はじめに
ちょうど一年ほど前に Splunk MLTKを使って Kaggleの Titanicに挑戦したのですが、その後 Deep Learning Toolkitもリリースされたため、今度は頑張って Deep Leariningを使って同じ課題に挑戦してみたいと思います。前よりもいい結果が出るといいなー。
Splunk Deep Learning Toolkit (DLTK)とは?
以前の記事で Splunk DLTKについてセットアップ方法を解説しましたが、Splunk内に保存されたデータをDeepLearningを使って作成したモデルで学習し予測できるようになる追加のAppになります。特徴としてはDocker のコンテナ環境でモデルの学習ができるため、リモートのGPUを積んだマシン上で高速な学習や予測ができる点と、Jupyter Notebookを使ったモデル作成ができます。利用できるライブラリも tensorflowや pytorchや spacyなどのNLPにも対応しております。また自分で追加したライブラリをコンテナとして用意することで、最新のライブラリなども追加ができるようになります。
DLTKのセットアップや詳細はこちらをご覧ください↓
Deep learning に対応!! Splunk DL Toolkit に触ってみた
https://qiita.com/maroon/items/5a8b027631a674d6d8be
やること
今回も前回同様に Kaggle で提供されているTitanicのデータを使います。こちらの訓練データには乗客者の情報や生死の情報があり、テストデータには生存結果以外のデータがあります。訓練データを用いてモデルを学習し、テストデータに対して生存予測を行い結果をKaggleに提出してスコアを確認したいと思います。
ただし今回は Splunk DTLKを用いることを条件とします。
以前の MLTKを使った Kaggle 挑戦記事
https://qiita.com/maroon/items/53fd1ce702fe14485ba1
環境準備
今回はシンプルに Single Instanceに Splunk と Dockerをインストールし、DLTKを追加しました。 GPUは使ってません。
Kaggle Titanic データはこちらです。 (train.csv と test.csv)をダウンロードします。
https://www.kaggle.com/c/titanic/data
ダウンロードしたデータは、lookupファイルとしてSplunkにアップロードしておきます。
「設定」ー「ルックアップ」ー「ルックアップテーブルファイル」ー「新規追加」

今回はそれぞれ、titanic-train.csvと titanic-test.csv としてSplunkに登録しました。
これでSplunkからデータを読み込めるようになりました。

データの分析・前処理
