簡単に
・LightGBMのパラメータ"Categorical Feature"の効果を検証した。
・Categorical Featureはcategorical_feature変数に列名を指定するか、pandas dataframeのcategory型の列に対して適用される。
・Categorical Featureへ設定する変数は、対象のカテゴリ変数を0始まりの整数に変換後、int型 or category型にするのが公式の推奨。
・Categorical Featureを設定すると、必ず精度が向上するわけではない。
・high-cardinality or low-cardinalityなカテゴリ変数のみをCategorical Featureに設定すると精度が向上する可能性がある。
初めに
SIerでデータサイエンティストをしているSinchir0です。
データ分析コンペティションサイトKaggleではLightGBMという分析手法が高い人気を誇っています。
そのLightGBMのパラメーターの一つに「Categorical Feature」があります。
Categorical Featureにカテゴリ変数を設定すると、LightGBMに最適な形で
カテゴリ変数を処理してくれるらしいです。
このCategorical Featureですが、kaggleのカーネルや様々な記事を見ていると
記載している人や記載していない人、記載していても設定している変数のデータタイプがバラバラなように見えて、正しい使い方がよく分かりません。
「正しい設定の仕方は?そもそも本当に効果あるの?」と疑問に思ったため検証しました。
変な所などあったら指摘頂けると勉強になり助かります。
コードは下記にて公開しています。
https://www.kaggle.com/sinchir0/will-categorical-feature-really-improve-accuracy
Categorical Featureは指定した方が良い?
データによります、という無難な回答になります。
記事の後半で説明しますが、私がtitanicのデータで試した時は、性能向上は確認できませんでした。もしかしたら高速化などで効果があるのかもしれませんが、確認はできていません。
Categorical Featureの設定方法
僕が初めてCategorical Featureを使用しようと思った際に一番困ったのは
「コードのどこに記載すればいいんだ・・・」という悩みであったため、
初めに記載方法から説明します。
LightGBMの記載方法にはTraining APIとScikit-learn APIがあります。
Training APIの場合は下記のtrainが記載場所となります。
cat_list = ['column1', 'column2', 'column3']
