はじめに
今回、AWS re:Invent2025で発表にもありました「Lambda durable functions」を実際に使用してみた際の内容をまとめてみました。
AWS Lambdaを使用されている方も多いと思いますので、どういったメリットがあり
どういった場面でどのように活用できるか参考になればと思います。
機能の概要
Lambda durable functionsの機能でポイントになるのは、「チェックポイント/リプレイ」になるかと思います。
チェックポイント/リプレイは、Lambdaの特定の処理の中にチェックポイントを作ることで、処理を中断が発生した場合にユーザーアクションや指定した時間などを通して完了したチェックポイントをスキップして処理の再開(リプレイ)ができる機能になります。
主な特徴
Lambda durable functionsの特徴について、以下にまとめました。
- チェックポイント/リプレイによる処理の途中中断、再開が可能
- 最大1年間の実行一時停止と再開
- 待機中はコンピューティング課金なし
個人的には実行を再開するまでの待機中のコンピューティングに関する課金が発生しないところはかなりありがたいポイントかと思いました。
サポートと提供リージョン
Lambda durable functionsは、2025/12/10時点でPython(バージョン 3.13 および 3.14)および Node.js(バージョン 22 および 24)ランタイムのサポートとともに、米国東部(オハイオ)で一般提供されています。
実際に触ってみた
デモの内容
今回は、durable functionsの特徴であるチェックポイント/リプレイ機能を確認するために以下のようなシーンを想定してデモを動かしてみます。
- Lambdaを実行
↓ - 処理内:文字列「Hello,」を用意する。
↓ - 処理内:【チェックポイント】S3にファイルの格納されるまで処理を中断する。
↓
自由時間(最大1年)
↓ - S3に「World!」と記載されたテキストファイルを格納する。
↓ - S3イベントにより中断されていた処理が再開する。
↓ - ファイルを取得し「Hello, World!」をレスポンスとして返却する。
実演の前提準備
Lambda durable functionsの使用は、関数の作成時にチェックを1つ入れるだけで
簡単に設定できます。
そのため、基本的な流れは通常のLambdaとほぼほぼ同じになります。
準備1:コンソール上からLambdaを開き、関数の作成を行います。
準備2:メイン用および、S3イベント用のコードの作成および、デプロイを行います。
※S3イベント用はPUTをトリガーとなるようにS3バケットの方での設定が別途必要になります。
準備1:コンソール上からLambdaを開き、関数の作成を行います。
ランタイムの下にある「Durable execution 」にチェックを入れて関数を作成します。
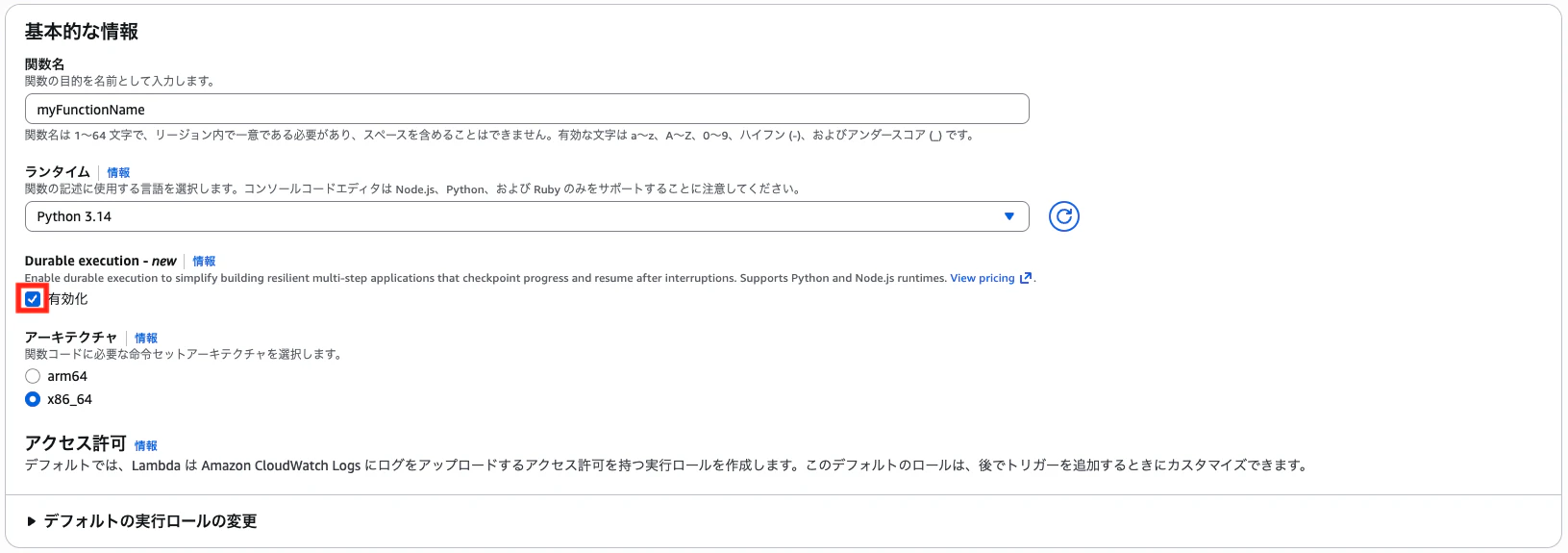
※2025/12/10時点では、東京リージョンでの利用はできないため米国東部(オハイオ)のリージョンに切り替えていただく必要があります。
準備2:コードの作成を行います。
Lambdaはメインとなるものと、S3のファイルアップロードをトリガーにチェックポイントで停止しているLambdaをリプレイ(再開)させるLambdaの2つから構成されます。
メインのサンプル
from aws_durable_execution_sdk_python import (
DurableContext,
durable_execution,
durable_step,
)
from aws_durable_execution_sdk_python.config import Duration
# ----------------------------
# Step: ファイル情報取得
# ----------------------------
@durable_step
