はじめに
Databricksでは基本的にNotebook baseでの開発を中心としており、ローカルのIDEでの開発という観点では。。。という感じでした。この度Databricks for Visual Studio Codeが発表され、IDEでの開発もしやすくなったとのことなので早速試してみたいと思います。
こちらのマニュアルを参考にしております。詳細はマニュアルをご覧ください。
https://docs.databricks.com/dev-tools/vscode-ext.html
動画で確認したい方はこちらをご覧ください。
https://www.youtube.com/watch?v=jAXxViBI3Ho
どんな事ができるのか?
-
Visual Studio Codeで開発したローカルコードをリモートワークスペースと同期させ実行することができます。
-
Visual Studio Code からローカルの Python コードファイル (.py) および Python ノートブック (.py と .ipynb) を、リモートワークスペース内の自動化された Databricks ジョブとして実行します。
-
VSCode上からDatabricks Clusterを起動・シャットダウンできる。
-
Debugできる(databricks connectとの連携が必要)
利用要件
利用するには以下の環境条件を満たす必要があります。
-
Databricks Workspace : (詳細はこちら)
- Clusterが作成されていること (SQLWarehouseはサポートされておりません)
-
Databricks Reposが使える事 (同期するためのRepositoryを作成)(Repos以外にもWorkspaceを使用できるようになりました)
-
Local開発環境 (詳細はこちら)
- Visual Studio Code version 1.69.1 or higher.
- A Databricks CLI & configuration profile(setupはこちら)
Getting Started
- VSCode Marketplaceから"Databricks for Visual Studio Code"を検索してInstallします。
構成をセットアップする
