letter in enumerate(line):
tensor[li][0][letterToIndex(letter)] = 1
return tensor
訓練用集合および検証用集合からテンソルとしてランダムなデータを一つ取り出せるようにします。
def categoryFromOutput(output):
top_n, top_i = output.topk(1)
category_i = top_i[0].item()
return category_i
def randomTrainingExample():
id = random.randint(0, len(train_X) - 1)
category = train_Y[id]
line = train_X[id]
category_tensor = torch.tensor([category], dtype=torch.long)
line_tensor = lineToTensor(line)
return category, line, category_tensor, line_tensor
def randomTestingExample():
id = random.randint(0, len(test_X) - 1)
category = test_Y[id]
line = test_X[id]
category_tensor = torch.tensor([category], dtype=torch.long)
line_tensor = lineToTensor(line)
return category, line, category_tensor, line_tensor
1回のepochでランダムに抽出した4000語の単語を(ミニバッチではなく)1つずつRNNに入力して学習を進めます。計50回これを繰り返すことします。
import copy
import time
import math
import matplotlib.pyplot as plt
def train(category_tensor, line_tensor):
hidden = rnn.initHidden()
rnn.zero_grad()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
loss = criterion(output, category_tensor)
loss.backward()
for p in rnn.parameters():
p.data.add_(p.grad.data, alpha=-learning_rate)
return output, loss.item()
def train_model(model, criterion, num_epochs=25,n_iters =4000):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch+1, num_epochs))
print('-' * 10)
for phase in ['train', 'val']:
running_corrects = 0
if phase == 'train':
current_loss = 0.0
model.train()
for iter in range(1, n_iters + 1):
category, line, category_tensor, line_tensor = randomTrainingExample()
output, loss = train(category_tensor, line_tensor)
if category == categoryFromOutput(output):
running_corrects += 1
current_loss += loss
train_loss = current_loss/n_iters
train_acc = running_corrects/n_iters
train_losses.append(train_loss)
train_accs.append(train_acc)
print('train loss: {:4f}'.format(train_loss))
print('train acc: {:4f}'.format(train_acc))
if phase == 'val':
model.eval()
for iter in range(1,n_iters//4+1):
category, line, category_tensor, line_tensor = randomTestingExample()
hidden = rnn.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
if category == categoryFromOutput(output):
running_corrects += 1
test_acc = running_corrects/(n_iters//4)
test_accs.append(test_acc)
print('test acc: {:4f}'.format(test_acc))
if phase == 'val' and test_acc > best_acc:
best_acc = test_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('best test Acc: {:4f}'.format(best_acc))
# ベストモデルの重みをロード
model.load_state_dict(best_model_wts)
return model
n_letters = len(all_letters)
n_categories = 2
n_hidden = 128
rnn = RNN(n_letters, n_hidden, n_categories)
criterion = nn.NLLLoss()
learning_rate = 0.005
n_iters = 8000
num_epochs = 50
train_losses = []
train_accs = []
test_accs = []
rnn = train_model(rnn,criterion,num_epochs,n_iters)
epochs = [i for i in range(num_epochs)]
plt.plot(epochs, train_losses)
plt.xlabel("epochs")
plt.ylabel("train loss")
plt.show()
plt.plot(epochs, train_accs)
plt.xlabel("epochs")
plt.ylabel("train acc")
plt.show()
plt.plot(epochs, test_accs)
plt.xlabel("epochs")
plt.ylabel("test acc")
plt.show()
