S3のSigV2、Xデーはどんどん近付いてきます
https://dev.classmethod.jp/cloud/aws/s3-sigv2-abolition/
私が携わっているレガシーの塊な歴史あるプロダクトもバッチリ対象になってました
プログラムの修正をしても本当に殲滅できてるかチェックする必要があるわけです
(aws-sdkのバージョンアップなので普通に考えてSigV2が使われることは有り得ないはずですが、まあ…)
パパっとググってみればSigV2の使用を検出する記事はたくさんありそうで余裕かと思われました
https://dev.classmethod.jp/cloud/aws/check-s3-sig2-usage-cloudwatch/
特にこのAWSチームのすずきさんはこの件について参考になる記事をたくさん書いてらっしゃるのですが、
AWSのいろんな機能を繋ぎまくってて私のようなにわかAWSマンには難しかった
にわか(私)が日頃使ってる機能で簡単になんとかならんものか
と考えた時に、やはりS3のアクセスログのファイルをそのままAthenaで扱いたくなるんですが、
ここでネックになるのが、出されるファイルそのままではどうもパーティションが使えないっぽい。(=金が溶ける可能性が上がる)
それをみんな大好きlambdaでフォローしてみよう、という考え方です。
なので今回使うのは、
- lambda
- athena
この2つです。メジャーなやつですね。
対象
- CloudTrailとかよくわからん!
- athenaとlambdaならぼちぼちわかる!
- SigV2が廃止になって問題ないか不安!
- S3ログの取り回しに日頃から不満がある!
概要
- S3のアクセスログファイルをathenaで扱いやすい形にrenameしてからあとは普通にathenaでいじる
すごいお手軽そうですね、でも意外とここから長いです。
作業
S3のログを有効化する
まずはログを取らないとどうしようもない
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/ServerLogs.html
取ったログファイルをrenameする
作成されるS3ログファイルのフォーマットは上のドキュメントにもある通り
TargetPrefixYYYY-mm-DD-HH-MM-SS-UniqueString
という形式です。これがクセモノです。大量のファイルがフォルダ分けされることなく置かれていきます。
そもそもS3にフォルダという概念はなく、オブジェクトの名前を/で区切った部分をなんとなくフォルダっぽくよろしくやってるらしいです。
理屈はわからんでもないですが、実際コンソールではフォルダっぽく使いまくるので非常にやりにくいです。
athenaでもlocationとかパーティションでなにかとフォルダっぽく使う必要があります。
つまり、__S3のログファイルはそのままだとすごい使いにくい__です、これは前からずっと思ってた。
なのでこのYYYY-mm-DD-HH-MM-SS-UniqueStringを使いやすい形式にrenameしてしまいます。
で、lambdaの出番です
実装はお好みでどうにでもなりますが私はGoブームが来てるのでこんな感じで
package main
import (
"context"
"fmt"
"regexp"
"strings"
"github.com/aws/aws-lambda-go/events"
"github.com/aws/aws-lambda-go/lambda"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/s3"
)
func initSession() *s3.S3 {
s := session.Must(session.NewSessionWithOptions(session.Options{
SharedConfigState: session.SharedConfigEnable,
}))
return s3.New(s)
}
func moveS3Object(s3ses *s3.S3, bucket string, key string) error {
splitKey := strings.Split(key, "/")
keylen := len(splitKey)
rgx := regexp.MustCompile(`([0-9]{4}-[0-9]{2}-[0-9]{2})-(.+$)`)
objName := rgx.ReplaceAllString(splitKey[keylen-1], "dt=$1/$2")
splitKey[keylen-1] = objName
copyKey := strings.Join(splitKey, "/")
copyInput := &s3.CopyObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(copyKey),
CopySource: aws.String(bucket + "/" + key),
}
deleteInput := &s3.DeleteObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
}
if _, err := s3ses.CopyObject(copyInput); err != nil {
return err
}
if _, err := s3ses.DeleteObject(deleteInput); err != nil {
return err
}
return nil
}
func handler(ctx context.Context, event events.S3Event) {
s3ses := initSession()
for _, record := range event.Records {
