前回以下のような記事を投稿させていただきました。
PolyBaseとCOPYはどっちがロードが早いか検証してみた(Azure Synapse Analytics SQLプール)
Azure Synapse Analytics SQLプールではデータベースへロードするファイルを、ロードの速度の観点から何かと分割する事が多いです。
何かいい方法が無いかと調べていましたらAzure DataFactoryを使えば簡単にファイルの分割が出来そうでしたので本記事にまとめておこうと思います。
※既にAzure DataFactory V2はリソース作成されている前提で記載をいたします。
Azure PortalよりOpen Azure Data Factory Studioを起動
まずは対象のAzure DataFactoryからOpen Azure Data Factory Studioを起動します。

データセットの作成
Open Azure Data Factory Studioが起動したら、分割対象のファイルと、分割後のファイルをそれぞれデータセットして登録します。
以下の通り、「データセット」→「新しいデータセット」でデータセットを作成します。
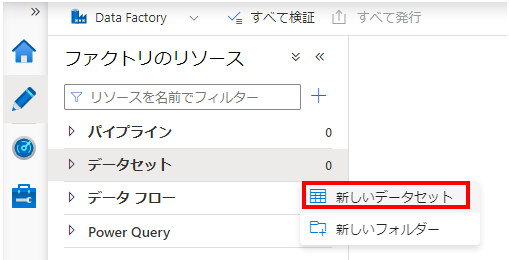
分割対象となる入力ファイル用のデータセットの作成
データストアの選択
今回はAzure Data Lake Storage Gen2のデータを対象としますので、「Azure Data Lake Storage Gen2」をデータストアとして選択します。

データの形式の選択
対象のファイルはCSVファイルとなるため、「DelimitedTxet」を選択します。

各種プロパティの設定
データセットの各種プロパティを入力します。「名前」、「リンクサービス」、「ファイルパス」を指定します。ファイルパスはAzure Data Lake Storage Gen2上の対象のファイルを指定しています。
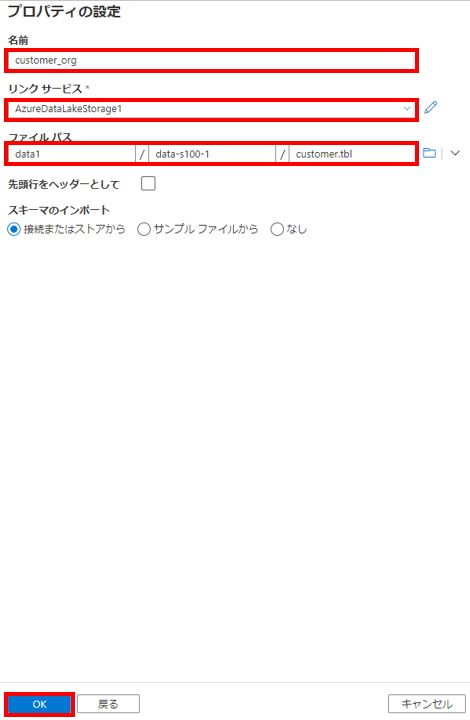
※また、リンクサービスが存在してなかったので、上記画面上で、Azure Data Lake Storage Gen2へのリンクサービスの作成も行っています。