RemoteのDatabricks環境と連携するために、以下をセットアップする必要があります。
1.Extension設定にて同期する先を選択します。(今回はWorkspaceを選択)
「Code」メニュー -> 「基本設定」 -> 「設定」 -> 「Extension」 - 「Databricks」にて、以下の設定画面を開きます。
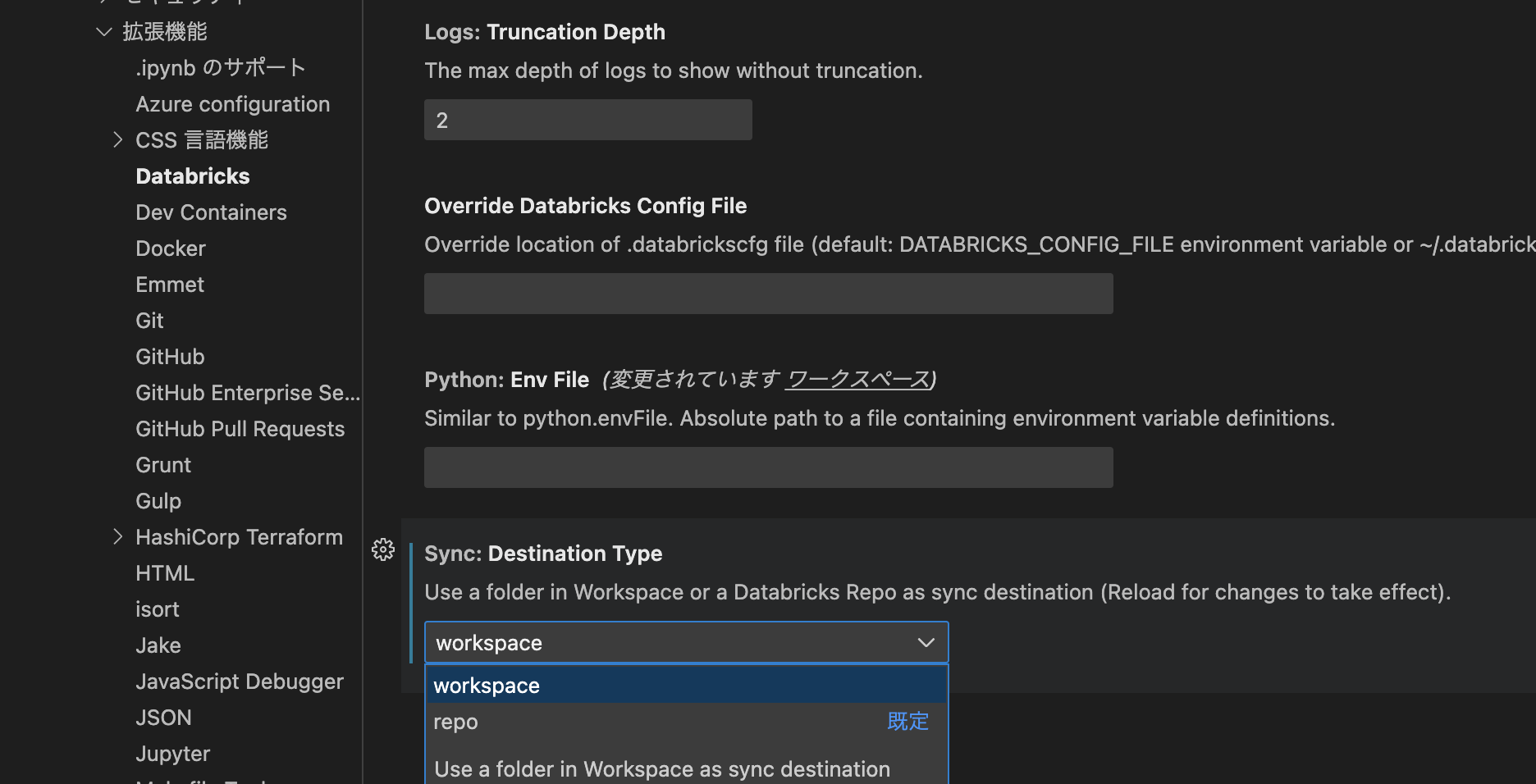
「Destination Type」にて、workspaceを選択します。(もちろん、Reposのままでも結構です)
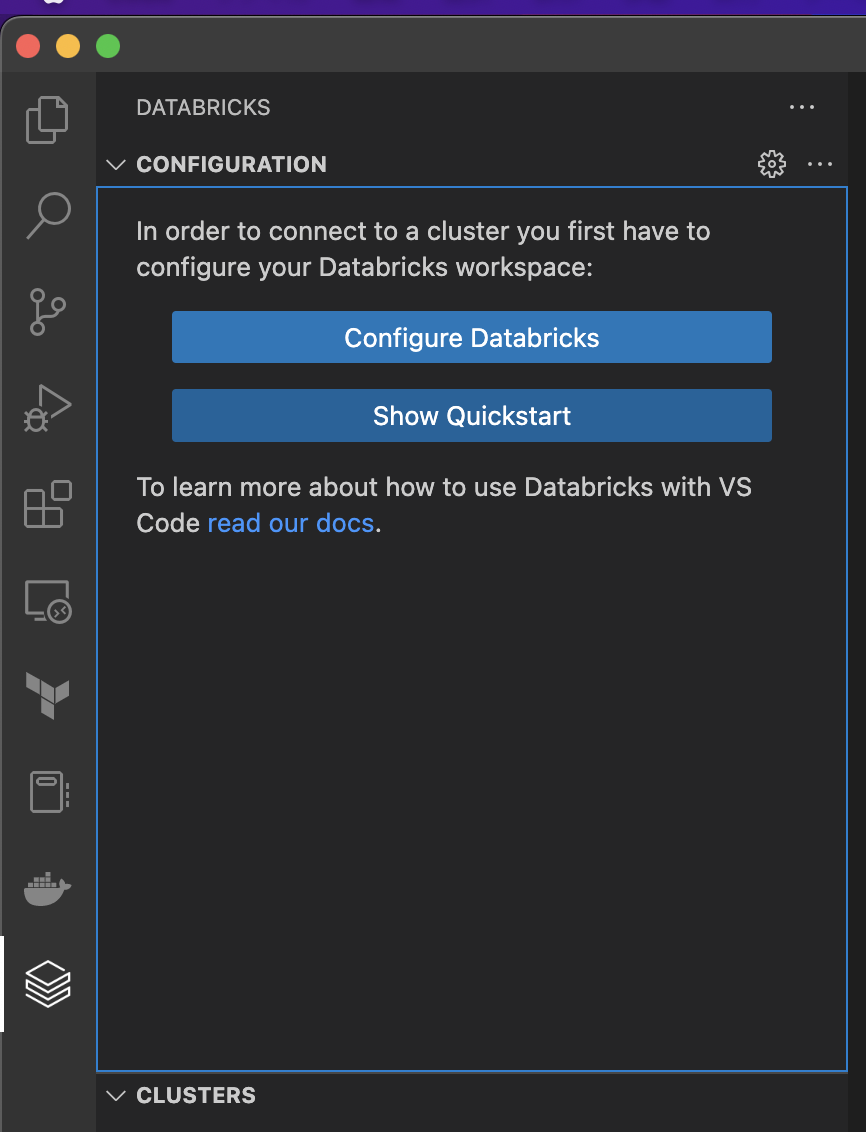
2.Databricks構成情報のセットアップ
Databricks icon -> Configure Databricks にてセットアップ
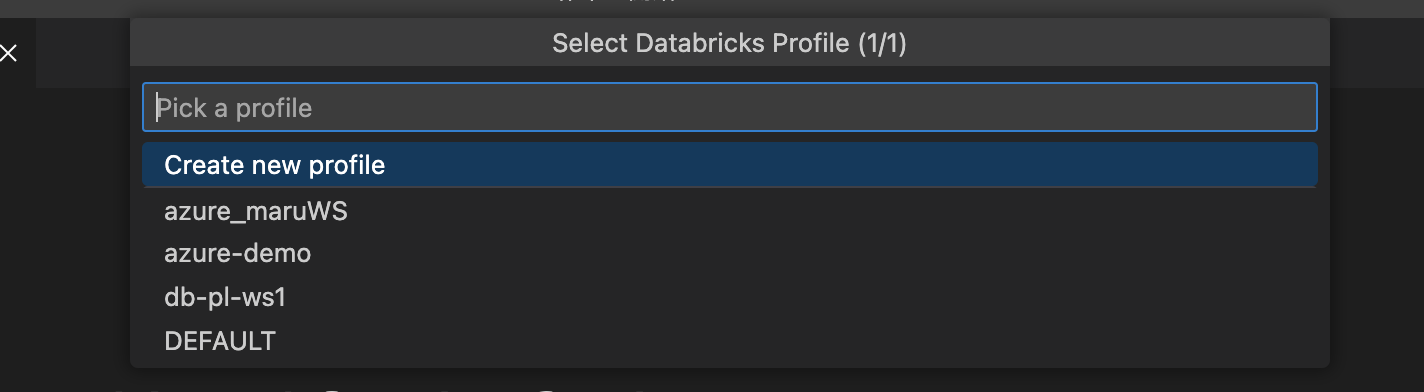
Databricks CLIで作成したプロファイルを選択する