学習の様子(訓練用データに対する精度、検証用データに対する精度の変化)をグラフ化すると次の通りです。
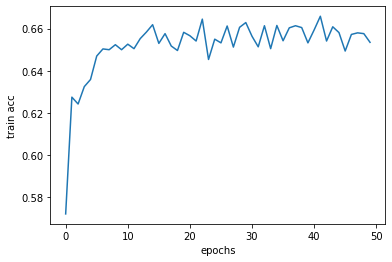
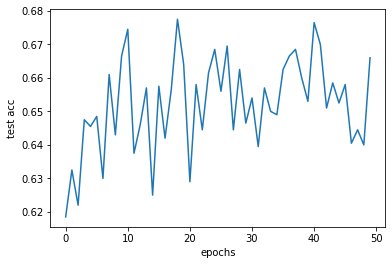
10epoch目くらいから学習がものの見事に停滞していることがわかります。最良のepochでも検証用データに対する的中率は0.6775に留まっています。0.5よりも高い以上、学習によって完全に未知の単語の実在・不在を少しは言い当てられることがわかったのは収穫ですが、スコアは思いの外伸びません。
そして個人的には、これがこのタスクの限界だとは思えません。なぜなら、我々人間ならば聞いたことのない単語「わーごこちくさ」や「やくきはだきた」が、単に知らないのではなく適当にでっち上げた偽物だということがもっと正確にわかるような気がするからです(ただし、これはあくまで「気がする」だけで、知識の中にないこと(=文字列の並び以外の情報)を参照して無意識に判断している可能性もあります)。つまり、この精度のイマイチさはモデルの簡易さ、学習方法の単純さ、そして何よりぼくの機械学習技術のなさに起因しているに違いない、ということです。
ならば、もう一踏ん張りしてみる価値はありそうです。
手法の改善
とはいえ、学習曲線を見るに過学習をしているわけではなく(訓練用データと検証用データに対するパフォーマンスに大差がない)、また学習はすでに停滞しているので闇雲にepoch数を増やして改善するとは思えません。試行錯誤した結果、やや姑息な改善策に打って出ます。
文字数の限定
識別の対象となる単語の文字数を統一します。例えば6文字からなる単語のみで学習・検証を行い、性能がどう変わるかを見てみます。これは、ありそうな単語かどうかの判定基準が単語の長さに強く依存しそうであること、および文字数の多い単語ほど識別がしやすそうであることに拠りました。
結果は、次の通りです。
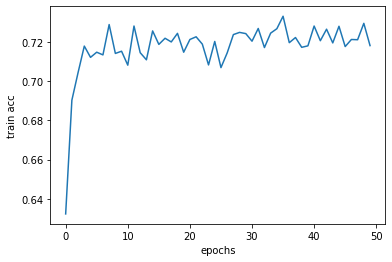
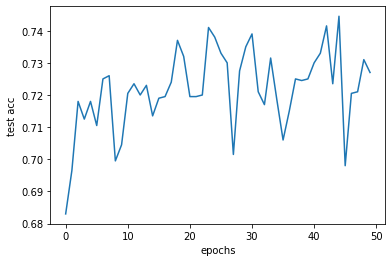
的中率が5%ほど向上したことがわかります。検証用データでの的中率は最高のもので74%程度でした。やや物足りないですが、この後「文字を母音と子音に分解して入力ベクトルの次元を下げる」「最適化アルゴリズムを変える」などを試みても改善が果たせなかったため、今回はこのモデルを採用します。
「ありそうでない言葉」の生成
本当は実在しないのにも関わらず、上で学習した識別モデルによって存在すると判定されてしまう単語こそ、今我々の追い求めている「ありそうでない言葉」です。より選別を厳しく行うために、ランダムに生成した単語20000個のうち「ありそう度」が高い上位10個を出力すると、次のようになりました。
import matplotlib.pyplot as plt
d = []
his = []
for _ in range(20000):
fake_word = generate_fake_word()
line_tensor = lineToTensor(fake_word)
hidden = rnn.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
prob = np.exp(np.float(output[0][1]))
d.append((fake_word,prob))
his.append(prob)
d.sort(reverse=True,key=lambda x:x[1])
plt.hist(his,bins=20)
for di in d[:20]:
print(di[0])
おつべのせる
ほよづのばん
おつがいがち
ひゆのりずじ
ふつきんがー
あくとのよき
あんたいがす
あんじそがん
ふよぷいもし
おこをくだう
結果の是非は、意見が分かれるところでしょう。ただ確かに、「おつがいがち」なる勝ち方、「フッキンガー」なる科学者、「あくよのとき」なる時間帯、「あんたいガス」なる危なげな気体があっても、おかしくはないのかもしれません。「おこをくだう」は、ロバート秋山が言うところの「雰囲気慣用句」でしょうか。
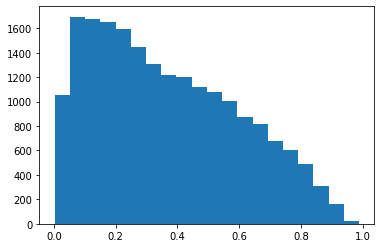
ちなみに、ランダム生成した単語たちに対する推定確率の分布は次のようになっています。(1に近いほど、その単語は「ありそう」)
ついでに、「ありそう度」が低いものたちを出力します。
のがんせやせ
つばなせはほ
うせんいれせ
うだきろむほ
つしうしんほ
よをやとおせ
うひさじいせ
よぼんーつせ
ずしんしくが
うをいろんぞ
確かに、どんなに周りが酔っ払っていても、山手線ゲームで「のがんせやせ」だの「つばなせはほ」だのと口走った奴が逃げ切れるとは思えません。(「せ」や「ほ」で終わる単語が並んでいるのが何やら不穏です)
本記事のタイトルにもなっている『「ありそうでない言葉」をたくさん作る』という目標に到達できたか少し怪しいですが、鑑賞のしがいがある結果にはなりました。
おわりに
文字の並びだけで実在・非実在を判定する限界
「響き」だけでありそうな言葉かなさそうな言葉を判断することは一見人間なら可能のように思えますが、実際には人は、言葉に紐付けされた知識も動員して判定を下しているようにも感じます。例えば、「冷凍みかん」と聞けば、仮に人生で一度も見たことがなかったとしても、「きっと冷凍したみかんなんだろうな」と勘付き、「ありそう」だと思うはずです。一方、「冷凍メガネ」では想像がつかず、「なさそう」だと考えるはずです。これは単純化した例にすぎませんが、人間には言葉の意味を知っているがために、想像や類推によって単語の有無を見定められる場合があるのです。
また、短い長さ(2~4程度)の単語に関しては、人間でもあるかないかを正確に区別することが極めて難しいと考えられます。「るす」という単語があって「るそ」という単語がないと分かるのには、単純に「我々が『留守』という言葉を知っているから」以上の理屈があるとは思えません。
したがって、この「単語のリストを学習して、未知の単語の実在・非実在を分類する」というタスク自体に原理的な限界があることは間違いないでしょう。個人的には興味深い課題だと感じ、また訓練データの用意が極めて簡単なので、ぜひ関心のある方は取り組んでみてほしいです(どういうアプローチがあるのか知りたいです)。
感想
というわけで、ある程度思わしい結果が出たものの、いかにもありそうな単語がポンポン出てくるという理想の結末に至ったとは言い難いです。これには、識別器の性能がそこまで上がらなかったことや単語の辞書に大文字小文字の区別がなかったことに加え、候補を量産してそのうちから選別するというアプローチそのものの不適切さも関係しているように思われます。というのも、ランダムに生成した単語が、学習データに入った本物/偽物単語のどちらとも似ても似つかないものになったとき、その判定結果は無根拠なものにならざるを得ないからです。より生成の精度を見込みたいのならば、敵対的生成ネットワーク(GANs)の活用が有力だと考えられます。
気が向けば再チャレンジしたいです。