はじめに
- これは個人の見解です。
- それでもsplunkさんのnative仕様の
意味不英語マニュアルを読み重ねて、参考資料を読み重ねてたどり着いたまとめです。 - みなさんはここからdatamodelと仲良くなるスタートにしてください。
「よし、datamodelを使って高速検索だ!!って高速化サマリ?何それ?」
- Splunkを使い倒してくると、いずれぶち当たる壁。サーチの高速化。
- そこで出てくるdatamodelさん
- datamodelという言葉の意味と機能、そしてコマンドがわかっているようで分からない。
- 同時にtstatsコマンドとpivotコマンドも絡んできて、混乱の極みへ。
- 一度、丁寧にドキュメントを読み、answerを見て、サーチを試しながら違いについて独自の見解をまとめてみました。
(結論から)整理した結果
Why思考の私にとって、**なぜ、その機能が生まれてきたのか?**を理解できるのが一番落ち着きます。機能が作られた歴史背景をたどってみて、一旦こんな感じで役割が整理できました。
とりあえずこんなときにはこれ!

datamodelとは
###まずdatamodelとは?
検索しやすくするための、データセットの固まり。それがデータモデル。
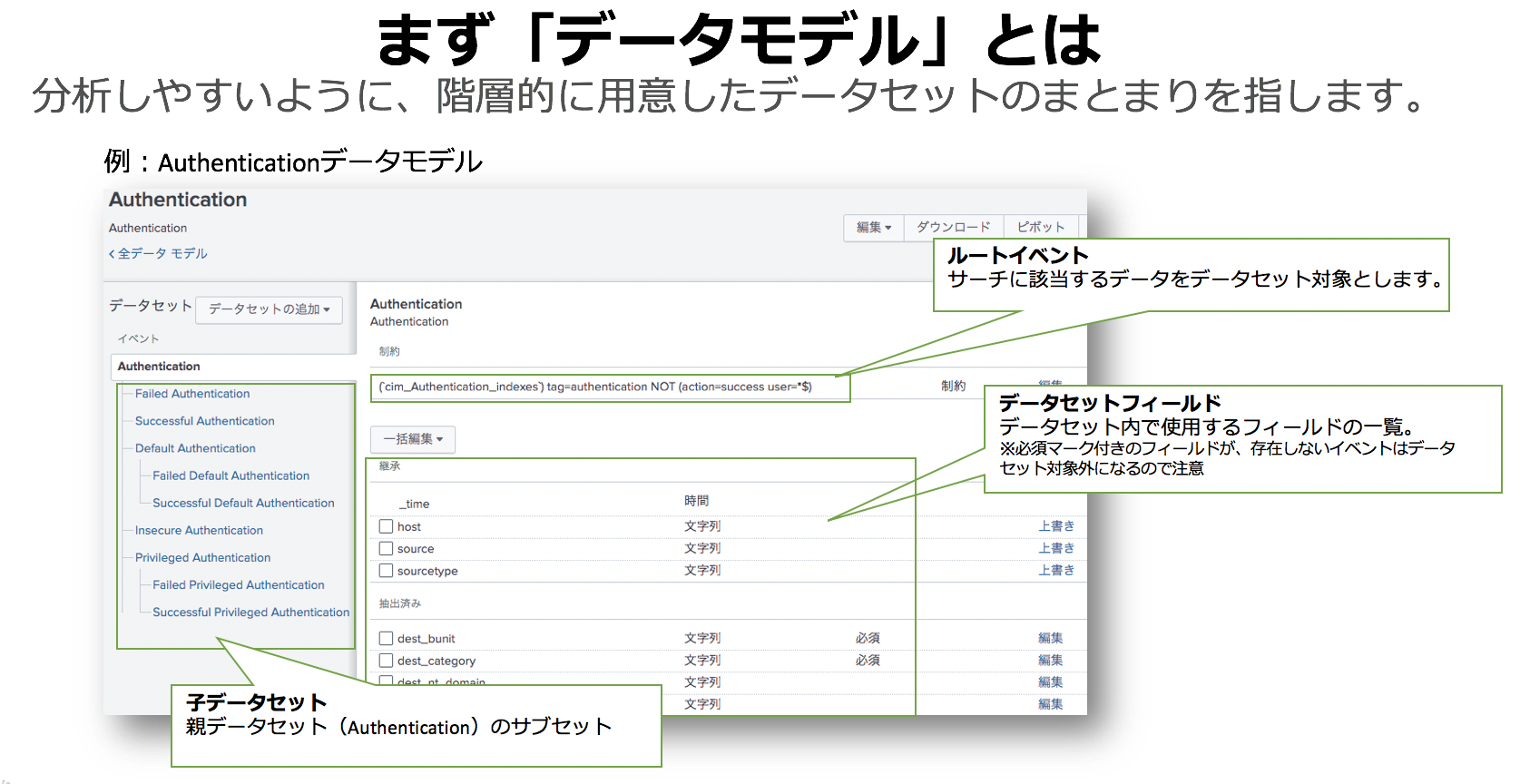