おそらく一番時間がかかり、かつスコアをあげるためには重要な箇所だと思いますが、データを分析して DeepLearningで分析できるように、またスコアがあがるようにデータを加工しなければいけません。この部分はDLTKは全く利用せず Splunkの機能を使って処理をしていきます。(以前のMLTKを使った記事なども参考にしてください)
機械学習と違う点は特徴量が多くなっても、それほど問題にならないので、思いっきりOnehot Encodingを使える点でしょうか。ただしテストデータにも同じ特徴量がないとApply時にエラーになるので、その点だけは注意が必要です。また特徴量が多くなりすぎると精度が落ちる可能性もあるので調子に乗って作りすぎに注意です。
また機械学習と同じく数値データに変換しなければいけないのと、欠損値はなにかしらの対応をしないといけません。
Splunkで分析する上で便利ないくつかのコマンドをご紹介します。
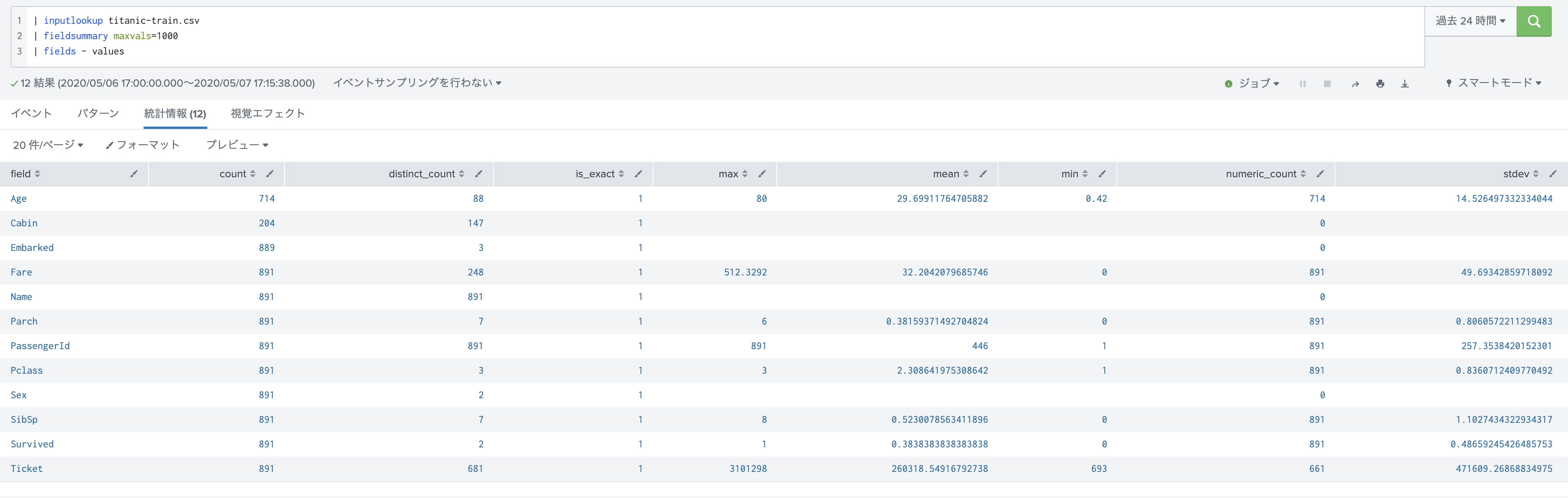
fieldsummary : (Field情報の確認・欠損値の確認)
各Field情報を確認できます。 values フィールドには全部のvalueが出るため見にくくなるので、そちらは省きました。
count を見ると、Age / Cabin / Embarked がいくつか欠損していますね。また numeric_countを見ると数値データの数が確認できます。数値データ以外はなにかしらの方法で数値に変換が必要になります。
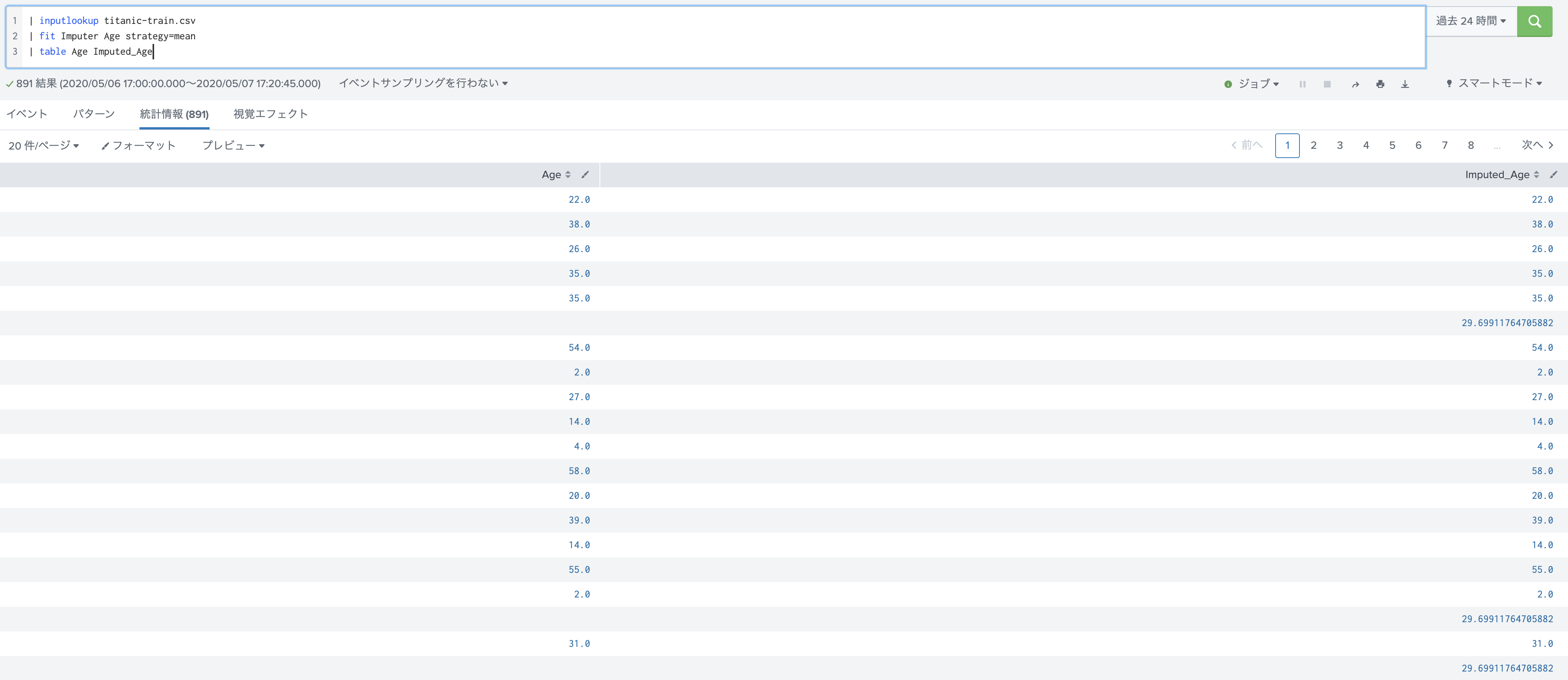
fit Imputer : (欠損値を平均や中央値で埋める)
Age Fieldを見ると欠損値データを全部省くわけにはいかないので、なにかしらの数値で埋めたいですね。ここで便利なのが fit Imputer です。
オプションで指定する事で平均値や中央値で埋めてくれます。新たに Imputed_Age というフィールドができるので、 renameで戻してあげるなどの処理を忘れずに。
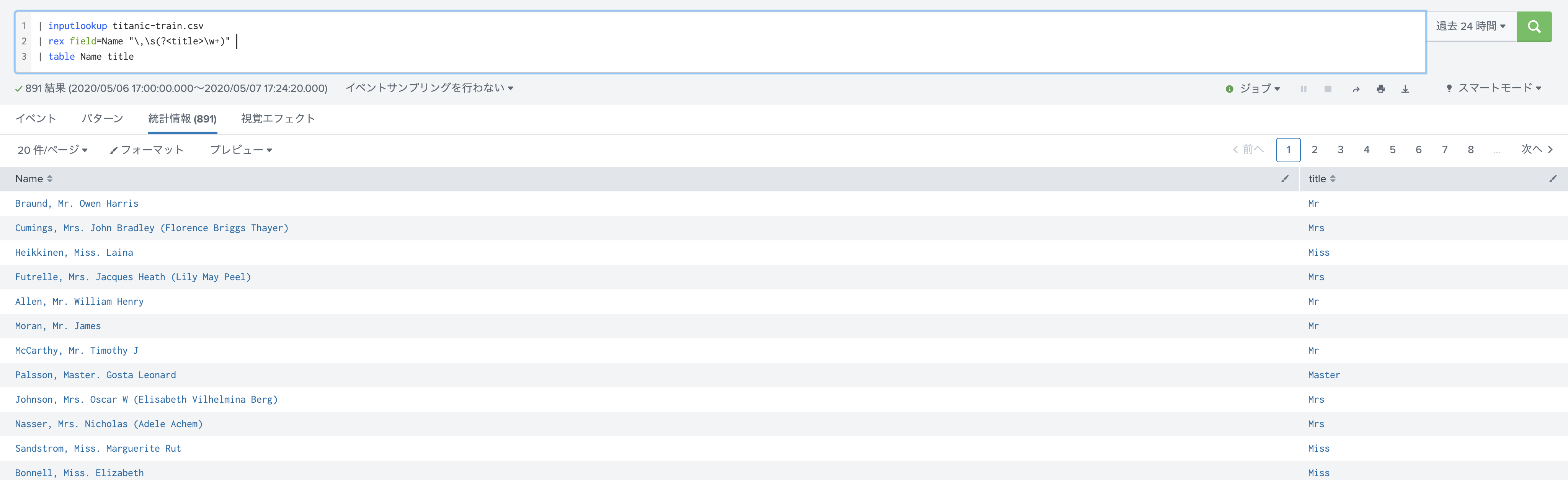
rex : (フィールド抽出)
これは Splunkユーザーならお馴染みのコマンドですが、特定の箇所を抜き出したいときに正規表現を使って抽出できます。
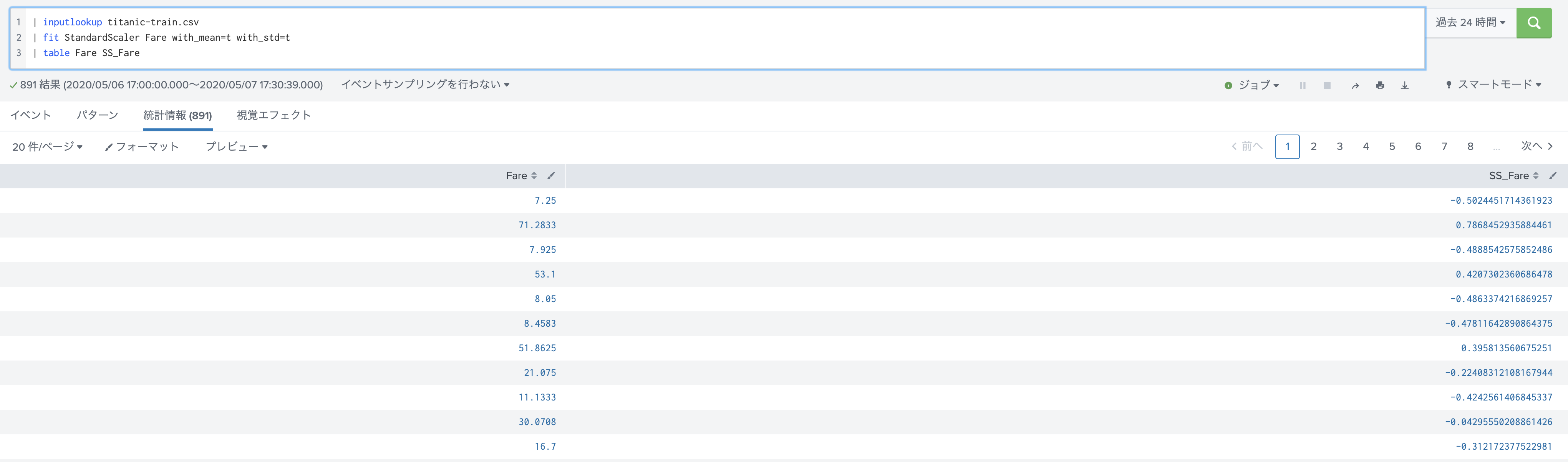
fit StandardScaler : (データの正規化)
特定の特徴量だけ大きい数字だとうまく学習ができないことがあります。そこでデータを正規化したいときに便利なコマンドです。データ値を平均0, 偏差1に変換してくれます。こちらもSS_という頭文字がつく新規フィールができるのでご注意を
bin : (データの分割)
データが数値データの場合ある程度まとまった範囲でカウントした方が便利なことがある。そんな時は binが便利。span以外にも binsなど色々な分割方法がある
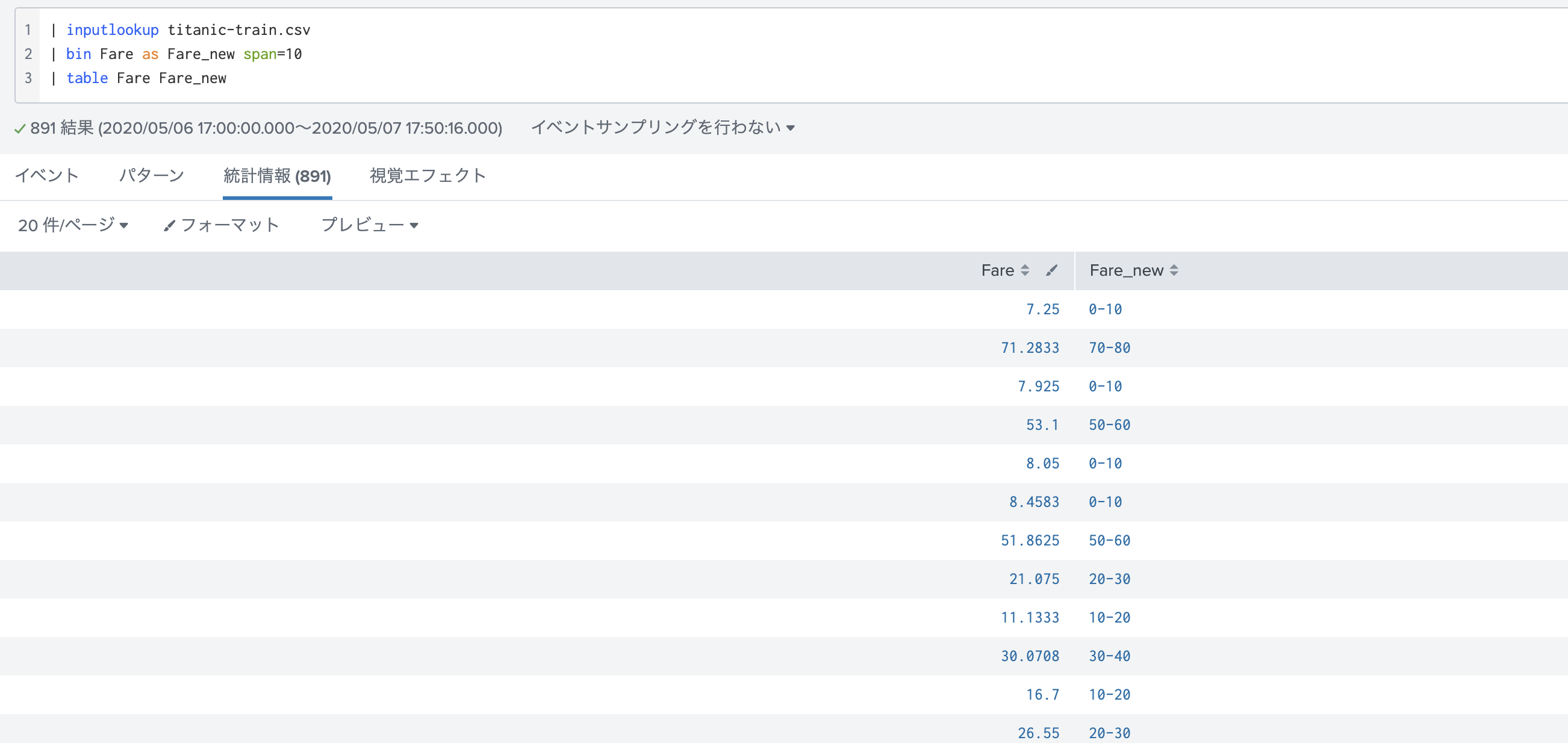
eval - case : (ケース文法)
データをいくつかのカテゴリに分類したいときに使うと便利です。このあと紹介する One-Hotを行う前にカテゴリ分けしておくと特徴量の爆増を抑えることができます。
