はじめに
こんにちは。この記事は、MYJLabアドベントカレンダー16日目です。
2日連続なので息切れ気味ですが、はりきって僕の推しツールを布教したいと思います。
前回の記事では分析環境であるJupyterLabの紹介をしました。本当にいいツールなのでぜひ使ってください。今日は分析に入る前の段階、データ収集で使うツールについて紹介をします。
スクレイピング・クローリングについて
皆さんは、機械学習などでデータを収集する時にどのような手段でデータを収集してくるでしょうか? 個人で開発しているとデータを買うわけにもいかず、かといって自分で一からデータを作ることもできません。僕の場合は、データに困ったらとりあえずスクレイピングするようにしています。
スクレイピングとは、Webページ上から必要な情報を抽出する技術のことです。類似の技術にクローリングがありますが、人によってスクレイピングとクローリングの差はまちまちです。本記事では、以下のように分類します。
- クローリング: リンクを辿ってWebページにアクセスする技術
- スクレイピング: Webページから必要な情報を抜き出す技術
通常、抜き出したい情報が1つのWebページで完結することはないので、クローリングとスクレイピングは一緒に行うことがほとんどです。例えば、マルコフ連鎖で嘘ニュースを作るためにYahooニュースのデータを収集したいとします。
Yahooニュースのページは主に2つのページに分類できます。
- ニュース記事を一覧表示するページ
- ニュースの詳細を表示するページ
全てのニュースを収集したい場合は、以下のような処理をします。
- ニュース記事の一覧表示ページを取得
- 一覧表示ページからニュース詳細を表示するページのリンクを取得
- 2で取得したリンクにアクセス
- 必要な情報を取得する
- 2〜4を繰り返す
この処理を行うことで欲しいニュースの情報を取得することができます。しかし、これらの作業をコードにすると雑魚エンジニアの僕は中々に可読性の低いコードを生み出してしまいます。しかも、クローリングで意識しなければいけないことはこれだけではありません。
- リクエスト失敗時に時間をあけてリトライを行う
- robots.txtで決められているスクレイピングしてはいけないページを避ける
- 取得した情報をデータベースやAWS s3に保存する
- 取得した画像はリサイズしてから保存したい
- サーバに負荷をかけないように時間を空ける
- でもドメインが違うなら同時リクエストしたい
- JavaScriptをレンダリングしてからスクレイピングしたい
- その他多数
これらのことを意識しながらコードが綺麗に書けるほど僕はできたエンジニアではありません。
しかし、こんな悩みはScrapyがあれば簡単に解決します。
Scrapyについて
