はじめに
以前、Databricks extension for Visual Studio Codeにて、VSCode上で開発したコードをDatabricks上で実行したり、JobとしてWorkflow実行したりする方法をご紹介しました。
ただしSparkコードに対してDebug機能が利用できなかったため、開発も中途半端。という思いをされたのではないでしょうか?
この度 Databricks Connect V2 がリリースされ、Sparkコードに対して、IDEやアプリからDatabricksのSpark Clusterを利用することが可能となりました。
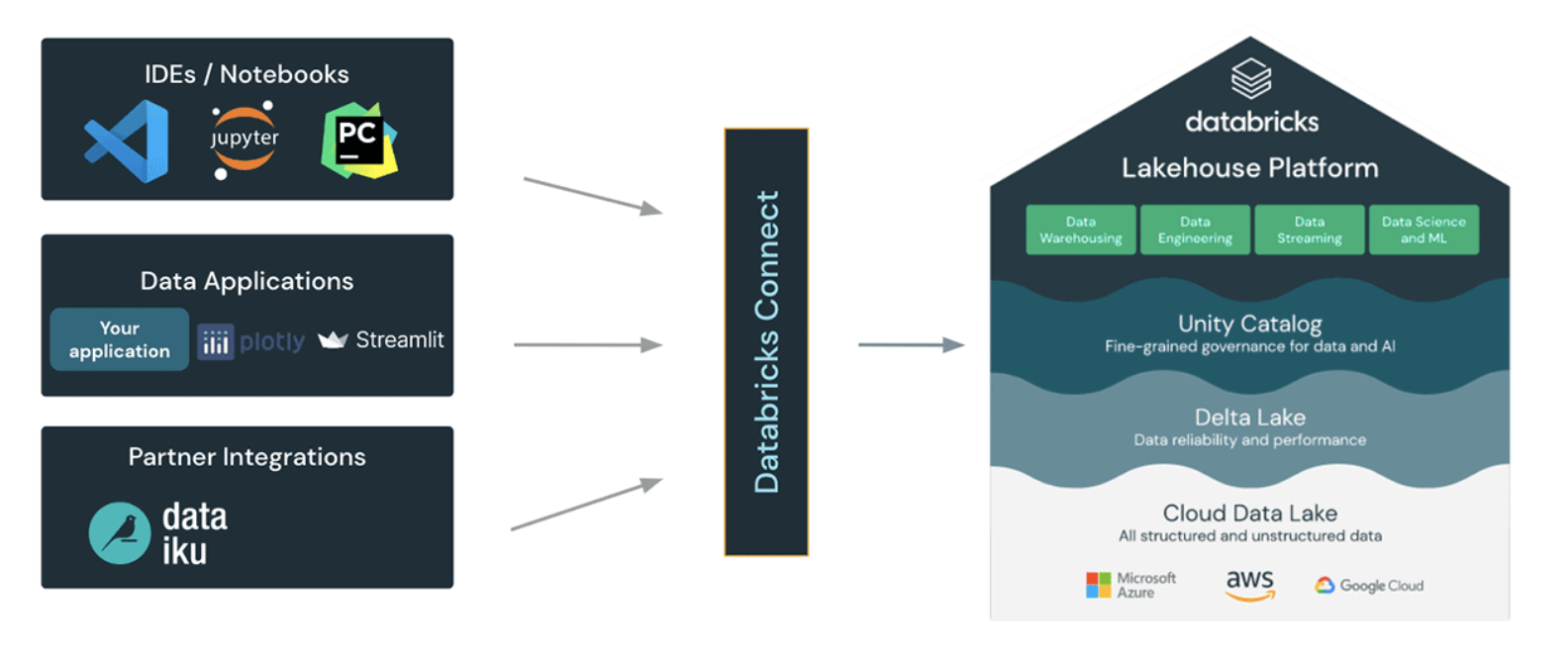
また、表題にあるとおり Databricks Extension for VSCodeと連携することで、Debugが可能となりました。今回は実際に設定して試してみたいと思います。
