はじめに
Splunkは分散サーチ機能によりサーバー数を増やしたり、IO速度の早いflashなどを使ったりすればサーチ速度も上がりますが、そのようなアーキテクチャを変更せずに簡単に高速化するにはどうすればいいでしょうか?
今回は、高速化の方法の1つである savedsearch & loadjob を使った方法をご紹介します。
検索の高速化には他にどんな方法があるの?
ちなみに今回ご紹介する方法も含めて、アーキテクチャの変更なく高速化させる方法はどんなものがあるのでしょうか?私が知る限りですが以下のようなものがあります。
-
サーチコマンドを見直す
サーチコマンドには、Indexer側で実行できる streamingコマンド(search,evalなど)と サーチヘッド側で実行する non-streamingコマンド(stats,timechartなど)に分けられます。詳しくはマニュアル参照。最初にindexer側で処理を終えて、フィルター後にサーチヘッド側で集約できるように、先にstreamingコマンドを並べるべきです。また*(アスタリスク)などは多様化せず(特に先頭の*は最悪)、最後まで書いたり、joinを使わずに、statsなどで処理する。などコツがあります。 -
DMA (データモデル高速化)
データモデル(データセット)を作成して、その対象ログのメタ情報を保存しておき、そこに対する検索により、高速化させる方法です。SplunkのプレミアムサービスAppは大体この方法を使っており、データモデルを作成しているケースはこちらの方法がお勧めです。odorusatoshiさんがDMAについて詳しい記事を書かれております -
レポート高速化
