Synapse SQLプールはデフォルトでクラスター化列ストアインデックスが作成されます。
今回はこのクラスター化列ストアインデックス(Clustered Column Store Index-CCI)について記載します。
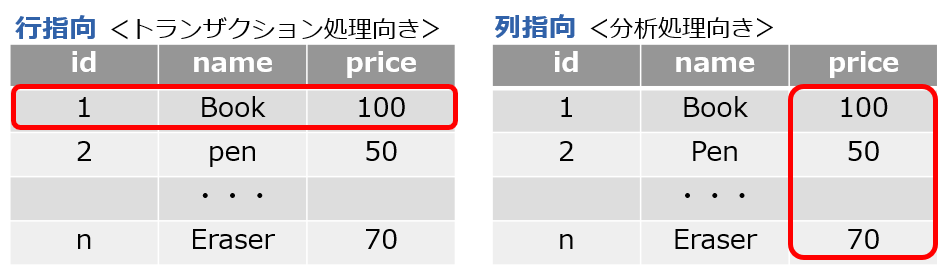
行指向と列指向
多くのデータベースで利用されている一般的なデータの格納形式は行指向と呼ばれる格納形式です。イメージ的には1つ1つの行をひとかたまりに扱っています。
一方、列指向とは列方向にデータをまとめて扱います。この為、特定の列の値をまとめて処理することに長けており、さらに列単位でデータが格納されている為、データを圧縮した時の圧縮効率も非常に良いとされています。
行指向が主にOLTP系のデータベースで使用されるのに対し、列指向はDWHなどの大容量データかつ、特定のカラムの集計処理などがよく行われるデータベースで利用されます。
クラスター化列ストアインデックス
クラスター化列ストアインデックスは列単位でデータを格納する列指向のオブジェクトとなります。また、「クラスター化列ストアインデックス」は「インデックス」とありますが、すべてのカラムのデータを持っています。(インデックスのリーフに実データが格納されます。)
クラスター化列ストアインデックスは、「行グループ」、「列セグメント」、「デルタストア」、「Delete Bitmap」、「Tuple Mover」などから構成されます。
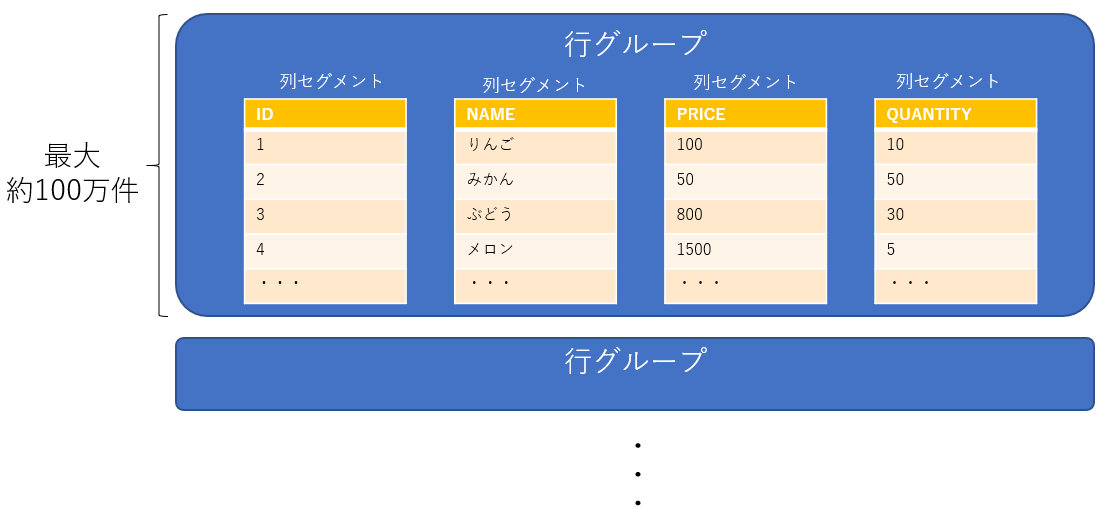
行グループと列セグメント
行グループは、列指向で格納されるデータのすべての列で構成され、最大で約100万件(実際には1,048,576件)のレコードの集合体です。また、データは列セグメントという列単位のデータセットで格納され、かつ圧縮された状態でストレージに格納されます。なので、行グループはデータの列数分だけ列セグメントを持っており、されに最大で約100万件のレコードで構成さることになります。
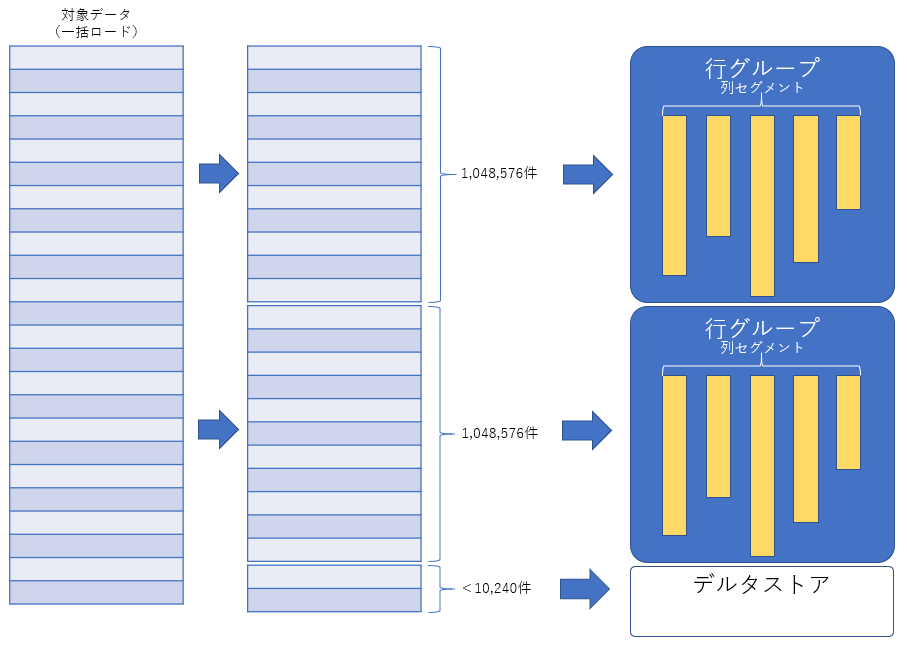
デルタストア