その他の設定
各種プロパティの設定後、その他の設定値を変更します。当該CSVですが、区切り文字が「パイプ(|)」なので変更します。
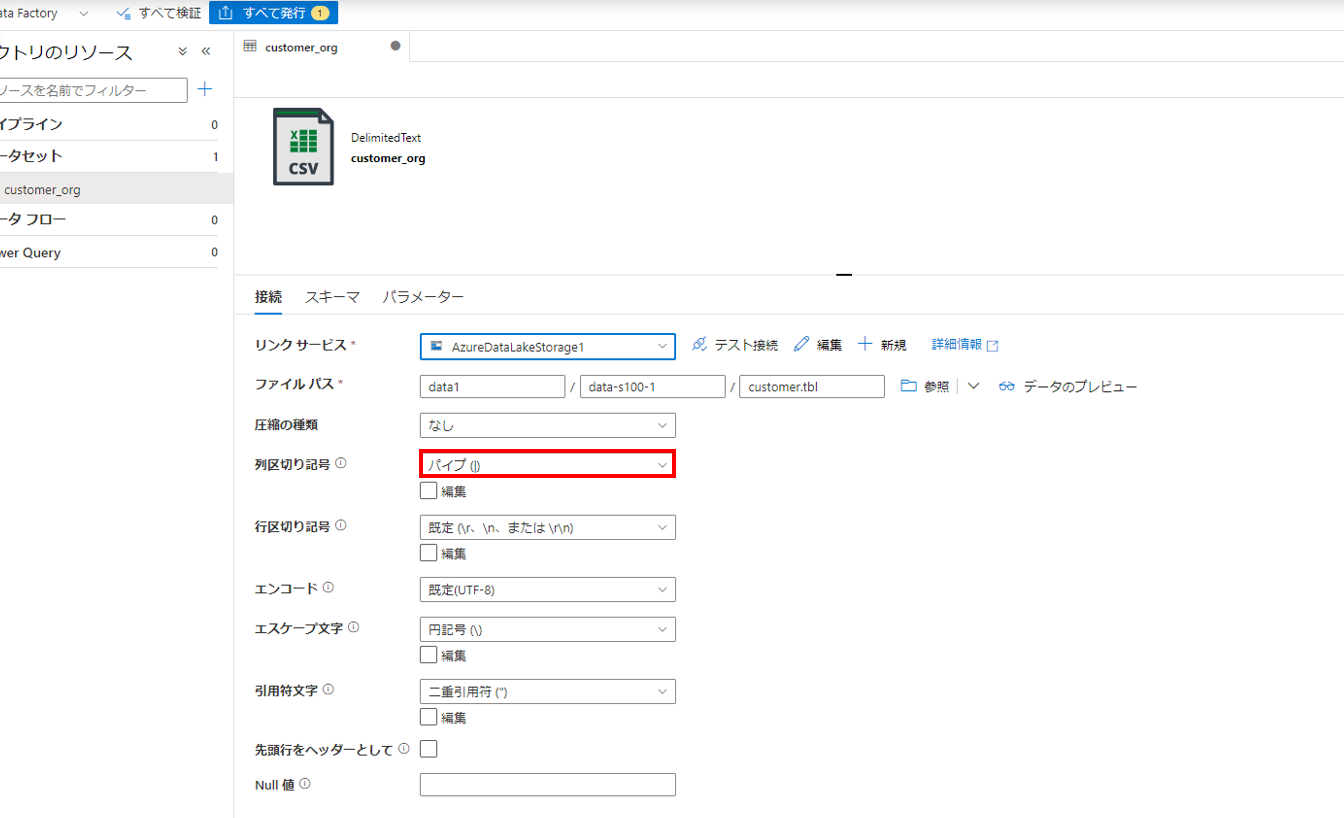
さらに、「スキーマ」タブより「スキーマのインポート」→「接続またはストアから」を選択します。