なお、今回の設定はこちらのマニュアルを参考にしました。
準備
- Databricks Extension for VSCodeが利用できる状態。(前回の記事を参照)
- Databricks Cluster Runtime は 13.0以降(通常とML両方サポート)を予め用意
dbconnectをTurn On
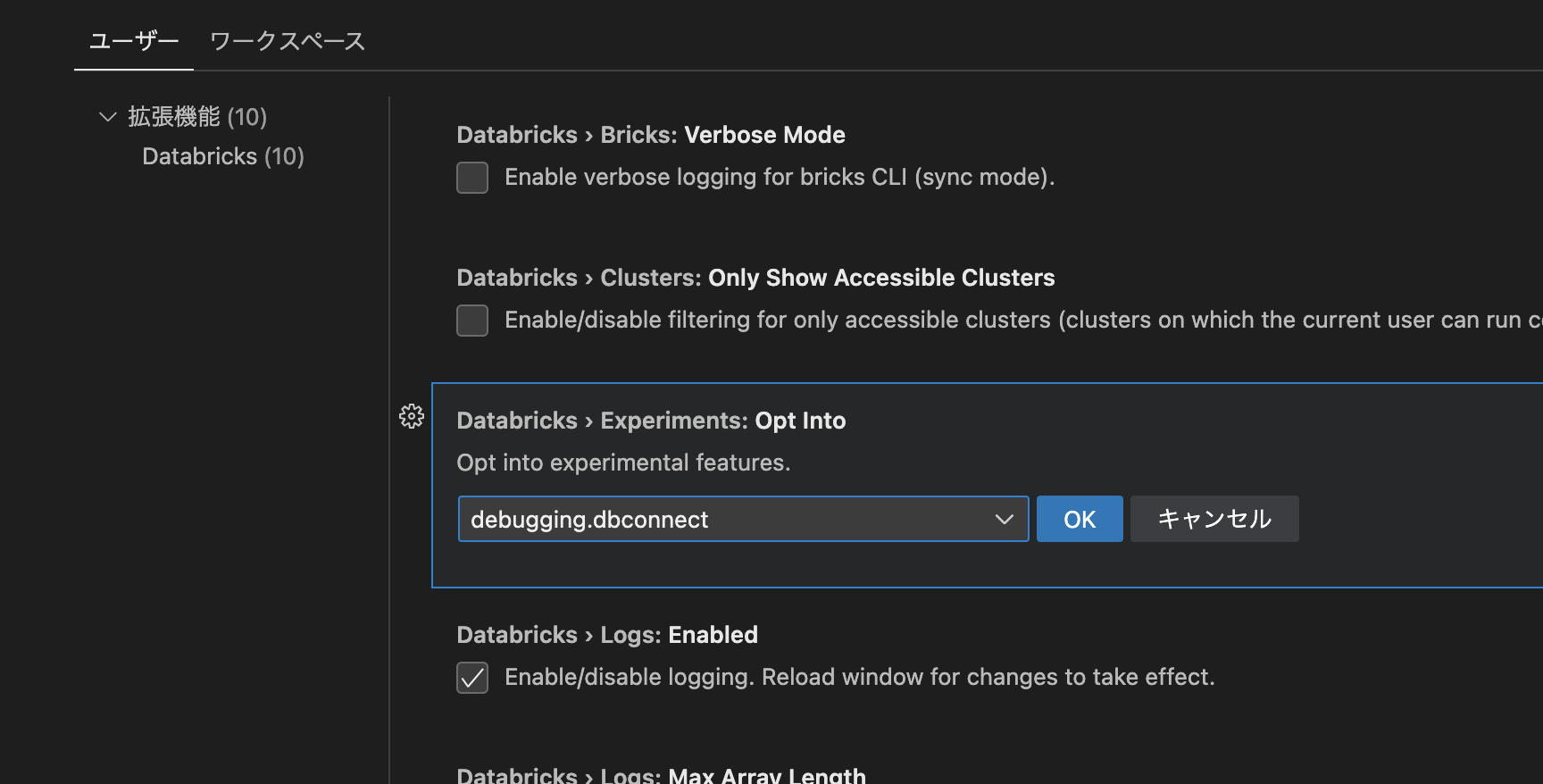
VSCodeのExtensionの設定画面にて、debugging.dbconnectを追加します。
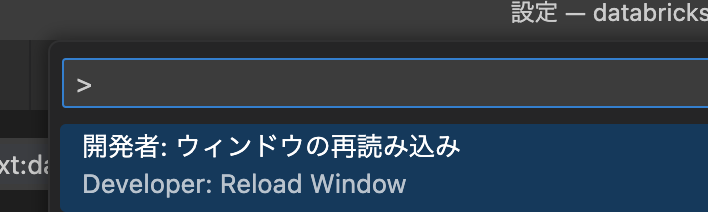
「表示」ー「コマンドパレット」にて、Reload Window を実行してリロードする
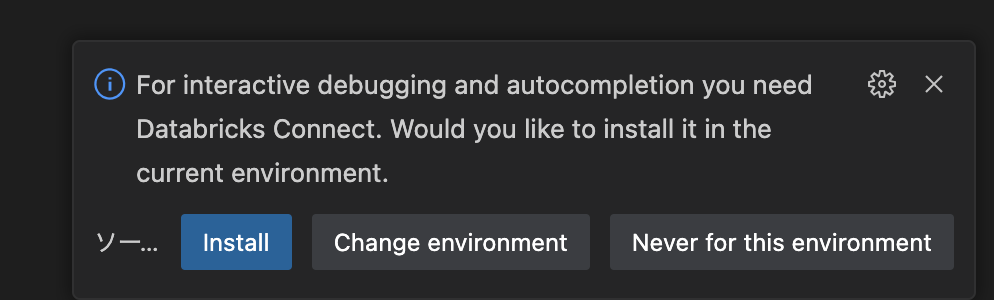