model = lgb.train(params, lgb_train, num_boost_round=num_round,
valid_names=['train', 'valid'],
valid_sets=[lgb_train, lgb_eval],
categorical_feature = cat_list, #ここでcategorical_featureを設定
)
Scikit-learn APIの場合は下記のfitが記載場所となります。
cat_list = ['column1', 'column2', 'column3']
model.fit(X_train, y_train,
eval_set = [(X_test, y_test)],
categorical_feature = cat_list, #ここでcategorical_featureを設定
)
Categorical Feature とは
公式では下記のように説明されています。

(https://lightgbm.readthedocs.io/en/latest/Advanced-Topics.html より引用)
ざっくり訳すと
・LightGBMはCategorical Featureの設定によって、one-hot encodingより良い精度を出すよ。
・カテゴリ変数を整数(int)でエンコードする必要があるよ。
という感じです。
また、別のページでは下記のような説明があります。

(https://lightgbm.readthedocs.io/en/latest/Parameters.html#categorical_feature より引用)
ざっくり訳すと
・Categorical Featureはmulti-intかstringを取るよ。
・int型のカテゴリ変数のみサポートしてるよ。
・カテゴリ変数が0から始まる連続した整数だとベストだよ。
・負の値は欠損値として扱われるよ。
という感じです。
更にCategorical Featureが何をしているかが下記でまとめられています。(多分)

(https://lightgbm.readthedocs.io/en/latest/Features.html#optimal-split-for-categorical-features より引用)
ここ、正直何を言わんとしてるかよく分からないのですがとりあえず、
・high-cardinalityな(=要素が多い)カテゴリ変数をone-hot encodingして決定木で扱う場合には、木を深くする必要がある。
・それを回避するための素敵な方法をCategorical Featureに設定するとやってくれる。
ということは分かりました。
まとめると、
・設定するとhigh-cardinalityなカテゴリ変数を上手く扱ってくれる。
・設定するカテゴリ変数は整数であること
・設定するカテゴリ変数は0から始まっていること