また最後のその他の項目を作る際には 1=1 などと指定するのがコツです。
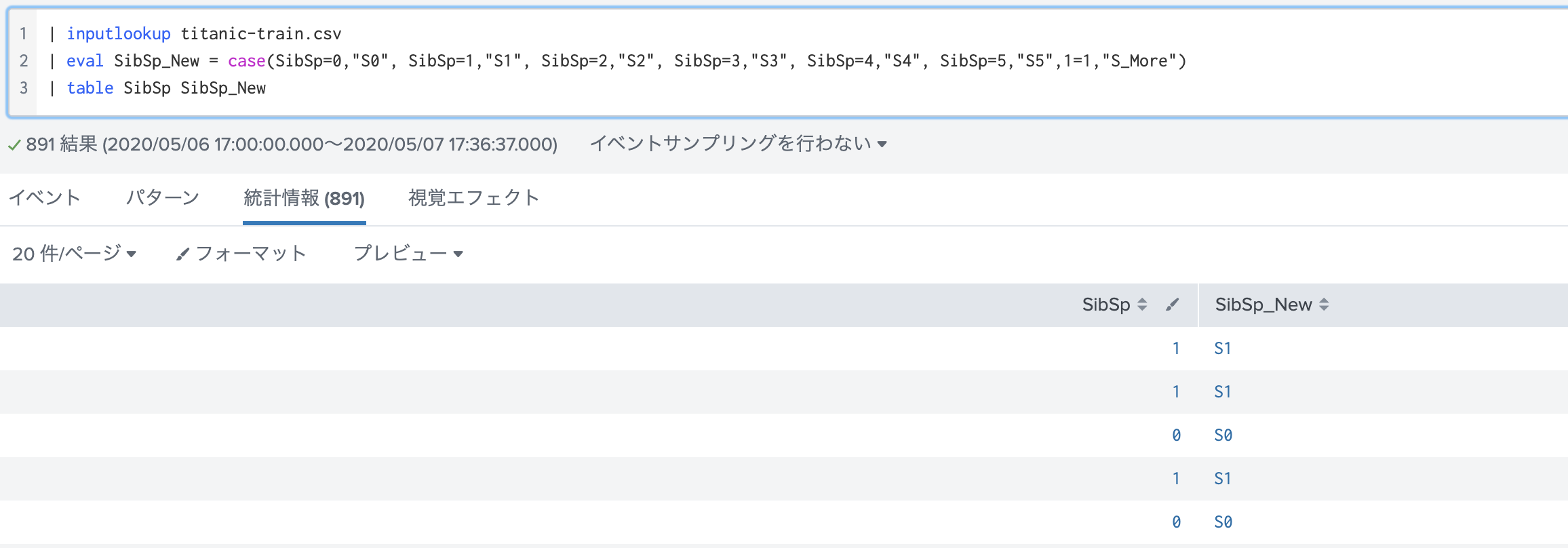
eval {} = 1 : (OneHot エンコーディング)
カテゴリカルフィールドを数値に変換するのに用いられる OneHotですが、Splunkではこのように実行します。最後に fillnullで null値を 0で埋めるのを忘れずに。

今回実施した前処理
今回は色々と試しましたが、最終的に以下のような前処理を行いました。
| inputlookup titanic-train.csv
# Ageの欠損値を平均で埋めて、90で割って0-1に収まるようにした
| fit Imputer Age strategy=mean | eval Age = round(Imputed_Age / 90,1) | fields - Imputed_Age
# Embarked は、欠損値が2つだけだったためDropした。
| search Embarked = *
# SibSpとParchは数値データだったが、0-1に治めるため文字に変換して、あとで OneHotを行った
| eval SibSp = case(SibSp=0,"S0", SibSp=1,"S1", SibSp=2,"S2", SibSp=3,"S3", SibSp=4,"S4", SibSp=5,"S5",1=1,"S_More")
| eval Parch = case(Parch=0,"P0", Parch=1,"P1", Parch=2,"P2", Parch=3,"P3", Parch=4,"P4", Parch=5,"P5",1=1,"P_More")
# Fareに関しては最大値を計算して、その値でそれぞれ割ることで 0-1の値に収めた
| eventstats max(Fare) as max_Fare
| eval Fare = round(Fare/max_Fare,1) | eval Fare = "F_" + Fare, Age = "Age_" + Age | fields - max_Fare
# Name からtitleを抽出し、それを利用した
| rex field=Name "\,\s(?<title>\w+)" | fields - Name
| eval title = case(title="Mr","Mr", title="Miss", "Miss", title="Mrs","Mrs",title="Master","Mastar",1=1,"Other")
# Ticketも数字データだけ抽出し、今回はbinを使って分類した
| rex field=Ticket "(?<TicketNo>\d+)$" | fields - Ticket
| bin TicketNo span=100000
