#CLUSTERED COLUMNSTORE INDEX
Azure Synapse Analytics SQLプールではデフォルトでCLUSTERED COLUMNSTORE INDEX(クラスター化列ストアインデックス)と言う形式でデータが格納されます。
Azure Synapse Analytics SQLプールのCLUSTERED COLUMNSTORE INDEXにはこんな特徴があります。
・データは列指向で格納される。
・格納されるデータは圧縮される。
・60のディストリビューションに分割して格納される。
今回はこのCLUSTERED COLUMNSTORE INDEXについて検証しましたので、記事にまとめておこうと思います。
CLUSTERED COLUMNSTORE INDEXの詳細につきましては以前にまとめたものを参考にしていただければと思います。
Synapse SQLプールのクラスター化列ストアインデックス
#CLUSTERED COLUMNSTORE INDEXを構成する要素
検証の前に、少しだけ本記事でもCLUSTERED COLUMNSTORE INDEXについておさらいをしようと思います。
CLUSTERED COLUMNSTORE INDEXはいくつかの要素から構成されています。この要素について記載します。
##行グループ
CLUSTERED COLUMNSTORE INDEXでは、データは行グループという単位で管理されることになります。1つの行グループは最大で1,048,576件の件数で管理されます。
また、圧縮はこの単位で圧縮されます。
Azure Synapse Analytics SQLプールは60のディストリビューションに分かれていますが、各行グループはディストリビューション単位で作成されます。(よって、60のディストリビューションに均一にデータが配置されたとしても、6000万件程度のデータが無ければ圧縮してくれない可能性があります。)
##デルタストア
まだ圧縮されていない、未圧縮の状態の行グループを格納する領域となります。また、未圧縮の状態で行グループが格納されているだけではなく、この領域に格納されているデータは列ストア(列指向)ではなく、行ストア(行指向)で格納されています。
また、一度のロードでディストリビューションあたり102,400件を超える場合はデルタストアを経由せず、圧縮された列ストアとして行グループが形成されます。
##Tuple Mover
デルタストアに格納されている行グループが1,048,576件に達した場合、その行グループのステータスがOPENからCLOSEに変更されます。CLOSEになった行グループに対してSynapse Analyticsが自動で行ストアから列ストアへデータを変換し、さらに圧縮をおこないますがこの動作を担っているのが、このTuple Moverです。
CLOSEされた行グループの圧縮が完了しましたら、圧縮前の行グループは破棄可能状態(TOMBSTONE)となり、他のプロセスから参照されていなければ削除されますが、この削除もTuple Moverが行います。
##Delete Bitmap
行グループのデータがDELETEされますと、物理削除されるわけではなく、削除済みである旨フラグが立つのみです。そのフラグを管理するのがDelete Bitmapです。
#検証
ここから実際のデルタストアから列ストアになる動きを確認したいと思います。
##準備
クラスター化列ストアインデックスにおける行グループの情報を取得するビューの作成
CREATE VIEW dbo.vColumnstoreDensity
AS
SELECT
GETDATE() AS [execution_date]
, DB_Name() AS [database_name]
, s.name AS [schema_name]
, t.name AS [table_name]
, COUNT(DISTINCT rg.[partition_number]) AS [table_partition_count]
, SUM(rg.[total_rows]) AS [row_count_total]
, SUM(rg.[total_rows])/COUNT(DISTINCT rg.[distribution_id]) AS [row_count_per_distribution_MAX]
, CEILING((SUM(rg.[total_rows])*1.0/COUNT(DISTINCT rg.[distribution_id]))/1048576) AS [rowgroup_per_distribution_MAX]
, SUM(CASE WHEN rg.[State] = 0 THEN 1 ELSE 0 END) AS [INVISIBLE_rowgroup_count]
, SUM(CASE WHEN rg.[State] = 0 THEN rg.[total_rows] ELSE 0 END) AS [INVISIBLE_rowgroup_rows]
, MIN(CASE WHEN rg.[State] = 0 THEN rg.[total_rows] ELSE NULL END) AS [INVISIBLE_rowgroup_rows_MIN]