if e := moveS3Object(s3ses, record.S3.Bucket.Name, record.S3.Object.Key); e != nil {
fmt.Printf("Move Object Error: %v", e)
}
}
}
func main() {
lambda.Start(handler)
}
YYYY-mm-DD-HH-MM-SS-UniqueStringをdt=YYYY-mm-DD/HH-MM-SS-UniqueStringにします。
(renameというか雑にcopyして雑にdeleteなんですが、aclとか大丈夫かいな)
オブジェクトの作成をトリガーに設定します。
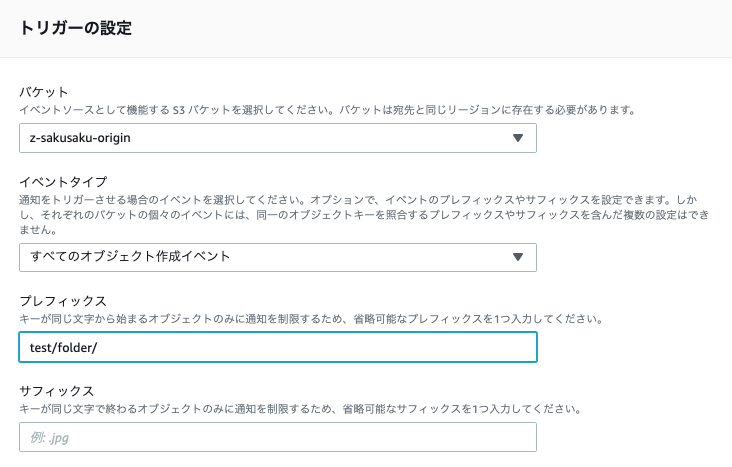
bucket名はご愛嬌ということで(もう消した)
athenaで解析
上の変換によりパーティションが使いやすくなっています。(というか元がアレすぎる)
dt=YYYY-mm-DD と一見よくわからない変換をしたのもパーティションのため。
この辺のことは公式で https://docs.aws.amazon.com/ja_jp/athena/latest/ug/partitions.html
次のちょっとした問題はログのフォーマットです
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/LogFormat.html
正規表現パターンはこれまたAWSチームのすずきさんのこちらを参考にしました。
https://dev.classmethod.jp/cloud/aws/s3-accesslog-new-fields/
このままだと一致しないものがあるので少し手を加えてこんな感じ
^(\S+) (\S+) (\S+ \S+) (\S+) (\S+) (\S+) (\S+) (\S+) (\"[^\"]*\"|-) (\S+) (\S+) (\S+) (\S+) (\S+) (\S+) (\"[^\"]*\"|-) (\"[^\"]*\"|-) (\S+) (\S+ ?\S+) (\S+) (\S+) (\S+) (\S+) (\S+)$ | ^(.+)$
- クォーテーションで囲ってある部分が空の時にクォーテーションなしの
-になってるパターン - どうもHostIdにスペースが入ってるパターンがあるっぽい?(もしくは未知のフィールドがある?)(区切り文字スペースなんだから勘弁してくれー)
- これでまだ一致しないものは最後にとりあえず拾ってあとあと対処(事前の完全フォローは無理)
- またいつ変わるかわからない
で、テーブルを作ります
CREATE EXTERNAL TABLE IF NOT EXISTS default.test (
`bucket_owner` string,
`bucket` string,
`time` string,
`remote_ip` string,
`requester` string,
`request_id` string,
`operation` string,
`key` string,
`request_uri` string,
`http_status` string,
`error_code` string,
`bytes_sent` string,
`object_size` string,
`total_time` string,
`turn_around_time` string,
`referrer` string,
`user_agent` string,
`version_id` string,
`host_id` string,
`signature_version` string,
`cipher_suite` string,
`authentication_type` string,
`host_header` string,
`tls_version` string,
`unmatch` string
)
PARTITIONED BY (dt date)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' = '^(\\S+) (\\S+) (\\S+ \\S+) (\\S+) (\\S+) (\\S+) (\\S+) (\\S+) (\"[^\"]*\"|-) (\\S+) (\\S+) (\\S+) (\\S+) (\\S+) (\\S+) (\"[^\"]*\"|-) (\"[^\"]*\"|-) (\\S+) (\\S+ ?\\S+) (\\S+) (\\S+) (\\S+) (\\S+) (\\S+)$|^(.+)$'
) LOCATION 's3://z-sakusaku-origin/test/folder/'
TBLPROPERTIES ('has_encrypted_data'='false');
正規表現に一致しない行は最後のunmatchにまるっと入るので見つけ次第フォローします。
パーティションをロードします。
MSCK REPAIR TABLE default.test;
(初めてHive形式でやってみたけどこれってファイル増えたらまたやらないといけないのか…これ金かからないよな?)
今回はパーティションをdate形式にしたので範囲でwhereが使えます、これはちょっと便利かも。
SELECT * FROM default.test where dt > date '2019-04-01' and signature_version = 'SigV2';
(結果はモザイクだらけになるので貼りません)
締め
今回は私の環境で最適と思った方法を紹介してみました。
もっと細かくパーティショニングしたいならHHも使えばいいし、S3の視認性を重視したいならYYYY/mm/DD/のような感じでrenameしてALTER TABLE ~ ADD PARTITION ~ すればいいと思います。
なんにせよ、AWSガチ勢から見ればヤキモキするやり方かもしれませんが、にわかにはこの程度がちょうどよい。