VSCodeの左下に以下のような赤いメッセージが表示されるので、これをクリックする
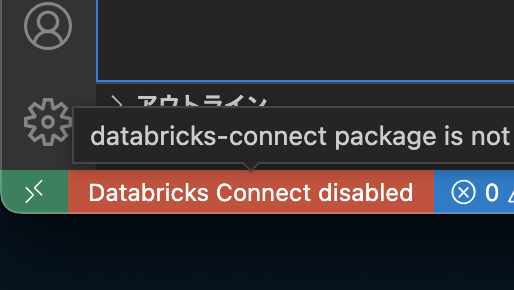
databricks connectを installするかどうかメッセージが出てくるので、installする
(venv環境にactivateした後に実行する)
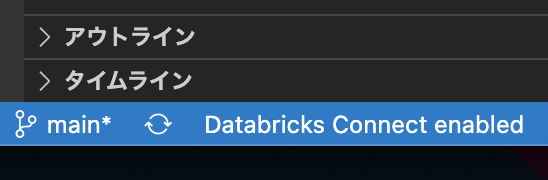
有効になっていると以下のように enableと表示されます。
設定は以上です。
コード上の注意
dbconnectを利用してdebugするためには、コード上で以下のように追加してあげる必要があります。(Databricks Notebook上で実行する場合は、このような記述は不要だがDB Connectを利用する際には必要)
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