, MAX(CASE WHEN rg.[State] = 0 THEN rg.[total_rows] ELSE NULL END) AS [INVISIBLE_rowgroup_rows_MAX]
, AVG(CASE WHEN rg.[State] = 0 THEN rg.[total_rows] ELSE NULL END) AS [INVISIBLE_rowgroup_rows_AVG]
, SUM(CASE WHEN rg.[State] = 1 THEN 1 ELSE 0 END) AS [OPEN_rowgroup_count]
, SUM(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE 0 END) AS [OPEN_rowgroup_rows]
, MIN(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE NULL END) AS [OPEN_rowgroup_rows_MIN]
, MAX(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE NULL END) AS [OPEN_rowgroup_rows_MAX]
, AVG(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE NULL END) AS [OPEN_rowgroup_rows_AVG]
, SUM(CASE WHEN rg.[State] = 2 THEN 1 ELSE 0 END) AS [CLOSED_rowgroup_count]
, SUM(CASE WHEN rg.[State] = 2 THEN rg.[total_rows] ELSE 0 END) AS [CLOSED_rowgroup_rows]
, MIN(CASE WHEN rg.[State] = 2 THEN rg.[total_rows] ELSE NULL END) AS [CLOSED_rowgroup_rows_MIN]
, MAX(CASE WHEN rg.[State] = 2 THEN rg.[total_rows] ELSE NULL END) AS [CLOSED_rowgroup_rows_MAX]
, AVG(CASE WHEN rg.[State] = 2 THEN rg.[total_rows] ELSE NULL END) AS [CLOSED_rowgroup_rows_AVG]
, SUM(CASE WHEN rg.[State] = 3 THEN 1 ELSE 0 END) AS [COMPRESSED_rowgroup_count]
, SUM(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE 0 END) AS [COMPRESSED_rowgroup_rows]
, SUM(CASE WHEN rg.[State] = 3 THEN rg.[deleted_rows] ELSE 0 END) AS [COMPRESSED_rowgroup_rows_DELETED]
, MIN(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE NULL END) AS [COMPRESSED_rowgroup_rows_MIN]
, MAX(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE NULL END) AS [COMPRESSED_rowgroup_rows_MAX]
, AVG(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE NULL END) AS [COMPRESSED_rowgroup_rows_AVG]
, 'ALTER INDEX ALL ON ' + s.name + '.' + t.NAME + ' REBUILD;' AS [Rebuild_Index_SQL]
FROM sys.[pdw_nodes_column_store_row_groups] rg
JOIN sys.[pdw_nodes_tables] nt ON rg.[object_id] = nt.[object_id]
AND rg.[pdw_node_id] = nt.[pdw_node_id]
AND rg.[distribution_id] = nt.[distribution_id]
JOIN sys.[pdw_table_mappings] mp ON nt.[name] = mp.[physical_name]
JOIN sys.[tables] t ON mp.[object_id] = t.[object_id]
JOIN sys.[schemas] s ON t.[schema_id] = s.[schema_id]
GROUP BY
s.[name]
, t.[name];
以下の情報が確認可能です。
| 列 | 説明 |
|---|---|
| table_partition_count | テーブルを構成するパーティションの数。 |
| row_count_total | テーブル内のデータの合計件数。 |
| row_count_per_distribution_MAX | ディストリビューション当たりの目標となる件数。 |