私の環境では4つのワークスペース用のプロファイルがあるので4つ出てきました。 ここで新規プロファイル作成も可能です。このプロファイルは、対象となるDatabricks Workspaceにアクセスするための情報が保存されてます。(Databricks CLI setupはこちら)
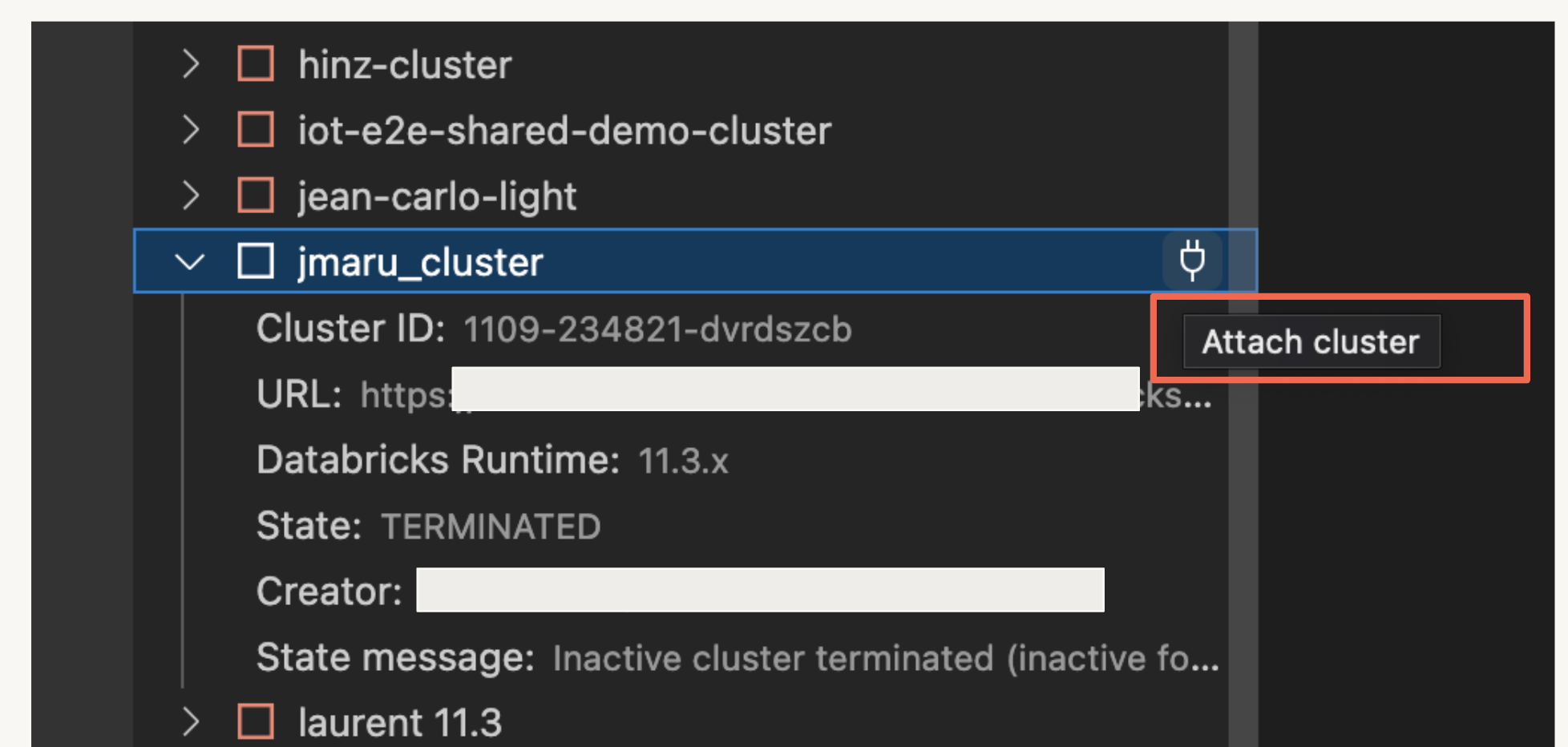
Clusterの選択
プロファイルを使って無事にWorkspaceと連携出来ると、左のペインにクラスターリストが表示されます。今回利用するクラスターをアタッチします。
ファイルの同期
ギアマークの左にある同期マークをクリックすると、ローカルのコードがDatabricks Workspace(もしくはRepos)と同期されます。
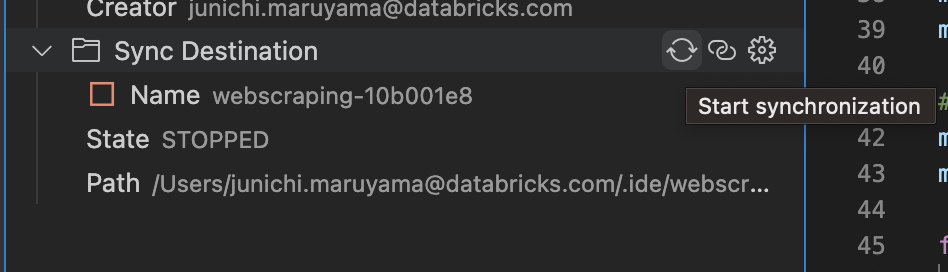
Databricks for Visual Studio Codeは、ローカルのVisual Studio CodeプロジェクトからリモートのDatabricksワークスペースにある関連リポジトリへのファイル変更の一方向の自動同期のみを実行するものです。詳細はこちらをご覧ください
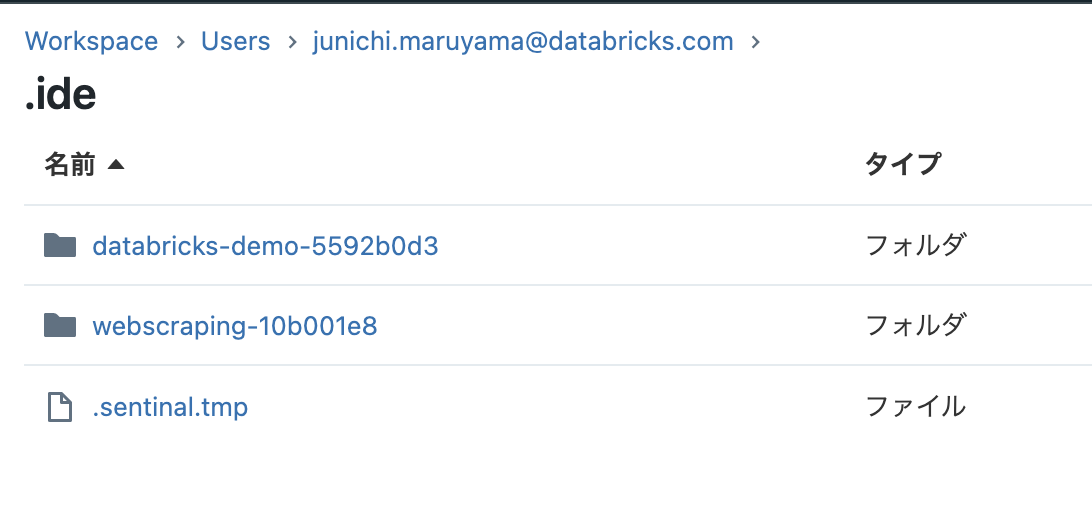