デバッグの実行
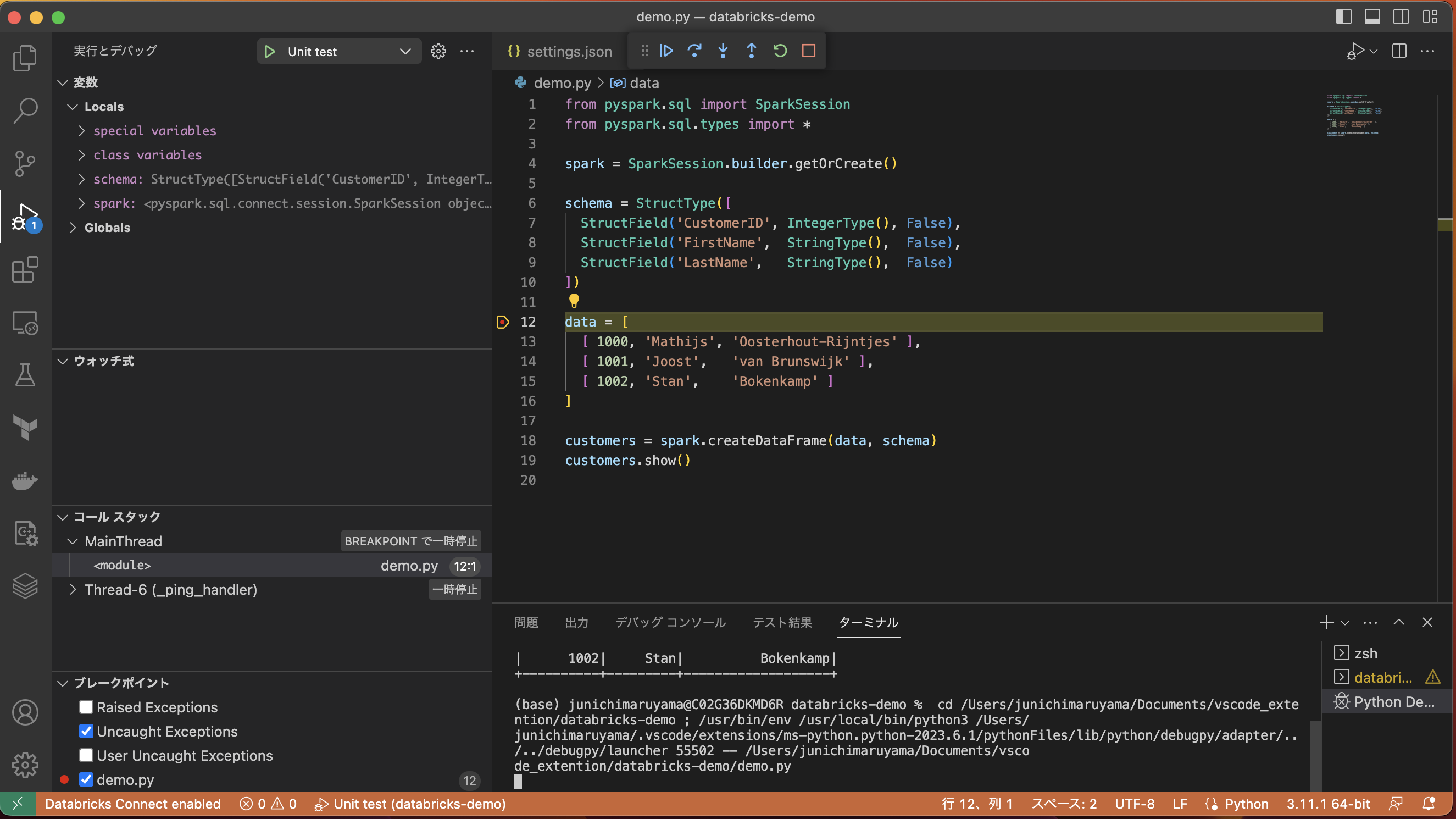
それではDBR13以降のクラスターをアタッチして、コードをDebugしてみよう。
今回は以下のコードを実行
from pyspark.sql import SparkSession
from pyspark.sql.types import *
spark = SparkSession.builder.getOrCreate()
schema = StructType([
StructField('CustomerID', IntegerType(), False),
StructField('FirstName', StringType(), False),
StructField('LastName', StringType(), False)
])
data = [
[ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ],
[ 1001, 'Joost', 'van Brunswijk' ],
[ 1002, 'Stan', 'Bokenkamp' ]
]
customers = spark.createDataFrame(data, schema)
customers.show()
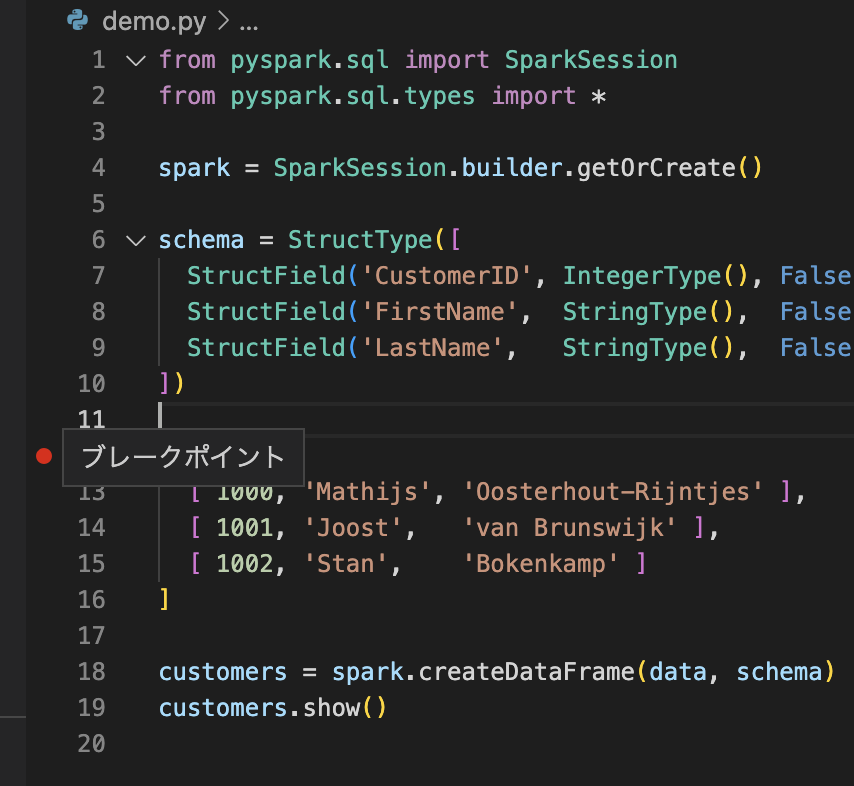
まずは、ブレークポイントを作成
右上のドロップダウンから、Pythonファイルのデバッグを実行
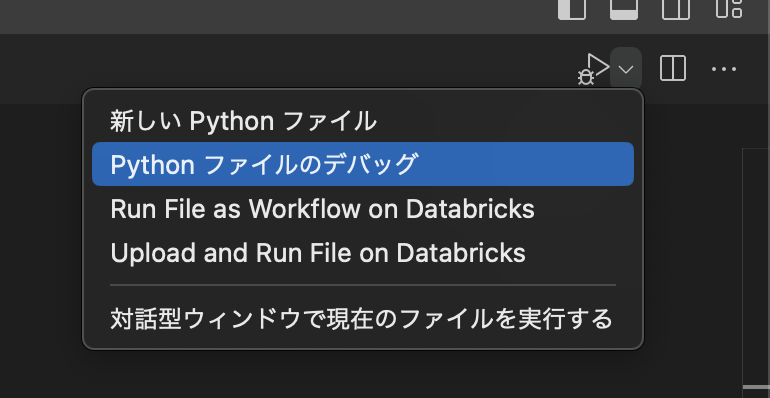
ちゃんと機能してますね。
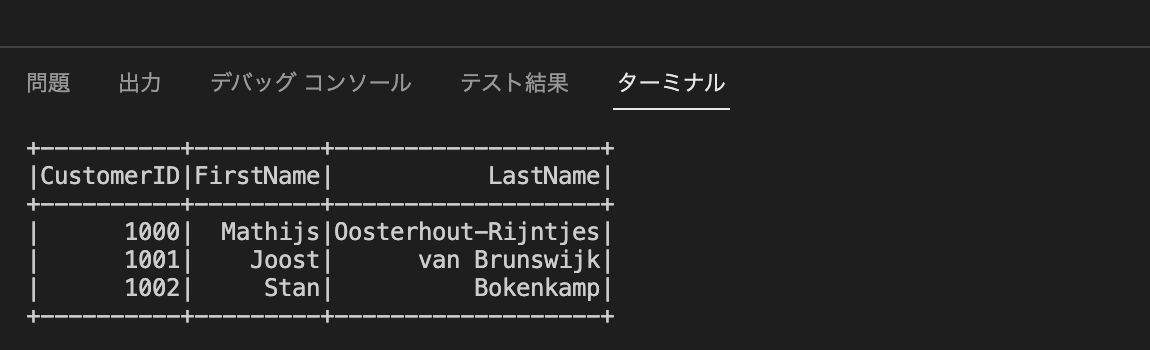
そのまま実行を続けると、最終的な結果がコンソールに表示
是非、お試しください。