
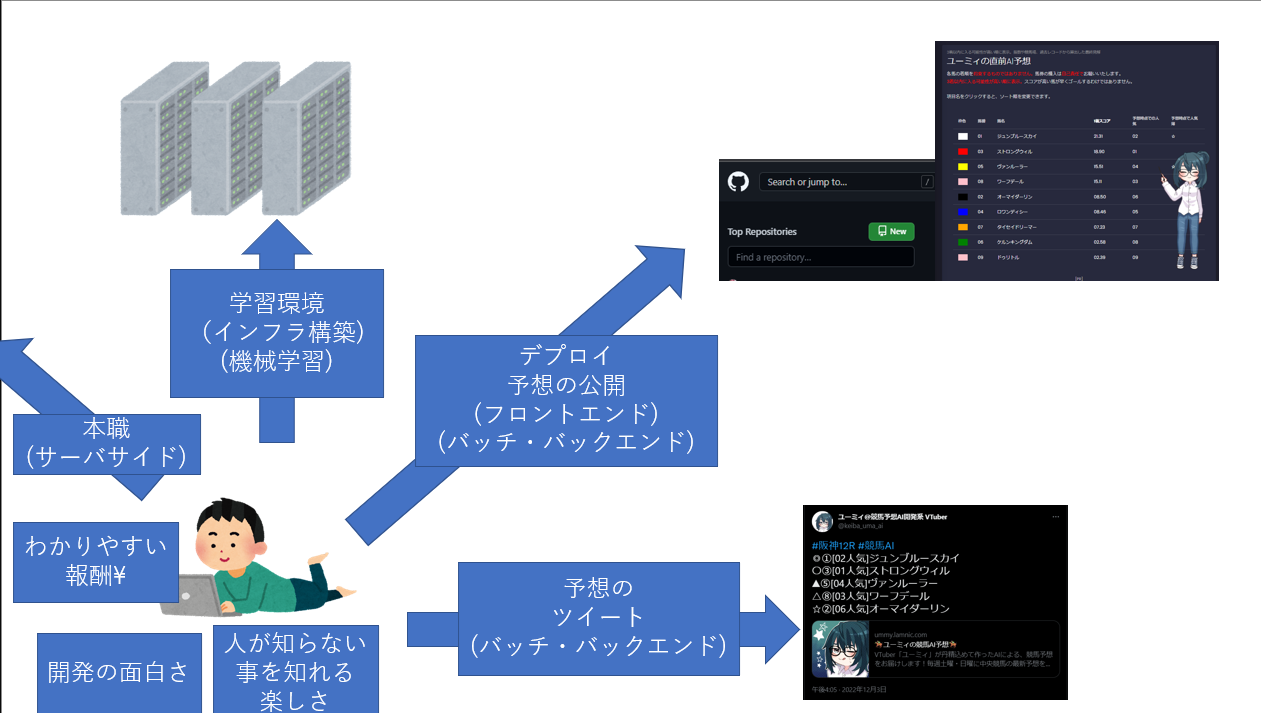
自己紹介
こんにちは、まさちゃこといいます。
普段は、競馬AI開発系 VTuberユーミィちゃんの、技術支援をしています。
ユーミィちゃんは、主に競馬AIの予想をつぶやいたり、各レースに関する動画を投稿したりしています。
予想は中央競馬の予想がほとんどで、たまに地方競馬の予想も呟きます。
予想は↓のような形で、レースの10分ほど前にツイートされます。
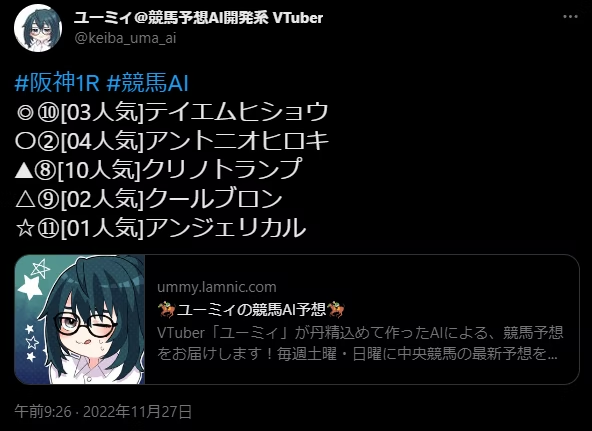
URLをクリックするとこんな感じで、予想の詳細を見ることができます。
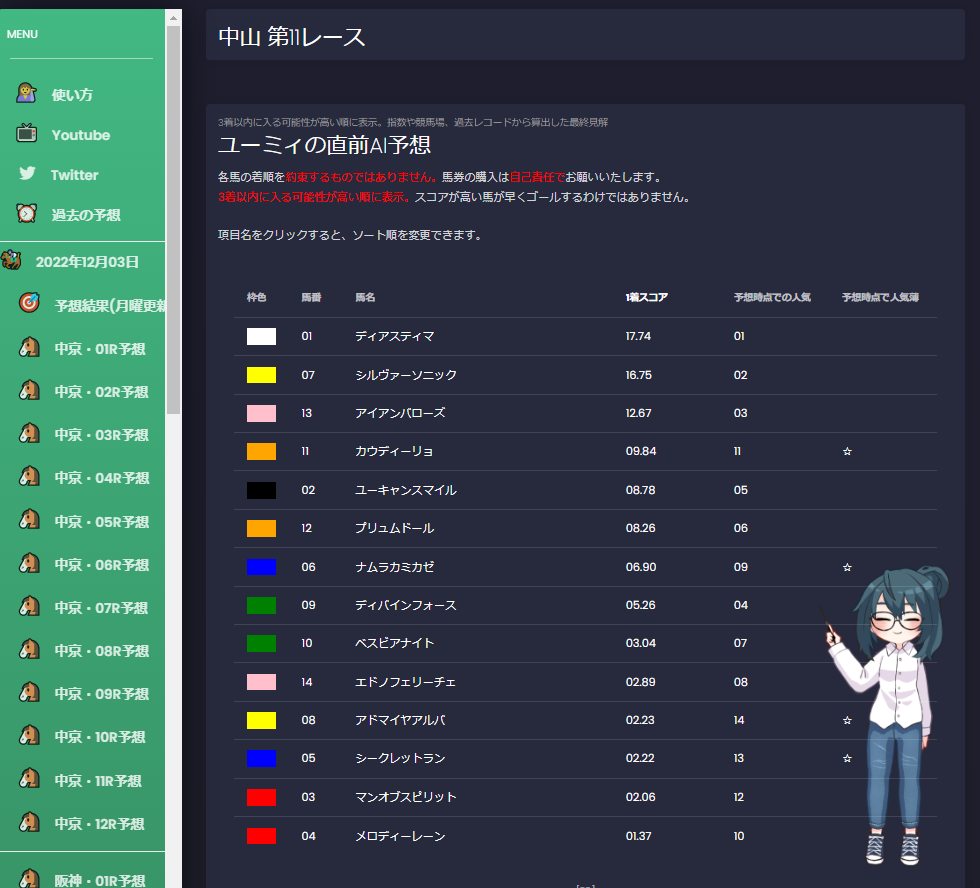
今日は、中山と中京の開幕週だったのですが中京の調子がめちゃくちゃ悪かったです・・・。
実は、私はプログラミングの経験はあったものの、競馬も機械学習も昨年から始めたばかりでした。
ちょうど1年くらいたったので、この機会に見返してみたいと思います。
技術的な取り組みも、記載しますが、ほぼほぼ振り返りのポエムとなります。ご了承ください。
事の発端
ウマ娘です。
ウマ娘が流行り、私たちの中でも、リアル競馬予想してみよう。という話が出ます。
折角なので、ポイント制で重賞の予想合戦をして遊ぼうという話が出ました。
競馬予想をしてみる
とりあえず、最初の予想合戦のレースは、2021年のNHKマイルカップに決まりました。
競馬はやったことないので、予想の仕方も手順もわかりません。
そもそも、お馬さんは生き物なのでそんな予想通立てても滅多に予想通り行くもんちゃうやろ。くらいに考えていました。
色々調べてみると、どうやら予想をするには、新聞を見たり、馬柱を見るのがセオリーのようです。
まずは、何はともあれJRAのサイトを訪問して馬柱を見ることにしました。
馬柱に絶望する
どれどれ、どんなもんじゃろね。
と、馬柱を見に行くと、馬毎に、前走、前々走、、、。と記載された馬柱が表示されました。
あー、ふーん。なるほどね。 無理だこれ
確かに一個一個の項目の解説を見て行って、どれが何を表していて。
というのは理解できます。
しかし、私にはこの馬柱の形式で予想するのは結構大変だぞ。ということが分かりました。
私の目論見としては、お馬さんの力を比較するので、
ある程度同じラインにデータを並べて、比較するんだろうな。と思っていました。
例えば、このお馬さんは、1600mなら何秒で走ったよ。
別のこのお馬さんは、1600mなら何秒で走ったよ。
そういうのをソートしたりして、比較したりするものだと思っていました。
初心者の私には、各場所に何を書いてあるのかを追うので精一杯。
脳のメモリを使い果たしてしまいます。
netkeibaに頼ってみる
その後、netkeibaというサイトがある事を知りそこを訪れます。
比較しやすい構造になっており、お馬さんや騎手の過去のデータもすぐにたどることができました。
