GraphStudioとは
TigerGraph GraphStudio(以降、GraphStudio)はグラフアプリケーション開発・管理のためのブラウザベースの直感的なインターフェイスです。ユーザはノーコード(またはローコード)でグラフをセットアップし利用することができます。
GraphStudioの機能
GraphStudioでは以下の機能を提供しています。
-
設計スキーマ
グラフスキーマを編集することができます。スキーマに追加した各ノードやエッジの属性やフィールドを追加・編集することができます。 -
データマッピング
外部ファイルからデータを追加し、スキーマ内の対応するノードやエッジにマッピングします。 -
データの読み込み
マッピングで指定されたデータをデータベースにロードします。 -
グラフの探索
グラフデータを探索することができます。グラフ内のエッジの検索、近接するノード、ノード間のエッジの検索、GSQLクエリーの実行が可能です。またグラフ探索パネルを使用して、データ探索結果のビジュアライゼーションを変更・拡張することができます。 -
グラフパターン作成
ドラッグ&ドロップでグラフクエリを視覚的に構築することができます。これにより、ユーザーはクエリを書くことなくデータを探索することができます。 -
クエリーを書く
テキストベースのクエリエディタを使用して、GSQLクエリを作成しテストすることができます。クエリエディタはユーザーのクエリ構文を検証しエラーがあればユーザーに通知します。 -
既存ソリューションのインポート
バックアップまたはTigerGraphが提供するソリューション(スキーマとサンプルデータ)ファイルを取り込みます。tarball(tar.gz)ファイルをインポートします。 -
現在のソリューションのエクスポート
現在のデータベースに構築されたスキーマ、データマッピング、クエリをエクスポートします。tarball(tar.gz)ファイルとして出力されます。 -
操作
管理者にのみ提供される機能でありデータの削除やグラフデータベースの再構築を行います。

GraphStudioのデザインと対応している言語
GraphStudioは現時点では以下の言語に対応しています。
- 英語
- 中国語
- 日本語
またUIのデザインテーマとしてLightとDarkデザインが選択できます。
これらの変更は画面右上のユーザアイコンを押下することで、選択可能です。
TigerGraphデータベースのインスタンス構造
グラフデータベース インスタンスでは以下の図のとおりオブジェクトが定義・保存されます。
インスタンス(Global View)内に各グラフを定義します。このグラフにはスキーマとそれに紐付くデータ、そしてクエリが保存されます。スキーマはインスタンス直下にグローバルオブジェクトとして定義することも可能です。グローバルオブジェクトは各グラフに利用できるので繰り返し利用するオブジェクトに「定義ずれ」がおきることがありません。