| COMPRESSED_rowgroup_rows | 列ストアの合計行数。 |
| COMPRESSED_rowgroup_count | 列ストア形式の行グループの数。 |
| COMPRESSED_rowgroup_rows_AVG | 列ストアの平均行数。この値がCOMPRESSED_rowgroup_rows_MAXよりもはるかに小さい場合は、ALTER INDEX REBUILDで再作成を推奨。 |
| COMPRESSED_rowgroup_rows_MIN | 列ストア形式の行グループの最小件数。 |
| COMPRESSED_rowgroup_rows_MAX | 列ストア形式の行グループの最大件数。 |
| COMPRESSED_rowgroup_rows_DELETED | 列ストア形式の論理的にDELETEされたデータの件数。件数が多い場合はALTER INDEX REBUILDで再作成を検討。 |
| OPEN_rowgroup_rows | デルタストア内の行グループ内のデータの件数。 |
| OPEN_rowgroup_count | デルタストア内で現在利用されている行グループの数。ディストリビューションが60個あるため、60個OPENされている事は一般的。 |
| OPEN_rowgroup_rows_AVG | デルタストア内の行グループの平均行数。 |
| OPEN_rowgroup_rows_MIN | デルタストア内の行グループの最小の件数。 |
| OPEN_rowgroup_rows_MAX | デルタストア内の行グループの最大の件数。 |
| CLOSED_rowgroup_rows | デルタストア内でCLOSEされた行グループ内のデータの件数。 |
| CLOSED_rowgroup_count | デルタストア内で、CLOSEされた行グループの数。ただしデルタストア内でCLOSEされた行グループはTuple Moverにより自動で列ストア化されるのであまり意識する必要はない。 |
| Rebuild_Index_SQL | クラスター化列ストアインデックスを再作成する際に使用。 |
実行例は以下の通り
--クラスター化列ストアインデックスの列ストア、行ストアの情報取得
select
table_name
,table_partition_count
,row_count_total
,row_count_per_distribution_MAX
,COMPRESSED_rowgroup_rows
,COMPRESSED_rowgroup_count
,COMPRESSED_rowgroup_rows_AVG
,COMPRESSED_rowgroup_rows_MIN
,COMPRESSED_rowgroup_rows_MAX
,COMPRESSED_rowgroup_rows_DELETED
,OPEN_rowgroup_rows
,OPEN_rowgroup_count
,OPEN_rowgroup_rows_MIN
,OPEN_rowgroup_rows_MAX
,OPEN_rowgroup_rows_AVG
,CLOSED_rowgroup_rows
,CLOSED_rowgroup_count
,Rebuild_Index_SQL
from
vColumnstoreDensity;
##検証①600万件に満たないデータのロード
600万件に満たないデータをロードする場合、均等にデータが分散されればディストリビューション当たり102,400件を下回るためデータがデルタストアに格納されるはずです。
###1.テーブルの作成
CTASでテーブルを作成します。
CREATE TABLE TEST
WITH (
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
AS SELECT * FROM LINEITEM WHERE 1=2;
###2.データの投入
600万件のデータを投入します。
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
###3.確認
ロード後の結果を確認します。
select
table_name
,table_partition_count
,row_count_total
,row_count_per_distribution_MAX
,COMPRESSED_rowgroup_rows
,COMPRESSED_rowgroup_count
,COMPRESSED_rowgroup_rows_AVG
,COMPRESSED_rowgroup_rows_MIN
,COMPRESSED_rowgroup_rows_MAX
,COMPRESSED_rowgroup_rows_DELETED
,OPEN_rowgroup_rows
,OPEN_rowgroup_count
,OPEN_rowgroup_rows_MIN
,OPEN_rowgroup_rows_MAX
,OPEN_rowgroup_rows_AVG
,CLOSED_rowgroup_rows
,CLOSED_rowgroup_count
,Rebuild_Index_SQL
from
vColumnstoreDensity
where
table_name = 'TEST'
;
600万件のデータがロードされています。

