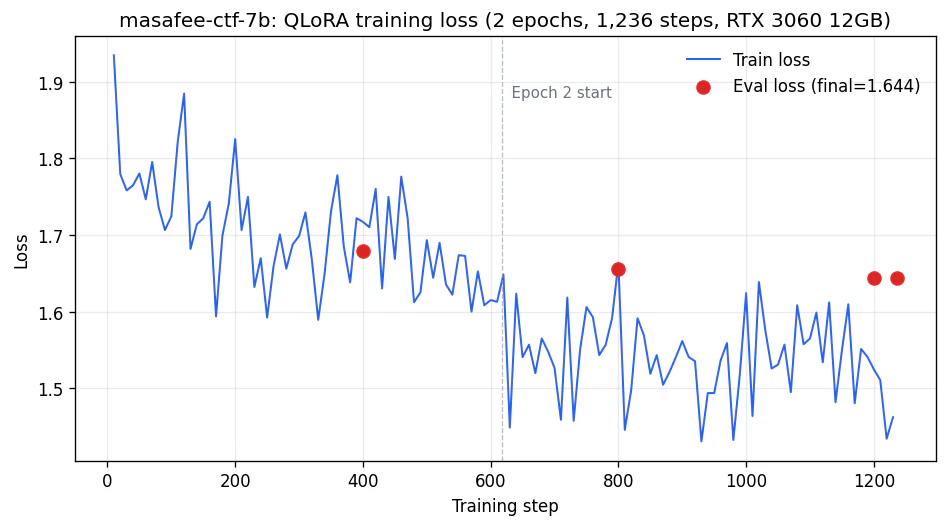
「自宅の RTX 3060 12GB で 7B モデルをフルにファインチューニングして、Cisco のセキュリティ特化 LLM と評価ベンチで並べてみたら何が起きるんだろう?」というところから始めた個人研究の記録。結論から言うと、知識MCQでは引き分けたけど、CTF実問題は 0/30 で完敗しました。



TL;DR
| 項目 | 値 |
|---|---|
| ベース | Qwen 2.5 Coder 7B Instruct |
| 手法 | QLoRA (r=32, α=64) via unsloth |
| データ |
justinwangx/CTFtime (18,013 writeup → 5,200 × 2048-tok packed) |
| GPU | 自宅の RTX 3060 12GB(クラウド0円) |
| 学習時間 | 12 時間 17 分 |
| 電気代 | 約 150 円 |
評価結果(3モデル比較):
| Benchmark | Base Qwen Coder 7B | masafee-ctf-7b | Foundation-Sec-8B (Cisco) |
|---|---|---|---|
| CyberMetric-500 (知識MCQ) | 86.20% | 84.00% | 82.60% |
| NYU CTF Bench (30問 single-shot) | 4/30 | 0/30 | 2/30 |
| Hedging語出現数 (30出力中) | — | 7 | 77 |
つまり:
- 知識MCQは 全モデル誤差範囲内 (95% CI ±3.1pp)
- CTF実問題は writeup 過適合で トークン使い切って FLAG に辿り着けず 0/30
- Hedging語は Cisco比 11倍少ない(writeup の断定的口調 vs SOC 文体)
きっかけ
これは「masafee シリーズ」第二弾。第一弾はStable Diffusion LoRA で自分のキャラを描かせるもので、画像生成だった。今回はテキスト生成版がやりたかった。
ちょうど話題になってた Cisco のFoundation-Sec-8B-Instruct(SOC運用想定のセキュリティ特化 LLM)を見て、「自宅の 1 枚の GPU で同じ土俵に立てるのか?」というのが純粋に気になった。
結論を先に書くと、作れる、けど方向性が全然違うものになる、という感じだった。
何を作ったか
- ベースモデル:
Qwen/Qwen2.5-Coder-7B-Instruct - 学習データ:
justinwangx/CTFtime— CTFtime.org からスクレイピングされた writeup 18,013 件 - 手法: unsloth で QLoRA (rank=32, α=64, 4-bit NF4 base)
- 出力: LoRA adapter (
safetensors) + Q4_K_M GGUF (4.4 GB) - 配布: GitHub + Hugging Face + Zenodo DOI + 論文 (EN/JP)
セキュリティ用途として大事な scope の話:学習用 CTF の範囲で writeup の文体・専門用語を学ばせること が目的で、Claude Mythos みたいな実世界脆弱性発見能力は最初から狙ってない(個人の倫理と能力の限界の両方の理由で)。
環境・コスト
| 項目 | 詳細 |
|---|---|
| GPU | NVIDIA GeForce RTX 3060 12GB(自宅) |
| OS | Ubuntu 24.04 LTS |
| Python | 3.11 (uv で venv) |
| PyTorch | 2.11.0+cu128(後述:cu124 だと unsloth と非互換) |
| unsloth | 2026.5.8 |
| 学習時間 | 12 h 17 min |
