ロードが高速に可能なPolyBaseとCOPY
Azure Synapse Analytics SQLプールではBLOB、Azure DataLake Storageから高速にロードするコマンドが2つ用意されています。それがPolyBaseとCOPYコマンドです。
2つともロードは高速に行われるとのことですが、今回はどちらが高速に処理可能なのか検証を行ってみました。
検証
TPC-HのLINEITEMと言うテーブルをAzure Synapse Analytics SQLプールでPolyBaseとCOPYを使いながら様々なシチュエーションでロードしてみます。ロードするLINEITEMはCSV形式となっており、非圧縮で約74GBあります。(gzip圧縮すると約22GB)
ロード時に使うリソースクラスはそれぞれ同じxlargercと言うものを使用します。
パターン①:ファイルを60分割/gzip圧縮でロード
CSVファイルを60個のファイルに分割し、それぞれのファイルをgzipで圧縮します。gzip圧縮された60個のファイルのロード時間で違いが出るのか検証しました。
結果
| DWUc | PolyBase | COPY |
|---|---|---|
| DW100c | 2,307,466ms | 1,759,206ms |
| DW500c | 498,640ms | 546,726ms |
DWU100cの時にCOPYコマンドの方が約1.3倍高速にロードできました。DW100cではそもそも実行時間が長いので、この差は大きいかもしれません(10分程度の差があります)。
パターン②:ファイルを60分割/未圧縮でロード
パターン②では、CSVファイルはパターン①同様に60個に分割しますが、今度は圧縮を行わず非圧縮の状態でロードします。この状態でロード時間で違いが出るのか検証します。
結果
| DWUc | PolyBase | COPY |
|---|---|---|
| DW100c | 2,548,196ms | 1,380,513ms |
| DW500c | 521,326ms | 527,090ms |
DWU100cの時の性能差がパターン①よりも大きくなりました。PolyBaseは圧縮したファイルと比べて未圧縮の方が多少遅くなりましたが、COPYコマンドでは未圧縮の方が1.3倍程度高速になり、結果PolyBaseとCOPYの性能差は約2倍となりました。(約20分の違い)
一方でDW500cでの性能差はほとんどありません。
パターン③:ファイル分割なし(1ファイル)/非圧縮でロード
パターン③ではファイルの分割は行わず1ファイルにてロードを行いました。この時ファイルの圧縮は行いません。
結果
| DWUc | PolyBase | COPY |
|---|---|---|
| DW100c | 2,413,576ms | 5,640,390ms |
| DW500c | 504,766ms | 5,206,806ms |
パターン③ではCOPYコマンドが非常に遅い状況でした。また、DWUcを変更しても全く性能が上がらずDW500cとDW100cとでは性能は変わりませんでした。このことからCOPYコマンドではファイルの分割は必須だという事が分かります。
一方でPolyBaseではファイルを分割していなくても、内部で自動で分割されてくれるようです。(ただし、ファイルが非圧縮の状態に限ります。Azure Synapse Analyticsでデータをロードする時にファイルは分割した方がいい?分割しなくてもいい?)