分割後の出力ファイル用のデータセットの作成
次に分割後の出力ファイル用のデータセットの作成をします。基本は「分割対象となる入力ファイル用のデータセットの作成」と同じなので、似たような場所は割愛し、各種プロパティの設定から記載します。
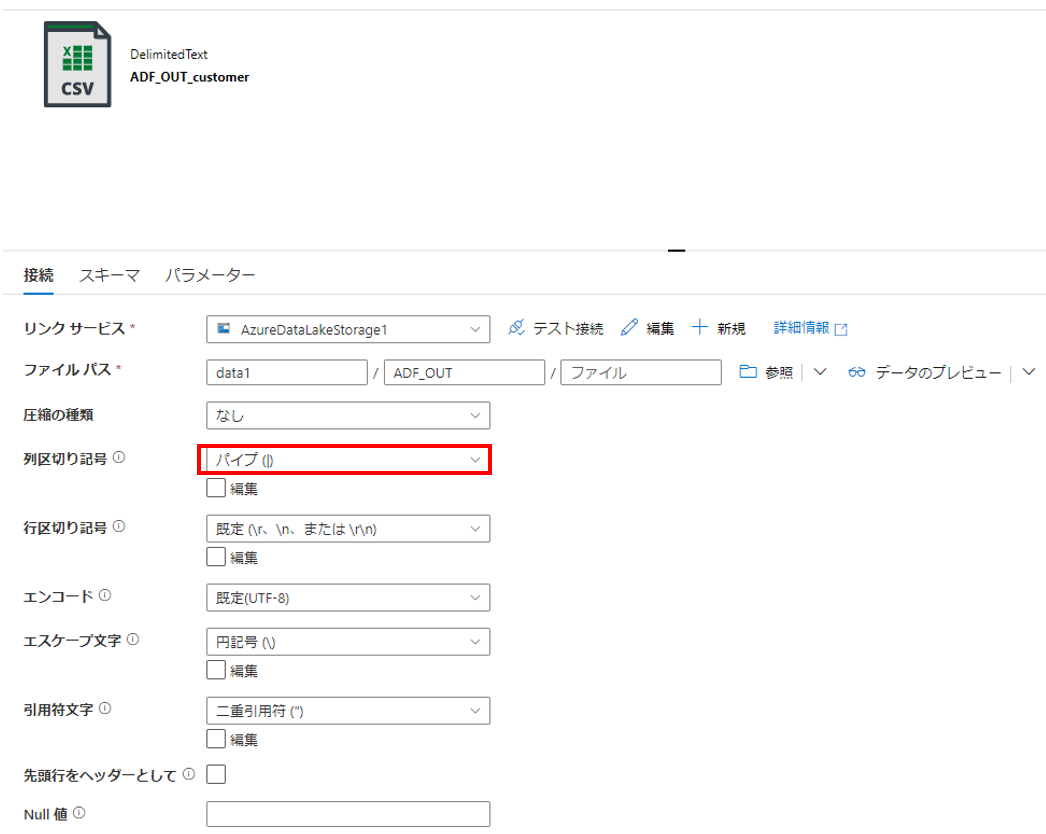
各種プロパティの設定
「名前」や「リンクサービス」を指定します。またファイルパスですが今回は、「ファイル システム」、「ディレクトリ」のみ指定し、「ファイル」は空白のままとします。

その他の設定
こちらも入力ファイルと同様に「列の区切り記号」を「パイプ(|)」に変更します。
データフローの作成
次にデータフローの作成を行います。
「データフロー」→「新しいデータフロー」を選択します。

