きっかけ
私はちょっとした趣味としてこんな風にアナログ絵を描くことがあるんですが、
コピックなどの色を塗る道具を持っていなくて色塗りが出来ないので、
どうにか色をつけたいなーと思ったので線画の着色をするやつを作ってみました。
この子に色をつけたい!!

環境
Mac OS Monterey ver12.4
python: 3.7,7
PyTorch: 1.12.0
学習用データ
アニメのカラー画像を集めてそこから線画を抽出する方法にしました。
そのアニメの画像はkaggleのデータセットから集めました。(実際使ったのはその内の2万枚)
使用したデータセット
線画の抽出
まずは線画の抽出から
方法はこちらのブログを参考にしました
se = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (6, 6))
bg = cv2.morphologyEx(img, cv2.MORPH_DILATE, se)
result = cv2.divide(img, bg, scale=255)
この方法だとこんな風に綺麗に線画を取れるんですが


背景が真っ黒だったり暗めのイラストだったりすると


ノイズが入っちゃうので注意が必要です
ヒントの付与
今回はどこをどんな風に塗るかあらかじめこちらで指定できるように線画とは別に、ヒントとして黒背景で様々な長さや太さ方向のヒントとなる線をたくさん引いたこのような画像をモデルに与えます。
ヒントなしで学習させても色を塗ってくれることには塗ってくれるのですが、こんな風に髪の色がでたらめになったり、髪が黒以外の色で塗られなかったりすることがあったのでヒントを与えることにしました。