GraphStudioのハンズオン
では実際にGraphStudioを利用してグラフをセットアップしていきましょう。
以下の手順はTigerGraph Cloudでインスタンス構成が完了していることを前提としていますので、まだインスタンスを作成していない場合は「TigerGraphをさわってみよう」記事を参考に環境を用意ください。
手順1から4まで、と手順5で章立てを分割しています。
手順概要
- スキーマを定義する
- グラフを作成する
- データマッピングを作成する
- データをロードする
- 分析する
※ この手順はグローバル スキーマを利用する方法です。グラフ内(ローカル)で定義する場合、手順1と2は入れ替わります。
スキーマ&データ セットアップ
0. セットアップの前に(環境の開始)
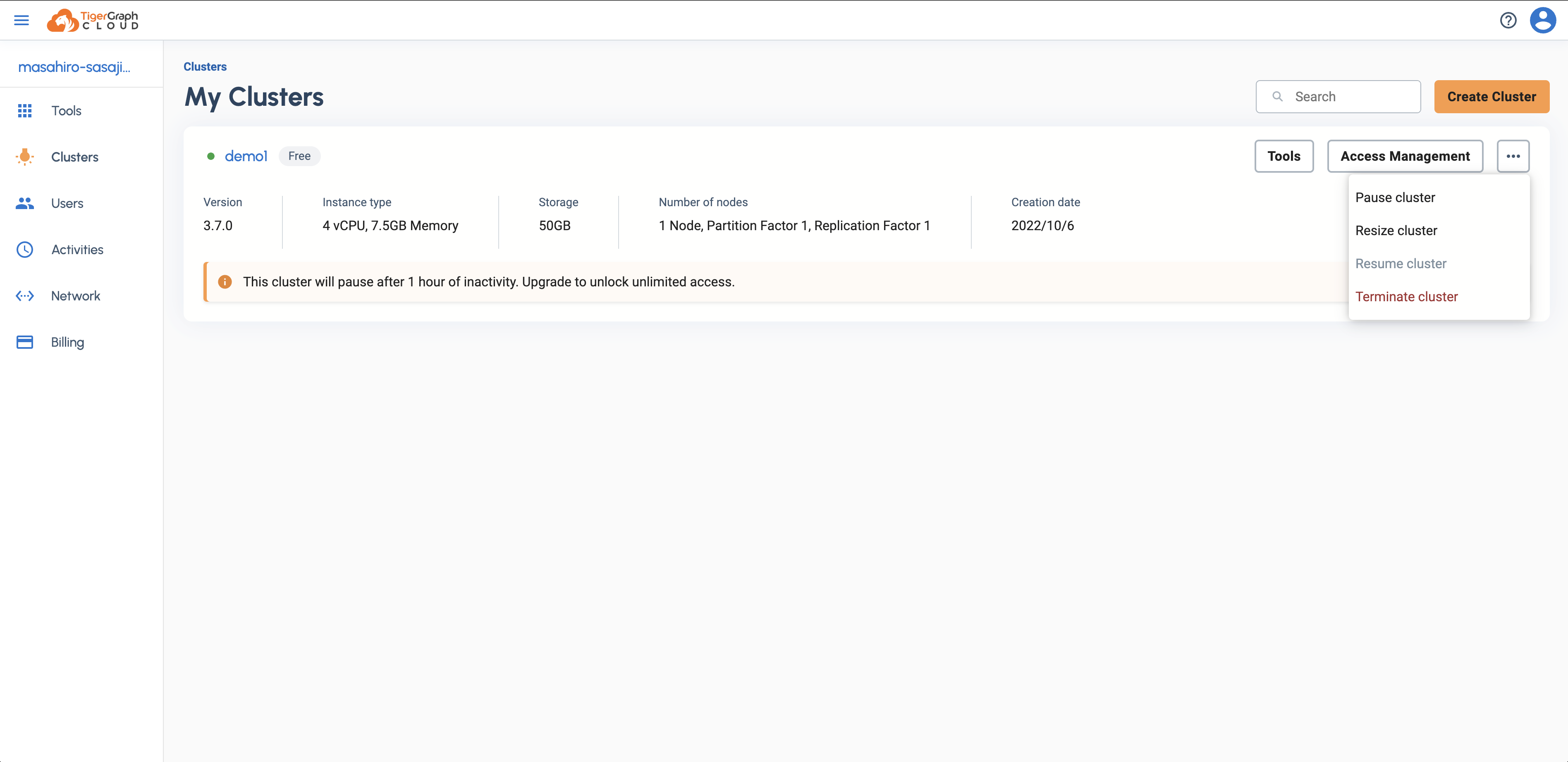
TigerGraph Cloudにログインし、左ペインメニューからClustersを選択します。利用するインスタンスが稼働しているかを確認し、停止している(Pause)場合は該当インスタンス右上にある「…」メニューから「Resume cluster」を選択してサービスを起動します。
サービス起動後(インスタンス名の左側の○が緑色)、「Tools」メニューから「GraphStudio」を起動します。
1. スキーマを定義する
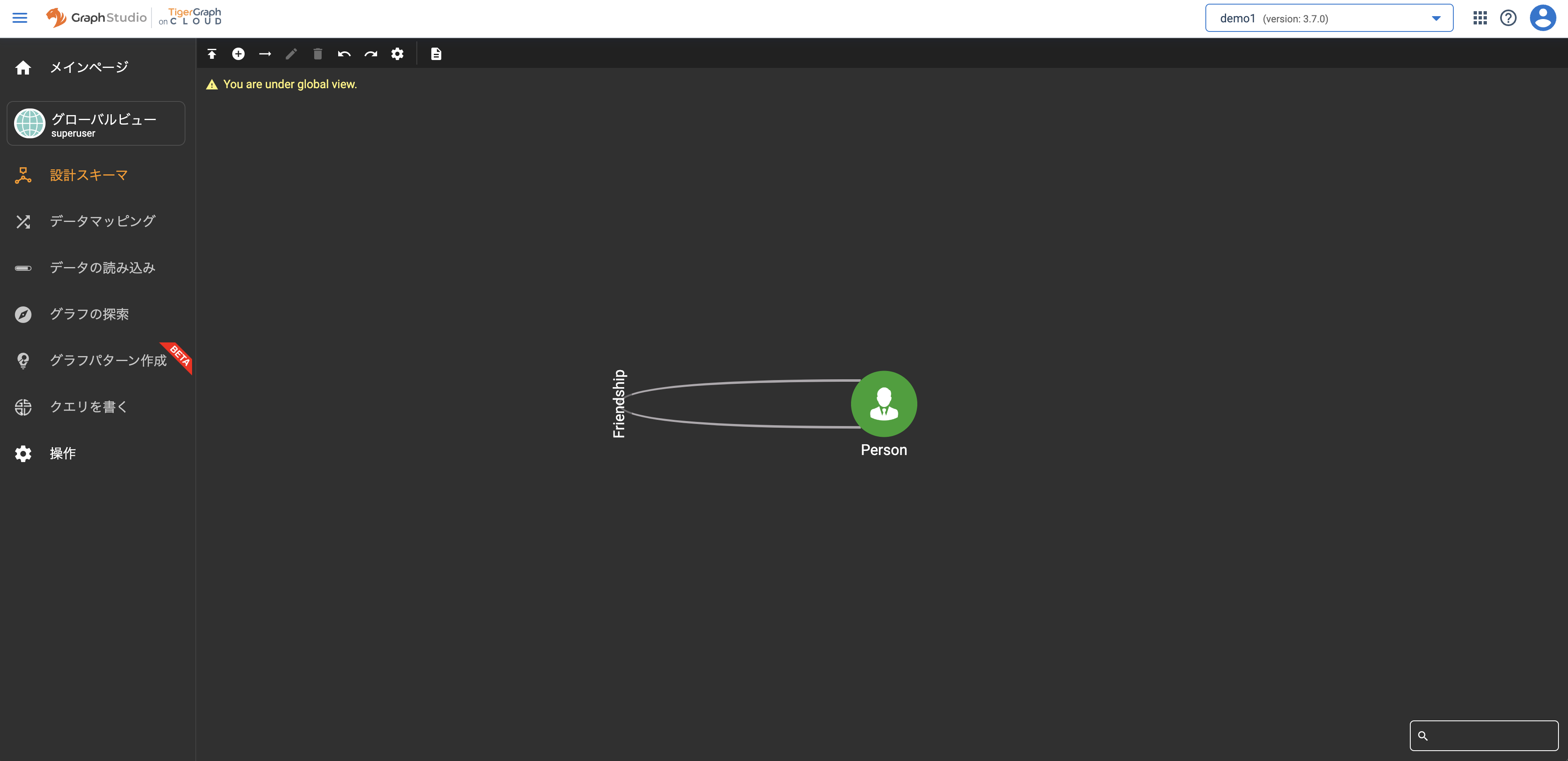
GraphStudioに遷移したら、左ペインメニューのグラフアイコンが「グローバルビュー」であることを確認し、「設計スキーマ」を押下します。