ソースの追加
以下の通りソースの追加を選択します。

ソースの設定
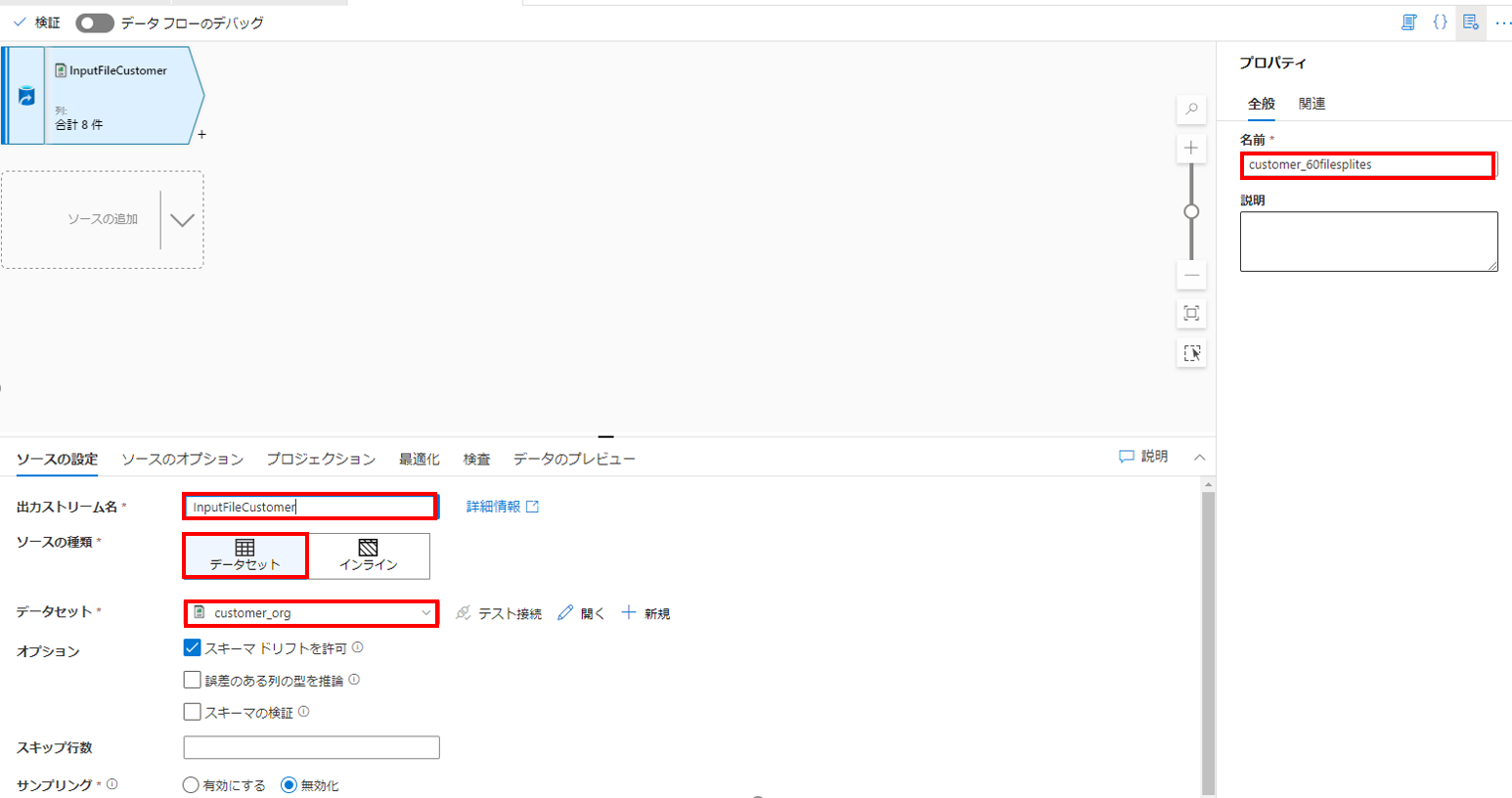
「出力ストリーム名」に適当な名前を入力し、ソースの種類に「データセット」を選択、「データセット」では先ほど作成した分割対象となる入力ファイル用のデータセットである「customer_org」を入力。
※ついでに右側のプロパティでこのデータフローの名前も入力します。
シンクの追加
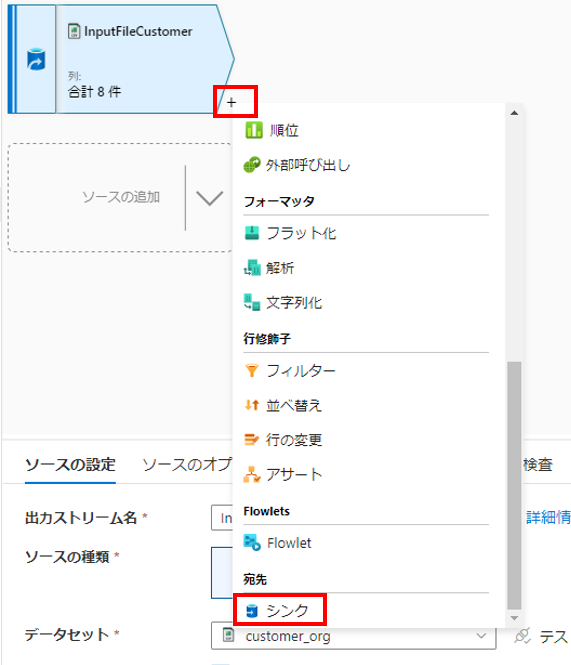
以下の通り、「+」を押下して、「シンク」を選択し、データフローにシンクを追加します。
シンクの設定
「出力ストリーム名」に適当な名前を入力し、「着信ストリーム」は先ほど作成した、ソースを選択します。シンクの種類で「データセット」を選択し、「データセット」では分割後の出力ファイル用のデータセットとして作成した「ADF_OUT_customer」を選択します。