Yes, pivotコマンドはここで使われます
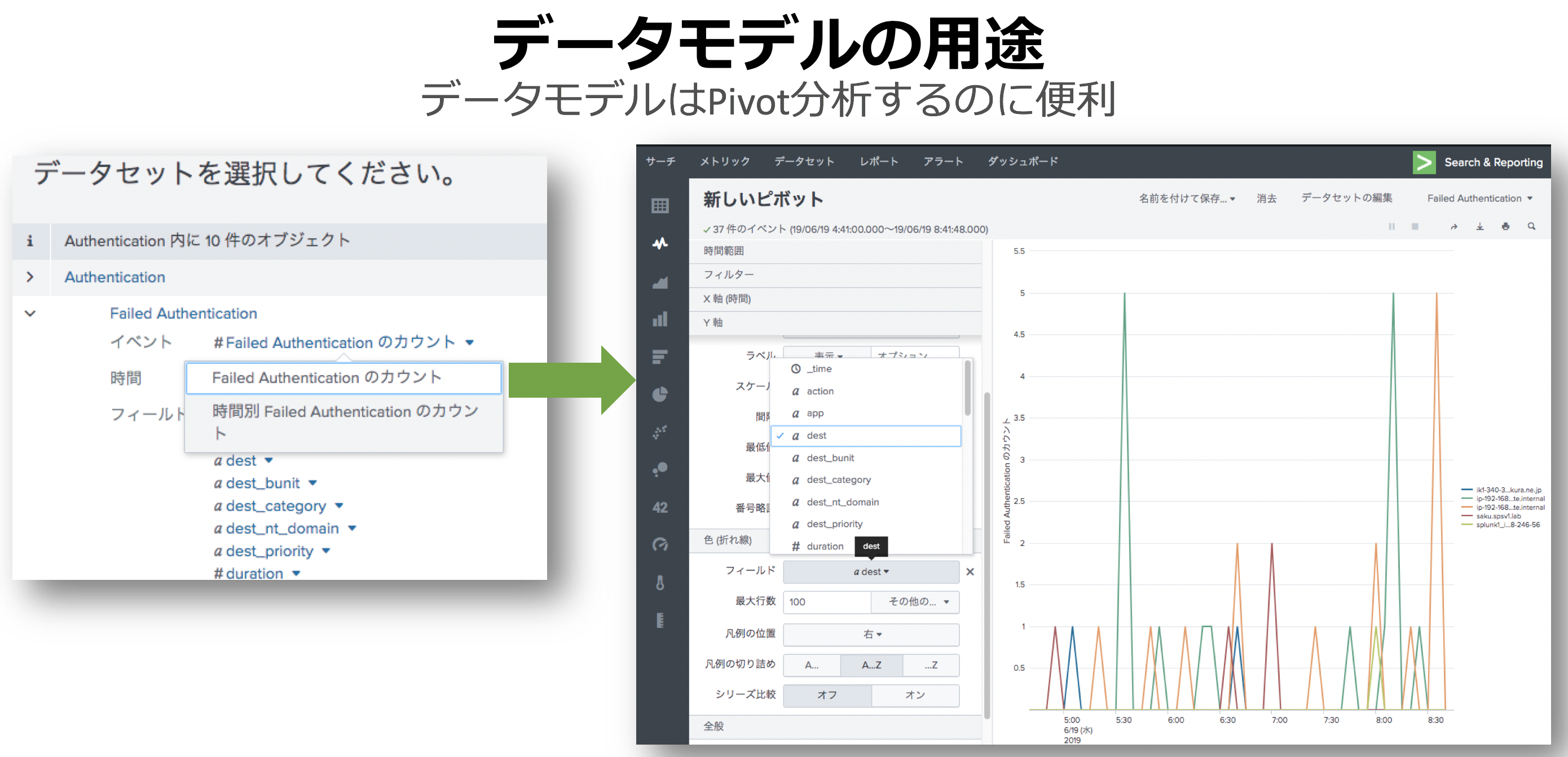
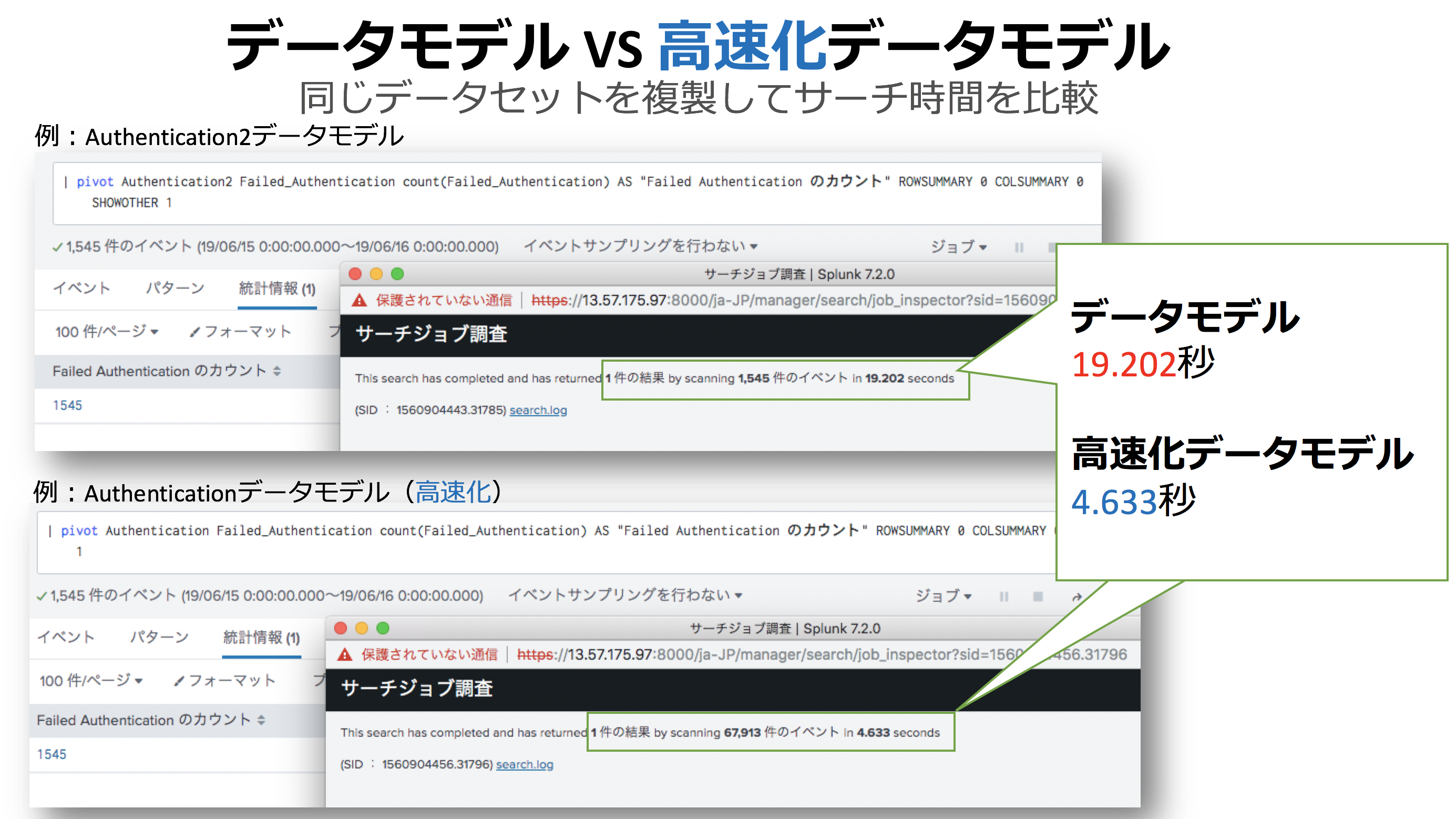
でも、イベント件数が多くなるとサーチが遅くなる。。。。
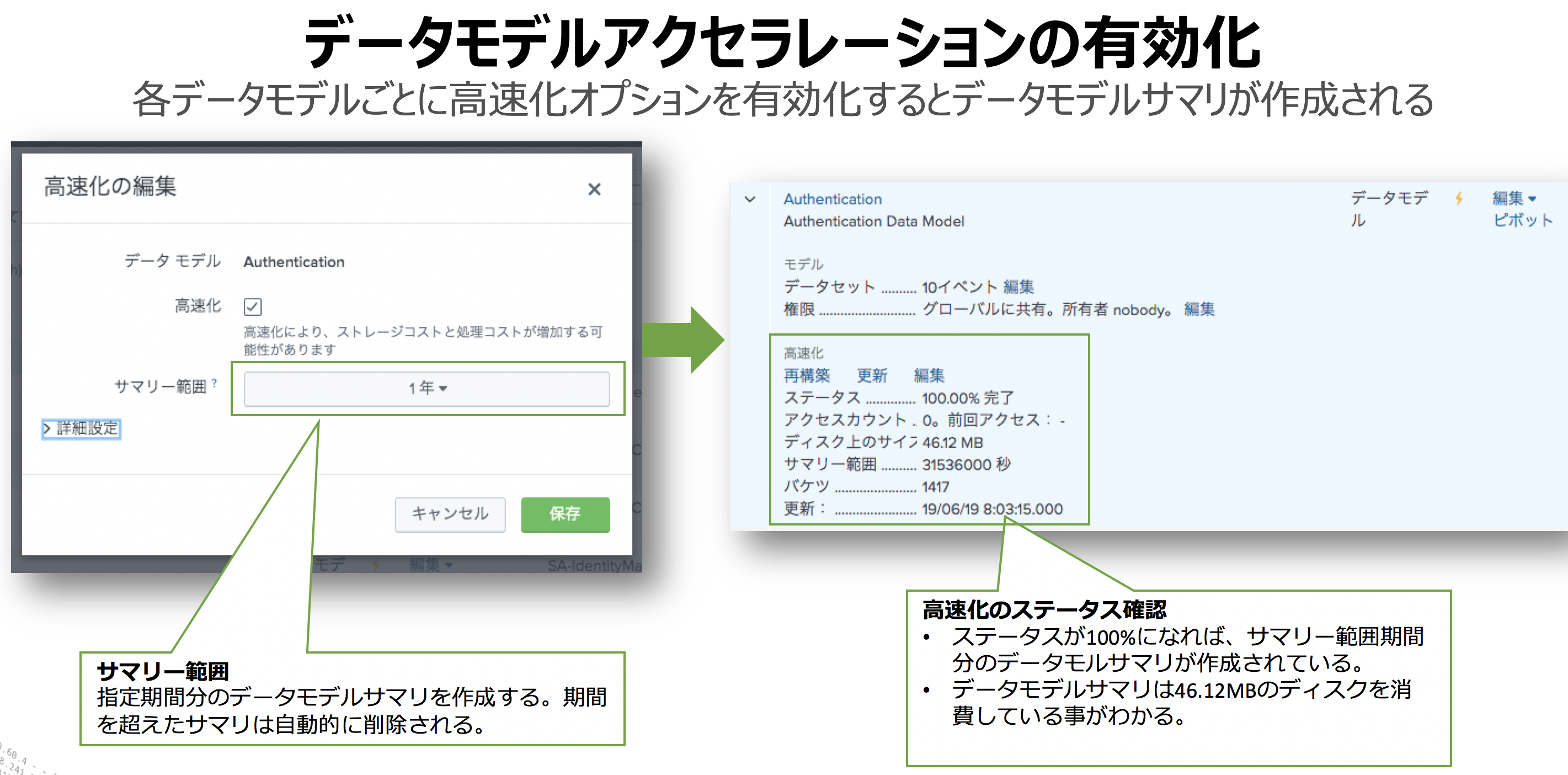
そこで!データモデルアクセラレーションの誕生!