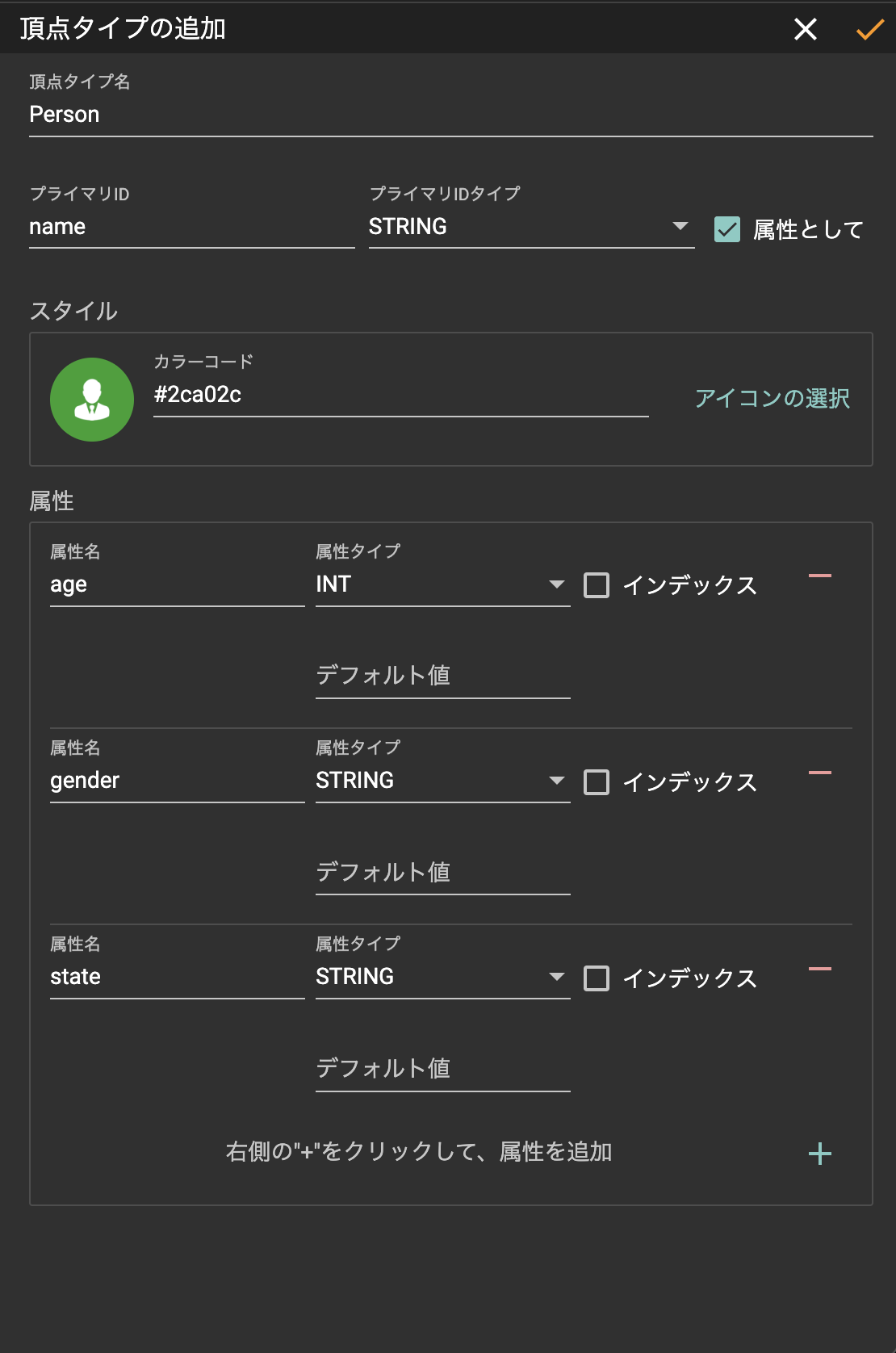
GraphStudioのツールバー(上部のアイコン群)から「+」アイコンを押下してバーテックス(ノード)を定義します。定義が完了したら、ツールバー右にある「✓」を押下して保存します。
定義内容 - Vertex
| 項目 | 設定値 |
|---|---|
| 頂点タイプ名 | Person |
| プライマリID | name |
| プライマリIDタイプ | STRING |
| 属性として | チェックあり |
| 属性名 | 属性タイプ |
|---|---|
| age | INT |
| gender | STRING |
| state | STRING |
スタイルは色とアイコン(必要に応じて)を設定可能です。任意の色やアイコンを設定ください。
次にツールバーにある「→」アイコンを押下してエッジを定義します。アイコンを押下したら関係を紐付けるバーテックスをFrom、Toの順番で選択します。このハンズオンではPersonからPersonを紐付けるエッジとして定義します。定義が完了したら、ツールバー右にある「✓」を押下して保存します。
定義内容 - Edge
| 項目 | 設定値 |
|---|---|
| エッジタイプ名 | Friendship |
| 有向エッジ | (なし) |
| ソース頂点タイプ | Person |
| ターゲット頂点タイプ | Person |
| 属性名 | 属性タイプ |
|---|---|
| connect_day | DATETIME |
スタイルは色とアイコン(必要に応じて)を設定可能です。任意の色やアイコンを設定ください。