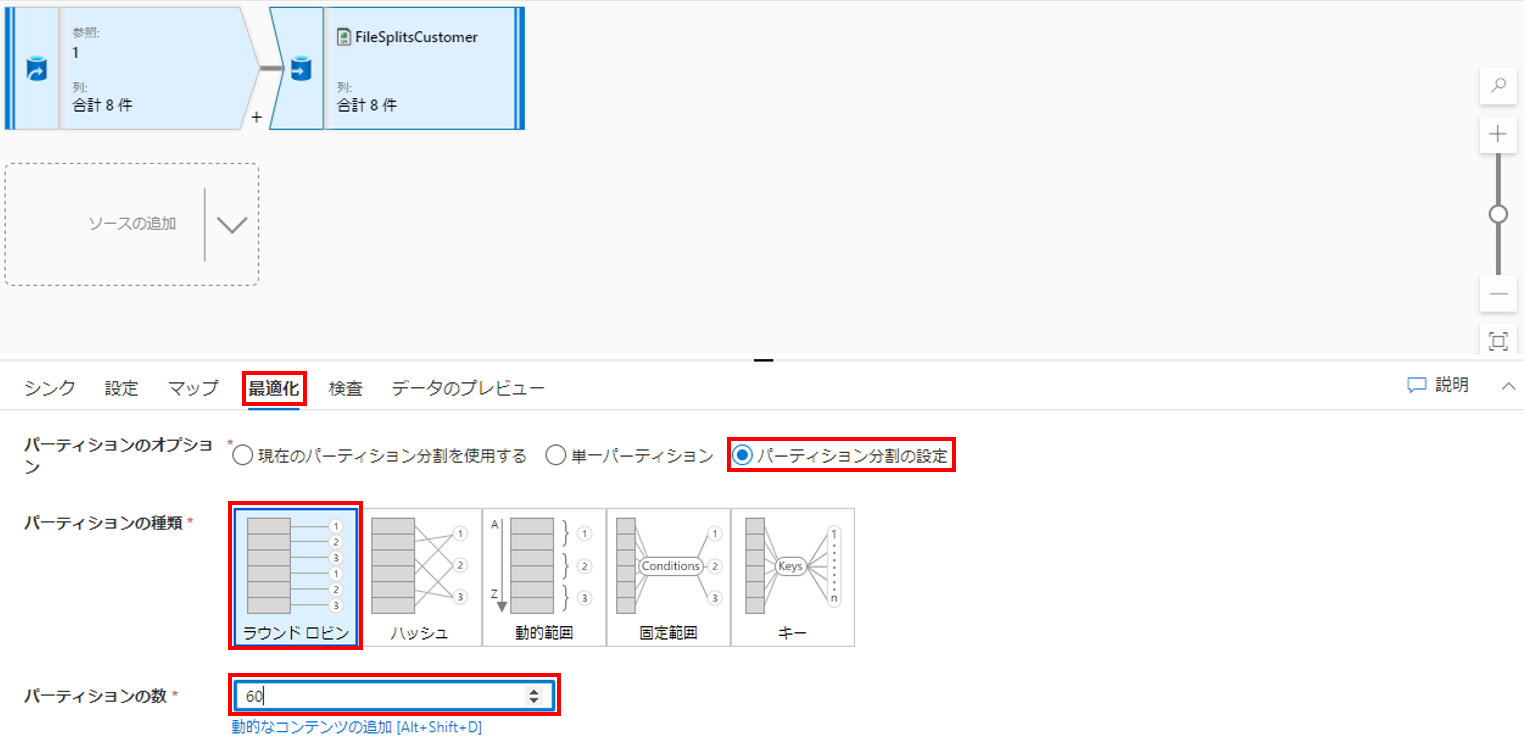
シンクの最適化
シンクの「最適化」タブを選択します。パーティションのオプションから「パーティション分割の設定」を選択、パーティションの種類に「ラウンドロビン」を選択します。また、パーティションの数では分割後のファイル数を指定します。今回は60個のファイルに分割したいので「60」を入力しました。
パイプラインの作成
次にパイプラインを作成します。