| eval TicketNo = case(TicketNo="0-100000","No0", TicketNo="100000-200000", "No100000", TicketNo="200000-300000", "No200000",TicketNo="300000-400000","No300000",1=1,"NoOther")
# CabinはNULL値がほとんどだったが、アルファベット+数値だったため、なんとなく最初のアルファベットが重要だと感じ、アルファベットだけを抽出し利用しました。
| rex field=Cabin "(?<Cabin>\w)"
| eval Cabin = case(Cabin="T","Cabin_Unknown",Cabin="C","Cabin_C", isnull(Cabin),"Cabin_Unknown",1=1,Cabin)
# OneHotでカテゴリカル変換しました。
| eval {Pclass} = 1, {Sex} = 1, {Embarked} =1, {title}=1, {Cabin} = 1, {TicketNo}=1, {SibSp}=1,{Parch}=1, {Fare} =1, {Age} = 1
| fillnull
# 最後に不要なフィールドは削除
| fields - Pclass, Sex, Embarked, title, count, Cabin, TicketNo, Fare, SibSp, Parch,Age, PassengerId, "Age_0.9"
# DeepLearning モデル作成
次に DeepLearning でモデルを作成してきます。ここからは DLTKを利用します。
DLTKの Container 画面で、[TensorFlow CPU]を選択して、[Start]します。 その後 [JUPTERLAB] をクリックします。
Jupyter Notebookの画面が現れます。パスワードは(Splunk4DeepLearning)です。
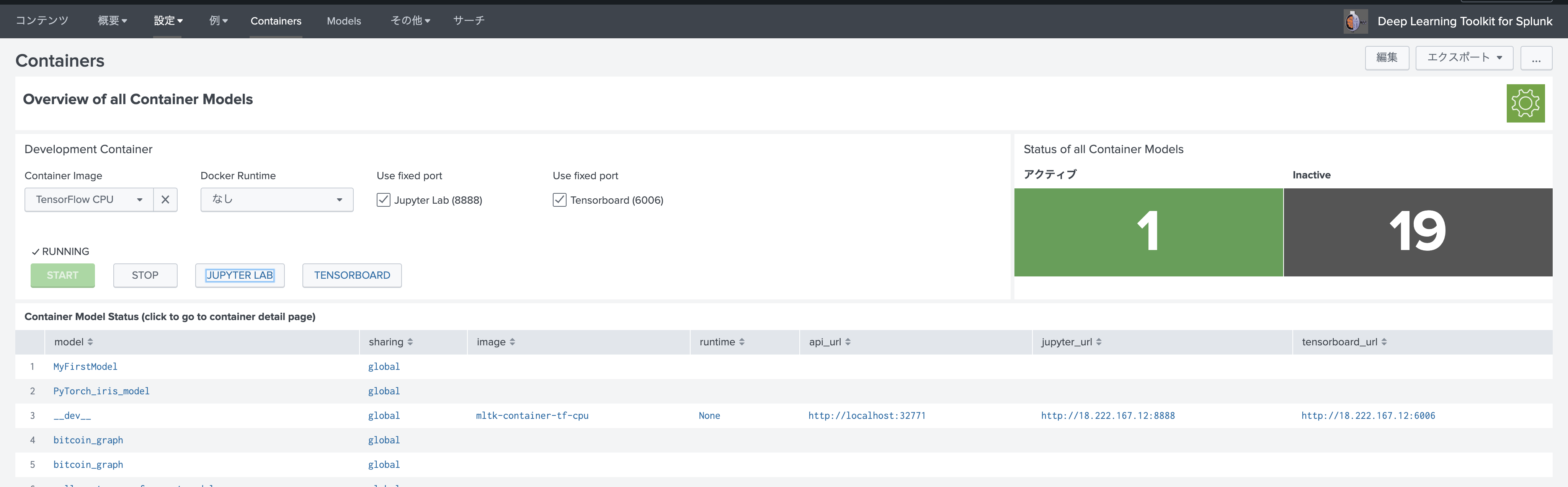
いくつかサンプルコードがあります。一からコードを書くことも可能ですが、Splunkと連携するためのお作法的なところもあるので、利用できるものは利用しましょう。
今回は生存を予測するので、2値予測になります。一番近いものは「binary_nn_classifier.ipynb」のため、こちらをコピーしてrenameして利用します。今回は[mytitanic3]としました。

サンプルデータの読み込み
次にモデルを作成するために実際のデータを読みこんでおきます。あくまでコードを書くためのものなので、ここで学習したものはまったく利用されません。実際にサンプルデータを動かして問題がないかチェックしたり、ネットワーク作成の際に参考とするためのものになります。
先ほどSplunkで前処理を行ったコマンドに続いて、以下のコマンドを追加します。注目点は mode=stage オプションです。こちらはあくまでステージング処理。という意味でデータをコンテナに引き渡すモードになります。これでデータがコンテナ内に送られます。送られたデータは "/srv/notebooks/data/" に保存されます。