バーテックス、エッジの定義が完了したらツールバーにある「↑」アイコンを押下して定義を公開(パブリッシュ)します。
無事に公開されたら定義は完了です。
2. グラフを作成する
左ペインメニューからグラフメニュー(グローバルビューと表示されている箇所)を押下し、「グラフの作成」を選択します。グラフ名を設定し、手順1で作成したバーテックス(Person)とエッジ(Friendship)を選択後「作成」ボタンを押下します。
作成後、自動的に作成したグラフが選択された状態になります。切り替わっていない場合は左ペインメニューからグラフ→作成したグラフを選択してください。グローバルスキーマのオブジェクトは地球儀のアイコンが付与されます。
定義内容 - グラフ
| グラフ名 | Social |
|---|

3. データマッピングを作成する
左ペインメニューからデータマッピングを選択し、バーテックスとエッジにそれぞれデータ項目をマッピングしていきます。このハンズオンでは以下のCSVデータをローカル端末からアップロードして定義します。
CSVファイルはUTF-8(BOMなし)で保存してください。以下のハンズオンのサンプルデータは半角英数しか含まれていませんが、ダブルバイト文字を取り込む場合に文字化けします。
person.csv
name,gender,age,state
Tom,male,40,ca
Dan,male,34,ny
Jenny,female,25,tx
Kevin,male,28,az
Amily,female,22,ca
Nancy,female,20,ky
Jack,male,26,fl
friendship.csv
person1,person2,date
Tom,Dan,2017-06-03
Tom,Jenny,2015-01-01
Dan,Jenny,2016-08-03
Jenny,Amily,2015-06-08
Dan,Nancy,2016-01-03
Nancy,Jack,2017-03-02
Dan,Kevin,2015-12-30
ツールバーから「+(データファイルの追加)」を押下し、データソースタイプの選択で「ローカルファイル」を選択します。自身のパソコン内のファイルをアップロードします。データ形式の選択画面でCSVを選択します。
同じファイル形式のファイルは複数まとめてアップロードすることができます。

ローカルファイルを選択の画面まで遷移したら、person.csvを選択します。
選択するとデータのプレビューが表示されるので取り込むための書式を設定します。
※ End Of Lineは「\n」で設定していますが、必要に応じて変更してください。
person.csv - ファイル書式
| File format | text |
|---|---|
| Delimiter | , (カンマ) |
| End Of Line | \n (バックスラッシュn) |
| Enclosure character | none |
| Has header | チェックあり |
person.csvファイルが取り込まれたら、キャンバス上に表示されます。
続いて同様の操作をおこないfriendship.csvファイルを取り込みます。
friendship.csv - ファイル書式
| File format | text |
|---|---|
| Delimiter | , (カンマ) |
| End Of Line | \n (バックスラッシュn) |
| Enclosure character | none |
| Has header | チェックあり |

ファイルが取り込まれたらマッピングを定義します。ツールバーから「矢印が交差するアイコン」を選択し、「person.csv」、「Person」の順番で選択します。キャンバスの右側にマッピング画面が表示されるので左のテーブル(ファイル)の項目から右のテーブル(バーテックス)の項目へドラッグ&ドロップしてマッピングを作成します。
マッピングを間違えた場合は、間違えたマッピングの線にマウスオーバー(マウスカーソルを線上にあわせる)と「×(削除)」アイコンが表示されるので、削除することができます。
マッピング定義 - person.csv to Person
| file: person.csv | Person バーテックス |
|---|---|
| name | name |
| gender | gender |
| age | age |
| state | state |