「これは便利~!早速予想してみよう。」
と思いながら、比較を始めました。
なるほど、この子が人気と、、、過去にどんなレースでどんな走りだったんだろう(ポチ)(タブが開く)
なるほどなるほど、じゃあこの子は、、、過去にどんなレースでどんな走りだったんだろう(ポチ)(タブが開く)
なるほどなるほどなるほど、じゃあこの子は、、、過去にどんなレースでどんな走りだったんだろう(ポチ)(タブが開く)
あれ、じゃあ、前のあの事この子は前のレースで一緒に戦ってたのか、その時は・・・?(ポチ)(タブが開く)
山のようにタブが開きました。
且つ、お馬さんごとにページを行ったり来たりするので、煩雑です。
最初のころは、人気どころも人気薄どころもわからないので前頭見ていました。
そのうえで、良さそうな所と、悪そうなところをスプレッドシートにメモしておき、
このお馬さんと、このお馬さんならどっちが好み?ということを繰り返し、手動でソートするようにしていました。
ちなみに、一番最初のNHKマイルカップの予想はこんな感じだったみたいです
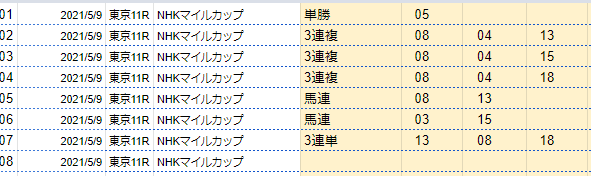
今見返したんですけど、11人気、4着のリッケンバッカーを挙げてたりと結構面白いですね。
手動比較した甲斐があったのかもしれません。
宝塚記念あたりで限界を迎える
宝塚記念、マーメイドステークスあたりでも同じようにスプレッドシートにメモをし、
手動で1頭1頭相互に比較ソートしていました。
宝塚記念は時に入念に過去のレースを見直し、クロノジェネシスがめちゃくちゃ強いことと、
他のお馬さんはクロノジェネシスに勝つにはどうしてくるかを考えたりしていました。
結果、各コーナーごとの展開予想などを1頭1頭考えたりしていました。
が、しかし。それだけデータを見ているので、1レース予想するのにかなりの時間を使います。
どうにかしようと考えました。
比較しやすいツールを作ろう
流石に、時間がかかりすぎるな。と思うようになったので、自分用に比較するツールを作ることにしました。
・レース、お馬さん、騎手の基本情報(勝率等)
・お馬さんの距離ごとのタイムを比較する表
・そのタイムがレコードタイムに対して何秒遅かったのか
・過去のレースで一緒に走ったことがあれば、その時の勝ち負け
・重賞入賞経験
などなどのデータをスクレイピングなどで集めておき、
自分用にvue.jsを使って1ページで表示できるようにしました。
競馬とvuejs、スクレイピングに対する知識が向上する
自分のためにバリバリツールを作るので、vuejsやスクレイピングの実装がもりもり身に付きました。
ただ、自分用のツールであるがゆえに、雑で動けばいいコードを量産していたため洗練されたコードにはなりませんでした。
また、ツールを作っているうちに、自分の知らない競馬に関する用語・知識がバンバン出てきます。
