記事を作成した背景
どうもこんにちは。私は某企業でデータ活用部門にてお仕事をしているmasahiro54と申します。
この度触れたことのない、データ基盤作りに関わるということで、勉強がてら記事を書くことにしました。
(outputしたほうが身に付く気がするので。)
そして、まずはメジャーなツールである「embulk」「digdag」をローカル環境で触ってみようと考えました。
今回目指すモノ
以下の図の通りに、embulkを用いて以下のデータ連携を行います。
- csv → 分析DB
- 別のDB → 分析DB
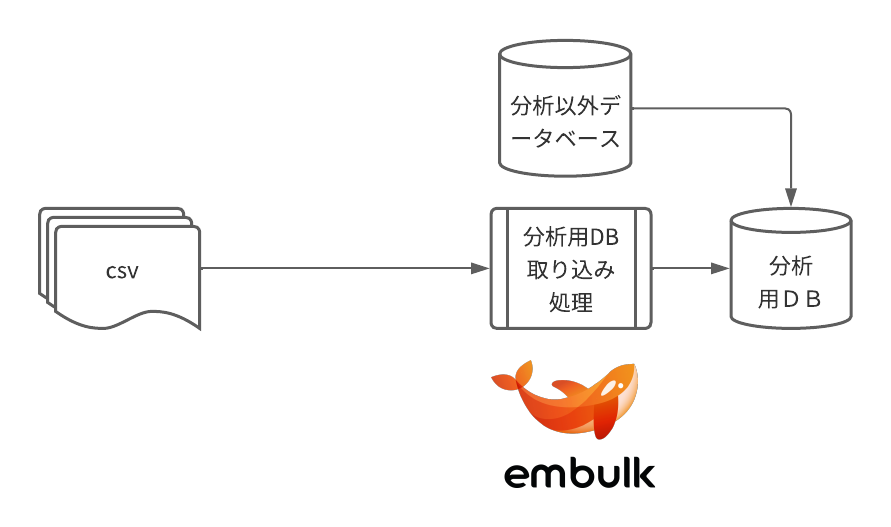
そしてdigdagにてembulkを実行するところが今回のゴールです。
作業前の状態
環境(ざっくりです。)
※全体的に古めの環境ですが、こちらのほうがやりやすかったので最新にはしていません。
- windows11
- java 1.8.0_371
- PostgreSQL13
- digdag 0.9.42
- embulk 0.10.0
作業前の状態
以下の通りです。
-
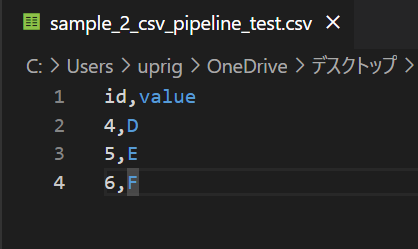
csv(input)
-
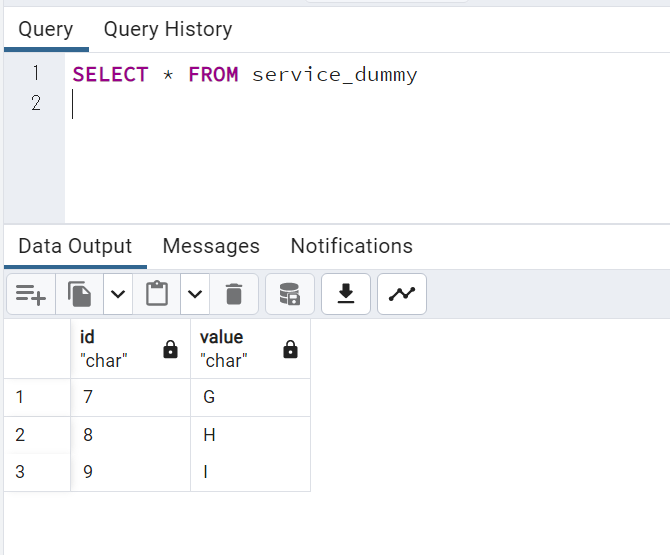
分析外のDB
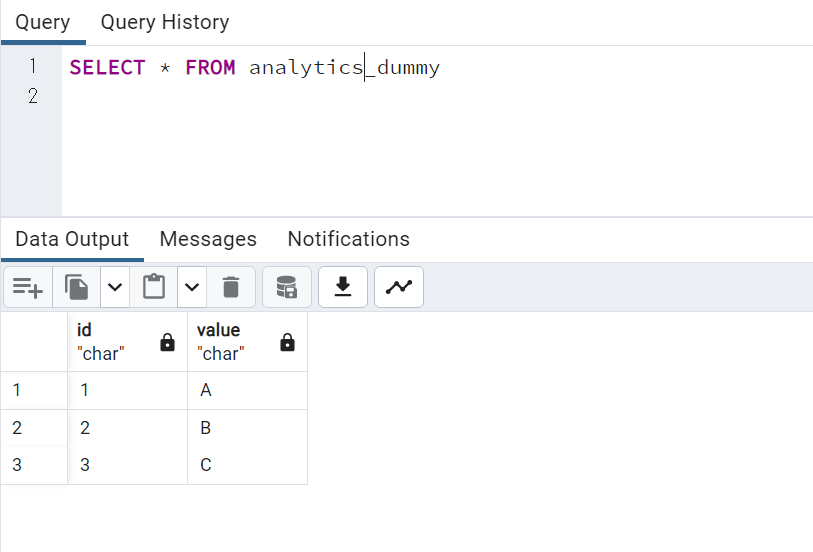
- 分析DB
やってみたこと
embulk
下準備
- 以下のコマンドでembulk(ver.0.10.0)をインストールします。
- 「embulk-0.10.0.jar」を「embulk-latest.jar」にすれば最新版にできます。
- (恐らく以下で正しいと思いますが。。。当時のメモからコピペしてるので間違っていたら申し訳ないです。)
PowerShell -Command "& {Invoke-WebRequest http://dl.embulk.org/embulk-0.10.0.jar -OutFile embulk.bat}"
- pluginのインストール
postgresqlの操作をするため、以下の2つのプラグインをインストールします。コマンドは
※csvはデフォで出来ました。
- embulk-input-postgresql
- embulk-output-postgresql
コマンドはそれぞれ以下です。
embulk gem install embulk-input-postgresql
embulk gem install embulk-output-postgresql
- JDBCドライバの更新
以下のディレクトリの該当するプラグインのフォルダを開き、「default_jdbc_driver」の中のJDBCドライバを最新のものに置き換えます。
(私は「postgresql-9.4-1205-jdbc41.jar」→「postgresql-42.6.0.jar」に置き換えました。)
.embulk\lib\gems\gems
※ちなみにpostgresqlのJDBCドライバはこちらから取得しました。(https://jdbc.postgresql.org/)
ymlファイルの作成
今回は以下の2点を作成しました。
- csvからDBにデータを送るためのymlファイル
- DBから別のDBにデータを送るためのymlファイル
csvからDBにデータを送るためのymlファイル
※パスワードは適当な文字列を入れてます。
ご自身の環境のパスワードを入れてください。
in:
type: file
path_prefix: C:aaa\\bbb\\ccc\\sample_2_csv_pipeline_test.csv # 入力ファイルのパスを記載してください。
