はじめに
ゼロから作るDeep LearningはO'reilly Japanから出版されている、文字通りディープラーニングをゼロから学ぶための書籍で、2024年12月時点で5冊出版されています。
- ゼロから作るDeep Learning❶ ― Pythonで学ぶディープラーニングの理論と実装
- ゼロから作るDeep Learning❷ ― 自然言語処理編
- ゼロから作るDeep Learning❸ ― フレームワーク編
- ゼロから作るDeep Learning❹ ― 強化学習編
- ゼロから作るDeep Learning❺ ― 生成モデル編
ゼロから作るDeep Learning❶が2016年9月発売で、最新作の❺が2024年4年なのですが、この間に世界ではMidjourneyやChatGPTが登場し、Deep Learningのない世界は考えられない時代になりましたが、その一方で機械学習を知らない人にとって、Deep Learningは今でもなんだか得体のしれない技術のように捉えられてると思います。
「ゼロから作るDeep Learning」では、文字通りpythonを使って1から構築することでDeep Learningがどういった原理で成り立っているか、それがどのように実装されているか理解できる書籍で、今世の中で話題になっている様々なモデルの基礎について学ぶことができます。
たとえば❶では写真から人や動物を判別するような画像分類モデルを学習できますし、❷ではChatGPTやBERTのような、いわゆるTransformer系と呼ばれるモデルの一部であるAttentionについてRNNを通して学習することができます。
また❸ではPytorchやTensorflowのような昨今のフレームワークがどのように実装されているかを学ぶことができ、❹ではAlphaGoで使われた深層強化学習を、そして❺ではMidJourneyに代表される拡散生成モデルを学ぶことができます。
PytorchやTensorflowといった最近のフレームワークでは、これらのモデルがすでに組み込み済みでさらに複雑なモデルを呼び出すことも容易ですが、自分の手で1から実装することで最新の技術や論文への理解を深めることができると思います。
読み進めるにあたって
読み進めるにあたり、ChatGPTでもGeminiでも何でもいいので商用LLMが使える状態にしておくのが良いと思います。
私がこの本を読み始めた頃はまだLLMは登場していませんでしたが、最新作の❺を読み進めるにあたっては、コードや数式を丸ごとChatGPTに説明してもらうことで何をやってるかすごくわかりやすくなったので、少しでも行き詰まったらすぐにLLMに確認するのをお勧めします。
はじめに
まず初めに、このシリーズを読み始める前の自分のDeep Learningに関する知識ですが、こちらのスライドの10ページ目くらいから怪しくなってくるくらいの理解度だと思ってください。
https://speakerdeck.com/kuruton/he-tonakuwakarudeipuraningu

※このあたりから怪しい
詳細な感想
ここからは各書籍の内容と感想を書き出していきます。あくまで個人の感想なので、誤解してる部分も多々あると思いますが、各自本を読んで実際のところを確認いただけると幸いです。
ゼロから作るDeep Learning❶ ― Pythonで学ぶディープラーニングの理論と実装
シリーズ第一作です。まずはDeep Learningのベースとなる
- ニューロン
- パーセプトロン
- 活性化関数
- ニューラルネットワーク
- 順伝搬と逆伝搬、偏微分
について学習します。
最初は聞きなれない単語や数式が出てくるため、コードの写経を行い、可能であればコードの元になってる数式も書き写し式の展開まで自分で試すと理解が深まると思います。
Deep Learningではあらかじめ決まった数式を実装するのではなく、入力値と正解のペアを大量に与え、それを元に重み(パラメタ)と呼ばれる変数を調整していくことでモデルを学習を進めます。
与えられた入力全てに対して正解を導くような変数を見つける際、何かをヒントにモデルがなるべく正解になるように重みを調整するのですが、そこで登場するのが微分関数です。