パイプラインにデータフローを設定
先ほど作成したデータフローをドラッグ&ドロップでパイプラインに設定します。また、ついでに右側のパイプラインのプロパティでパイプラインに適当な名前を入力します。

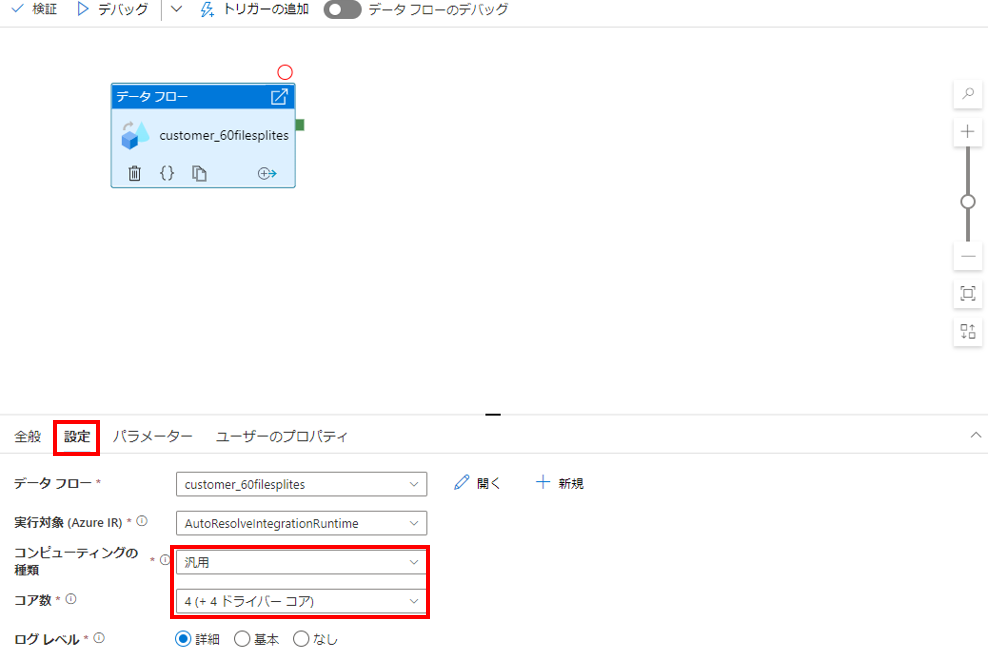
パイプラインの設定
パイプライン上のデータフローが実行する時のリソースを、「設定」タブより変更できます。ファイル分割に時間がかかりすぎてしまう場合、ここを見直してみるのもいいかもしれません。※今回はデフォルトのまま設定しました。
Azure DataFactoryのデプロイ
これまで作成した各種Azure DataFactoryのリソースをデプロイします。「すべて発行」を押下すればデプロイできます。

パイプラインの実行
デプロイ完了後、パイプラインを実行します。「トリガーの追加」より「今すぐトリガー」にてパイプラインの実行が可能です。

実行完了後以下の通り、60個のファイルが出力されている事がAzure Data Lake Storage Gen2の指定のディレクトリの中で確認できます。

最後に(Azure Synapse Analytics SQLプールへの取り込み)
分割したファイルがAzure Synapse Analytics SQLプールへ取り込めるか確認します。
COPY INTO CUSTOMER --ロードするテーブル名を指定
FROM 'https://<ストレージアカウント名>.blob.core.windows.net/data1/ADF_OUT/part*' --ロードするファイル指定
WITH (
FILE_TYPE = 'CSV' --ファイルフォーマット指定
,CREDENTIAL = (IDENTITY= 'Storage Account Key', SECRET='<ストレージアカウントのキー>') --ストレージアカウントキーで認証
,FIELDTERMINATOR='|' --デリミタ(|)
,ROWTERMINATOR = '0x0A' --改行コード(LF)
);
--件数のカウント
select count(*) from customer;
無事取り込みが行う事が出来ました。