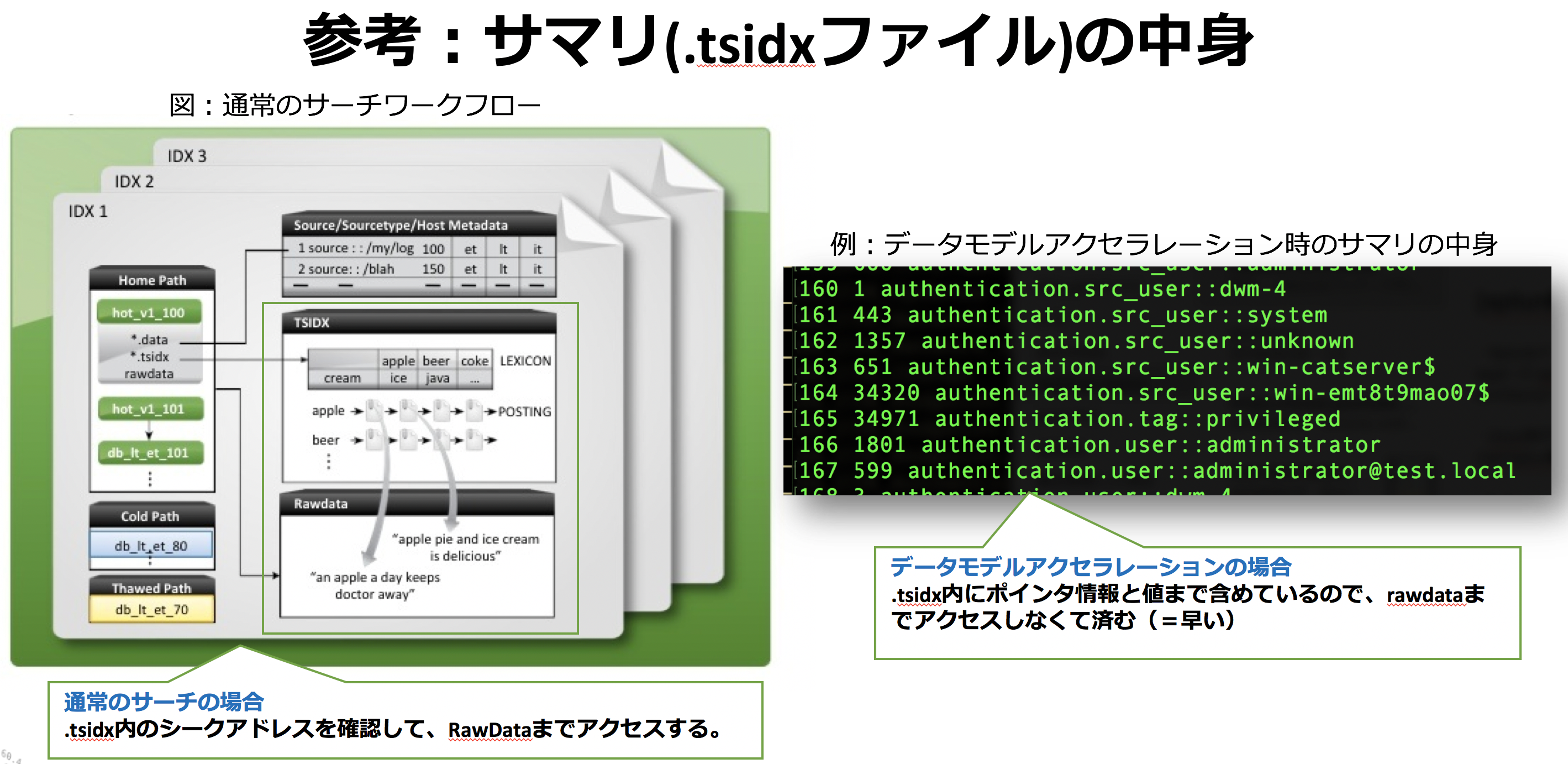
###データモデルアクセラレーション=datamodelの高速化って何?

爆速のポイントは.tsidxファイル
よし使ってみよう!CIM appをインストールして使いたいデータモデルを高速化!