具体的には微分を使って重みを少しずつ調整するのですが、微分の計算をプログラムに落とし込む場合、以下のいずれかの方法で実装する必要があります。
- 数値微分
- 数式微分
- 自動微分(フォワードモード)
- 自動微分(リバースモード)
❶では主に数値微分、数式微分、リバースモードの自動微分について実装します。
自動微分についてはscikit-learn、Keras、TensorFlowによる実践機械学習の「付録D 自動微分」に数値微分、フォワードモード自動微分、リバースモード自動微分の計算方法が図解付きでまとまっており、こちらもセットで読み進めるとイメージが掴みやすいと思います。
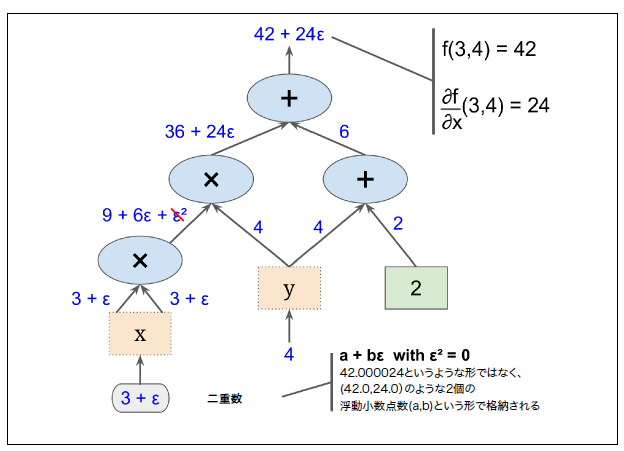
※リバースモード自動微分の解説の一部抜粋
その後基本的なニューラルネットワークを実装する方法を学び、畳み込みニューラルネットワーク(Convolutional Neural Network - CNN)の実装に進みます。
基本的なニューラルネットワークでは表現力が乏しく単純な画像の分類しかできませんが、CNNを用いることでより複雑な画像分類ができるようになります。
CNNでは重みをなるべくを増やさずに効率的にいろんな観点から学習させるため、様々な行列変換を行います。
pythonやnumpyの関数を多用するため、インプットとアウトプットそれぞれにprint文を追記し、CNN内で行列がどのように変換されるかを実際の値を見ながら進めると良いと思います。
CNNについてさらに理解を深めたい場合、TFLearnというリポジトリにGoogleNetのTensorflow実装があるので、こちらを写経するのもお勧めです。
ただしリポジトリ更新が止まっているため、最新のTensorflowではエラーになるかもしれません。
ゼロから作るDeep Learning❷ ― 自然言語処理編
❷ではDeep Learninの時系列データモデルであるRNNを使い、自然言語タスクを解く方法を学びます。
❶はどちらかというとプログラムを書く延長で進めることができたのですが、❷はコンピュータで自然言語を扱うための方法を学ぶ必要があり、馴染みのない領域だったため難しく感じました。
❷についてはちょっとでもわからないことがあったらLLMにしつこく質問するのが良いと思います。
❷では
- 自然言語処理での単語の扱い方
- Embeddingベクトル
- Word2Vecと単語の分散表現
- RNN
- LSTM・GRU
- Attention
を実装します。
機械学習では単語をコンピュータで扱うために、埋め込みベクトル(Embeddingベクトル)という密なベクトルに変換する必要があり、Word2Vecを実装する形で埋め込みベクトルを学んでいきます。
その後RNNの実装に入ります。まずはシンプルなRNNとして文章を時系列に見立てて次に登場する単語を予測するモデルを開発します。
次に英語から日本語、英語からフランス語のように時系列を別の時系列に変換するモデルの実装を行います。
更にRNNの発展形としてゲートという手法を使ったLSTM・GRUの実装を行い、ある地点の時系列と別の時系列との関連性(もしくは1つの文内での単語とそのほかの単語との関連性)を学習するAttentionの実装を行います。
ChatGPTなど最近のLLMの殆どはTransformerというモデルの発展形ですが、AttentionはTransformerの中でも利用されている重要な技術の1つです。
❷はTransfomerの実装自体は行わないため、❷を一通りやったあとこちらのQitaを実装することでTransformerの中身を理解できると思います。
作って理解する Transformer / Attention
Transformerについては大規模言語モデル入門の第2章に詳細にまとまっており、こちらは基礎だけでなく実装から訓練までプロダクションでも通用する実装が学べるのでおすすめです。
またRNNでは文書をトークンという単位に分割するのですが、非英語圏の文書は英語のように単語と単語の間に区切りが無いため、単語に分割する際に分かち書きという手法を使います。