検証の結果
パターン③よりCOPYコマンドでは__圧縮、非圧縮に限らずファイルの分割は必須__です。ちなみに最適なファイルの分割数は以下の以下のURLが参考になりそうです。
https://docs.microsoft.com/ja-jp/sql/t-sql/statements/copy-into-transact-sql?view=azure-sqldw-latest#faq
パターン①、②からDWUcがDW100cのように非常に小さい場合ではCOPYコマンドを用いて非圧縮の適切に分割されたファイルをロードするのが良いように思います。
一方でDWUcを上げるていくと、その差はなくなりどちらかと言うとPolyBaseの方が早いように見えます。
ただし、そこまで大きな差はなさそうなのでDW500c以上の環境では、ロードする対象のファイルを分割等がきっちりとされていれば、PolyBaseかCOPYかはあまり気にする必要はなさそうです。
※どうしてもこだわりたい場合は、ファイルを適切に分割し、gzipで圧縮したPolyBaseを選択しておけば間違いないと思います。
終わりに
今回はCSVでの検証でしたが、他にもparquet 形式、ORC形式での取り込みが可能です。これらファイルの場合には上記の結果となるかはわかりませんので、どこかで検証してみてみたいと思います。
COPYコマンドがファイル分割無しで遅かった理由についての考察
COPYコマンドでファイルの分割の有無でDMSの動きに違いが無いか確認してみました。
確認のSQLは以下の通りです。
--実行中のクエリを確認する
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE status not in ('Completed','Failed','Cancelled')
AND session_id <> session_id()
ORDER BY submit_time DESC;
--dmsの状況の確認
SELECT * FROM sys.dm_pdw_dms_workers
WHERE request_id = '<QIDから始まるrequest_id>';
以下は60ファイルで分割されているときの状況ですが、HASH_READERがたくさん(60)立ち上がっており、パラレルでデータを読み込んでいる状況を確認出来ます。
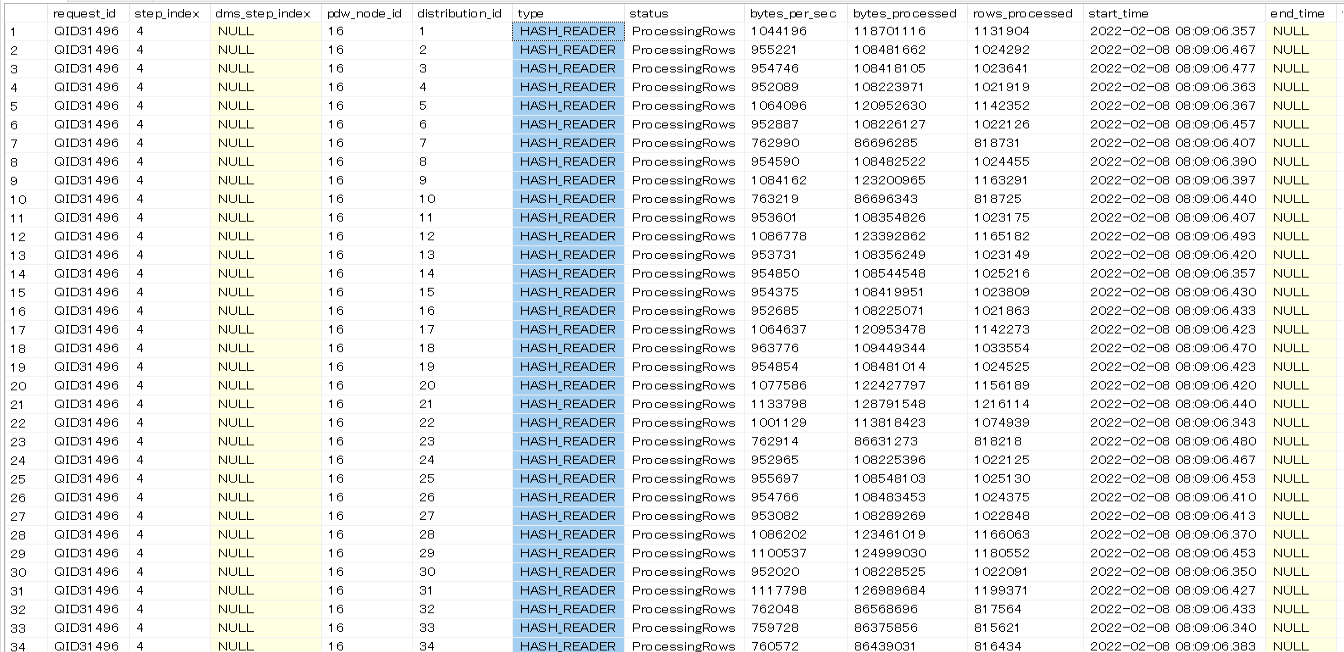
以下は1ファイルで分割がされていない状況ですが、先ほどと違いHASH_READERが1つしか立ち上がっていません。なのでシリアルでデータを読み込んでいる状況であると推察されます。
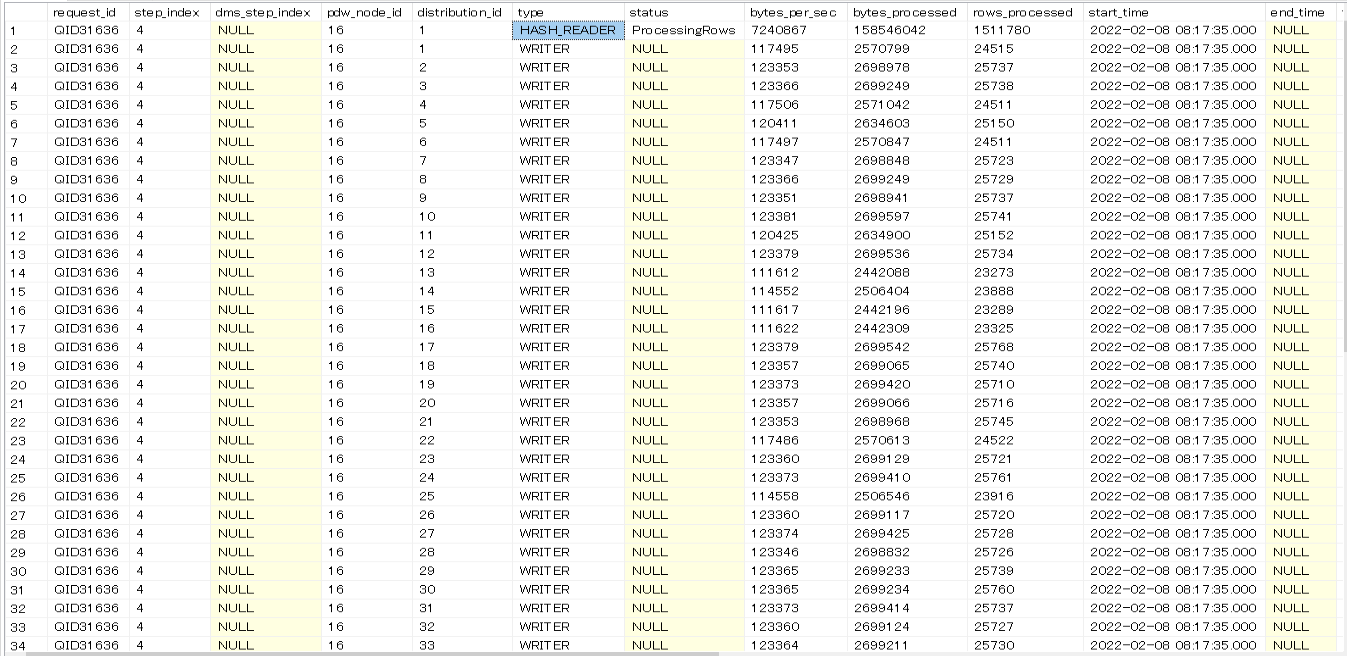
WRITERの数はファイル分割の有無にかかわらず60でした。ファイル分割しないとパラレルでデータが読み込まれず、これが分割しないと遅い原因であると考えられます。
また、HASH_READERは1つのコンピュートノード当たり60個起動するようです。DW1000cでは2つのコンピュートノードが起動しますが、ファイルの推奨分割数が120となっているのはこのためであると思われます。(最大のDW30000cでは60のコンピュートノードが起動しますが、60ノード×60プロセス=3600ファイルとなり、こちらも推奨の値と合致します。)