が大事っぽいです。
ざっくりは理解しました。後は検証で理解しようかと思います。
使用データ、LightGBMパラメータ
検証内容の前に、使用データとパラメータについて記載します。
データ概要
かの有名なkaggleのタイタニックデータで検証します。
変数「division」はtrainとtestの結合時に追加しました。
データの先頭5行と、データタイプ一覧です。
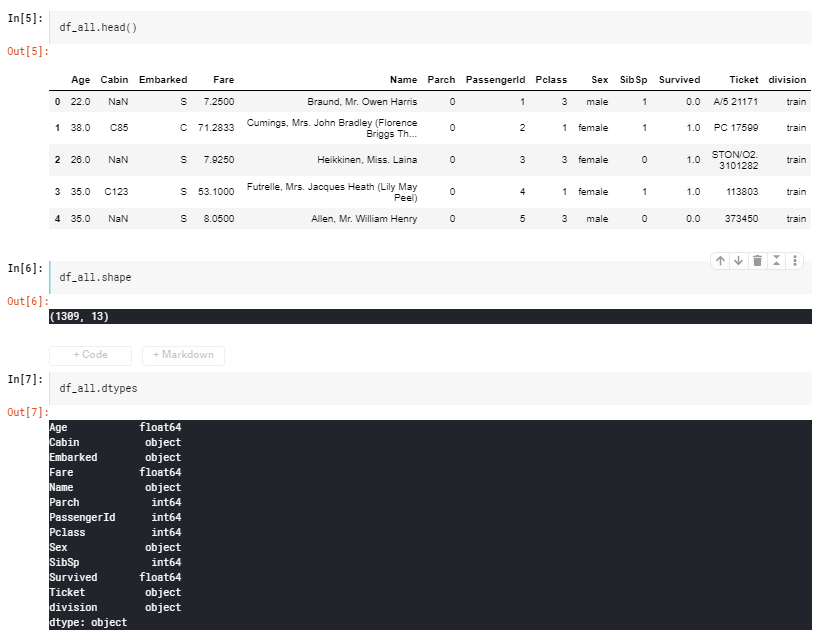
使用する変数
全変数のうち、PassengerId,Name,divisionを除いた下記変数を使用します。
・Survived
・Pclass
・Sex
・Age
・SibSp
・Parch
・Ticket
・Fare
・Cabin
・Embarked
上記のうち、カテゴリ変数に該当するものは下記となります。
・Survived
・Pclass
・Sex
・SibSp
・Parch
・Ticket
・Cabin
・Embarked
Survivedは目的変数のため、それ以外のカテゴリ変数をいじっていきます。
LightGBMのパラメータ
パラメータは下記で行います。
num_leaves=300,
learning_rate=0.1,
random_seed=1,
max_depth=2,
num_boost_round=1000,
early_stopping_rounds=10,
#検証
下記5パターンで検証しようかと思います。
評価指標はAccuracyです。Stratified K-Foldで3分割したAccuracyの平均で比較を行います。
1.Categorical Feature自動設定、one-hot encoding
2.Categorical Feature自動設定、Label Encoding
3.Categorical Feature設定あり、int型
3-1.全てのカテゴリ変数をCategorical Featureに設定
3-2.要素が多いカテゴリ変数のみをCategorical Featureに設定
3-3.要素が少ないカテゴリ変数のみをCategorical Featureに設定
4.Categorical Feature設定あり、文字型
5.Categorical Feature設定あり、category型
1.Categorical Feature自動設定、one-hot encoding
自動設定のため、Categorical Featureのパラメータは明記しない方針です。
何も考えずカテゴリ型は全てone-hot encodingします。
(本来はone-hot encodingする必要がないため、誤った方法です。)
# リストの作成
one_hot_list = ["Pclass","Sex","SibSp","Parch","Embarked","Ticket","Cabin"]