「後ろ3F?」「競馬場の構造??」「ダートの外枠内枠?」「雨の日の芝とダートの馬場状態の違い・・・?」
色々知識を吸収しながら、自分用の競馬比較ツールはアップデートを繰り返しました。
競馬AIとの出会いと、予想自動化計画
比較用のツールを作っていくうえで、お馬さんの強さを比較するのに
ある程度注目するデータがどこらへんかが、多少分かってきました。
そんな中、Qiitaでこの記事を見つけます(当時はQiitaに掲載されていましたが、現在hatenablogに移転されています)
netkeibaなどのデータを集めて、機械学習して競馬予想してみるというものでした。
当時の私は流し見程度で、チンプンカンプンだったのですが、
上記の記事で制作したAI予想が公開されていることを知りました。
どんなもんなんでしょね。と思い、見てみると確かに結果に近い予想になっていました。
高スコアの予想は1人気以外でも1着になるなどしていたりしているのを見て驚きました。
一方で、確かにデータを集めればある程度予想に役立つことはわかっていたので、
私もせめて、自分の予想に関する考えをアルゴリズムに落とし込んで、自動化できないかな。
と考えます。
そうして爆誕したのが、レコメンドソート でした。
レコメンドソートの爆誕
ある程度、ここら辺は有効なデータだな。というあたりがついていたので、
まずは、それらのデータを、レース単位でランキング化します。
そのうえで、この項目はこれくらい重要だから、重みはこれくらい、この項目はこれくらい・・・。
というのをトライアンドエラーででやって、結果として出てきたお馬さんのスコア順にソートして表示する。
という機能を実装しました。
結果、稀にそれっぽい予想は出すものの、実用とはほぼ遠い機能ができました。
本腰を入れて競馬AIを作ってみよう
その後、いろいろな競馬AIを見て確かにデータがあれば、(儲かるかどうかはさておき)有用な予想を出せる競馬AIは作れるものなんだなー。
ということが分かりました。
ここまでで、競馬予想や比較ツール開発を始めてから半年ほど立っていたので、ここまでの知識を使ってAIを作ったらどのようなものができるんだろうと気になりました。
ということで、まずは、先述した「AIうまたん」の技術記事をなぞって、自分でも競馬AIを作ることにしました。
競馬AIを作り始める
記事を読んでみると、
・netkeibaからデータを集めて
・CSVデータとしてまとめて
・データの変換をして
・LightGBMというフレームワークに渡す
と予想してくれる。ということが分かりました。
なるほどね。
netkeibaからデータを集めて...
やりたくないなぁ
スクレイピングの壁
すでに競馬比較ツールを作っていたので、ある程度感じていたのですがスクレイピングには時間がかかります。
特に競馬予想用のデータを集めるとなると、結構な量を集めることになることが予想されました。
ので、一旦JRA-VAN DataLabという中央競馬のデータを提供してくれるサービスと