Splunkのレポート機能にある、高速化オプションです。savedsearch と近い方法ですが、個人的にはあまりお勧めしません。というのもいくつか制約があって、高速化できる処理としては transformingコマンド(例: chart, timechart,stats) で締め括られていないとダメな点。とデータの更新が10分間隔となっており、バックグラウンドでサーチが多発するためです。 -
summary index
予めデータをサマっておく方法です。例えば dailyで訪問者数や状況などを計算しておいて、サマリーindexに積み上げで保存しておくことで、月間の情報や年間の情報がこのサマリーインデックスをみればよくなります。シンプルにいうと予め計算など処理を施した結果を別のindexに保存しておき、そこを参照するから早いでしょ。という高速化。 -
savedsearch
今回ご紹介する方法です。このあと解説します。
savedsearch ?
一度サーチ実行した結果を呼び出す。という方式です。そのためレポート高速化のようなコマンド制約はありませんし、バックグラウンドで実行するタイミングや頻度も決められます。その代わり前回サーチを実行した結果を表示するため、リアルタイム表示には向いてません。(そのような場合はDMAを利用してください)
注意点としては、サーチ結果はあくまで前回サーチ実行したタイミングのもの。そしてその結果は新規ストレージ領域に保存されるため、ストレージ容量にも注意が必要です。(古いサーチ結果は自動的に削除されていきますのでご安心を)
設定方法
1. レポート作成
まずは、実行したいサーチをレポートとして保存します。サーチ実行後に右上にある「名前をつけて保存」から「レポート」を選びます。