# one-hot encodingの実施
df_all_1 = pd.get_dummies(df_all, columns = one_hot_list)
とってもsparseなデータが無事出来上がりました。
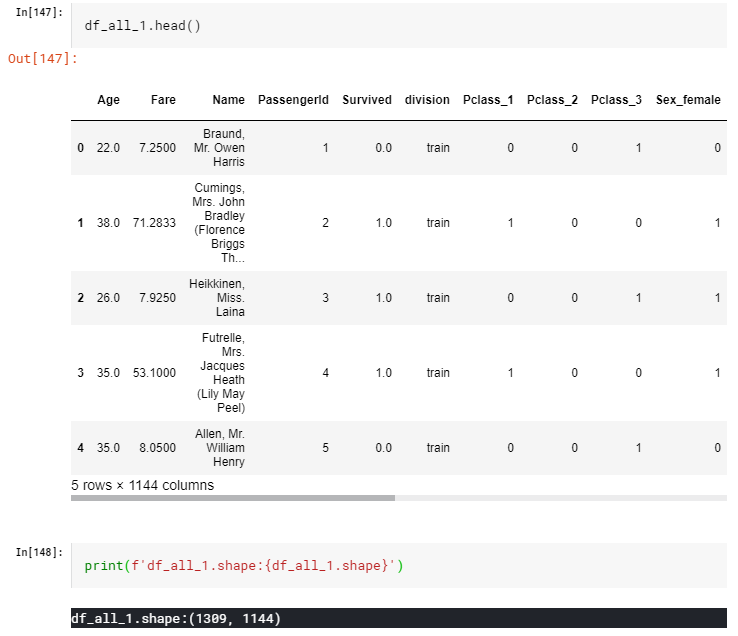
1144列!メモリ食いまくりですね。
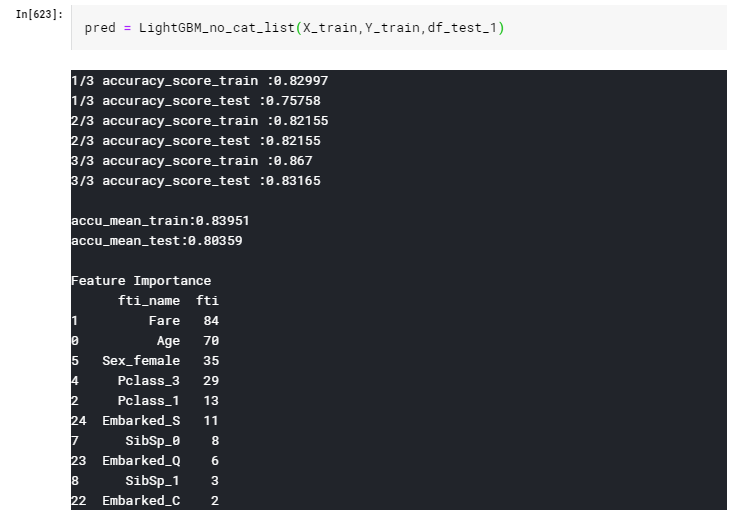
このときの、LightGBMによる3-fold Cross Validationのaccuracyの平均は
0.80359となりました。
2.Categorical Feature自動設定、Label Encoding
次はカテゴリ変数をLabel Encodingのみ行います。
まず、カテゴリ型のうち、データタイプがobjectのものをLabel Encodingします。
# リストの作成
Label_Enc_list = ["Sex","Embarked","Ticket","Cabin"]
# Label Encodingの実施
import category_encoders as ce
ce_oe = ce.OrdinalEncoder(cols=Label_Enc_list,handle_unknown='impute')
#文字を序数に変換
df_all_2 = ce_oe.fit_transform(df_all)
#値を1の始まりから0の始まりにする
for i in Label_Enc_list:
df_all_2[i] = df_all_2[i] - 1
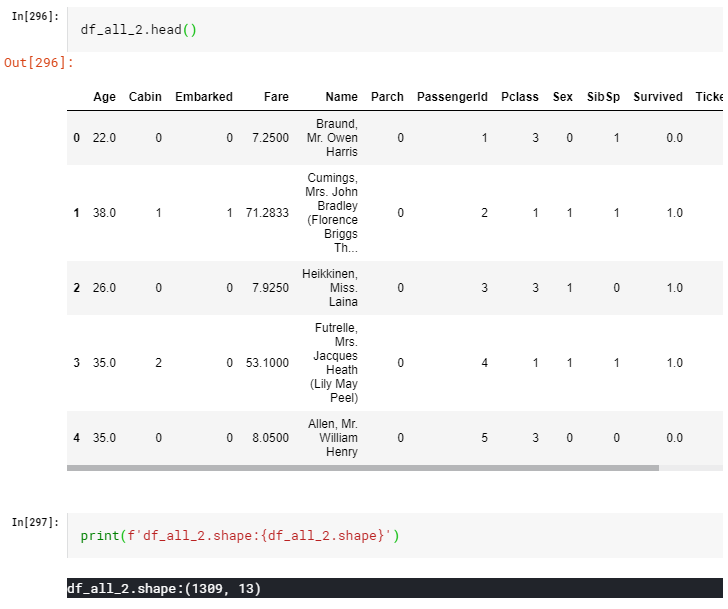
うん、綺麗にまとまってて扱いやすそうですね。
このときの、LightGBMによるaccuracyの平均は
0.82267となりました。
(精度一覧は最後にまとめて行います。)
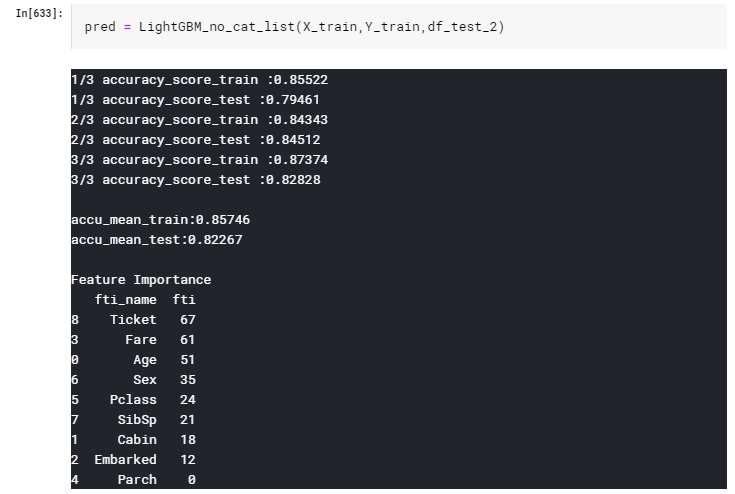
3.Categorical Feature設定あり、int型
ここからが本題で、Categorical Featureの設定を行います。
最初はint型で入れてみます。
まず、2と同様にLabelEncodingを行い、その後データタイプをintに変換します。
# リストの作成
Label_Enc_list = ["Sex","Embarked","Ticket","Cabin"]
# Label Encodingの実施
import category_encoders as ce
ce_oe = ce.OrdinalEncoder(cols=Label_Enc_list,handle_unknown='impute')
#文字を序数に変換
df_all_3 = ce_oe.fit_transform(df_all)
#値を1の始まりから0の始まりにする