分かち書きについてより深く知りたい人は実践・自然言語処理シリーズ第2巻 形態素解析の理論と実装が勉強になります。
ゼロから作るDeep Learning❸ ― フレームワーク編
❸はこれまでと若干趣向が変わり、dezeroというDeep Learningフレームワークの作り方を学びます。
dezeroはDeep Learningのフレームワークですが、pyhtonでフレームワークやライブラリを作る際の実装方法としても参考になります。
可能であれば❸を始める前にTensorflowかPytorchでチュートリアルを行い、OSSのフレームワークでモデルを一通り作ってから着手するのをお勧めします。
商用フレームワークでCNNモデルを組む場合、洗練された実装により直感的にモデルが組めると思いますが、❸を通して実装することで、これらのフレームワークが実際にはどのようにコードを実装しているのかを体験することができます。
またコンパイルが必要で複雑になりがちだったtensorflow 1系の時代にDefine-By-Runを取り入れたChainerの先進性も伝わると思います。
❸はゼロつくシリーズで最も分厚いですが、pythonコードがメインなので❷よりも進めやすいのではないかと思います。
ゼロから作るDeep Learning❹ ― 強化学習編
❹は強化学習編です。
1章でバンディット問題によって報酬を最大化するためのロジックを実装します。
バンディット問題は常に同じスロットマシンに対して試行を繰り返し報酬を最大化するロジックですが、2章からはより複雑な環境や終わりのないタスクで報酬を最大化するためのモデルを実装します。
2章から6章にかけては以下のように3x4の限られたマスの中で機械学習により報酬を最大化する手法を実装します。
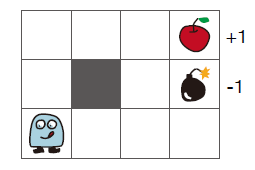
強化学習では、タスクが完了してから学習を行うモンテカルロ法と、現在と次のステップから現在の予測を更新するTD法などがあり、それらを学習することができます。
さらに強化学習のモデルをDeep Learningのモデルとして学習し、DQNとして実装します。
またDQNの他にDeep Learningを使った手法として方策勾配法やREINFORCE、Actor-Critic法という手法の実装を進めます。
❹ではOpenAIのGymというライブラリを使います。Gymは強化学習用に様々なタスクが用意されており、8章以降はCart Poleを環境に強化学習を実装します。
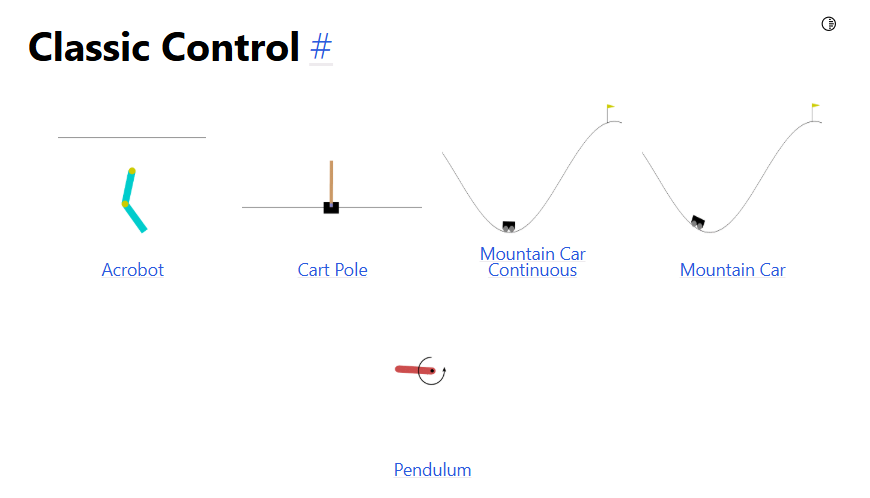
https://www.gymlibrary.dev/environments/classic_control/index.html
以下はCart Poleの実行結果ですが、未学習状態だとこのようにすぐゲームオーバーになってしまいます。

Cart Poleに対して❹のActor-Criticを実装し、学習するとこのようにモデルが自分で学習し、長時間ゲームを続けることができるようになります。
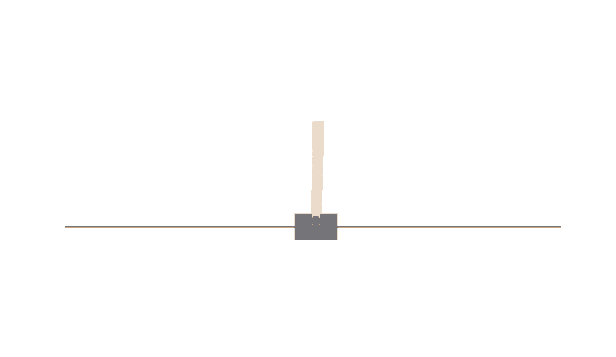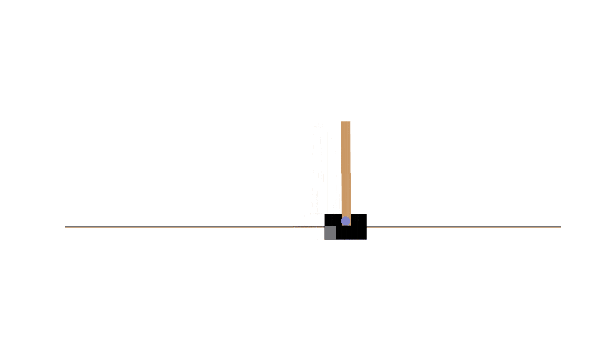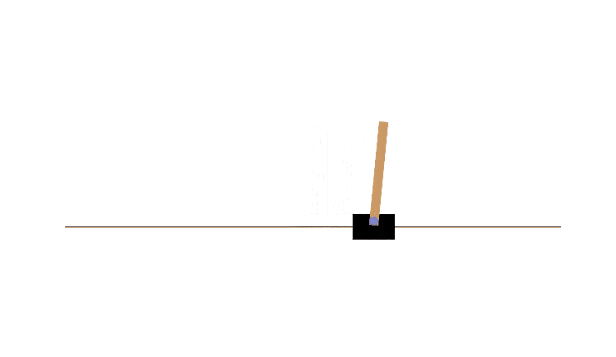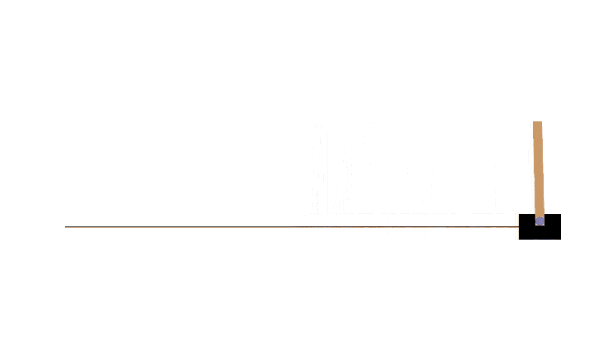
ちなみにOpenAIのGymはすでにメンテ終しているようで、これから❹を実装する場合、以下のようにgymnasiumをインストールして進めてください。
pip install gym
pip install gymnasium
pip install "gymnasium[classic-control]
またgymおよびgymnasiumをjupyter notebookで直接動かすことはできないので、実行結果をフレームとして保存してgifとして描画する必要があります。
これから❹をやる人はこちらを参考に実装してみてください。
import gymnasium as gym