行グループを構成する時に、少ない行数で構成しても圧縮の効果を得ることができません。一定以上の件数で行グループを構成して初めて圧縮効率がよくなります。この「一定以上の件数」に到達するまでにデータを格納されるエリアがデルタストアです。行グループを構成可能な件数(最大で1,048,576件)のデータが格納されるまで、このデルタストアでデータは格納されますが、このデルタストアは列指向ではなく、行指向でデータが格納され、さらに非圧縮で格納されます。行グループ構成可能な件数に達したタイミングでバックグラウンドでTuple Moverにて行グループが作成されます。
行グループへの移行タイミングは以下の通りです。
- デルタストアが行数の上限に達するとOPEN状態からCLOSED状態に変更
-
Tuple Moverによりバックグラウンドで圧縮しながら行グループへ移動 - 移動が完了したデルタストア(厳密にはデルタ行グループ)をTOMBSTONE状態(破棄可能状態)に変更
- 参照が無ければ、TOMBSTONE状態のデルタストアを
Tuple Moverが削除
デルタストアに格納されるデータ、直接行グループに格納されるデータ
デルタストアは先ほど記載した通り、「行指向」、「未圧縮」となっており、集計などで意図せず性能劣化を招く可能性があります。なので、デルタストアに格納されるデータや、直接行グループに格納されるデータに関して記載します。
データをロードする場合、一回のロード(一括ロード)で102,400行に満たないデータをロードした場合、デルタストアにデータが格納されます。
また、一括ロードで1,048,576件以上のデータをロードする場合、1,048,576件単位で行グループが作成され、あまった行数が102,400行に満たなかった場合、デルタストアにこの「あまったレコード」のみ格納されます。
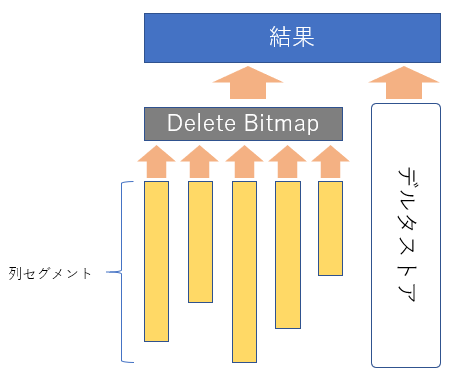
Delete Bitmap
クラスター化列ストアインデックスはDelete、Updateなどの更新処理も可能です。
一方で列セグメントのデータを直接更新するわけではなく、Delete Bitmap(削除済みマーク)とデルタストアでこれを実現します。