for i in Label_Enc_list:
df_all_3[i] = df_all_3[i] - 1
#intにする変数名の指定
int_list = ["Pclass","Sex","SibSp","Parch","Embarked","Ticket","Cabin"]
for i in int_list:
df_all_3[i] = df_all_3[i].astype("int")
categorical_featureの設定はLightGBMの下記コメントの部分で行います。
gbm = lgb.LGBMClassifier(objective='binary',
num_leaves=300,
learning_rate=0.1,
random_seed=1,
max_depth=2,
num_boost_round=1000,
)
gbm.fit(X_cv_train, y_cv_train,
eval_set = [(X_cv_test, y_cv_test)],
early_stopping_rounds=10,
verbose=False,
categorical_feature = cat_list, #ここでcategorical_featureを設定
)
「high_cardinarityなカテゴリ変数を適切に処理する」という説明が公式の文章にあったため、
その検証を行うべく、Categorical Featureに下記3パターンで設定を行います。
3-1.全てのカテゴリ変数
3-2.要素が多いカテゴリ変数のみ
3-3.要素が少ないカテゴリ変数のみ
3-1.全てのカテゴリ変数をCategorical Featureに設定
まずは全てのカテゴリ変数をCategorical Featureに設定してみます。
Categoricak Featureに設定する変数は下記。
cat_list = ["Pclass","Sex","SibSp","Parch","Embarked","Ticket","Cabin"]
このときの、LightGBMによるaccuracyの平均は
0.80920となりました。
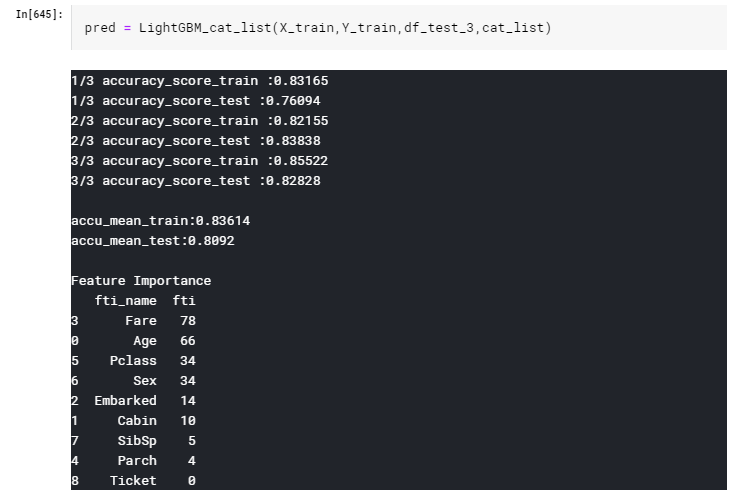
3-2.要素が多いカテゴリ変数のみをCategorical Featureに設定
次は、カテゴリ変数の要素が多いもののみCategorical Featureに設定します。
カテゴリ変数の要素数一覧は下記
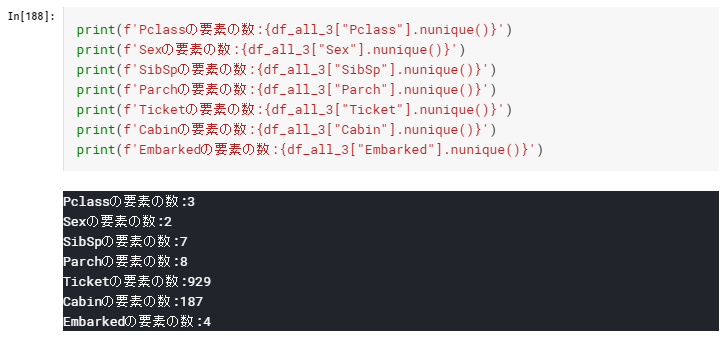
要素が100を超える、TicketとCabinのみCategorical Featureに設定
cat_list = ["Ticket","Cabin"]
このときの、LightGBMによるaccuracyの平均は
0.83277となりました。