PC-KEIBAというDataLabのデータをPostgresに入れてくるソフトウェアを使用することにしました。
その詳細はおおよそ↓に書いてあります。
うまたんちゃんの記事をなぞってみる
うまたんちゃんの記事をなぞって、AIを作ってみます
ただ、今回使用しているデータはDataLabのため
うまたんちゃんの記事で使用しているようなnetkeibaのタイム指数などは使用することはできませんでした。
ので、手順は踏襲しつつ、与える特徴量については気になったものを好き勝手渡すようにしました。
ざっくり手順としては
- データを集めて
- 数値にできないものはエンコードする(騎手名など)
- 予想させる指標をつくる(今回は3着以内に入るかどうか)
- LightGBMに予想してもらう
というものでした。
なるほどね。
AIを作ってみる
タイム指数などが使えないことや、データの取得元が違うことが分かっていたので、
ある程度自分の好きな要素を渡して、予想させてみようという気持ちでいました。
今思うと、かなり気持ちが掛かってますね・・・。
当時の私の思想はこうでした
「〇〇指数などの、人が自分の都合がいいように作ったデータを渡すと、予想に指数を作ったひとの主観が入ってしまう」
「ので、基本的に実績値以外は渡さない。つまり、DataLabのデータをほぼそのまま渡して、機械学習には予想してもらう」
「機械学習はかしこいので、そのデータから関連性を見つけて予想してくれるはず」
「他の人の主観は入れたくないので、人気もオッズもAIには渡さない」
賢い(?)ですね
まぁ、そんなに上手くいかないだろうという気持ちはありつつも、まずはこういう思想でデータを渡したらどうなるのか。
ということで作り始めました。
AIを作るために最低限必要だったもの
まずは以下の3点を作りました
・データセットを出力するプログラム
・AIモデルを作るプログラム
・AIモデルを使って予想をするプログラム
Java/nodejsプログラマーだった私は、ほぼ使ったことのないPythonで書いたので苦労しました。
pandasなども初めて使いました。
pandasはおおよそメモリにデータをロードしてDB的にデータを集計・操作できるので便利ですね。
AIモデルの作成は、とりあえずLightGBMフレームワークを使うことにしました。
AIちゃんにラベルエンコーディングが無視されてる事件
・ある程度DBからデータを取得してCSVに出力
・騎手名などはラベルエンコーディングして
・AIモデルを作って、予測
ということをやってみました。
ちょっと記憶があいまいなのですが、
・なんかハイパーパラメータというのをチューニングする必要があるらしい
・optunaというものが、そのハイパーパラメータは自動でチューニングしてくれるらしい
・学習してる項目の重要度(Importance)を出せるらしい
ということも、調べているうちに拾って試してみていました。