| TDP概算 | 170W × 12.3h ≈ 2.1 kWh |
| 電気代 | 31円/kWh × 2.1 = 約 150 円 |
クラウドGPU使わないと決めると、「ベンチで Cisco と比較しました」が ≒ 150円研究 になる。これが個人開発の純粋な楽しさ。
ハマりどころ
1. seq_len 4096 は RTX 3060 12GB に乗らない
最初 seq_len=4096 で smoke test したら torch.OutOfMemoryError: tried to allocate 34 MiB。 残り 34MiB が出ない時点で詰み。
→ seq_len=2048 に縮小 + optim="paged_adamw_8bit" で解決。dataset 側も packing をやり直し、5,200 × 2048 tok シーケンスにした。
2. PyTorch のバージョンが unsloth に合わない
unsloth 2026.5.8 を入れたら torch.int1 attribute missing。 torch 2.5.1 が古すぎた。
cu124 wheel で torch 2.6.0 を入れたら今度は register_constant missing。
最終的に:
uv pip install torch torchvision --index-url https://download.pytorch.org/whl/cu128
で torch 2.11.0+cu128 を入れて unsloth がやっと import 通った。unsloth は torch の最新 cu128 を要求しがち、というのが学び。
3. Foundation-Sec-8B が ollama デフォルト Modelfile では空応答
比較対象として Cisco の Foundation-Sec-8B を ollama で動かそうとしたら、TEMPLATE {{ .Prompt }} の単純な Modelfile では完全に空文字列が返ってきた。
Foundation-Sec は Llama 3 ベースなので Llama 3 のチャットテンプレート を自分で書く必要がある:
FROM foundation-sec-8b-instruct.Q8_0.gguf
TEMPLATE """<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|end_of_text|>"
これに直したら普通に応答するようになった。
4. Hugging Face Hub への 4.4GB GGUF アップロードが Python API で 33kB/s に低下
huggingface_hub.upload_file() で Q4_K_M GGUF (4.4GB) をアップしようとしたら、82% で 33kB/s まで低下して事実上停止。家のネットは Gigabit、nvidia-smi も iftop も問題なし。原因は HF 側の LFS レート制限っぽい。
→ Python API をやめて hf CLI(modern huggingface_hub 1.16 の統合 CLI)に切り替え:
hf upload masafy/masafee-ctf-7b ./masafee-ctf-7b.q4_k_m.gguf
すると Xet プロトコルが resume を検知して 201MB の差分だけ転送して 12MB/s で完走した。これは知らないと数時間溶かす罠。
5. LoRA merge が VRAM に乗らない
PeftModel.from_pretrained() で 7B FP16 を GPU に乗せようとすると 12GB に収まらず、自動オフロードが PeftModel と相性悪くて meta tensor エラーになる。
→ 素の transformers + device_map="cpu" で CPU マージ。30 秒くらいで終わる。
結果と考察
CyberMetric-500(一般 cybersecurity 知識 MCQ, 500問)