3-3.要素が少ないカテゴリ変数のみをCategorical Featureに設定
今度は、カテゴリ変数の要素が少ないもののみCategorical Featureに設定します。
要素が100を下回る、Pclass,Sex,SibSp,Parch,Embarkedを設定
cat_list = ["Pclass","Sex","SibSp","Parch","Embarked"]
このときの、LightGBMによるaccuracyの平均は
0.80696となりました。
4.Categorical Feature設定あり、文字型
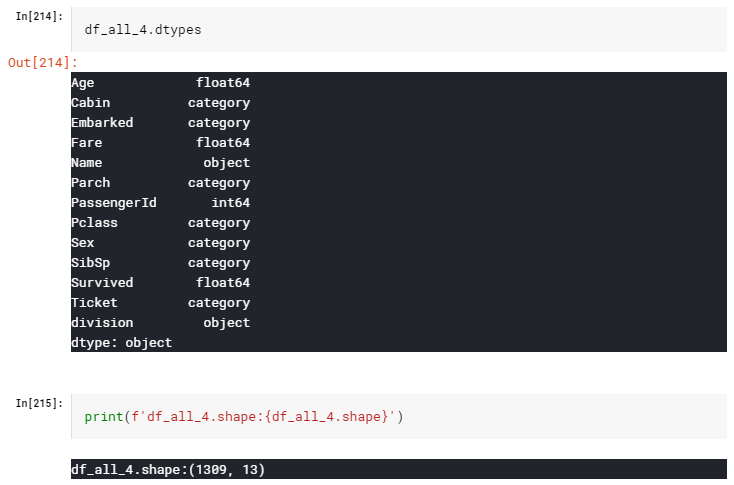
カテゴリ変数を全て文字型(object)に変換します。
# df_allを df_all_4へコピー
df_all_4 = df_all
#カテゴリ変数を定義
cat_list = ["Pclass","Sex","SibSp","Parch","Embarked","Ticket","Cabin"]
# カテゴリ変数を全て、object型へ変換
for i in cat_list:
df_all_4[i] = df_all_4[i].astype("object")
LigthGBMを実施してみると・・・
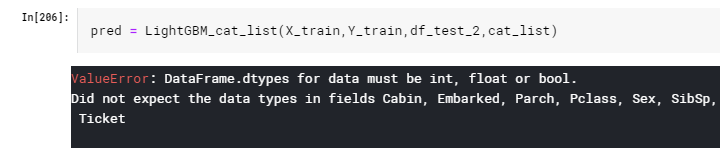
駄目でした・・・(´・ω・`)
>・Categorical Featureはmulti-intかstringを取るよ。
という説明をしましたが、どうやら
・Categorical Featureをintで指定した場合には、最初から何番目の列を指定する、
ex.「Categorical Feature = 1」なら「最初の列(0番目)から数えて1番目の列」を指定。
・Categorical Featureをstringで指定した場合には、列名で指定する
ex.「Categorical Feature = ['Pclass']」なら「"Pclass"という列名の列」を指定。
ぐらいの意味なんだろうなぁとここで察しました。
5.Categorical Feature設定あり、category型
職場で「整数値に変換後、category型で入れるべきだ」という意見をもらったことがあるため
合わせて検証しました。
カテゴリ変数を全て整数値に変換した後、文字型(category)に変換します。
# リストの作成
Label_Enc_list = ["Sex","Embarked","Ticket","Cabin"]
# Label Encodingの実施
import category_encoders as ce
ce_oe = ce.OrdinalEncoder(cols=Label_Enc_list,handle_unknown='impute')
#文字を序数に変換
df_all_5 = ce_oe.fit_transform(df_all)