モデル
ネットワークの形は、GeneratorにUnet、DiscriminatorにPatchGANを用いたものを使用しました。基本構造はPix2Pixと全く同じです。
今回はどこをどんな色で塗るかの指示を与えるためにU-netの入力を線画とヒント画像を結合したものを与えるため4チャンネル、PatchGANにはカラー画像と線画を結合したものを与えるために4チャンネルにしています。
(コードは長くなるので記事の最後に載せています)
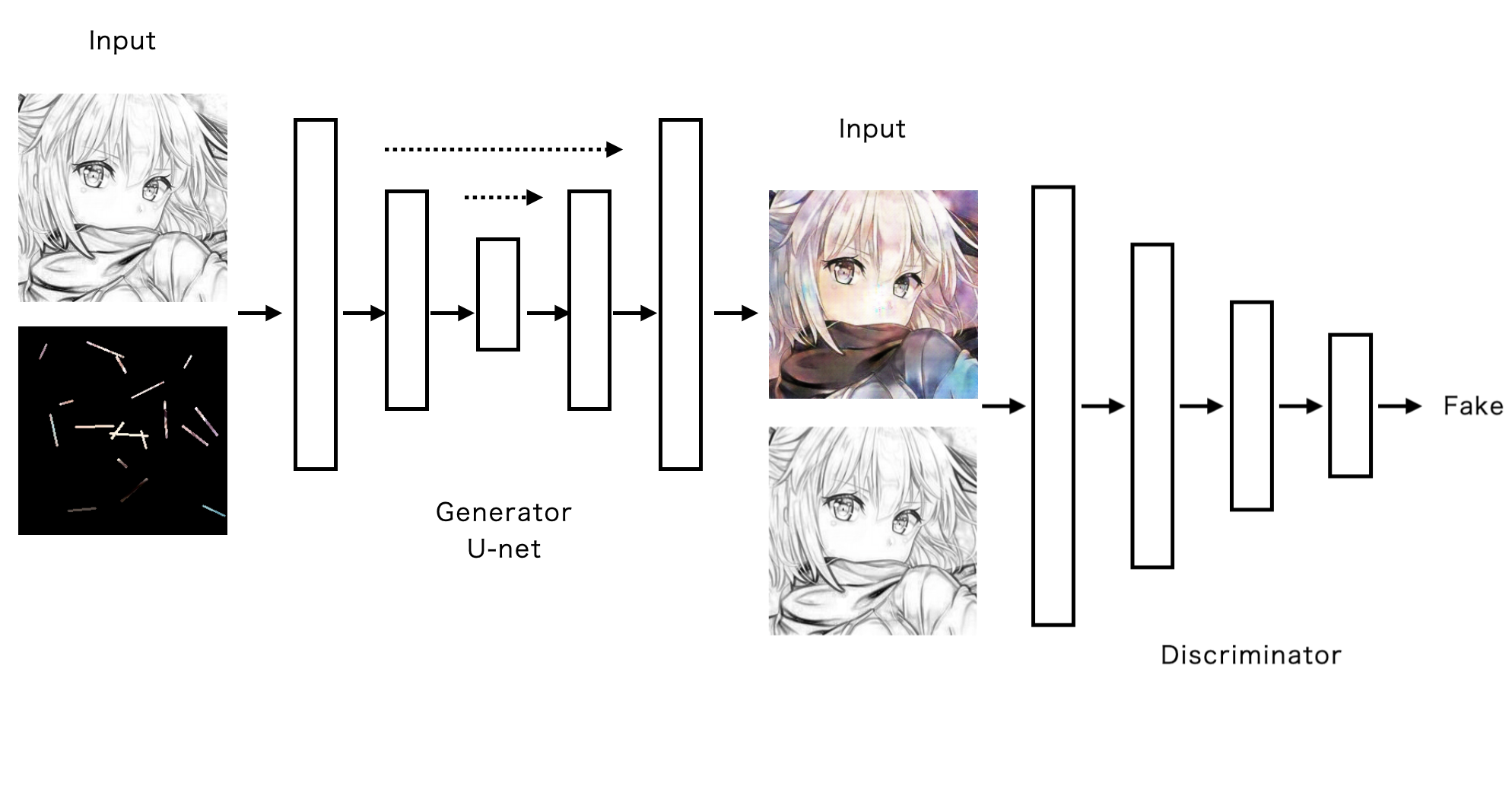
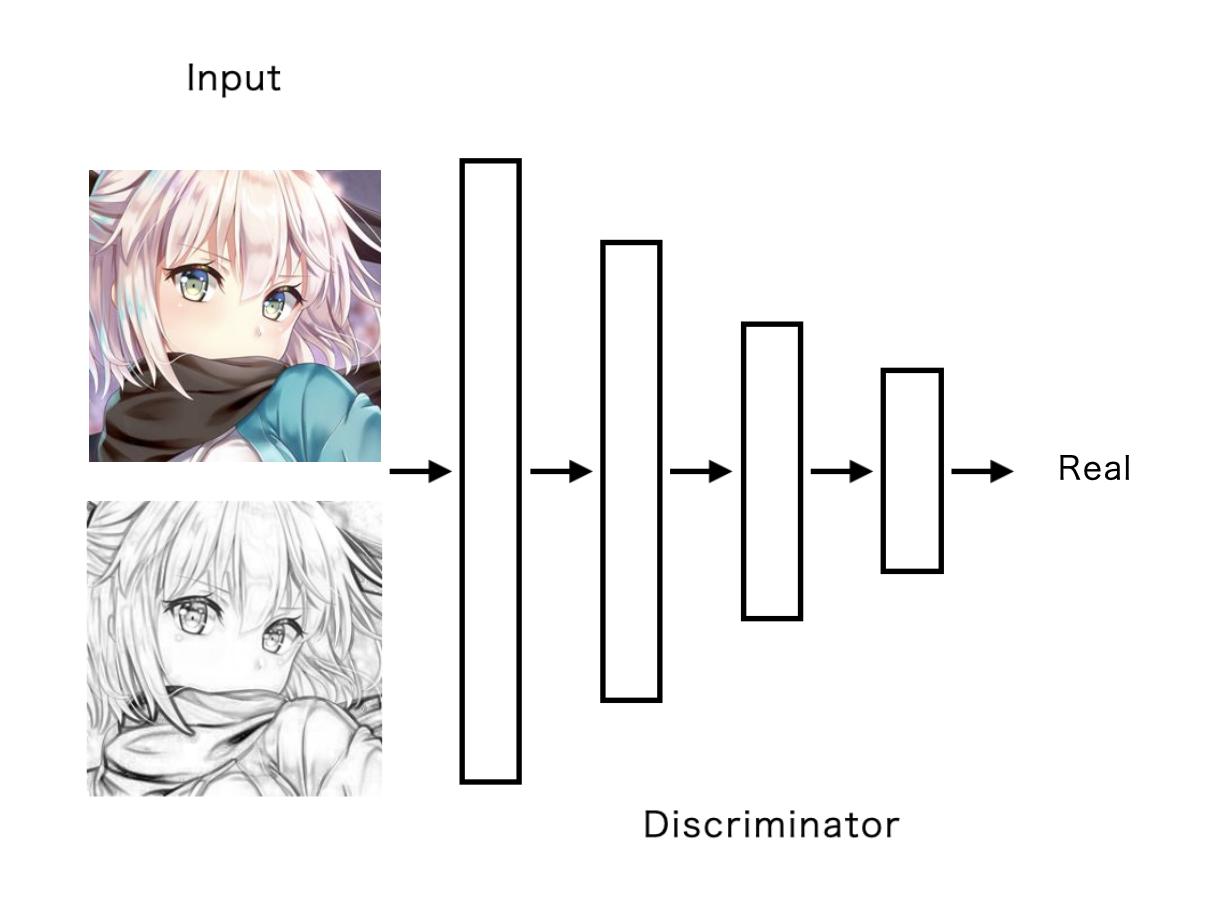
損失関数
Discriminator Loss
Discriminatorにはそれぞれ線画と本物画像、線画と偽物画像を結合したものを与えます。そしてそれぞれの出力に対してLossを計算し、その合計をDiscriminator Lossとします。(偽物画像はGeneratorが出力したものです)
ここでの損失関数は HingeLoss を使用しています。
コード上では以下のように記述しています。
d_loss = real_loss + fake_loss #real_lossは本物画像と線画をDiscriminatorに与え損失を計算したもの、fake_lossは偽物画像と線画をDiscriminatorに与え損失を計算したものです。
Generator Loss
Generator Lossは、より本物画像に近づけるために本物画像と偽物画像の差で損失を計算しそれに100を掛けたものとfake_lossの合計をGenerator Lossとします。
本物と偽物の誤差を求めるのには平均二乗絶対誤差を使用しています。
コード上では以下のように記述しています。
g_loss= fake_loss+loss_real_L1*100 #loss_real_L1で本物と偽物の誤差を求めています。
学習手順
学習はGenerator→Discriminatorの順番で行いました。
Generator
1.線画とヒントを結合したものをGeneratorに入力として与える
2.偽物画像と線画を結合したものをDiscriminatorに与え誤差を計算
3.偽物画像と本物画像から誤差を計算
4.2と3を足しそれをもとに逆伝搬、パラメータ更新
Discriminator
1.偽物画像と線画を結合したものをDiscriminatorに与え誤差を計算
2.本物画像と線画を結合したものをDiscriminatorに与え誤差を計算
3.1と2を足しそれをもとに逆伝搬、パラメータ更新
Generatorの学習の際、lossの計算に使うラベルは偽物ではなく本物のラベルを使うのがポイントです。なぜかというとこの記事でも述べられているように、Generatorの学習の際は本来の正解ラベルと逆の物を使うことで損失がより小さくなる方向に進むことになるからですね。
今回はbatch_sizeは1で30エポック学習させました。
import torchvision
from torch.utils.tensorboard import SummaryWriter
epoch = 30
writer = SummaryWriter("./log") #logを保存するディレクトリを指定