from matplotlib import animation
from matplotlib import pyplot as plt
from IPython.display import HTML
import numpy as np
env = gym.make('CartPole-v1', render_mode='rgb_array')
state = env.reset()[0]
frames = []
done = False
while not done:
frame = env.render()
frames.append(frame)
action = np.random.choice([0,1])
next_state, reward, done, truncated, info = env.step(action)
env.close()
fig = plt.figure()
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(fig, animate, frames=len(frames), interval=50)
HTML(anim.to_jshtml())
ゼロから作るDeep Learning❺ ― 生成モデル編
❺が2024年12月時点での最新作で、Midjourneyに代表される拡散生成モデルを実装します。
生成モデルでは変分オートエンコーダ(VAE)というモデルの理解が重要になります。VAEを理解するためステップ1~6にかけて以下を学習します。
- 正規分布
- 最尤推定
- 混合ガウスモデル
- EMアルゴリズム
上記を学んだあと実際にVAEの実装を進めていきますが、その前にTensorflowかPytorchでオートエンコーダモデルの実装をしておくとよいと思います。
オートエンコーダはニューラルネットワークに入力値を与え、出力結果と入力値が等しくなるように学習させる教師なし学習の一つで、その重みは入力値を効率よく圧縮したものになるため、主に次元削減や特徴抽出などに利用されます。
VAEは重みをガウス分布からサンプリングされる確率分布として実装することで新たなデータを生成することを目指すのですが、オートエンコーダをやっておくとVAEのイメージが付きやすくなります。
❺に沿ってMINSTを学習すると以下のようにノイズから手書き文字のような画像を生成できるようになります。

その後VAEをベースとした拡散モデルの実装に入ります。
拡散モデルは入力に何度もガウスノイズを追加していく拡散過程と、ノイズを除去する逆拡散過程があり、拡散生成モデルでは何度もノイズをかけた結果から元データを復元するモデルと、ノイズ化された入力に対してどのようなノイズがかけらたのかを予測するモデルがあり、❺では後者の実装を行います。
以下が拡散モデルの学習結果ですが、学習が進むごとにノイズではなく文字が生成されるようになることが確認できていると思います。
エポック0

エポック10

エポック30

この後入力にテキストの埋め込みを追加した条件付き拡散モデルの実装を行います。条件付き拡散モデルによって、入力テキストから画像を生成するという生成モデルが完成します。
まとめ
このシリーズを通してDeep Learningの基礎から画像分類、自然言語処理、フレームワーク実装、強化学習、拡散生成モデルまで幅広く知ることができました。
最近ではTensorflowやPytorchおよび周辺ライブラリを使うことで複雑で高度なモデルを簡単に使うことができますし、生成AIはサイトにアクセスしたりAPIをコールするだけで最新の高性能モデルを利用することができるようになりました。
このようにAIがコモディティ化していった結果、それらの技術について1から学ぶということが大変難しくなってきたように感じます。
今世の中を席巻しているようなAI技術の基礎についてこれだけ丁寧に紐解いている書籍は他にはなく、しかも日本語で学べるのはこのシリーズのみといっても過言では無いと思います。
Deep Learningを基礎から覚えたい、画像生成やLLMといった技術を使うだけではなくその理論も知りたい、という人は是非こちらのシリーズを試してみてください。