#値を1の始まりから0の始まりにする
for i in Label_Enc_list:
df_all_5[i] = df_all_5[i] - 1
#カテゴリ変数を定義
cat_list = ["Pclass","Sex","SibSp","Parch","Embarked","Ticket","Cabin"]
# カテゴリ変数を全て、object型へ変換
for i in cat_list:
df_all_5[i] = df_all_5[i].astype("category")
このときの、LightGBMによるaccuracyの平均は
0.80920となりました。
結果のまとめ
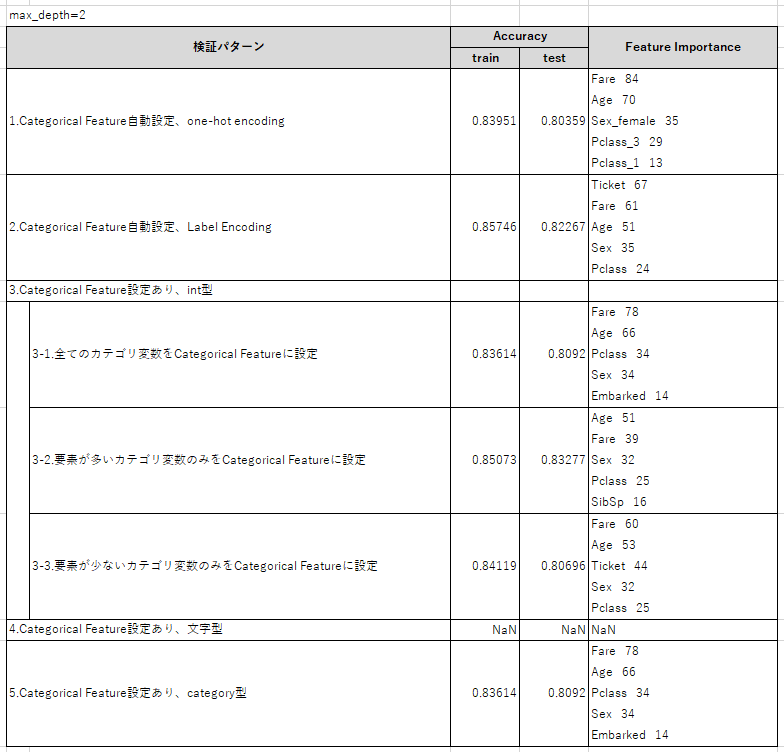
結果をまとめると下記の表のような感じになりました。(max_depth=2)
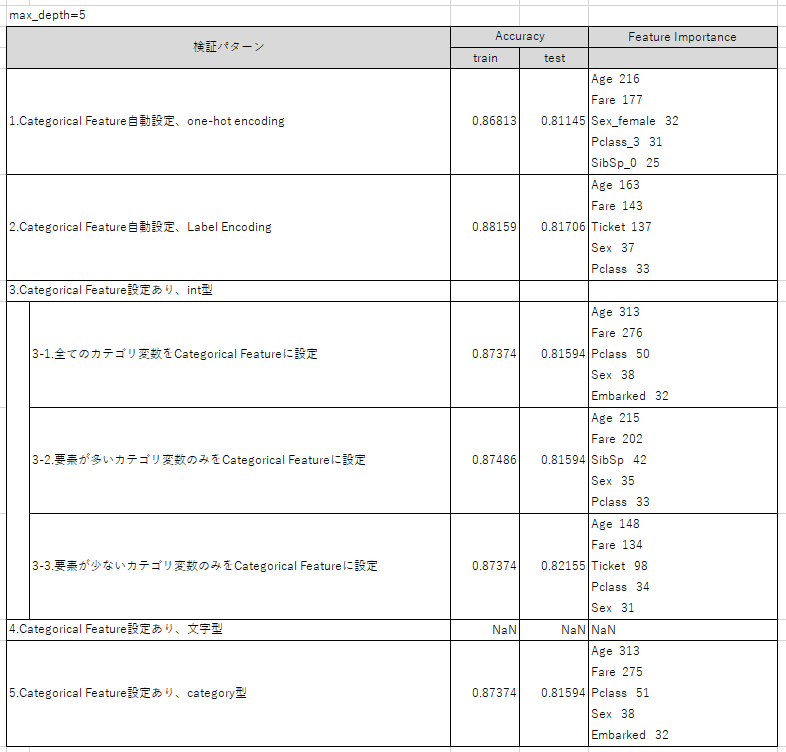
また、max_depth=5にして同様の作業を行うと下記のような結果になりました。
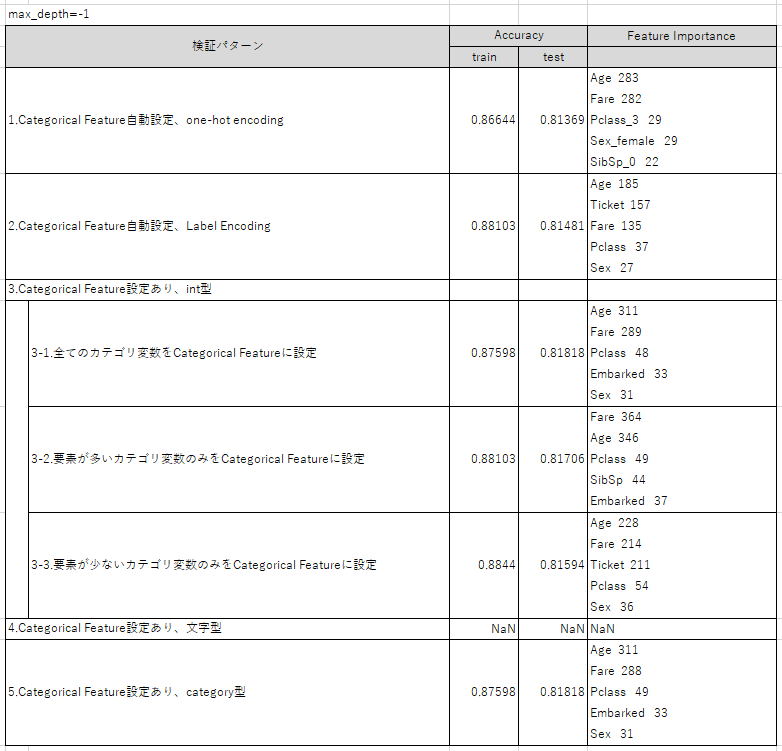
更にmax_depth=-1だと下記。
何点か結果からの気づきを記載します。全て、今回のケースに限っては、の話となります。
まず、max_depth=2のときの結果について
①「2.Categorical Feature自動設定、Label Encoding」と
「3-1.全てのカテゴリ変数をCategorical Featureに設定」の結果は一致して欲しかったのですが、
異なる精度になってしまいました。
自動設定で認識されるカテゴリ値と、僕が設定したカテゴリ値に差分があることを意味しています。
自動設定で何がCategorical Featureに設定されるかはもっと調べる必要がありそうです。
②「2.LabelEncoding」よりも「3-2.要素の多いカテゴリ変数のみCategorical Featureに設定」
の方が精度が高い。
③「3-3.要素の少ないカテゴリ変数のみCategorical Featureに設定」よりも
「3-2.要素の多いカテゴリ変数のみCategorical Featureに設定」の方が精度が高い。
④「3-1.全てのカテゴリ変数をCategorical Featureに設定」と「5.Categorical Feature設定あり」
の精度が全く同じのため、Categorical Featureはcategory型、int型のどちらで設定しても
精度に影響はない。
次に、max_depth=5の結果について、max_depth=2との差分を書くと
➄深くすると、検証パターン毎のAccuracyの差が少なくなる。
⑥「3-2.要素の多いカテゴリ変数のみCategorical Featureに設定」よりも