| Model | Accuracy |
|---|---|
qwen2.5-coder:7b (Base) |
86.20% |
masafee-ctf-7b |
84.00% |
foundation-sec-8b |
82.60% |
3モデルとも 95% 信頼区間 ±3.1pp の中に収まるので、実質的に同等。
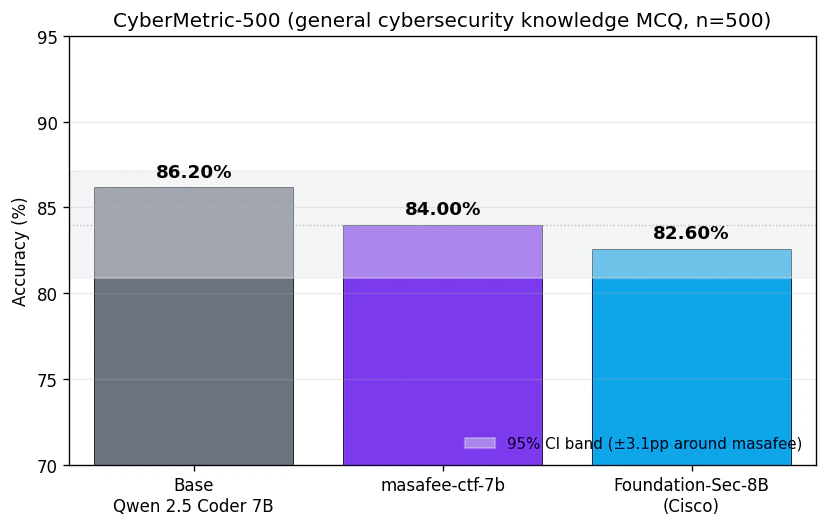
CTF writeup での continued pretraining は、MCQ 形式の知識テストに対して有意な改善も劣化も起こさなかった。素直に解釈すると「base の知識を壊さなかった」とも言えるし、「特化学習が知識向上には繋がらなかった」とも言える。
NYU CTF Bench(実 CTF 問題、30 問サブセット、single-shot)
| Model | Solved |
|---|---|
qwen2.5-coder:7b |
4 / 30 (13.3%) |
foundation-sec-8b |
2 / 30 (6.7%) |
masafee-ctf-7b |
0 / 30 (0.0%) |
ここが完敗で、しかも面白い負け方だった。
masafee-ctf-7b は CTF 問題を見ると writeup を書き始める。「## Challenge」「## Solution」「### Step 1」みたいな見出しを生成し、状況解説を延々と続け、FLAG にたどり着く前にトークン上限に達して終了する。
これは典型的な style overfitting:writeup の表面的なフォーマットを学習しすぎて、「直接答える」という挙動が抑制された状態。
ある問題(2017q-pwn-pilot)では、与えられた challenge と完全に無関係な架空の writeup を生成し始めた。writeup-format の prior が prompt の内容を上書きしている、わかりやすい hallucination。
Hedging 行動の違い
| Measure | masafee-ctf-7b |
foundation-sec-8b |
|---|---|---|
| Hedging語出現数(30出力中) | 7 | 77 |
| CTF tool/technique 用語の種類 | 22 | 21 |
Hedging語 = "I cannot be certain", "It is possible that", "may", "might", "could potentially" など。
masafee は writeup(断定的に解法を書く文体)で学習しているので hedging が極端に少ない。一方 Foundation-Sec は SOC アナリスト向け設計で、確証のないことを断定しない訓練が強くかかっている。
これは「どちらが優れている」ではなく 設計目的の違いの定量化。CTF 解法には direct な assertion が要るし、SOC 業務には慎重な hedging が要る。両方の方向に学習データが効いている、というのが綺麗に観測できた。
学んだこと
1. Continued pretraining は style transfer であって capability transfer ではない
これが今回の一番大きな学び。CTF writeup の生テキストで継続事前学習すると、口調・フォーマット・専門用語の使い方は確かに変わる。でも 問題を解く能力そのものは付与されない。
文体の獲得と能力の獲得は別物。当然ちゃ当然なんだけど、実験して数字を見るまでは「writeup を大量に読ませたら CTF が解けるようになる気がする」という素朴な期待があった。
2. 7B + 18k SFT では Base の推論能力を超えられない
ベンチ結果が示している通り、base Qwen Coder 7B が CTF MCQ も NYU CTF も一番強い。継続事前学習で天井を上げるのは、このスケールでは無理だった。