列ストアは何も出来ていません。

60の行グループが出来ており、平均100万件のデータが格納されています。

次にテーブルの容量を確認します。
※dbo.vTableSizeは「データの偏りに注意が必要(Azure Synapse Analytics SQLプール)」に作成方法を記載しています。
SELECT
database_name
, schema_name
, table_name
, distribution_policy_name
, distribution_column
, index_type_desc
, COUNT(distinct partition_nmbr) as nbr_partitions
, SUM(row_count) as table_row_count
, SUM(reserved_space_GB) as table_reserved_space_GB
, SUM(data_space_GB) as table_data_space_GB
, SUM(index_space_GB) as table_index_space_GB
, SUM(unused_space_GB) as table_unused_space_GB
FROM
dbo.vTableSizes
WHERE
table_name = 'TEST'
GROUP BY
database_name
, schema_name
, table_name
, distribution_policy_name
, distribution_column
, index_type_desc
ORDER BY
table_reserved_space_GB desc
;

大体1GB程度利用されているようです。
##検証②660万件データのロード
検証①で使用したテーブルに今度は660万件のデータをロードしてみます。この場合、ディストリビューション当たりの11万件のデータがロードされるので列ストアとして圧縮して格納されるはずです。
###1.データのトランケート
検証①のデータをトランケートで削除します。
TRUNCATE TABLE TEST;
###2.データのロード
660万件のデータをロードします。
INSERT INTO TEST SELECT TOP 6600000 * FROM LINEITEM;
###3.確認
ロード後の結果を確認します。
select
table_name
,table_partition_count
,row_count_total
,row_count_per_distribution_MAX
,COMPRESSED_rowgroup_rows
,COMPRESSED_rowgroup_count
,COMPRESSED_rowgroup_rows_AVG
,COMPRESSED_rowgroup_rows_MIN
,COMPRESSED_rowgroup_rows_MAX
,COMPRESSED_rowgroup_rows_DELETED
,OPEN_rowgroup_rows
,OPEN_rowgroup_count
,OPEN_rowgroup_rows_MIN
,OPEN_rowgroup_rows_MAX
,OPEN_rowgroup_rows_AVG
,CLOSED_rowgroup_rows
,CLOSED_rowgroup_count
,Rebuild_Index_SQL
from
vColumnstoreDensity
where
table_name = 'TEST'
;
660万件のデータがロードされています。

列ストアの中にデータが入っている事が確認出来ます。

デルタストア内の行ストアはやはり何も存在してないようです。

テーブルの容量も確認します。
--テーブルの件数とサイズを確認するSQL
SELECT
database_name
, schema_name
, table_name
, distribution_policy_name
, distribution_column
, index_type_desc
, COUNT(distinct partition_nmbr) as nbr_partitions
, SUM(row_count) as table_row_count
, SUM(reserved_space_GB) as table_reserved_space_GB
, SUM(data_space_GB) as table_data_space_GB
, SUM(index_space_GB) as table_index_space_GB
, SUM(unused_space_GB) as table_unused_space_GB
FROM
dbo.vTableSizes
WHERE
table_name = 'TEST'
GROUP BY
database_name
, schema_name
, table_name
, distribution_policy_name
, distribution_column
, index_type_desc
ORDER BY
table_reserved_space_GB desc
;

圧縮が効いているので、今度は300MB程度の容量となっています。
##検証③600万件×11回データをロード
この場合、10回目までのロードで各ディストリビューションの行ストアがほぼ最大件数(1,048,576件)近くまで到達し、11回目のロードで行ストアの最大件数を超え、デルタストアの行ストアCLOSEされ、列ストアにTuple Moverによって移行されるはずです。
###1.準備
検証②のデータをトランケートで削除します。
TRUNCATE TABLE TEST;
###2.データを10回投入
600万件ずつデータをまずは10回投入します。
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
###3.10回ロード完了後の確認
ロード完了後に列ストア、行ストア(デルタストア)の状況を確認します。
select
table_name
,row_count_total
,COMPRESSED_rowgroup_rows
,COMPRESSED_rowgroup_count
,COMPRESSED_rowgroup_rows_AVG
,OPEN_rowgroup_rows
,OPEN_rowgroup_count
,OPEN_rowgroup_rows_AVG
,CLOSED_rowgroup_rows
,CLOSED_rowgroup_count
from
vColumnstoreDensity
where
table_name = 'TEST'
;
60の行グループがデルタストアでOPENされており、列ストアは何もない事が分かります。