def read_s3_file(step_context, s3_event):
import boto3
s3 = boto3.client("s3")
bucket = s3_event["bucket"]
key = s3_event["key"]
response = s3.get_object(Bucket=bucket, Key=key)
content = response["Body"].read().decode("utf-8")
return {"content": content}
# ----------------------------
# Orchestrator
# ----------------------------
@durable_execution
def lambda_handler(event, context: DurableContext):
import json
"""
event = {
"executionId": "hello-world"
}
"""
# 1. Hello を用意
response = "Hello,"
# 2. S3イベント待ち(チェックポイント)
s3_callback = context.create_callback()
context.logger.info(f"callback_id: {s3_callback.callback_id}")
s3_result=s3_callback.result()
s3_event = json.loads(s3_result)
# 3. S3 から World! を取得
s3_data = context.step(read_s3_file(s3_event))
response += s3_data["content"]
# 4. 結果返却
return {"result": response}
S3イベント通知から呼ばれるLambdaのサンプル
import json
import boto3
lambda_client = boto3.client("lambda")
def lambda_handler(event, context):
"""
S3 の PutObject イベントで起動される想定
"""
s3 = boto3.client("s3")
record = event["Records"][0]
bucket = record["s3"]["bucket"]["name"]
key = record["s3"]["object"]["key"]
# この部分は、メインのLambdaを実行時にログから確認を行い値を入れてデプロイしてください。
callback_id = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# Durable 実行に callback 結果を送信
response = lambda_client.send_durable_execution_callback_success(
CallbackId=callback_id,
Result=json.dumps({
"bucket": bucket,
"key": key
})
)
return {"status": "callback_sent", "callback_id": callback_id}
※send_durable_execution_callback_successは、2025/12/10時点の話ですがLambdaから単にデフォルトのboto3をimportするだけではバージョンが古いため動きません。
最新のboto3のバージョンを取ってくる必要があります。
実演の流れ
- メイン関数を実行
- callback_idを取得し、S3イベント用のソースコードに反映
- S3にテキストファイルを格納
- メイン関数の実行が再開され、処理が完了していることを確認
実演
1. メイン関数を実行
Lamdaのコンソール画面上からテスト実行を行います。
以下、イベントJSONの参考
{