Scrapyとは、Pythonでウェブクローリングとウェブスクレイピングをするためのフレームワークです。監視から自動テストまで行えるすごいやつです。
上で挙げたようなクローリング・スクレイピングのめんどくさい処理を勝手にやってくれます。さらにスクレイピングするためのコードの雛形も自動で作ってくれるので、統一感のある(?)コードを書くことができます。
Scrapyの仕組み
正直、Scrapyの使い方はTutorialを見てもらうのが一番早いので、割愛します。ここでは、個人的に分かりづらかったScrapyの仕組みについて頑張って説明したいと思います。
Scrapyは以下のような仕組みで動いています。
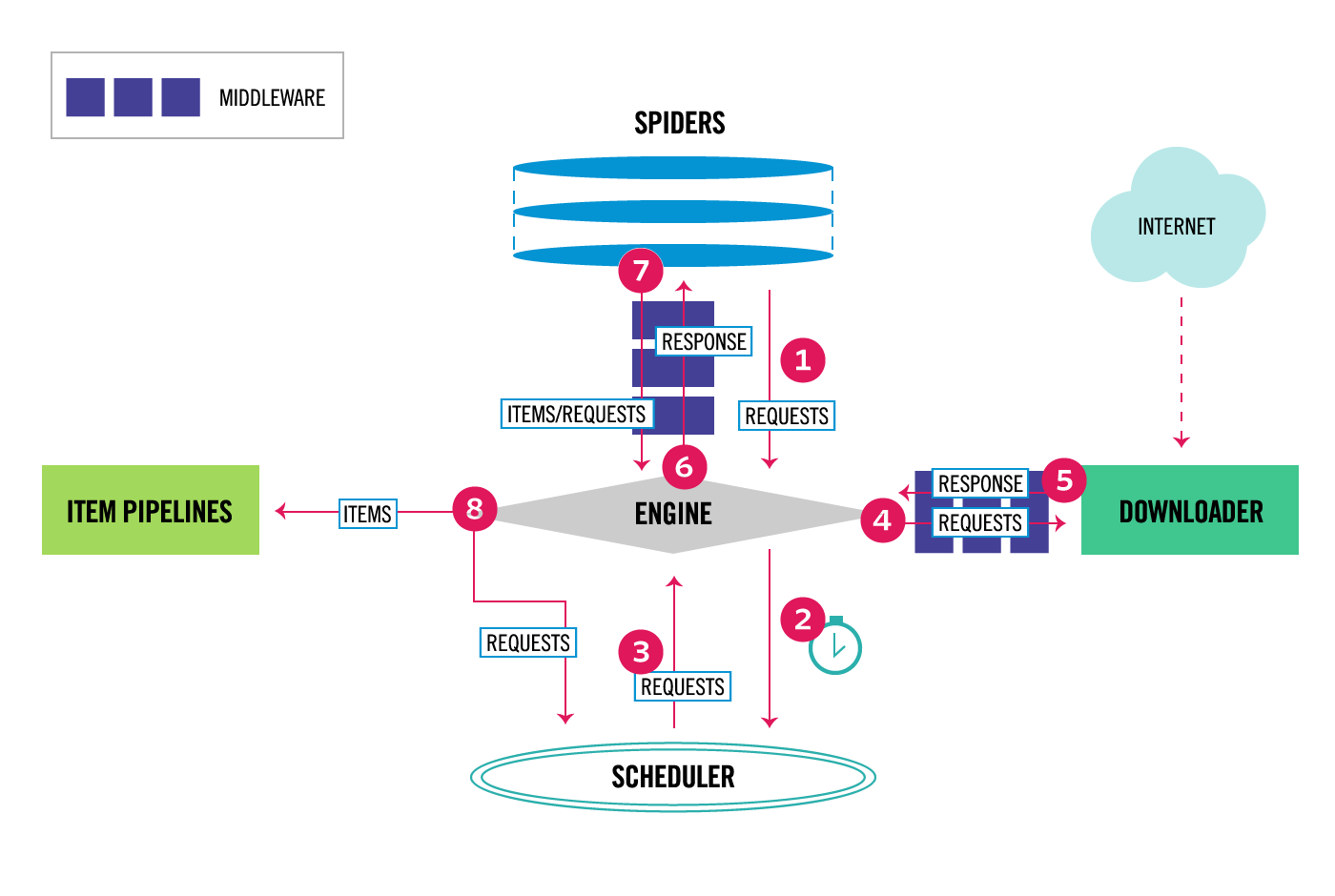
この図だと少し分かりづらいと思うので頑張って説明します。
Scrapyは主に6つのパーツから成り立っています。
Engine
Engineは、Scrapyのデータの流れを制御する役割を担っています。Scrapyはイベントドリブンなネットワークプログラミングフレームワークであるtwistedで書かれています。engineは特定のアクションが発生した時にイベントをトリガーします。
Scheduler
Schedulerは、エンジンから受け取ったリクエストをためていおいてタイミングをコントールするパーツです。上の図では、②③⑧がschedulerの仕事になります。
Downloader
Downloaderの仕事は、Webページを取得し、それをEngineを通じてSpiderに渡すことです。Webサイトへのアクセスは必ずこのDownloaderを通じて行われます。
Spider
Spiderは、開発者が主に手を加えるパーツで、要素の抽出や保存などを行います。ScrapyはItemという単位でデータを管理していて、SpiderのなかでItemオブジェクトを返せばデータの保存が始まり、Requestオブジェクトを返せば再度クローリングをします。
Item pipeline
Item pipelineは、Spiderで抽出されたアイテムを処理する役割を担っています。アイテムをMySQLに保存したり、クレンジングするのはItem pipelineの役割です。
Middleware
Middlewareは、各パーツ間でのやりとりの間に位置しているパーツです(上の図では紺色のパーツ)。Middlewareは、Download MiddlewareとSpider Middlewareの二種類があり、それぞれで役割が違います。
終わりに
まとまりのない記事になってしまいましたが、Scrapyをなんとなく感じていただけたら幸いです。他にもScrapyには便利な機能がたくさんあるので、興味をもったら是非調べてみてください。