(Optuna試したのはもう少し後だったかも)
すると、ある事に気が付きます。
ラベルエンコーディングした値の重要度が、どれも0になっていました。
つまり、丹精込めてエンコードした値はほぼ使われて無いようでした。
oh....
ちょっと理由はわからないのですが、とりあえず予想が出せたのでヨシ!
ぶっつけ予想
金曜日の夜から土曜を使ってちょうど、日曜に予想が出せるようになりました。
なんか、それっぽい予想が出てることが分かります。
今日は日曜日。GI 朝日杯FSが開催されます。なるほどね。
まずは、直近でやってたレースを予想させてみましょう
2021年の12月18日、阪神10Rに甲東特別を予想させたようです。
予想順は
◎ 1.シャーレイポピー
〇 7.メイショウシンタケ
▲ 4.シャンブル
△ 2.セントウル
☆ 5.ブレイニーラン
というものでした。
結果は。。。。
1着:◎1.シャーレイポピー
2着:〇7.メイショウシンタケ
3着:△2.セントウル
oh...おおよそ当たってました
ほぼ、人気通りの超堅い決着ですが人気やオッズを渡さずに人気に近い結果が出せたのを喜んでいた覚えがあります。
私は思います。 「あれ?結構行けるんちゃう?」
そのまま、朝日杯FSの予想へ。
こんな感じの予想でした
◎09:ドウデュース
〇07:ダノンスコーピオン
▲ 13:ジオグリフ
△04:セリフォス
☆08:プルパレイ
折角なので、ドウデュースを軸に3連単を流します。
理由はさっき3連単当てられそうだったからです。
当たりました。
結果は
1着 ◎09:ドウデュース(3人気)
2着 △04:セリフォス(1人気)
3着 〇07:ダノンスコーピオン(4人気)
という順でした。
https://jra.jp/datafile/seiseki/g1/afs/result/afs2021.html
私は思います。 「あれ?結構行けるんちゃう?」
そう思い、競馬AIの沼にずぶずぶと浸っていくのでした。
競馬AIの沼へ
とは言ったものの、実際はそんなに甘くありませんでした。
競馬のデータが距離や、競馬場ごとに絞る必要がありそうだと感じていたので、
レースごとに特化させたモデルを作っていました。
具体的には、距離や競馬場で絞ったデータを与えて学習させていました。
そうなると、そのたびに学習が必要になりますし、予想できる範囲がかなり絞られます。
また、GIのようなつよつよで、特徴が目立つお馬さんが多いとも限りません。
また、致命的なことに、穴目を全然拾えていませんでした。
しかし、一方で、「レコメンドソート」よりはかなり実用的なものができそうという期待がありました。
レースごとにモデルを作っていてはほんと時間がいくらあっても足りません。
また、人間と違う視点から予測する以上穴目を拾いたいものです。
ここからめちゃくちゃ色々作ることになります
つまり、あとはこれをいかに汎用化して、改良して、運用していくかです。
いろいろ取り入れて、いろいろ作る
