はじめに
一週間ほど前にJupyterじゃなくてJupyterLabを勧めるN個の理由という記事を書きました。全然話は変わりますが、AWSの新製品発表会のre:InventというイベントでSageMaker Studioという製品が発表されました。AWSで今まで存在していたSageMakerのサービスを1つの画面で管理できることができるようです。今まで自分のローカル環境かGoogle Colaboratoryでしか機械学習をしたことのない僕ですが、このSageMaker Studioを試して見たいと思います。
使ってみる
使ってみます。SegeMaker Studioは現在preview releaseとなっており、近所の東京リージョンでは使用できません。使用できるのはオハイオ(us-east-2)のみになっています。
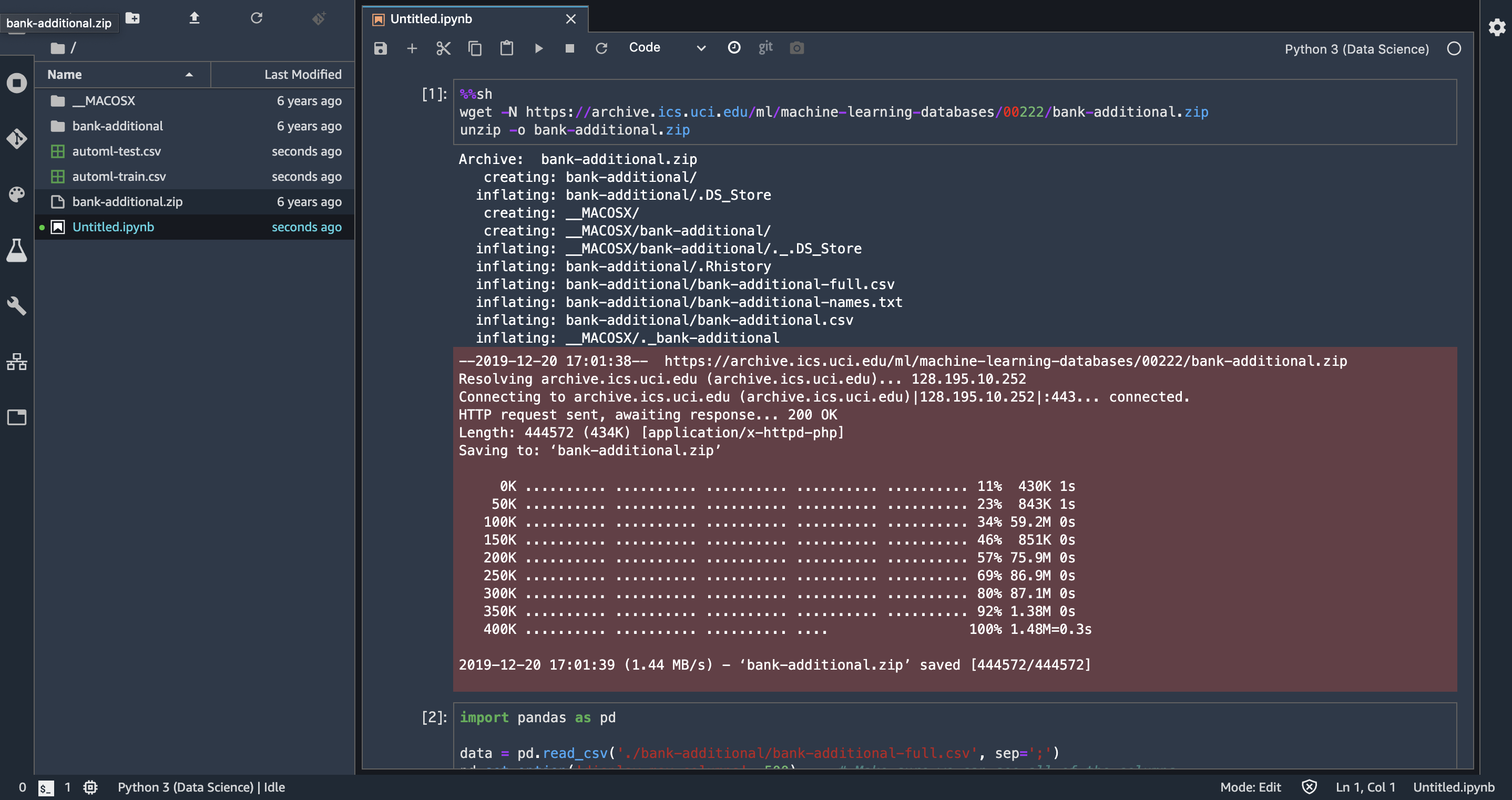
普通のJupyterLabって感じです。ショートカット等は僕の使う範囲(セルの移動、モード切り替え程度)では普通に使えます。
せっかくなのでSageMakerのサービスの1つであるSageMaker Autopilotを使ってみます。
SageMaker Autopilotについて
公式によるとSageMaker Autopilotは以下のように説明されています。
Amazon SageMaker Autopilot は、完全な制御と可視性を維持しながら、データに基づいて分類または回帰用の最適な機械学習モデルを自動的にトレーニングおよび調整します。
AutoML的なモノっぽいです。AutoMLにプラスして自動でデプロイしてくれたりするいいやつです。
僕はすぐに分析したいデータが手元にないので以下の動画を参考に試してみます。
使用するデータはUCIの配布しているデータで、銀行の顧客データと定期預金を申し込んだかどうかのデータセットです。
データのインポート
%%sh