batch_size = 1
sum_ = 0 #合計で何バッチ進んだか
for i in range(30):
num_batch = 0 #1エポックの中で何バッチ進んだか
for color, line , hint in zip(dataloader_color,dataloader_line,dataloader_hint):
ones = torch.ones((8,1,16,16)) #正解ラベル
zeros = torch.zeros((8,1,16,16)) #偽物ラベル
batch_len = len(color)
#・-----------------・#
# Generatorの学習 #
#・-----------------・#
opt_Unet.zero_grad()
#偽物画像の生成
fake_imgs = unet(torch.cat((hint,line),1))
#誤差を計算
dis_fake=dis(torch.cat((fake_imgs,line),1))
loss_from_fake = hgenloss(dis_fake,ones[:batch_len])
loss_real_L1 = L1loss(fake_imgs,color)
#合計してGeneratorの誤差とする
Gloss= loss_from_fake+loss_real_L1*100
#逆伝搬して、パラメータの更新
Gloss.backward()
opt_Unet.step()
#・-------------------------・#
# Discriminatorの学習 #
#・-------------------------・#
opt_Dis.zero_grad()
#誤差を計算
dis_real = dis(torch.cat((color,line),1))
real_loss =hdisloss_real(dis_real,ones[:batch_len])
dis_fake = dis(torch.cat((fake_imgs.detach(),line),1))
fake_loss =hdisloss_fake(dis_fake,zeros[:batch_len])
#合計してDiscriminatorの誤差とする
d_loss = real_loss + fake_loss
#逆伝搬して、パラメータの更新
d_loss.backward()
opt_Dis.step()
#ターミナルにパラメータなどを表示
print(f"[Epoch {i}/{epoch}] [Batch {num_batch }/{ len(dataloader_line)}] [D loss: {d_loss.item()}] [G loss: {loss_from_fake.item()}]")
#tensorboardで誤差をグラフとして可視化
writer.add_scalar("D loss", d_loss.item(),sum_)
writer.add_scalar("G loss", loss_from_fake.item(),sum_)
実際に使ってみよう
外付けGPUとかそんな高価なものは持っていないのでノパソのCPUに丸二晩学習してもらいました。
その結果がこちら
入力