行が削除される場合、Delete Bitmapに対象のレコードが削除済みである旨マークします。
また、更新の場合はまず、Delete Bitmapに対象のレコードが削除済みである旨マークを行い、デルタストアに新しいデータを格納します。
一方列セグメント内ではなく、デルタストア内のデータをDelete、Updateする場合はDelete Bitmap等は利用せずにそのまま更新します。
クラスター化列ストアインデックスからレコードを取得する場合、各、列セグメントから情報を取得し、Delete Bitmapでフィルターがかかりさらに、デルタストアのデータとマージして出力することとなります。
クラスター化列ストアインデックスの全体像
今回様々な登場人物が出てきましたので、全体像を以下の通り図示します。
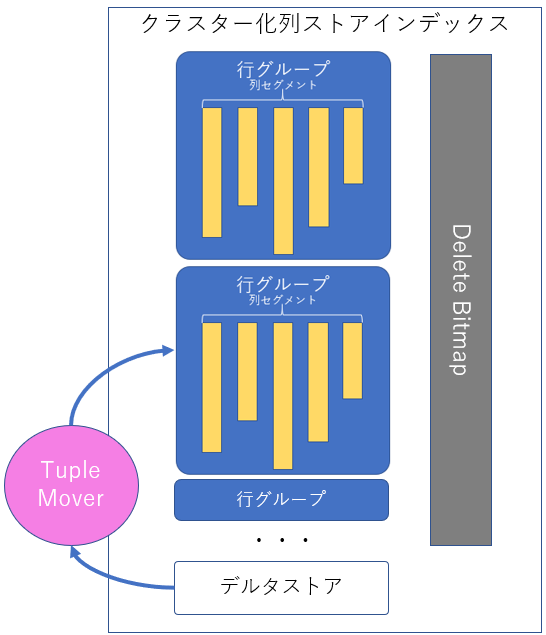
Synapse SQLプールのクラスター化列ストアインデックス
ここまで、クラスター化列ストアインデックスに着目して記載しました。Synapse SQLプールでも、このクラスター化列ストアインデックスの動きは同じです。ただ、一点異なるポイントがあります。それはSynapse SQLプールは60のディストリビューションが存在しており、各ディストリビューションにこのクラスター化列ストアインデックスが作成されるという事です。
すなわち、各ディストリビューションに最低でも100万件程度のデータが格納されなければ、各ディストリビューションで行グループが作成されず、デルタストアに格納されてしまいます。デルタストアでは前述の通り、「行指向」かつ「未圧縮」な状態となってしまいますので、本来の性能が発揮できません。
要するにSynapse SQLプールではクラスター化列ストアインデックスのパフォーマンスを得るためには最低で6000万件(100万件×60ディストリビューション)以上のデータが必要な事となります。
さいごに
Synapse SQLプールではクラスター化列ストアインデックスのパフォーマンスを得るために最低6000万件以上のデータが必要なようですが、パーティション分割した時にもこの考え方は適用されます。このあたりを次の機会に記載したいと思います。