Personバーテックスへのマッピングが完了したら続いてFriendshipエッジへのマッピングを設定します。ツールバーから「矢印が交差するアイコン」を選択し、「friendship.csv」、「Friendship」の順番で選択します。キャンバスの右側にマッピング画面が表示されるので左のテーブル(ファイル)の項目から右のテーブル(エッジ)の項目へドラッグ&ドロップしてマッピングを作成します。
マッピング定義 - friendship.csv to Friendship
| file: friendship.csv | Friendship エッジ |
|---|---|
| person1 | Source VertexのPerson |
| person2 | Target VertexのPerson |
| date | connect_day |

マッピングの定義が完了したらツールバーにある「↑」アイコンを押下して定義を公開(パブリッシュ)します。
無事に公開されたら定義は完了です。

4. データをロードする
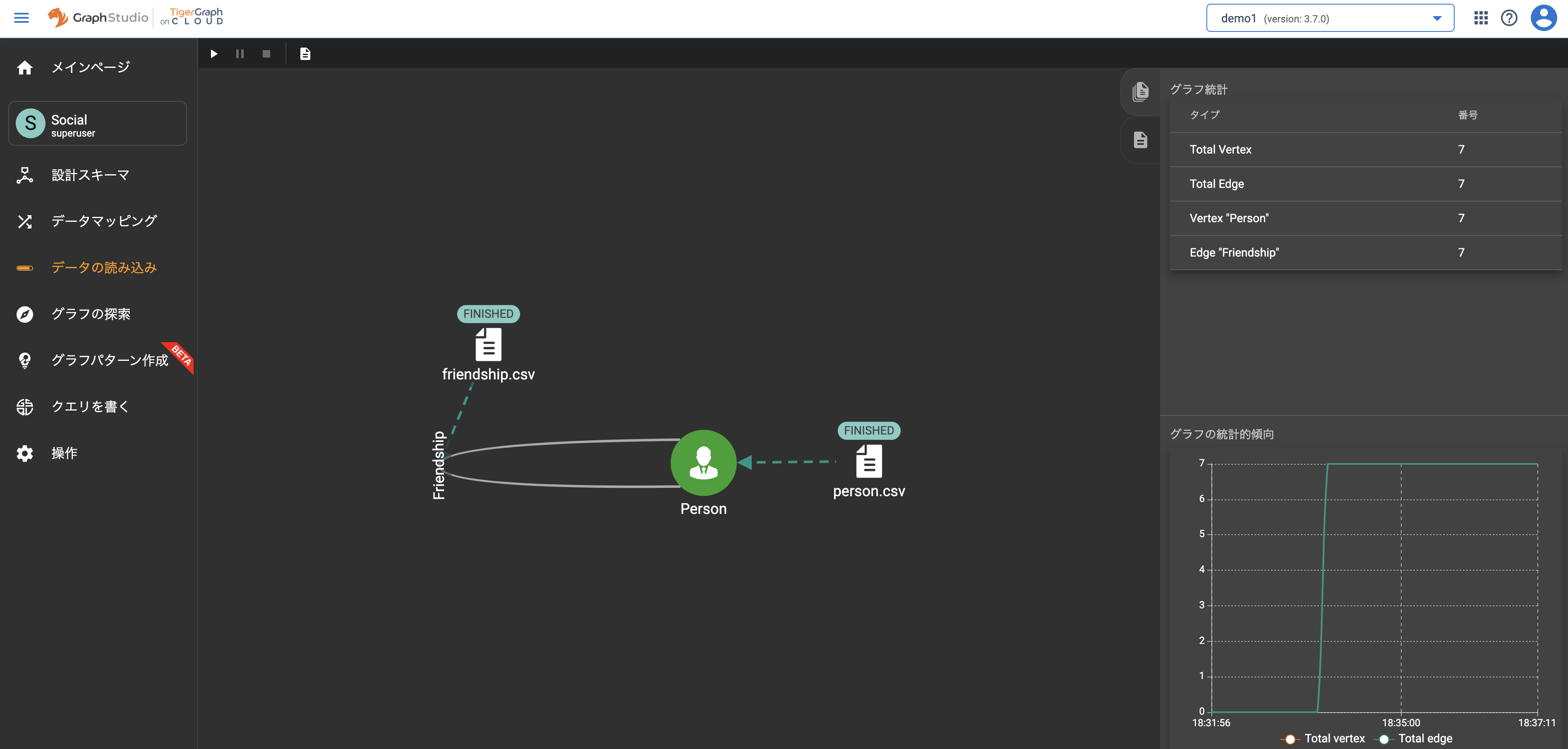
左ペインメニューからデータの読み込みを選択します。ツールバーにある「読み込みの開始/再生(再生アイコン)」を押下しデータをロードします。データロードが完了すると各ファイルのアイコン上に「FINISHED」マークが表示されます。
今回のサンプルデータを取り込むと以下のデータ件数がロードされます。
データロード件数
| タイプ | 件数 |
|---|---|
| Vertex - Person | 7 |
| Edge - Friendship | 7 |
番外編. ロードされたデータを削除する
ロードされたデータを削除する場合は、管理者権限をもつユーザでGraphStudioにログイン後 左ペインメニューから操作メニューへ遷移し「すべてのグラフデータをクリアする」を選択します。警告メッセージが表示されるのでガイドに従って実行してください。

番外編. ここまで構築した内容をクエリ言語で確認する
GSQL Shellツールを利用することでここまで定義した内容を確認することができます。
TigerGraph Cloudのコンソール>左ペインメニューからClustersを選択し、該当するインスタンスのToolsからGSQL Shellを選択します。
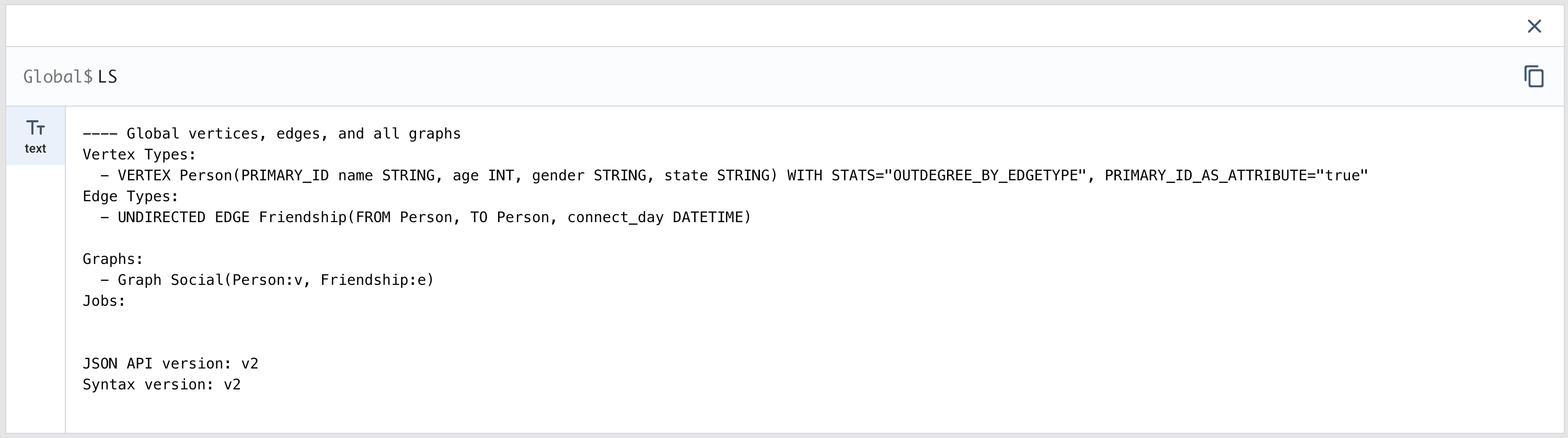
コンソール上で以下のコマンドを実行することで定義されているオブジェクト情報を確認することができます。コマンドを入力後、
コマンド(シェル入力部分にコマンドを入力。「Global$」はコンソールのメッセージなので入力しない)
Global$ LS
結果
データ探索・分析
グラフの探索
グラフの探索機能を利用すると直感的にデータの関係性を深掘りしていくことができます。探索をおこなうためには、GraphStudioの左ペインメニューより「グラフの探索」メニューを押下します。
探索例:Socialグラフを利用してJackから繋がる交友関係(Friendship)を把握する
-
グラフ探索メニューから「頂点IDで頂点を検索」 欄でJackを検索します。条件を選択後虫眼鏡アイコンを押下してデータを検索します。
頂点タイプ Person 頂点ID Jack -
キャンバス上に表示されたJackをダブルクリックすることで交友関係を視覚的に把握することができます。7人分のデータが登録されているので各Personバーテックスをダブルクリックしながら交友関係を視覚的に把握してください。
以下のデータ探索結果が得られます。