「3-3.要素の少ないカテゴリ変数のみCategorical Featureに設定」の方が精度が高い。
➆深くすると、特徴量重要度の上位はageで固定される。
となりました。
最後に、max_depth=-1(深さの制限なし)の結果について記載すると、
⑧「3-1.全てのカテゴリ変数をCategorical Featureに設定」した際が最も精度が良い。
考察
改めて言いますが、全て、今回のケースに限っては、の話となります。
まず、Categorical Featureを設定すると、必ず精度が向上するわけではなさそうです。
データ分析全般でそうですが、実際にやってみて判断が大事ということですね。
また、①について「2.Categorical Feature自動設定、Label Encoding」と
「3-1.全てのカテゴリ変数をCategorical Featureに設定」の結果は一致して欲しかったのですが、
異なる精度になってしまいました。
自動設定で認識されるカテゴリ値と、僕が設定したカテゴリ値に差分があることを意味しています。
自動設定で何がCategorical Featureに設定されるかはもっと調べる必要がありそうです。
また、③と⑥で結果が逆転するのは、理由は正直よく分かりません。
ただし、「high-cardinalityかどうかでCategorical Featureの設定する変数を変えることで、
精度が向上する可能性がある」ことが分かりました。
最後に、max_depth=-1で行うと、「3-1.全てのカテゴリ変数をCategorical Featureに設定」した場合が
最も精度が高くなりました。
このことから、Categorical Featureの設定が真価を発揮するのは、
max_depth=-1の時の可能性があることが分かります。
max_depthをLightGBM自身で決める際に、Categorical Featureを使っているということなんですかね?
全体のまとめ
というわけで、結論をまとめます。
・Categorical Featureを明記しない場合、pandas dataframeであれば自動で設定される。
・Categorical Featureはカテゴリ変数をLabelEncoding後、int型 or category型で設定するのが公式の推奨。
・Categorical Featureを設定すると、必ず精度が向上するわけではない。
・Categorical Featureの設定する変数をhigh-cardinalityかどうかでを変えることで、
精度が向上する可能性がある。
・max_depth=-1のときに、Categorical Featureを設定した成果が出るのかも。
コメント
初めての技術ブログ投稿&ヨワヨワなデータサイエンティストがまとめたものです。
変な所などあったらバシバシ指摘頂けると自身の成長にも繋がりとても嬉しいです。