| fit MLTKContainer mode=stage algo=mytitanic3 Survived from * into app:mytitanic3_model
保存されたデータは、データ部分とパラメータ部分に分けられて保存されています。juypter notebookへの読み込みコードがあるのでそのまま利用しましょう。
# mltkc_stage
# this cell is not executed from MLTK and should only be used for staging data into the notebook environment
def stage(name):
with open("data/"+name+".csv", 'r') as f:
df = pd.read_csv(f)
with open("data/"+name+".json", 'r') as f:
param = json.load(f)
return df, param
モデル作成
さて、ここではネットワークを自由に作成しましょう。どうやらお作法として モデルは def initで定義しておく必要があるようです。この後のfitやapplyも同じく defで定義しておく必要があります。
今回は2値分類ということで以下のようにしました。色々と試している内にどんどんレイヤーが深くなってしまいました。
- Dense x 9,
- BatchNormalization + Dropout を挟む。
- 初期パラメータを random_uniformで設定
- Optimizer は adam
- 損失関数は binary_crossentropy
def init(df,param):
X = df[param['feature_variables']]
print("FIT build model with input shape " + str(X.shape))
input_shape = int(X.shape[1])
model = keras.Sequential()
model.add(keras.layers.Dense(input_shape*2, input_dim=input_shape, activation=tf.nn.relu,
kernel_initializer='random_uniform'))
model.add(keras.layers.Dense(32, activation=tf.nn.relu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(32, activation=tf.nn.relu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(32, activation=tf.nn.relu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(32, activation=tf.nn.relu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(32, activation=tf.nn.relu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(32, activation=tf.nn.relu))