ひとまず、モデルが作れるようになりました。
意外と、やったらできたのは良かったです。
楽しくなってきたので、その後、現在までいろいろやってみました。
機械学習に関する基礎知識を手に入れる
を読みました。
とても詳しく書かれているので、十分に理解できているわけでは無いのですが、
実際にアヤメの分類などを実装してみて、機械学習がどのように学習していくのか、
また、各種エンコーディングの方法などを学びました。
特徴量の追加、選定。
DataLabのデータそのままではアカンことはわかりました。
得られたデータから色々作ったり試したりしてみます。
データは作る一方で、「できるだけ人の主観は入れない」というコンセプトは求めていきたいと思いました。
- データセットの構造の改善
- ラベルエンコーディングだけではなく、Categorical Futureを設定する
- https://qiita.com/sinchir0/items/b038757e578b790ec96a
- ラベルエンコーディングそのままだと、エンコード後の数値に意味を見出そうとしてしまう場合があります
- そのため、ラベルエンコーディングで数値にした後、データの型をcategory型に指定することで
- LightGBMにカテゴリであることを伝えます。
- また、LightGBMはcategory型で定義されていることが分かると、それを元に分類します。
- ラベルエンコーディングした際のエンコーダをモデルと一緒に保存しておく。
- ラベルエンコーディングすると、変数ごとに番号が振られます。
- 例えば「1:中山競馬場」「2:東京競馬所」といった具合です。
- しかし、データを与える順番によってはエンコーダは「2:中山競馬場」「1:東京競馬所」と振る場合があります。
- つまり、学習時のエンコードした時の方法を保存しておいて、予測時も学習時のエンコードルールでラベルエンコードする必要があります。
- そのため、学習時のエンコーダは、モデルと一緒に保存しておく必要があります。
- OneHotEncodingを試してみる
- 例えばそのデータが「中山競馬場」のレースのデータを表すために「中山競馬場のレースであるかどうか」を0/1で表すカラムを用意します
- そうすることで、LabelEncodingのように値自体に意味を見出さずTrue/Falseで機械学習に判断してもらうことができるようになります。
- ちなみに、LightGBMのCategorical Featureはこの仕組みを、より効率的に行えるらしい。
- 存在しないOneHotEncodingしたカラムをどうするか
- 例えば、騎手名でOneHotEncodigした際、2021年以前のデータには2022年にデビューした「今村聖奈騎手」のカラムはありません。
- しかし、予測データのには「今村聖奈騎手」をOneHotEncodigしたカラムが現れることになります.