データ量を増やす(10倍?100倍?)か、SFT/DPO で「答える」挙動を直接教える、あるいは agent loop で multi-turn にする、のどれかが必要。次の研究方向はこのへんになる。
3. 過剰な style 学習は、direct answer 生成を能動的に妨げる
これも面白かった。「うちのモデルは何もしなくなる」じゃなくて、「うちのモデルは間違った形式で熱心に何かする」になる。トークン予算を writeup 解説に使い切って FLAG を出力しないので、評価上は完全な 0 点になる。
形式の prior は強い。Instruction tuning なしの continued pretraining だけで配るときは要注意。
個人研究を「ちゃんと出す」やり方(手順メモ)
ここから先は研究内容と独立した、個人開発者向けのノウハウ。GitHub + Hugging Face + Zenodo DOI + 論文の 4チャネル同時公開 をやってみての記録。
Hugging Face
- アカウントは無料、書き込みトークンは細粒度(リポジトリ単位)で発行
- LoRA adapter は数百MB なので Python API で十分
- GGUF など 1GB 超は
hfCLI に Xet 経由でアップ(resume が効く)
Zenodo
- ORCID を先に取る(個人研究者として「組織なし」でも登録可、無料)
- GitHub と連携 ON にしてから release を作ると自動で DOI 付与
- Concept DOI(常に最新版を指す)と Version DOI(その版固定)の 2 種類があるので、README には concept を、CITATION.cff には両方書くと便利
- 初期 release を作る前に「リポジトリ ON」を忘れると後追いで archive されないので注意(私はこれを踏んで v1.0.0 を作り直した)
論文
LaTeX 2 カラムで EN と JP を両方書いた。
- EN:
article+twocolumn、pdflatex - JP:
ltjsarticle+ lualatex(フォントが綺麗、CJK 周りの罠が少ない)
LaTeX の CJK では 〈〉 を $\langle\rangle$ で書くと 「hプロンプト, 回答i」みたいな化け方をする。素直に CJK 角括弧 〈〉 を直書きするのが正解だった。
CITATION.cff
GitHub 右上の「Cite this repository」がこのファイルから生成される。
cff-version: 1.2.0
title: "Masafee CTF 7B: ..."
authors:
- family-names: Suzuki
given-names: Masato
orcid: "https://orcid.org/0009-0000-7977-2756"
doi: "10.5281/zenodo.20413080" # concept DOI
リンク集
- 🐙 GitHub: masafykun/masafee-ctf-7b
- 🤗 Hugging Face: masafy/masafee-ctf-7b
- 📄 論文 (English, 5p): paper_en.pdf
- 📄 論文 (日本語, 6p): paper_ja.pdf
- 🔗 Concept DOI: 10.5281/zenodo.20413080
- 評価レポート: EVALUATION_ja.md
おまけ:個人研究シリーズ
| 第 | プロジェクト | 領域 | GPU 使用時間 |
|---|---|---|---|
| 1 | masafee-lora | 画像生成 (SD LoRA) | ~6h |
| 2 | masafee-ctf-7b (これ) | テキスト生成 (QLoRA on LLM) | 12h17m |
第三弾は何にするか考え中。読んでくれてありがとうございました 🐾