-
探索結果が単一色で見づらく、またエッジにはエッジ名が表示されているのでこれを見やすく変更していきます。上部のツールバーから「歯車」アイコンを押下してプロパティを開きます。Personバーテックスを選択し、カラー設定を変更して今回は男性(male)、女性(female)ごとに色を変更したいと思います。
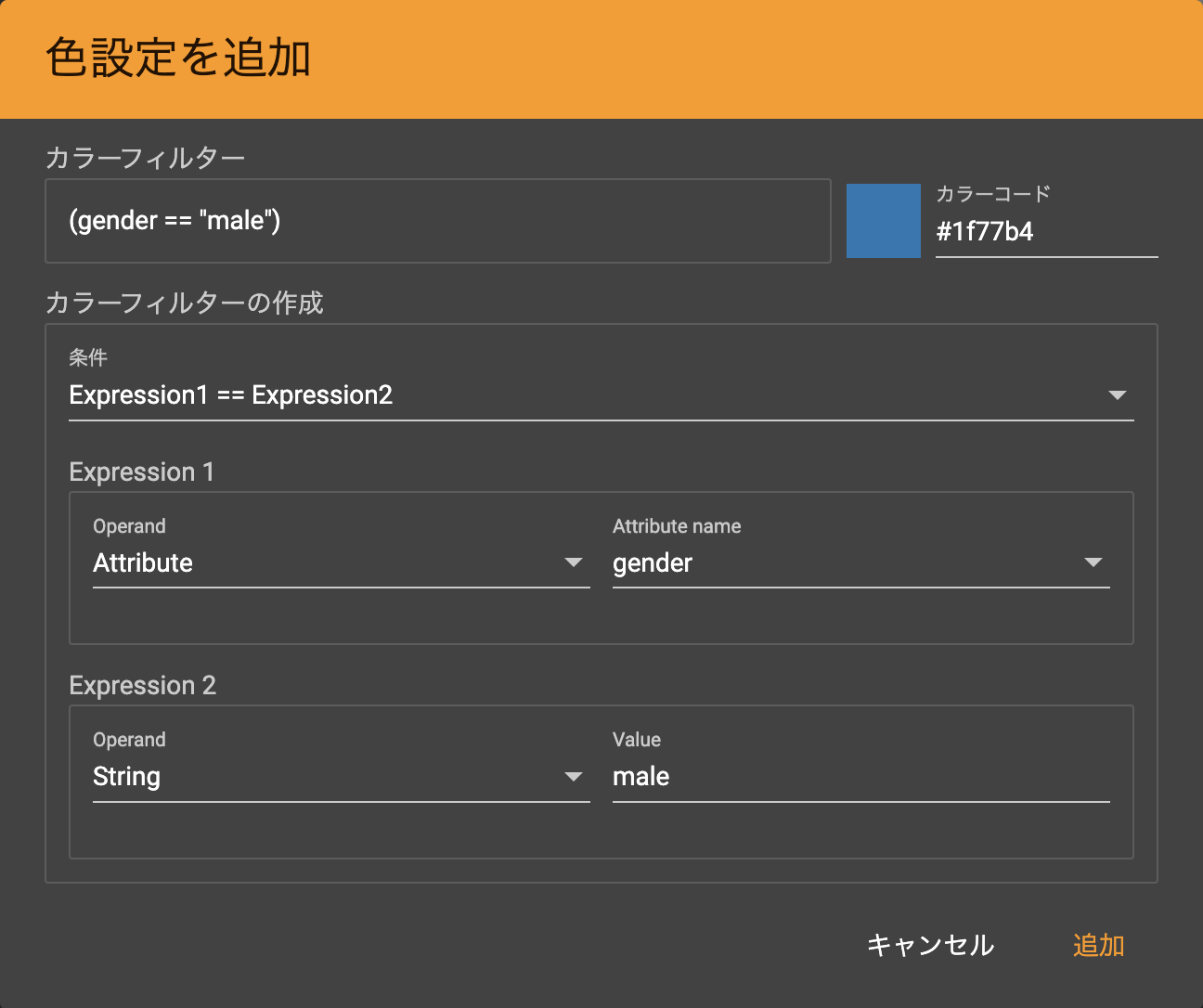
カラー設定の「+」アイコンを選択すると「None」という設定が追加されます。この右側にある「鉛筆(編集)」アイコンを押下して設定を編集します。それぞれカラーコードは任意でわかる色を設定してください。
男性用データ設定カラーフィルターの条件 Expression1 == Expression2 Expression1 - Operand Attribute Expression1 - Attribute name gender Expression2 - Operand String Expression2 - Value male 女性用データ設定
カラーフィルターの条件 Expression1 == Expression2 Expression1 - Operand Attribute Expression1 - Attribute name gender Expression2 - Operand String Expression2 - Value female 


次にFriendshipエッジを選択します。ビジュアル設定の属性の表示で「edge type」にチェックがはいっているのではずします。最後に適用ボタンを押下します。