- この場合、「今村聖奈騎手」のカラムはデータから削除することにしました。(予測時に存在しないので、判断基準を持っていないはずなので)
- 特徴量を増やす
- 出遅れ率
- 調教評価
- 休み明け判定
- スピード指数
- etc... - できるだけ、複数のモデルを作らなくてもいいように設計する
- その他いろいろ
予想を掲載するページを作る
作りました。サーバサイドレンダリングなどをしてみました。
ページ自体はGitHubPagesを利用することにしました。
データセットのビューアを作る
個人用なので公開していませんが作りました。
既存のツールでは、競馬データの閲覧に特化していないため、痒い所に手が届きませんでした。
データセットの分析や、作ったデータの正しさを確認するために使っています。
データセットの出力と、指数や勝率計算は分離する
1競馬場でも、5~10年単位のデータが欲しいので、データ数が膨大になります。
データセットを出すのにも時間がかかります。
また、そのデータセットを元に、勝率、指数などを計算すると時間がかかります。
時間がかかると、トライアンドエラーに時間がかかり、モデルの改良に時間がかかります。
データを出力するフェーズと、出力したデータを加工して、更にデータを作るフェーズは分けることでできるだけ時間がかからないようにしました。
クラウドを使ってマルチコンピューティングを実行する
それでも、データや、指数、勝率などを計算するようになると、データセットを出すのにも時間がかかります。
1競馬場でも、5~10年単位のデータが欲しいので、データ数が膨大になります。
5~10年単位のデータ x 中央競馬場(10会場)です。
手元のパソコンも、ノートPCでありながらメモリ64GBとなかなか強力なのですが、数の暴力で時間の短縮を図ります。
プリエンプティブルインスタンスを借りれば、お値段1/3ほどになります。
つよつよマシンをいっぱい借りて短期決戦で、決着を付けます。
実際、最近になってようやくやるようになったんですが、もっと早くの段階からやればよかったです。
お値段も、ちゃんとリソース管理すれば個人が出せる範囲で収まると思います。
リアルタイムに予想を投稿するプログラムを作る
作りました
実際の所、リアルタイム投稿以外にも以下のものを作る必要がありました
- 予想投稿前日に、データを集計するバッチ
- 予想投稿前日に、前日予想をしてデプロイするバッチ
- 予想投稿当日に、予想をデプロイするバッチ(常に実行しておき、時間になったら投稿する機能)
- 予想投稿当日に、予想をツイートするバッチ
地方競馬にも対応させる
コンスタントに予想投稿していませんが、地方競馬の予想も出せます
モデルを評価する仕組みを作る
作ったモデルがどれくらいの的中率なのか、どれくらいの性能なのかを評価するバッチを書きました。
1日の予想結果を出力する仕組みを作る
1日ツイートした予想に対して、実際はどうだったのかをパッと出せるようにするバッチを書きました。
学習管理を取り入れる
モデルを作成しているときに、学習がどんな感じで進んでいるのか、
モデルを作ったときにどんなコードで、どんな設定だったか、
どんな特徴量を使っていたか。管理が大変になってきました。
neptune.aiを利用して学習管理をするようにしました。
SHAPに就て学ぶ
モデルがどういう風にデータを解釈しているか知るために、SHAPのデータを出力できるようにしました。
FLAMLや、ランキング学習を試してみる
複数の機械学習フレームワークで、まとめて学習させることのできるFLAMLでのモデル作成を試してみました。
また、ランキング学習での予想も試してみました。
買い目生成器の作成
「予想を元に有効な買い目を作ることができるのか?」を検証するために、
AI予想から自動で買い目を出力するプログラムを作成しました。
また、自動で買い目を出せるようにしてみました。
リモートメンテの機能を整備
休日に競馬場に行ってても、AIちゃんのメンテや、バグ修正、保守をできる仕組みを整えました
競馬AI開発系Vtuber「ユーミィちゃん」の動画作成
動画をサクッと作るプログラムをつくったりしました。
--
その後どうなったか
AIちゃんは、人気どころも拾いつつ、穴目も拾うようになりました。
人気どころも押さえつつ、穴目も拾ってきますが、まだ、人気どころの信頼度も薄かったり、
紐抜けが起きたりしているので改良が必要だと思います。
実際、2桁人気や、中穴をAIちゃんが見つけてくれるとかなり嬉しいものがあります。
儲かりまっか/儲かりましたか
全然。全く。
運用コストも、研究費用もありますし、安定してプラスになる予想ではありません。
買い目の探求もするにはしていますが、どちらかというと予想の改善の方に力を裂いています。道楽です。
ただ、わりと、穴目とかを拾ってきてくれるようになったので、満足感はあります。
みんなが知らないことを見つけられるって楽しいですよね。
大人数が気づかなかったことを、自分の技術で知れるようになる経験は、なかなかないように思います。それがとても楽しいです。
また、自分がちゃんと良いものを作れていれば、競馬が当たるはずなので、予想を売るなどのこともしません。(;'∀')
今後
統計などの知識・資格などにも手を伸ばして堅実に力を付けたいなと思っているところです。
フルスタックエンジニアになったの?