model.add(keras.layers.Dense(32, activation=tf.nn.relu))
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
fit の定義
基本的にはサンプルコードを参考にしておりますが、テスト学習した際にvalidationデータがなかったので、データを8:2で分割して、validationデータを作成しております。また Earlystoppingを追記しました。これによって無駄な学習時間を短縮し過学習を防ぐことができます。
# mltkc_stage_create_model_fit
# returns a fit info json object
def fit(model,df,param):
returns = {}
X = df[param['feature_variables']]
Y = df[param['target_variables']]
X_train, X_val = np.vsplit(X, [int(X.shape[0] * 0.8)])
Y_train, Y_val = np.vsplit(Y, [int(Y.shape[0] * 0.8)])
model_epochs = 300
model_batch_size = 10
if 'options' in param:
if 'params' in param['options']:
if 'epochs' in param['options']['params']:
model_epochs = int(param['options']['params']['epochs'])
if 'batch_size' in param['options']['params']:
model_batch_size = int(param['options']['params']['batch_size'])
# connect model training to tensorboard
log_dir="/srv/notebooks/logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1, embeddings_freq=1)
# Early Stopping
earlystopping_callback= tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=20, verbose=0, mode='auto')
# run the training
returns['fit_history'] = model.fit(x=X_train,
y=Y_train,
verbose=2,
epochs=model_epochs,
batch_size=model_batch_size,
validation_data=(X_val, Y_val),
callbacks=[tensorboard_callback,earlystopping_callback])
# memorize parameters
returns['model_epochs'] = model_epochs
returns['model_batch_size'] = model_batch_size
returns['model_loss_acc'] = model.evaluate(x = X, y = Y)
return returns
その後に実際にサンプルデータを使って学習テストができるので、結果を見ながらモデルのネットワークをいじったりして繰り返します。

Apply 定義
Splunkに戻すデータは、ここで定義します。今回は predictした結果を返します。
# mltkc_stage_create_model_apply
def apply(model,df,param):
X = df[param['feature_variables']]
y_hat = model.predict(x = X, verbose=0)
return y_hat
その他定義 (save , load, summary )
その他のsave / load , summary などの定義はコピーしたサンプルをそのまま利用しました。
この後実際にSplunkから学習をすると、ここで定義したDirectoryに保存されたり、apply時にモデルを読みこんだりします。

これでモデルの作成(コーディング)は終了です。
学習開始
それでは作成したモデルに実際のデータを使って学習したいと思います。
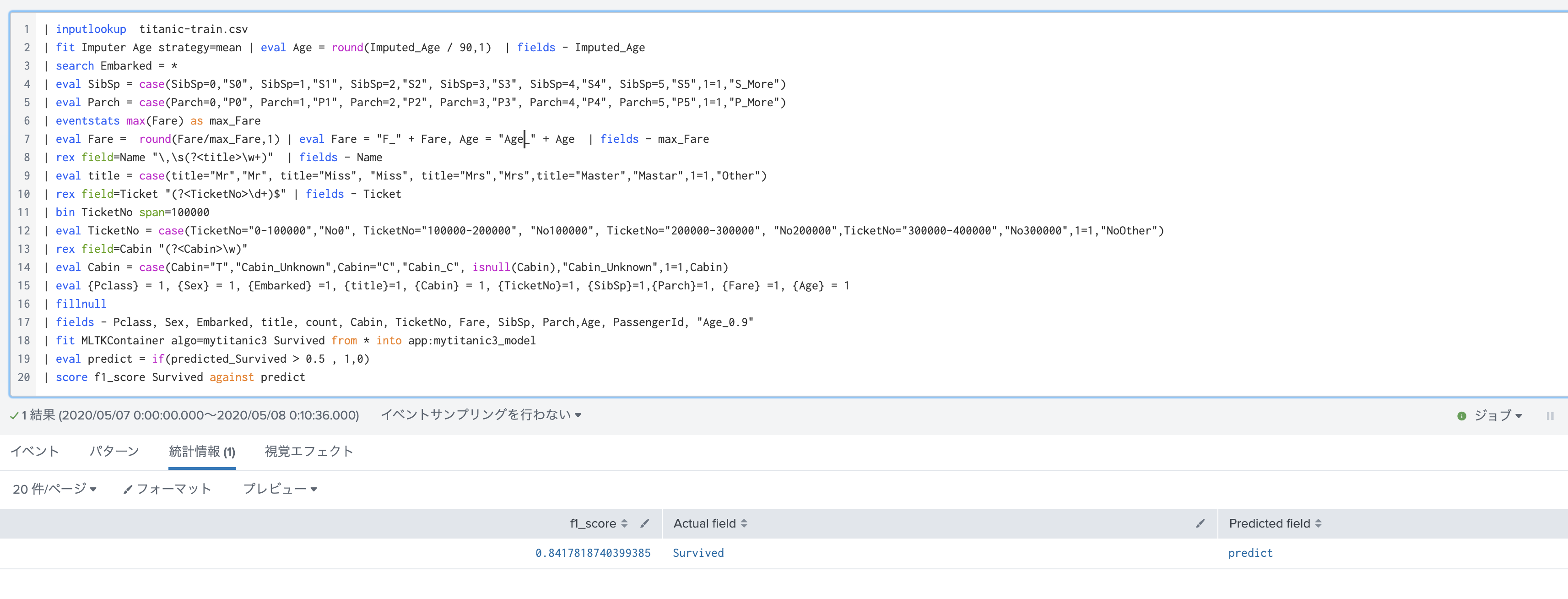
前処理を行ったデータに続いて、以下のSPLコマンドを追加します。 1行目のfit の行は、データ読み込み時に利用したコマンドに似ておりますが、mode=stageが抜けただけです。これでstagingではなく、実際の学習ということを伝えております。
今回 0 から 1 の間の連続した数値が予測結果として返ってきます。そのため今回はシンプルに 0.5よりも大きければ1(生), 小さければ 0(死) と判断しました。
最後は正解率をスコアするためのコマンドです。今回はf1_scoreを指定しております。この値が低い場合は、前処理をもう少し工夫するかモデルを修正する必要があります。
・・・
| fit MLTKContainer algo=mytitanic3 Survived from * into app:mytitanic3_model
| eval predict = if(predicted_Survived > 0.5 , 1,0)
| score f1_score Survived against predict