-
先ほど探索した結果セットの色が設定した配色に変更され、またエッジからはエッジ名が表示されなくなりました。

グラフパターンを探索
グラフデータはそのデータ構造(パターン)を利用して探索することができます。これを数学用語では部分グラフ(サブグラフ)と呼称します。GraphStudioでは「グラフパターン作成」機能を利用してパターンを利用したデータ探索を実行します。もちろんそれぞれのデータに含まれる特定の条件で絞り込む(フィルター設定をかける)ことも可能です。
これを実行するには左ペインメニューから「グラフパターン作成」を押下し、パターンとなるグラフを定義します。
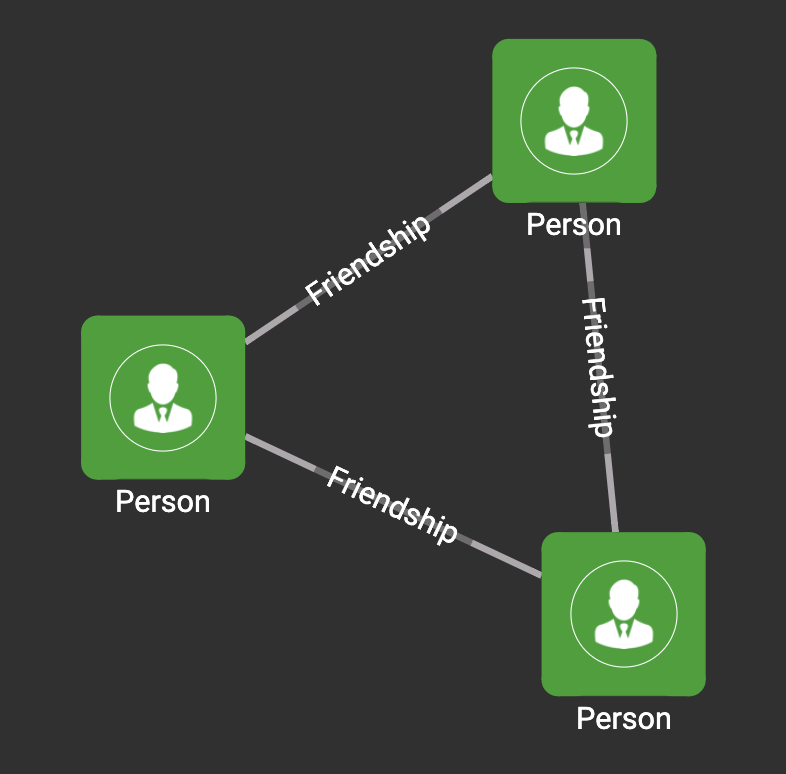
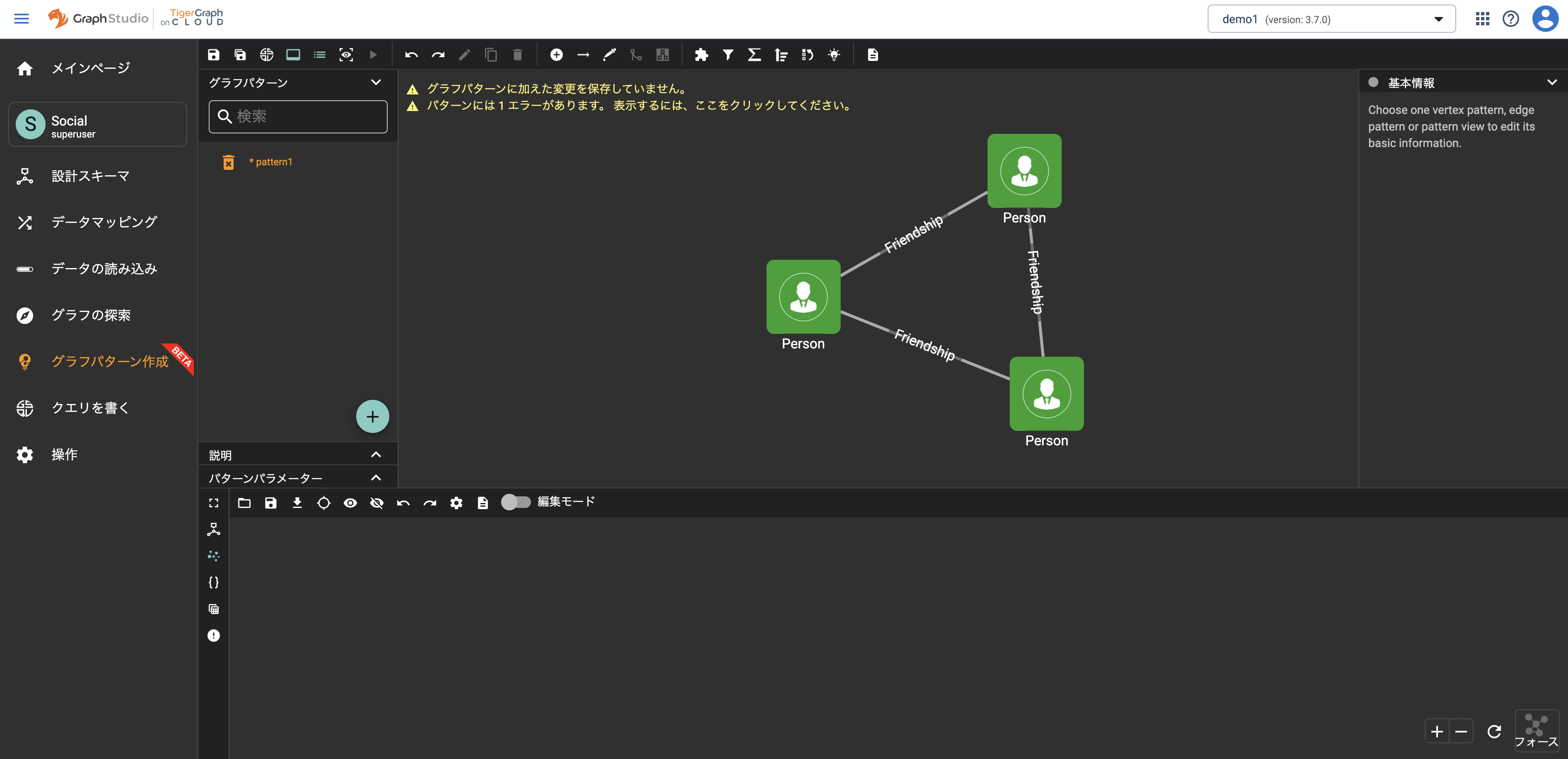
探索例:Socialグラフの中に含まれる3人のユーザデータでそれぞれが相互に友人であるデータを抽出する
パターンイメージ
-
グラフパターン作成キャンバスの左メニュー「グラフパターン」を開き「+」アイコンを押下して新規パターンを定義します。パターン名は任意(半角英数)で設定ください。
-
ツールバーから「+(頂点パターンの追加)」アイコンを3回押下し、3つのバーテックスをキャンバス上に表示させます。(設定の便宜上Person1、Person2、Person3と呼称します。)
-
ツールバーから「→(エッジパターンの追加)」アイコンを押下し、Person1からPerson2を順番にクリックしてエッジパターンを追加します。同様に、Person1からPerson3、Person2からPerson3にもそれぞれエッジパターンを追加します。
-
キャンバス上のPerson バーテックスパターンを一つ選択すると右ペインの基本情報が編集可能になるため、「名前(任意)」に「Person1」、「結果の挿入」をチェックありに設定します。設定後、基本情報メニューバーの右側にある「✓(適用) 」ボタンを押下します。同様に他2つのPerson バーテックスパターンもそれぞれPerson2、Person3の名前を設定し、結果の挿入にチェックをいれます。