wget -N https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip
unzip -o bank-additional.zip
データのインポート、表示
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv', sep=';')
pd.set_option('display.max_columns', 500) # Make sure we can see all of the columns
pd.set_option('display.max_rows', 50) # Keep the output on one page
data.head(10)
今回のデータは正解ラベルがyes, noの二値になっています。それぞれの数を数えてみます
data["y"].value_counts()
no 36548
yes 4640
不均衡ですね(小並感)。分析は今回の趣旨ではないので飛ばします。
この調整するところから面倒なデータもAutopilotがなんとかしてくれるみたいです。
とりあえず、trainとtestに分割して保存しておきます。
import numpy as np
train_data, test_data, _ = np.split(data.sample(frac=1, random_state=123),
[int(0.95 * len(data)), int(len(data))])
# Save to CSV files
train_data.to_csv('automl-train.csv', index=False, header=True, sep=',') # Need to keep column names
test_data.to_csv('automl-test.csv', index=False, header=True, sep=',')
import sagemaker
prefix = 'sagemaker/DEMO-automl-dm/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="automl-train.csv", key_prefix=prefix)
print(uri)
Autopilot Experimentの作成
SageMaker StudioからAutopilot Expreimentを作成します
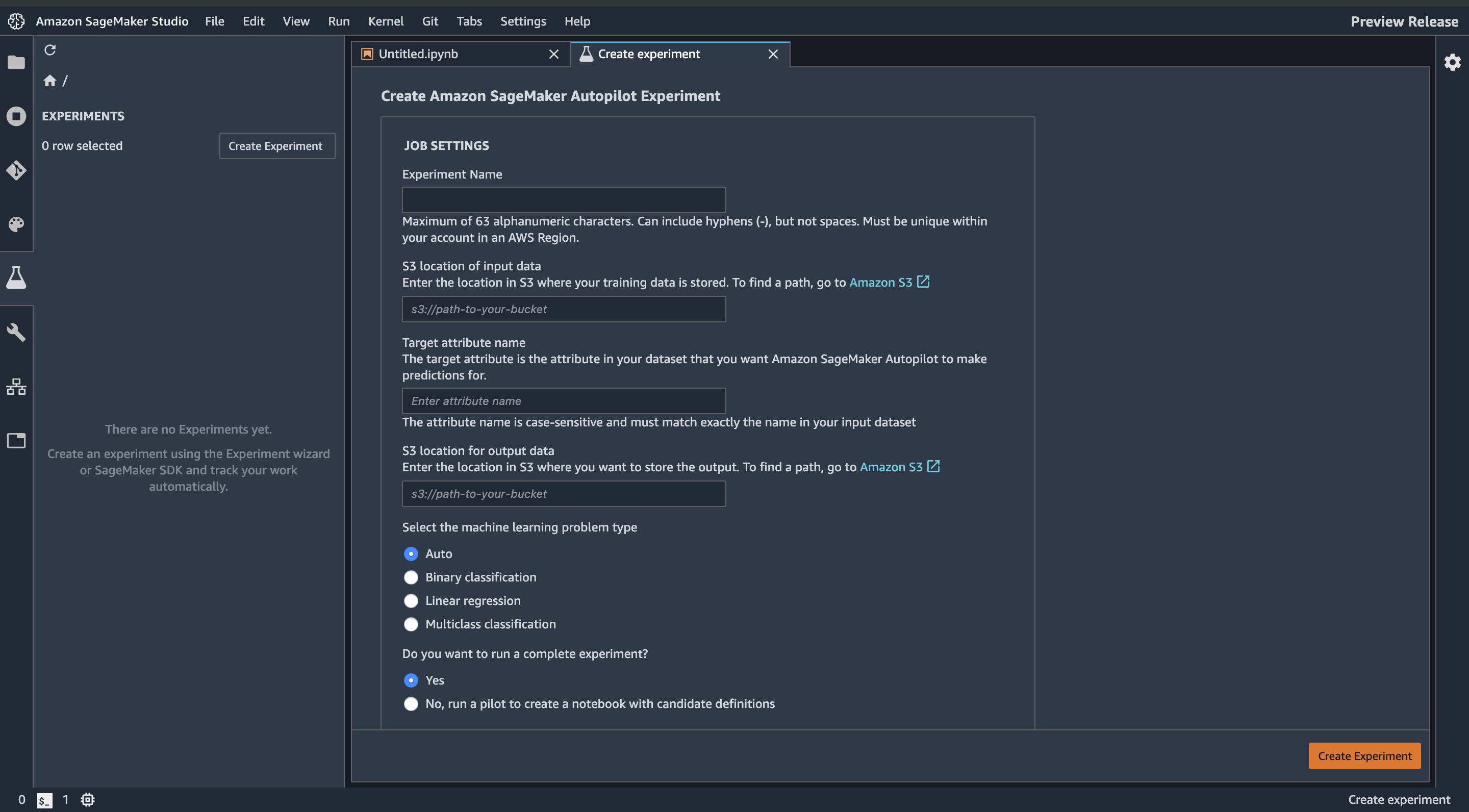
項目を埋めます。最後の項目は、Noを選択するとSageMakerが自動で生成してくれたモデルを試せるnotebookを作成してくれるようです。
Create Experimentを押すと自動でモデルの構築が始まります。
プロセスは大きく分けて3つの処理をしてくれます
- データの分析
- 特徴量エンジニアリング
- モデルのチューニング
結果をみた感じ、もう僕がやらずに機械に任せた方がいいのではって感じでした。技術の進歩すごい。
処理がまだ終わってないのですが、すごく眠いので今回はここまでにします。s
不安な点
AWSに限らずにクラウドサービス全般に言えることですが、料金体系がとてもわかりづらいです。今回のSageMaker Studioもいくらモデルの作成にかかるのかがよくわかりませんでした…
僕がボケてたとはいえ、GCPでDataProc使った時にクラスタ消し忘れて7000円吹き飛んだ恨みは消えてないぞ…
まとめ
日本語のやってみた記事が少なかったのでやってみました。
AutoMLなめてたっていうのが正直な感想です。ただ、SageMakerの機能を統合できるという側面が強いので、SageMakerの機能をフルで使い人にはおすすめだけど単にJupyterみたいな環境が欲しい人にはどうかな?って感じでした。