もともと、サーバサイド向けの開発をしていたのですが、自作AIを作ることで
・サーバサイド開発(もともとやってたこと)
・雑にクライアントサイドのアプリを作る
・クラウドの活用や、雑にマルチコンピューティング環境を構築する
・雑に機械学習を行う
・雑に企画を行う
・雑に改善を行う
ということを実施しました。
品質的には機械学習の精度もまだまだですし、クライアントサイドのページも重かったりするので、
ほんと趣味レベルのフルスタックエンジニアリングだなぁ。という気持ちです。
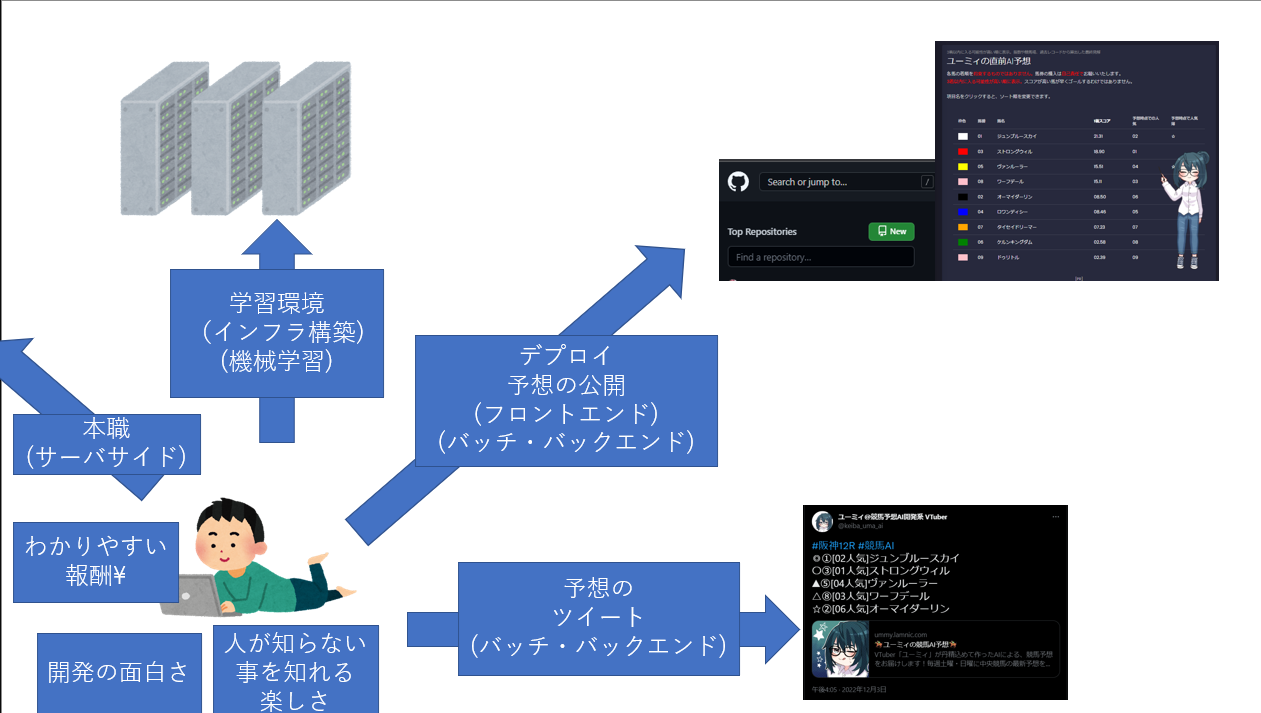
ただ、競馬AIは、とめどなくやりたいことと、やってみることがあふれてくるので
「何か作ってみたいけど、何作っていいかわからん」みたいな状況にはうってつけなんじゃないかと思いました。
競馬AIのおかげで年間を通して色々作って挑戦してみることができ、楽しい1年でした。
土日に勝手に予想考えてほしいな~。くらいからの構想にしては、だいぶ色々作るようになりましたが・・・(;'∀')