出力

おおーいい感じ
そして、こんな風にちゃんと色変もできる

ヒントの与え方次第でいろんな色に塗り分ける事も

かわいい
さて最後にこの子を塗ってみましょう


さて結果は...

ああー
鉛筆で書いた色が薄い線画だと綺麗に塗れないのかな...
今後の課題ですね...
最後に
ここまで見てくれてありがとうございます。今後は学習の際に用いる線画の種類を増やしたり、色が線画から溢れたりしないように工夫していきたいですね。鉛筆で書いた線画でも綺麗に塗れるようにがんばるます。
コード全体は後日githubに投稿予定です。
最後に、GeneratorとDiscriminatorのコードを載せておきます。
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 4, 2, 1, bias=False)]
if normalize:
layers.append(nn.InstanceNorm2d(out_size))
layers.append(nn.LeakyReLU(0.2))
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),
nn.InstanceNorm2d(out_size),
nn.ReLU(inplace=True),
]
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x, skip_input):
x = self.model(x)
x = torch.cat((x, skip_input), 1)
return x
class GeneratorUNet(nn.Module):
def __init__(self, in_channels=4, out_channels=3):
super(GeneratorUNet, self).__init__()
self.down1 = UNetDown(in_channels, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256)
self.down4 = UNetDown(256, 512, dropout=0.5)
self.down5 = UNetDown(512, 512, dropout=0.5)
self.down6 = UNetDown(512, 512, dropout=0.5)
self.down7 = UNetDown(512, 512, dropout=0.5)
self.down8 = UNetDown(512, 512, normalize=False, dropout=0.5)
self.up1 = UNetUp(512, 512, dropout=0.5)
self.up2 = UNetUp(1024, 512, dropout=0.5)
self.up3 = UNetUp(1024, 512, dropout=0.5)
self.up4 = UNetUp(1024, 512, dropout=0.5)
self.up5 = UNetUp(1024, 256)
self.up6 = UNetUp(512, 128)
self.up7 = UNetUp(256, 64)
self.final = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(128, out_channels, 4, padding=1),
nn.Tanh()
)
def forward(self, x):
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
d7 = self.down7(d6)
d8 = self.down8(d7)
u1 = self.up1(d8, d7)
u2 = self.up2(u1, d6)
u3 = self.up3(u2, d5)
u4 = self.up4(u3, d4)
u5 = self.up5(u4, d3)
u6 = self.up6(u5, d2)
u7 = self.up7(u6, d1)
return self.final(u7)
class Discriminator(nn.Module):
def __init__(self, in_channels=4):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalization=True):
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalization:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(in_channels, 64, normalization=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1, bias=False)
)
def forward(self, x):
return self.model(x)