parser:
charset: UTF-8
newline: CRLF
type: csv
delimiter: ','
skip_header_lines: 1
columns:
- {name: id, type: string}
- {name: value, type: string}
out:
type: postgresql
host: localhost
user: postgres
password: poiuytrewq
database: data_pipeline_test_B #分析用DB
table: service_dummy
mode: insert
DBから別のDBにデータを送るためのymlファイル
in:
type: postgresql
host: localhost
user: postgres
password: poiuytrewq
database: data_pipeline_test_A #分析以外の用途のDB
query:
select *
FROM service_dummy #入力元のデータを引っ張るSQL
out:
type: postgresql
host: localhost
user: postgres
password: poiuytrewq
database: data_pipeline_test_B #分析用DB
table: service_dummy
mode: insert
digdag
下準備
- 以下のコマンドでdigdag(ver.0.9.42)をインストールします。
- 「digdag-0.9.42.jar」を「digdag-latest.jar」にすれば最新版にできます。
- (embulkとコマンドが違いますが気にしないでください。多分、ほぼ同じ形でも行けると思います。ちなみに当時、下準備の順番はdigdag → embulkの順で行いました。)
PowerShell -Command "& {[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::TLS12; mkdir -Force $env:USERPROFILE\bin; Invoke-WebRequest http://dl.digdag.io/digdag-0.9.42.jar -OutFile $env:USERPROFILE\bin\digdag.bat}"
- digファイル作成
以下のdigファイルを作成しました。
timezone: "Asia/Tokyo"
_export:
sh:
shell: ["powershell.exe"]
# schedule:
# daily>: 10:00:00
+step1:
sh>: embulk run csv_to_db.yml
+step2:
sh>: embulk run db_to_db.yml
+step3:
echo>: Fin.
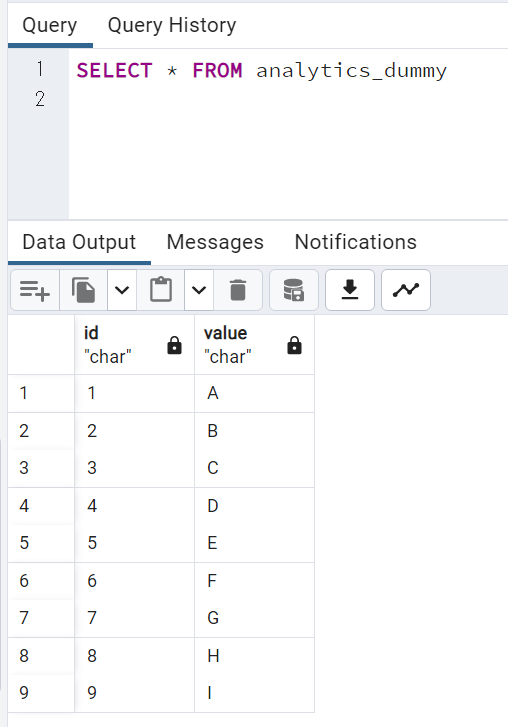
結果
以下の通り、更新されました。
まとめ
- とりあえず、embulkとdigdagの簡単な使い方はわかりました。
- 応用すれば、会社のデータ基盤でも使えそうです。
- とはいえこれだけだとかなりシンプルな動きしかできなさそうなので、さらに工夫を凝らした仕組みを構築してみたいです。。。
今後やってみたいこと
- embulkにクラウド環境へのデータ連携
- データソースからDWHに格納し、BIで可視化するまで。
- 分析用DBにおけるデータの洗い替えのパフォーマンス実験。
- Update
- Delete → Insert
- Drop → Create