-
キャンバス上のFriendship エッジパターンを一つ選択すると右ペインの基本情報が編集可能になるため、「結果の挿入」をチェックありに設定します。設定後、基本情報メニューバーの右側にある「✓(適用) 」ボタンを押下します。同様に他2つのFreindship エッジパターンもそれぞれ結果の挿入にチェックをいれます。
手順4、5まで完了すると各パターンがオレンジ色(ダークテーマの場合)でハイライトされます。

-
上部ツールバー一番左にある「フロッピー(保存)」アイコンを押下して、設定を保存します。同じくツールバーにある「開始(実行/再生)」アイコンを押下することで、パターンの探索を行います。今回のサンプルデータからは1パターンが発見されます。

クエリ言語を利用した探索
TigerGraphにはGSQLと呼ばれるクエリ言語(データベース操作用の言語)が提供されています。名前にあるようにリレーショナルデータベースでお馴染みのSQLに非常に近しい言語(SELECT * FROM XX)になっておりリレーショナルデータベースに慣れ親しんだエンジニアやアナリストも低コストで習熟することができます。
クエリを実行するためのGSQL Shell(またはクライアントツール)も提供していますが、データを探索するクエリについてはGraphStudioでも実行(および インストール)することが可能です。各クエリについてはインストールすることでREST APIのエンドポイントを作成するので外部からAPIとして呼び出すことができるようになります。GSQL自体の詳細についてはまた別の機会に説明していければと思いますが、このハンズオンではサンプルで用意されたクエリを実際に実行してみたいと思います。
GraphStudioでクエリを編集・実行するには左ペインメニューから「クエリを書く」メニューを選択します。
探索例:Socialグラフの中に含まれるAmilyからのつながりがあるユーザを可変的に取得する
グラフではノードを経由することをホップと呼称します。元々は通信ネットワーク上で通信相手に到達するまでに経由する転送・中継設備のことを示していました。今回の例ではAmilyから任意のホップ数(何人先の友人なのか)の友人を探索してみたいと思います。
-
エディタの左ペイン「GSQLクエリ」メニューから「+(新規作成)」ボタンを押下してクエリを作成します。
例では「findDeepLink」としています。 -
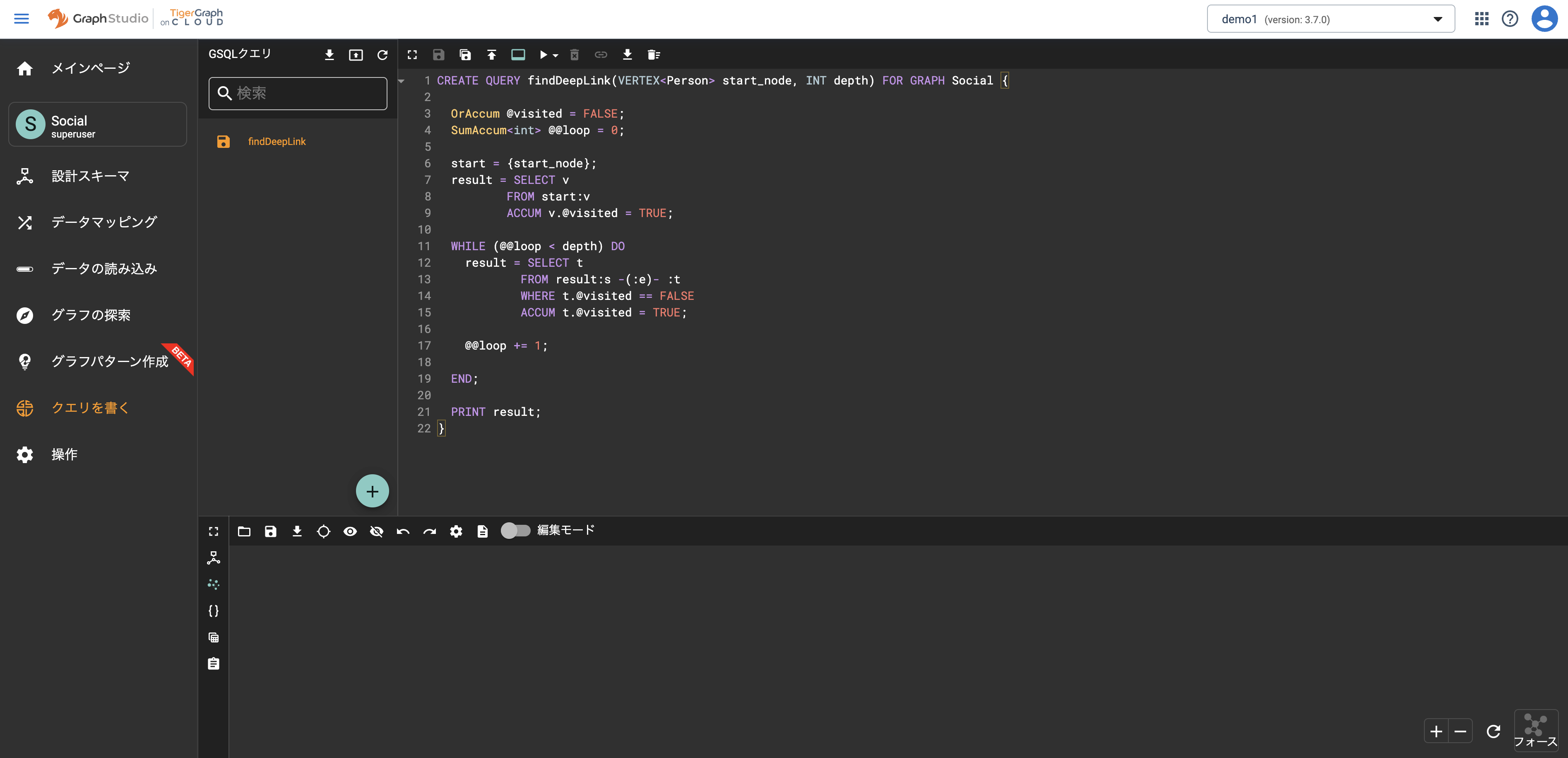
以下のクエリをコピーしたら、手順1で作成したクエリを選択しエディタ部分にペーストします。
もし例示と異なるクエリ名をつけている場合は、CREATE QUERY findDeepLinkのクエリ名部分を自身の作成したクエリ名とあわせてください。作成されたクエリ名と実際のエディタ内の定義が異なるとエラーが出力されます。CREATE QUERY findDeepLink(VERTEX<Person> start_node, INT depth) FOR GRAPH Social { OrAccum @visited = FALSE; SumAccum<int> @@loop = 0; start = {start_node}; result = SELECT v FROM start:v ACCUM v.@visited = TRUE; WHILE (@@loop < depth) DO result = SELECT t FROM result:s -(:e)- :t WHERE t.@visited == FALSE ACCUM t.@visited = TRUE; @@loop += 1; END; PRINT result; } -
上部ツールバーにある「フロッピー(保存)」アイコンを押下して、クエリを保存します。
-
ツールバー上の「↑(インストール)」アイコンを押下することで、クエリをインストールします。環境にもよりますがインストールには少々時間がかかります。これは上述にあるようにエンドポイントURL作成をおこなっていることに起因します。
-
同じくツールバーにある「開始(実行)」アイコンを押下することで、クエリを実行します。
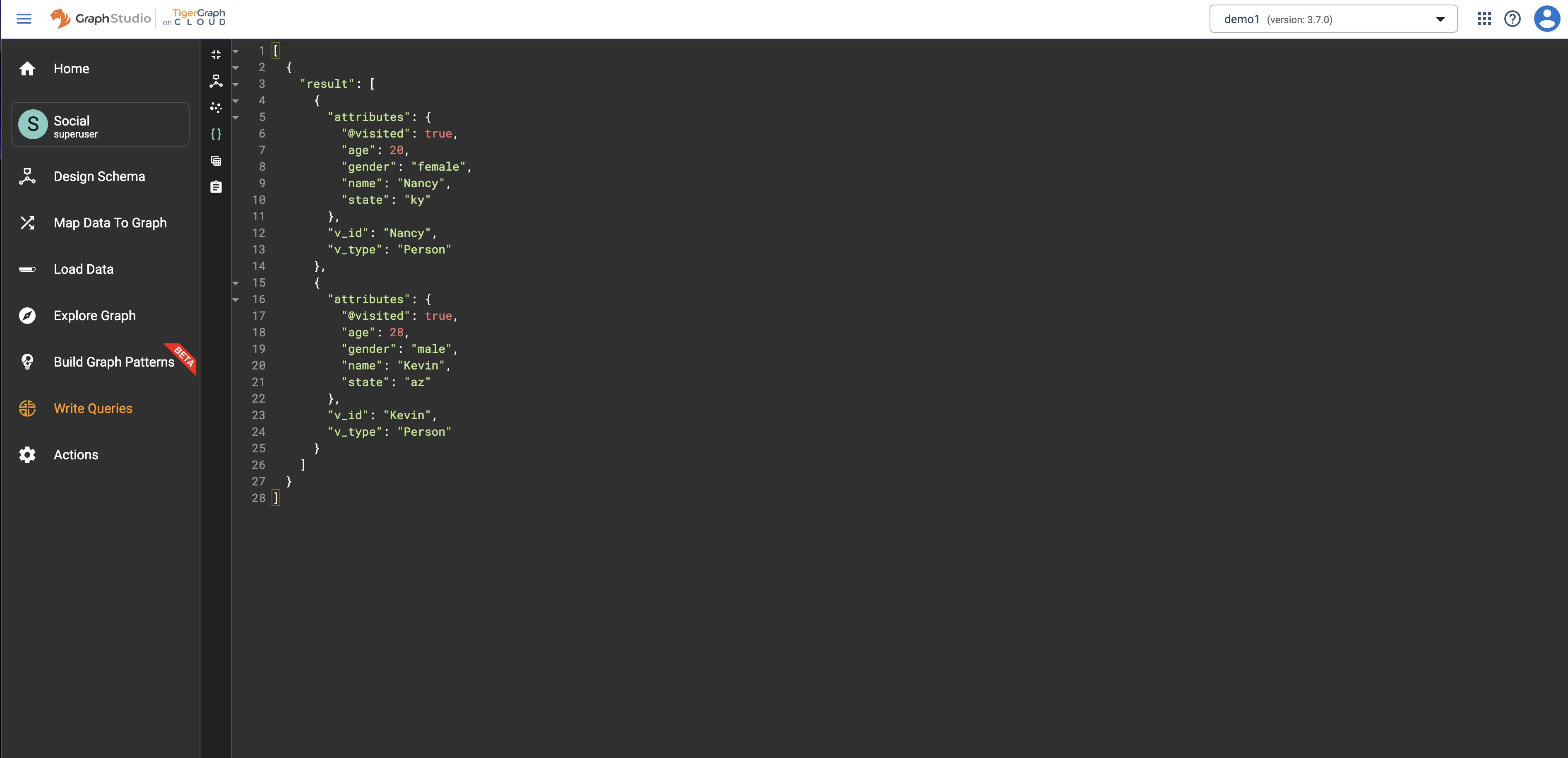
今回のデータ探索ではAmilyを起点として利用するため、「start_node: vertex」の頂点IDは「Amily」を指定し、「depth: int number」に任意の整数を設定します(サンプルデータは最大4ホップまでデータを返します)。
例では3ホップ目のユーザを取得しています。
取得された結果画面の「{}」アイコンを押下するとJSON形式で表示することもできます。
考察:リレーショナル データベースで同様のデータ探索をおこなう
ハンズオンでおこなったデータ探索をリレーショナルデータベース(SQL)でおこなうとどうなるでしょうか?
ストアドプロシージャではなくここではSQLで考えたいと思います。
グラフの探索/クエリ言語を利用した探索
今回のサンプルデータは最大で4ホップ(4人先)先までのデータが含まれていることがあらかじめわかっています。これであればSQLでも取得できます。ただし、GSQLで可変的に指定されたホップ数の友人を検索することはSQL単独ではデータを取得できそうにありません。
グラフパターンを検索
グラフパターンを検索する場合はどうでしょうか。部分グラフとしてのデータ探索はSQLでは実行できないため、予め出力されたレコードを元(副問合せ)としてさらにレコード問合せした後、交差(INTERSECT)させて必要なレコードを取得する必要があります。視覚的に検索することはツールによっては実現できそうですが、パフォーマンスを加味すると現実的ではない気がします。
上記からリレーショナルデータベースとグラフデータベースの機能配置は分析時の要件が定まっているかどうかではないかと考えられます。例えばBIツールを利用した固定ダッシュボードや帳票のように年月日、エリア(都道府県など)を指定するようなクエリについてはリレーショナルデータベースで問題なく実装できます。ただしアドホックな分析を行う場合にはグラフデータベースが向いていることがこのハンズオンを通じてご理解いただけると思います。
おわり
今回はGraphStudioを利用したハンズオンを紹介しました。次回はクエリ言語について説明していきたいと思います。