テーブルの容量を確認します。
--テーブルの件数とサイズを確認するSQL
SELECT
database_name
, schema_name
, table_name
, distribution_policy_name
, distribution_column
, index_type_desc
, COUNT(distinct partition_nmbr) as nbr_partitions
, SUM(row_count) as table_row_count
, SUM(reserved_space_GB) as table_reserved_space_GB
, SUM(data_space_GB) as table_data_space_GB
, SUM(index_space_GB) as table_index_space_GB
, SUM(unused_space_GB) as table_unused_space_GB
FROM
dbo.vTableSizes
WHERE
table_name = 'TEST'
GROUP BY
database_name
, schema_name
, table_name
, distribution_policy_name
, distribution_column
, index_type_desc
ORDER BY
table_reserved_space_GB desc
;
約9.5GBのデータ量であることが確認出来ます。

###3.11回目のロード
11回目の600万件のデータをロードします。(計6600万件のデータがロードされたことになります。)
INSERT INTO TEST SELECT TOP 6000000 * FROM LINEITEM;
###4.確認
ここで、行グループの状態を確認します。
select
table_name
,row_count_total
,COMPRESSED_rowgroup_rows
,COMPRESSED_rowgroup_count
,COMPRESSED_rowgroup_rows_AVG
,OPEN_rowgroup_rows
,OPEN_rowgroup_count
,OPEN_rowgroup_rows_AVG
,CLOSED_rowgroup_rows
,CLOSED_rowgroup_count
from
vColumnstoreDensity
where
table_name = 'TEST'
;
6600万件のデータが入り、デルタストアの60個の行グループがCLOSEされている事が分かります。
また、行グループの最大件数を超えたデータは新たなデルタストア内の行グループに格納されているようです。

時間がたつと徐々に、Tuple Moverによって列ストアに圧縮されていきます。

最終的には、CLOSEされた行グループはなくなり、列ストアにマイグレーションが完了した事が分かります。
※ただ、なぜ、列ストア内の行グループの数が120となっているのかわかりません。
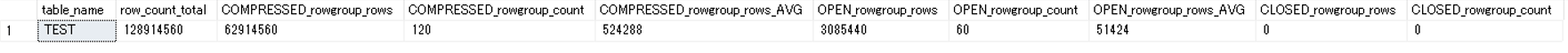
さらに時間が経過するとCLOSEされた行グループが削除されたものと思われますが、row_count_total等の値も6600万件にアップデートされます。
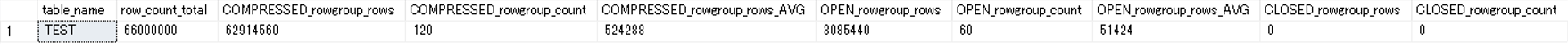
テーブルの容量を確認します。
--テーブルの件数とサイズを確認するSQL
SELECT
database_name
, schema_name
, table_name
, distribution_policy_name
, distribution_column
, distribution_id
, index_type_desc
, COUNT(distinct partition_nmbr) as nbr_partitions
, SUM(row_count) as table_row_count
, SUM(reserved_space_GB) as table_reserved_space_GB
, SUM(data_space_GB) as table_data_space_GB
, SUM(index_space_GB) as table_index_space_GB
, SUM(unused_space_GB) as table_unused_space_GB
FROM
dbo.vTableSizes
WHERE
table_name = 'TEST'
GROUP BY
database_name
, schema_name
, table_name
, distribution_policy_name
, distribution_column
, distribution_id
, index_type_desc
ORDER BY
table_reserved_space_GB desc
;
容量は3.2GBとなり、ここからも11回目をロードしかことにより、列ストアになって圧縮された事が分かります。

#最後に
マニュアルを読むだけでは、動作がわかりにくいですが、実際に動かしてみると大分理解が深まるような気がします。
ただ、検証③で、列ストアに行グループがなぜ120個出来たのかについてはよくわかりませんでした。もうすこし詳しく調べる必要がありそうです。Tuple MoverがCLOSEされた行ストアを列ストアに変換するタイミングで、行グループを分割しているように見えますが原因はよくわかりません。