「ええい!連邦軍のモビルスーツは化け物か」
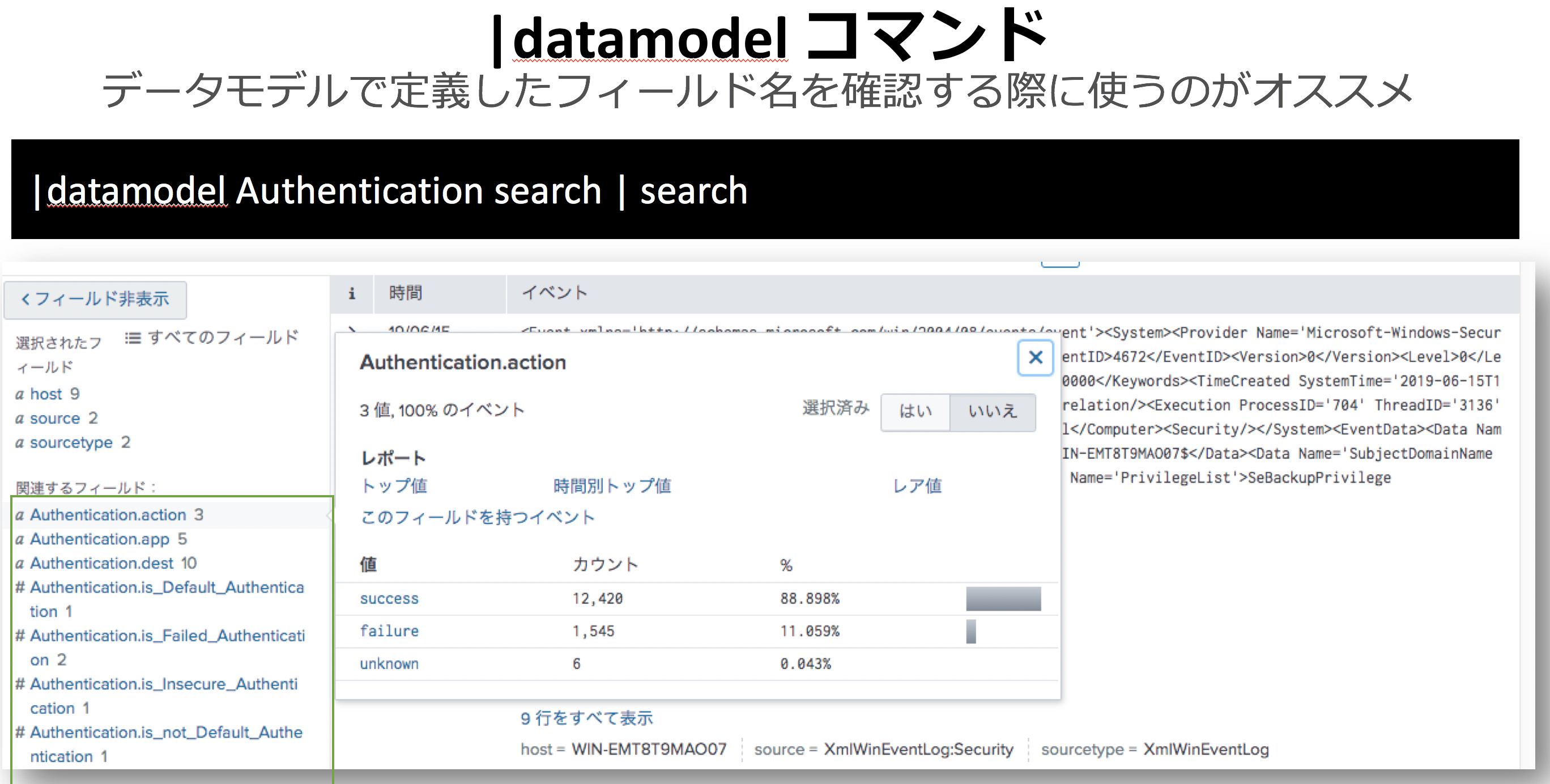
|datamodelコマンドのSPLはいつ使うのか?
便利なtstatsコマンドとは

statsコマンドと比べてみよう
ここでもやはり。「ええい!連邦軍のモビルスーツは化け物か」

まとめ
- スキーマオンザフライで取り込んだ生データから、相関分析のしやすいCIMにマッピングを行う
- CIMマッピング済みのデータモデルを活用して、複数ログソースを横断的に検索する
- 更に高速化データモデルを作成して高速集計、検索を行う