"executionId": "hello-world"
}
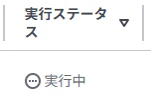
実行後、下記の「永続実行」のタブから実行状況を確認する。

実行が上手く行えていれば、以下のように実行ステータスが「実行中」になっています。
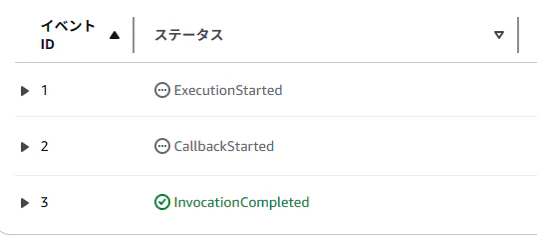
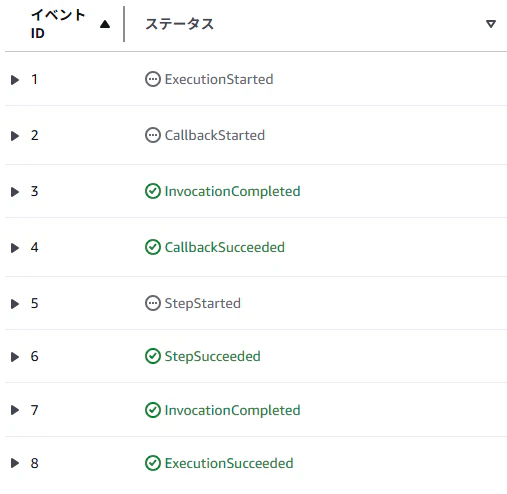
また、対象の実行名の部分をクリックすると詳細画面が表示され以下のような実行フローが確認できるかと思います。
2. callback_idを取得し、S3イベント用のソースコードに反映
CloudWatchの対象の実行ログから以下のようなログが出ているかと思うので
そこからcallback_idをコピーしてください。
{
"timestamp": "yyyy-mm-ddThh:MM:ssZ",
"level": "INFO",
"message": "callback_id: 【この部分をコピー】",
"logger": "root",
"requestId": "xxxxxx-xxx-xx-xxxx",
"executionArn": "arn:aws:~"
}
また、CloudWatchから対象のLambdaの実行ログを確認いただければ完了もせず途中でログがとまっていることが確認できるかと思います。
3. S3にテキストファイルを格納
先程、コピーしたcallback_idをS3イベント用のLambdaの対象の場所にコピーを行いデプロイのうえS3バケットにテキストファイルを格納します。
以下、実際に使用したテキストファイルの中身になります。
World!
4. メイン関数の実行が再開され、処理が完了していることを確認
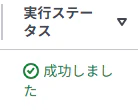
ファイル格納後、再びメイン関数を確認いただくと以下のような成功ログが出力されます。

実行ステータスは1で確認した実行ステータスも「成功しました」に変更されます。
また、1で確認した実行フローに関しても、S3に格納されたことをトリガーにフローが先に進められていたことが確認できます。
まとめ
- チェックポイントを作成し、処理を中断できる。
- ユーザーのアクションなどをトリガーに中断した処理の再開ができる。
- 待機は最大1年待機できる。
- 待機中のコンピューティングコストは発生しない。
チェックポイントなどはロジックに落とし込む部分があるため他のサービスを使用しながらフロー状況の管理となるとStepfunctionsの方が見やすいのかと個人的には感じました。
いかがでしたでしょうか、デモでは途中で処理を中断しユーザーの行動(S3へのファイル格納)をトリガーにして処理を途中から再開することを行いました。
チェックポイント/リプレイの機能イメージやどういった場面で実用できるかのイメージの助けとなれば幸いです。
参考
- https://aws.amazon.com/jp/blogs/aws/build-multi-step-applications-and-ai-workflows-with-aws-lambda-durable-functions/
- https://aws.amazon.com/jp/about-aws/whats-new/2025/12/lambda-durable-multi-step-applications-ai-workflows/
- https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/durable-execution-sdk.html
- https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/durable-functions.html
- https://dev.classmethod.jp/articles/aws-lambda-durable-functions-awsreinvent