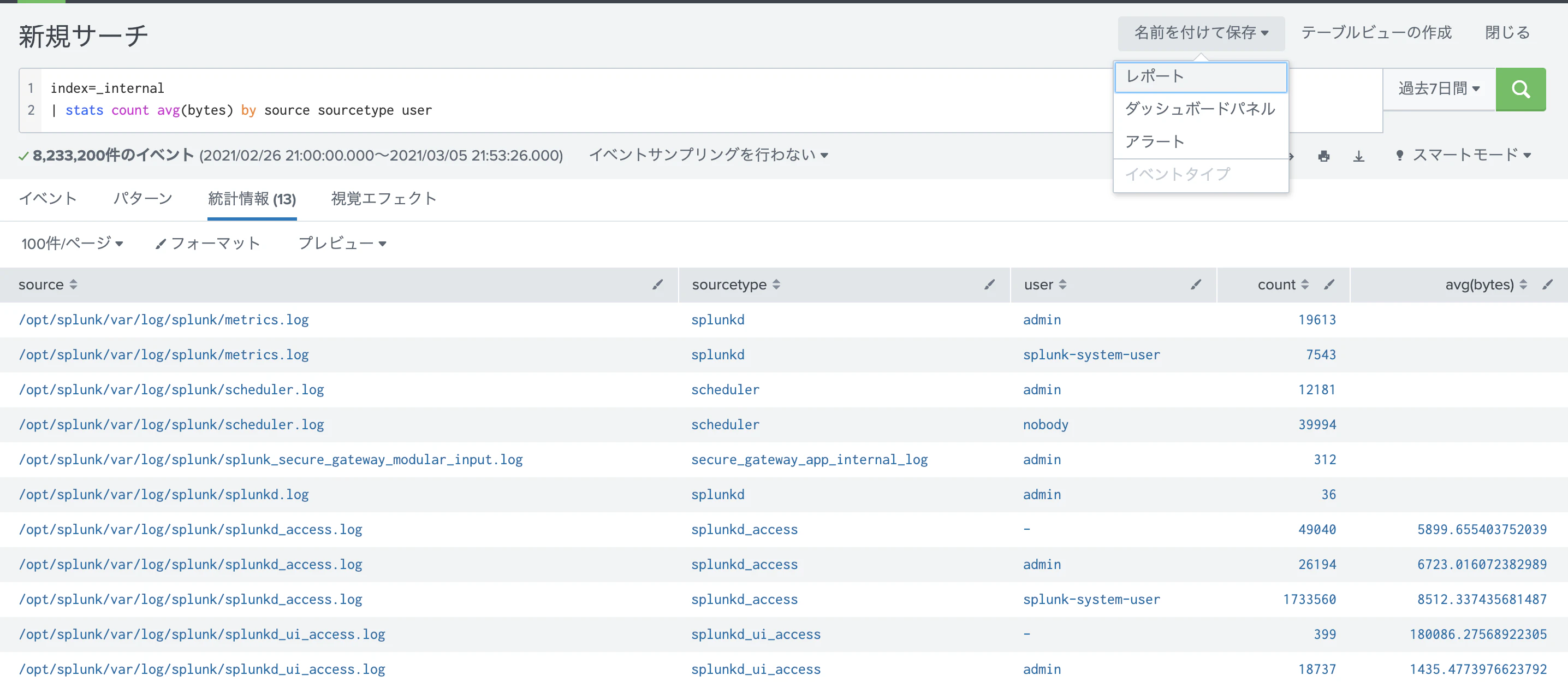
2. スケジュール設定
スケジュール設定で、実行頻度やサーチ対象範囲などを決めます。実行頻度は短くするとその分サーバー負荷があがるので要注意です。(短くしたい場合はDMAをご検討ください)
スケジュール実行されると、レポートを開いた時に以下のように結果が表示されております。ここが未実行だとsavedsearch の結果も0になります。

3. loadjob 実行
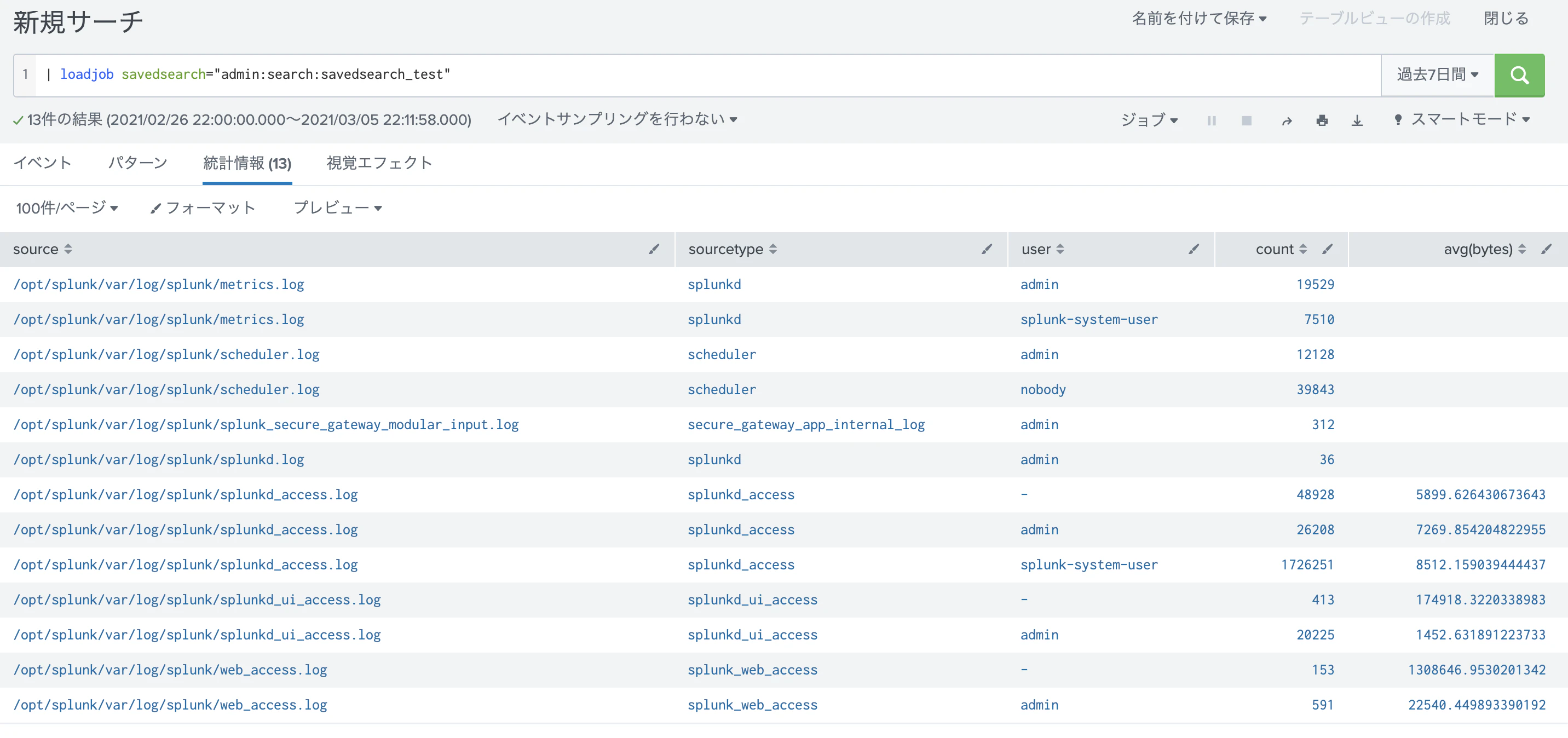
レポート結果を呼び出すにはloadjobコマンドを使います。
savedsearch オプションの中身は "<username>:<app名>:<report-name>" となります。
| loadjob savedsearch="admin:search:savedsearch_test"
どんだけ早くなった?
上のサンプル実行の結果を比較してみます。
通常実行 : 45.986 秒

savedsearch : 0.028 秒

な・な・なんと。2千倍近く(?)も早くなってます。scanning の数をみてもらうとわかると思いますが、loadjobの場合結果を読み込んでいるため、実際のデータにはアクセスしてません。(scan不要) また今回の結果は13件だけだったため、これだけ早くなるのも納得です。
さいごに
ちなみに呼び出した後は、普通にSPLが利用できます。

ダッシュボードなどを高速化させたい場合など、base_searchと組み合わせたら便利そうですね。
ただしあまり多様すると、スケジュールサーチが爆増してサーバー負荷があがるので、ご利用は計画的に。