同期されると、ワークスペース側に .ideというフォルダーが作成されております。
使ってみよう
1. python fileとして Databricks Cluster上で実行する
こちらのサンプルのPythonファイルを保存して実行してみます。
from pyspark.sql import SparkSession
from pyspark.sql.types import *
spark = SparkSession.builder.getOrCreate()
schema = StructType([
StructField('CustomerID', IntegerType(), False),
StructField('FirstName', StringType(), False),
StructField('LastName', StringType(), False)
])
data = [
[ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ],
[ 1001, 'Joost', 'van Brunswijk' ],
[ 1002, 'Stan', 'Bokenkamp' ]
]
customers = spark.createDataFrame(data, schema)
customers.show()
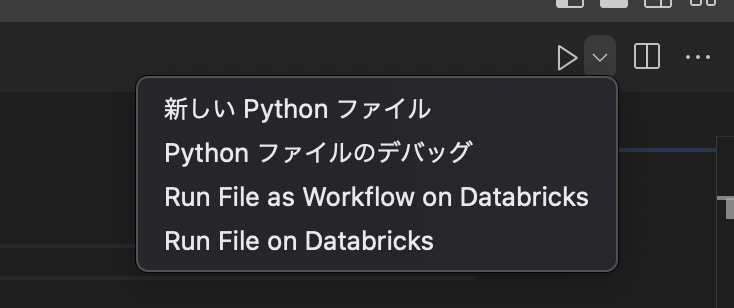
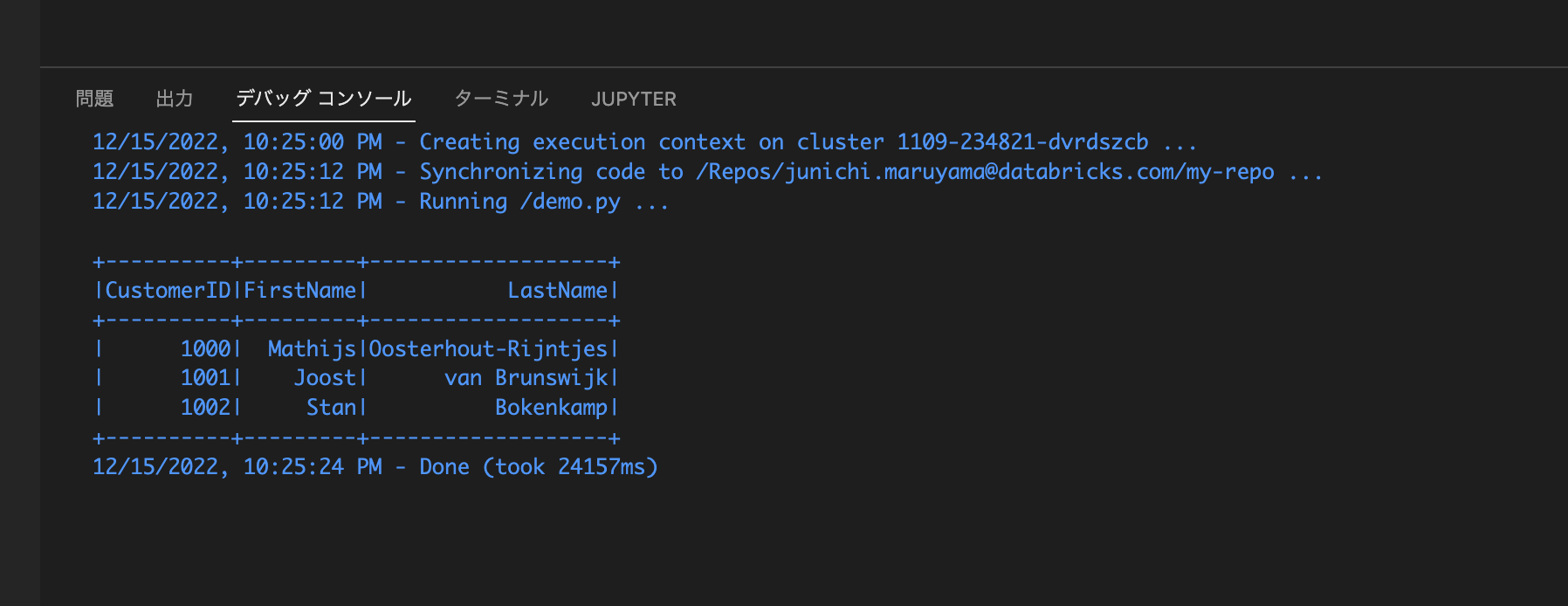
VSCodeの右上の実行ボタンを選択し、「Run File on Databricks」を実行する
実行結果が下のデバッグコンソールに出力されます。
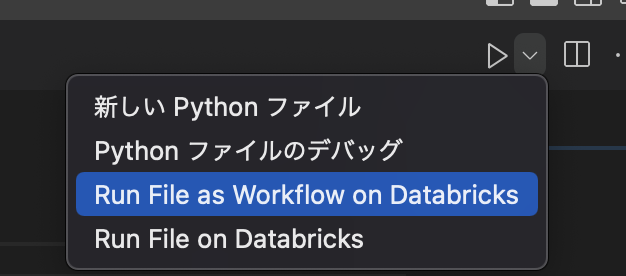
2. Jobとして実行する
コードファイルを開いて、右上の実行ボタンから「Run File as Workflow on Databricks」を実行します。
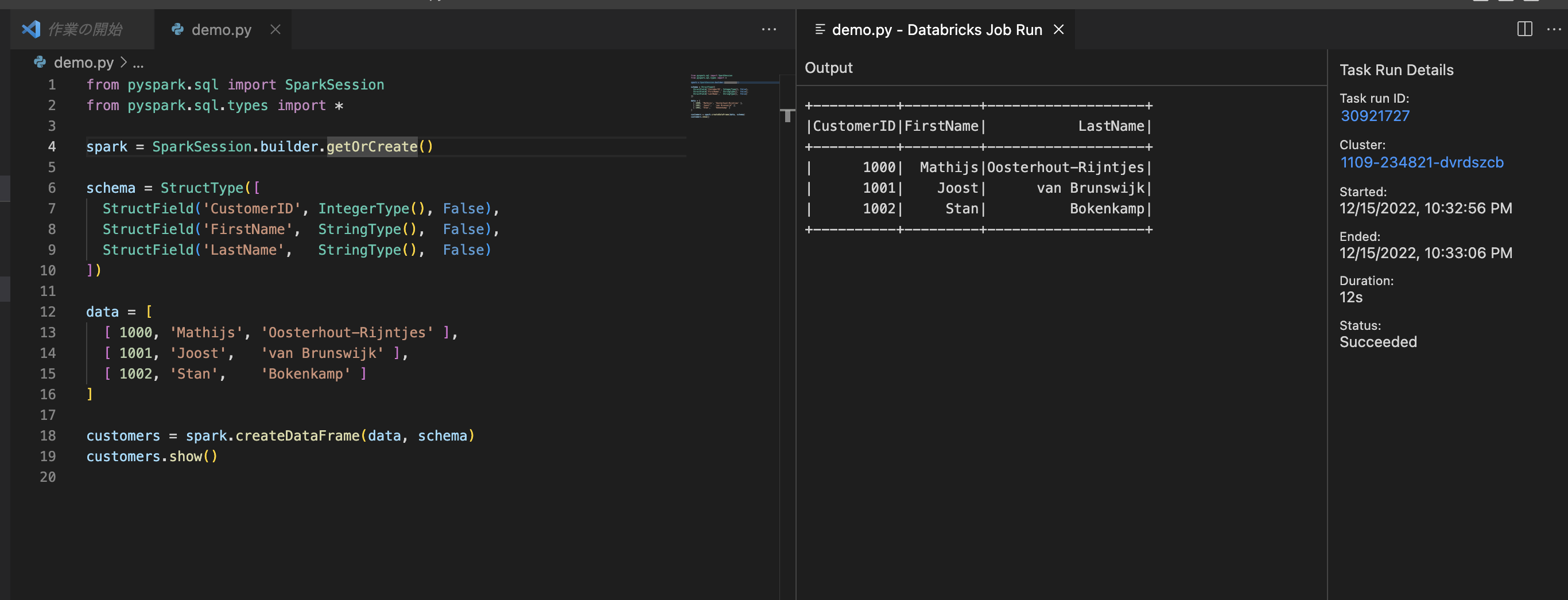
VSCode上に Job実行結果が出力されます。
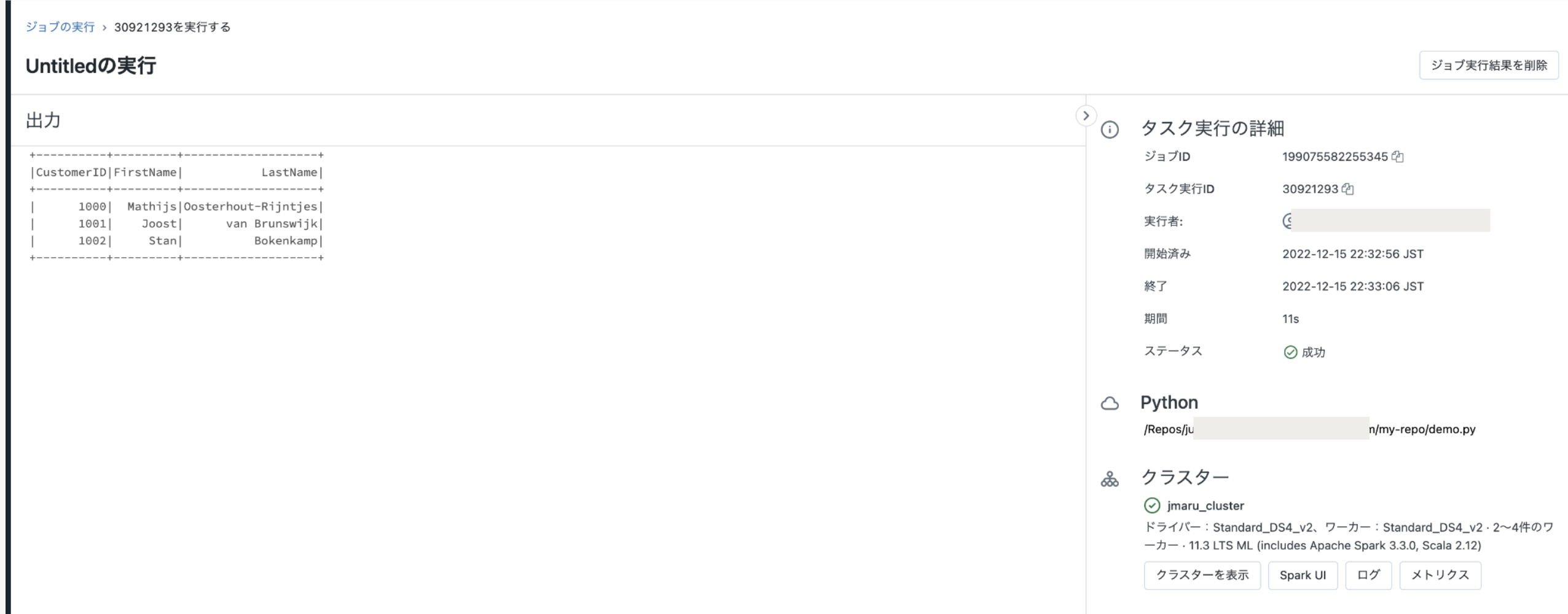