Tensorboard で学習状況の確認
Splunk側からは学習状況が確認できないですが、TensorboardがDLTKにはdefaultでついてますので、そちらで状況を確認できます。今回はEarlyStoppingが効いているのがわかります。

テストデータに適用
それではモデルの学習も終了したので、この学習済みモデルを使って、テストデータを予測したいと思います。
予測はシンプルで、applyコマンドを利用して、先ほどのモデルを読み込みます。ただしテストデータも訓練データと同じように前処理を行う必要があります。
前処理を行った後に、以下のコマンドを追記します。
最後にkaggleに提出するフォーマットに出力します。
・・・
| apply app:mytitanic3_model
| eval Survived = if(predicted_Survived > 0.5 , 1,0)
| table PassengerId Survived
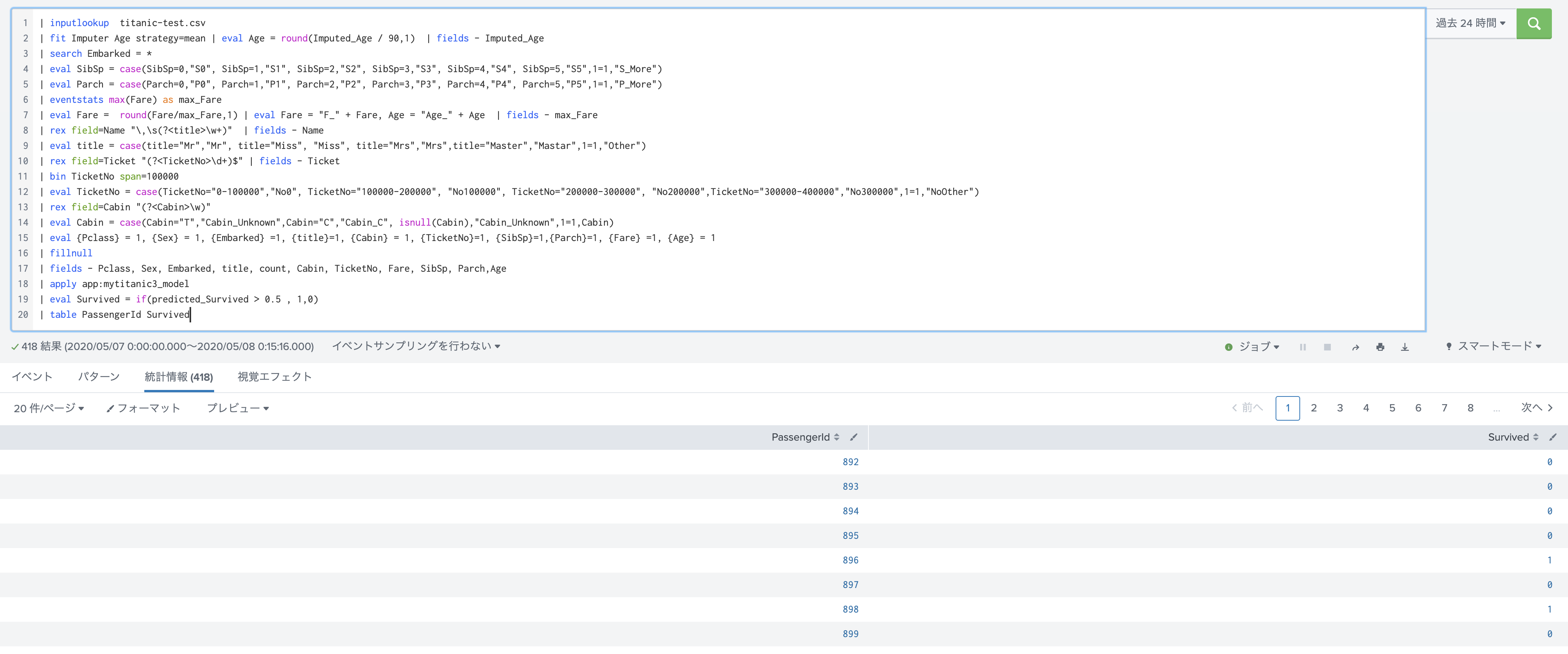
結果をcsv に出力します。
簡単に出力するためには、以下の権限をロールにアサインしておくと便利です。
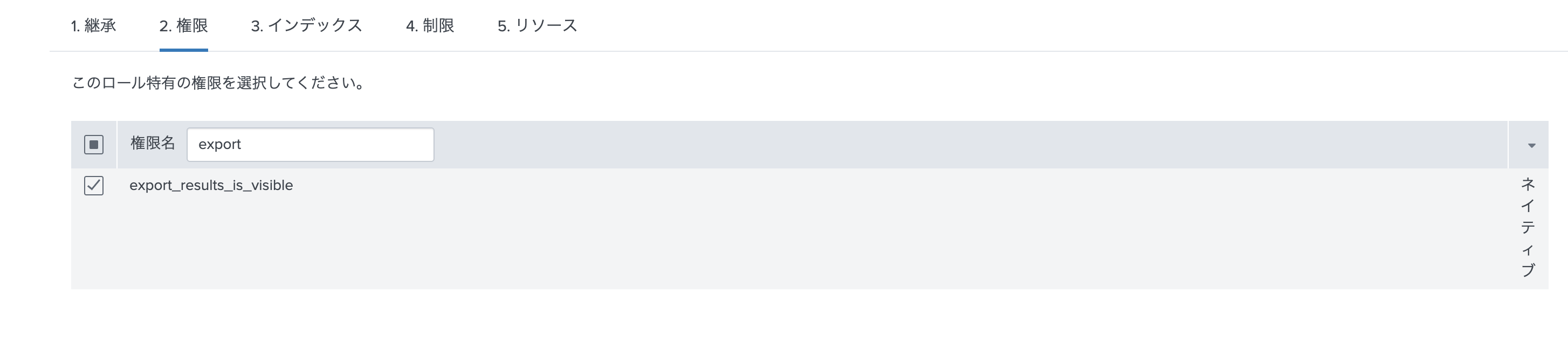
右側の中段あたりに export ボタンが現れて、csvで出力できるようになります。

kaggle へ提出
kaggle の titanic の提出サイトに移動し、先ほど出力したデータをアップロードします。
https://www.kaggle.com/c/titanic/submit

何度かモデルや前処理を変えながらチャレンジしましたが、80%を超えられず。。。。(残念)
しかしDLTKの使い方がわかってきて、当初の目的は達成できたかな。
ちなみに、MLTKを使ったチャレンジでは、0.77033 だったので、少しだけ改善しました。(ほとんど変わりませんが)
最後に感想
よかった点:
・データ抽出や加工などはSplunkをそのまま利用できる。可視化なども簡単!
・表現力がUpする
・jupyter labをそのまま利用できる
・前処理を編集しながら学習が簡単にできる
・サンプルコードの充実
気になった点:
・仕組みを理解できるようなドキュメントとかがもっと欲しい
・jupyterlab は便利だが、google collaboratory などと比較すると機能が劣る
・MLTKに比べると、やはり複雑でスキルも必要になるためハードルは高そう。(データサイエンティスト向けかも)
とはいえ慣れが大事なので、今後も別のデータを使ってチャレンジを続けたいと思います。
# (おまけ) 今回作成したコード
今回 jupyter labで利用した notebookは、こちらからダウンロードできます。整理されていないので中身はぐちゃぐちゃですが参考としてご利用ください。
https://github.com/maroon-spec/qiita/tree/master
ダウンロードしたファイルは、お使いのjupyter labにアップロードしてお使いいただけます。