Databricks上でもジョブを確認できます。ちなみにクラスターは指定したクラスター上で実行されます。(新規ジョブクラスターが作られるわけでは無い)
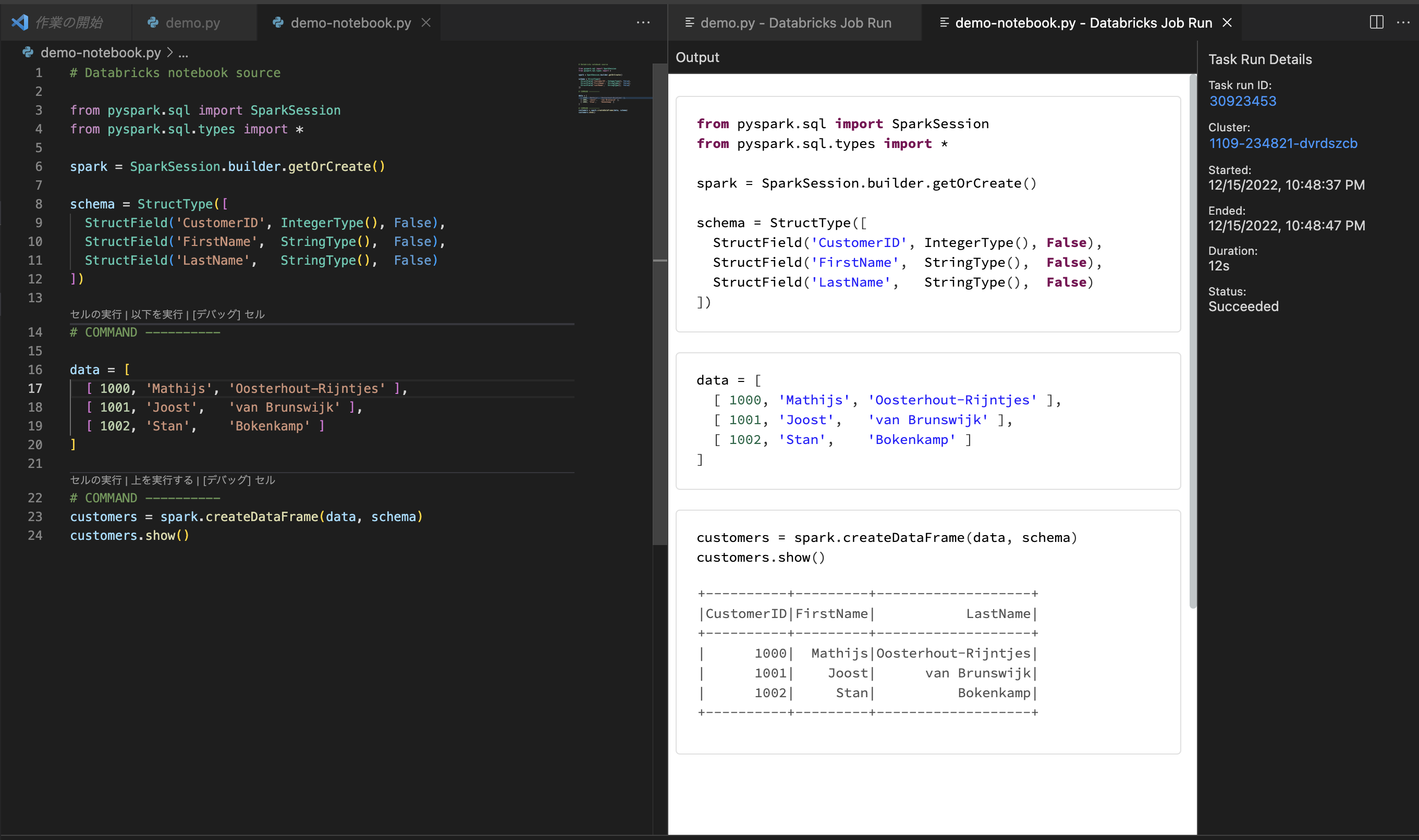
3. Python NotebookをJobとして実行する
databricks notebookとして実行するには、.py ファイルの最初の行に # Databricks notebook source を追加します。またセルを追加するには、# COMMAND ---------- を追加します。
以下のサンプルコードをご利用ください。
# Databricks notebook source
from pyspark.sql import SparkSession
from pyspark.sql.types import *
spark = SparkSession.builder.getOrCreate()
schema = StructType([
StructField('CustomerID', IntegerType(), False),
StructField('FirstName', StringType(), False),
StructField('LastName', StringType(), False)
])
# COMMAND ----------
data = [
[ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ],
[ 1001, 'Joost', 'van Brunswijk' ],
[ 1002, 'Stan', 'Bokenkamp' ]
]
# COMMAND ----------
customers = spark.createDataFrame(data, schema)
customers.show()
Run File as Workflow on Databricksを実行します。
このようにノートブックを実行した際の結果が新規タブに表示されます。
4. Debug実行
Debug実行するためには、Databricks Connectをセットアップしなければいけません。
そちらについては、別の記事をご覧ください。
Databricks Extension for VSCodeでDebugがサポートされました