5日間でSEO構造化データ自動生成ツールを作った話【Gemini 2.0 × Next.js】
はじめに
こんにちは!今回、URLを入力するだけでSchema.org準拠のJSON-LD構造化データを自動生成するツールを5日間で開発しました。
完成品はこちら:
https://schema-generator-one.vercel.app/
本記事では、開発の経緯から技術的な課題、特に苦労した「sameAs厳格化」の実装まで、開発ストーリーをお届けします。
完成品の紹介
デモ
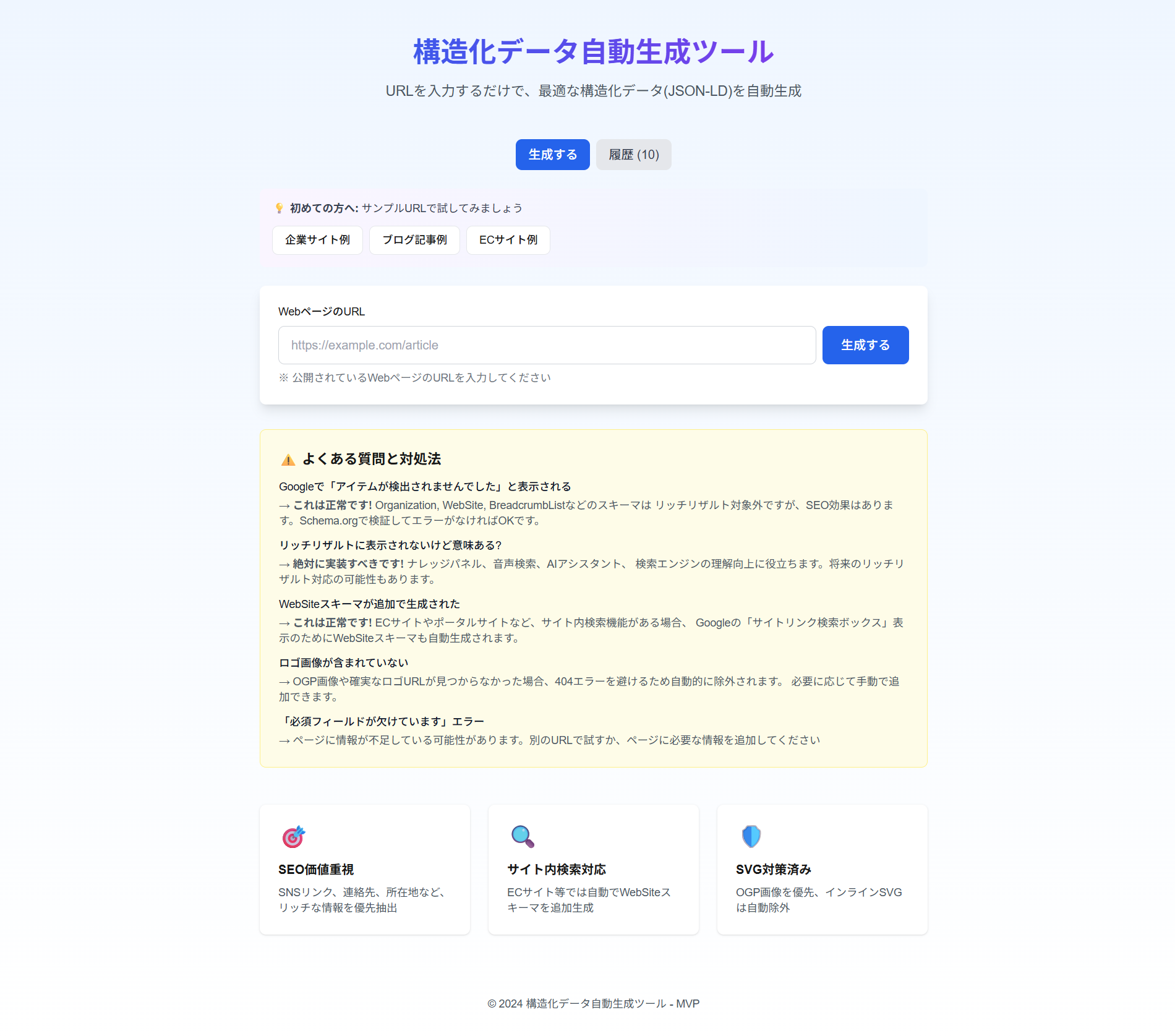
主な機能
- URLを入力するだけで自動生成: ページを解析し、最適なスキーマタイプを自動判定
-
対応スキーマ:
- 完全対応: Organization (企業サイト), WebSite (サイト内検索)
- 対応: Article (ブログ・ニュース記事)
- 近日対応予定: Product (商品ページ), FAQ
- SEO価値重視: SNSリンク(sameAs)、連絡先、所在地を優先抽出
- 検証ツール連携: Googleリッチリザルトテスト、Schema.org Validatorへ直接連携
- 生成履歴: 過去10件の生成履歴を保存
技術スタック
- フロントエンド: Next.js 14 (App Router), TypeScript, Tailwind CSS
- AI API: Gemini 2.0 Flash
- デプロイ: Vercel
- コスト: 完全無料 (Gemini無料枠 + Vercel Hobby)
なぜこのツールを作ったか
構造化データの重要性
構造化データは、Googleなどの検索エンジンがページ内容を理解するための重要な情報です。正しく実装すれば:
- リッチリザルト表示(記事、商品、FAQ等)
- ナレッジパネルの情報充実
- 音声検索の精度向上
- AIアシスタントへの情報提供
といったSEO効果が期待できます。
既存ツールの課題
しかし、構造化データの作成は面倒です:
- 手動作成: 時間がかかり、ミスが発生しやすい
- 既存ツール: 手動入力が多く、日本語対応が不十分
- 有料ツール: 海外製で高額($49/月〜)
「URLを貼るだけで自動生成」できるツールがあれば便利だと思い、開発を決意しました。
開発の流れ
Day 1-2: MVP開発
まずは基本機能の実装です。
実装内容:
- Next.js + Gemini API統合
- Organization、Articleスキーマ対応
- 基本的なUI
初期のプロンプト設計:
const prompt = `
以下のHTMLから、Schema.org準拠のJSON-LD構造化データを生成してください。
HTMLコンテンツ:
${html}
Organizationの場合、以下のプロパティを含めてください:
- name: 企業名
- url: サイトURL
- logo: ロゴ画像
...
`;
この段階では、基本的な生成はできるものの、抽出精度が低く、エラーも多発していました。
Day 3: SEO最適化
ここでGeminiに相談しながら、SEO価値を高める改善を実施しました。
主な改善:
- sameAs (SNSリンク)の優先抽出
構造化データで最も重要なのは、実はsameAsです。これは企業の公式SNSアカウントへのリンクで、Googleがエンティティ(企業や人物)を特定するために使用します。
プロンプトに以下を追加:
- **sameAs (必須・超重要):**
- SNS公式アカウント、Wikipedia、公式の外部サイトへのリンクを優先的に抽出
- Twitter/X, LinkedIn, Facebook, YouTube等
- OGP画像の優先抽出
ロゴ画像の抽出で404エラーが頻発していたため、OGP画像(og:image)を優先的に使用する方針に変更:
- **logo (推奨):**
- まず、HTMLの `<meta property="og:image">` からOGP画像を抽出
- OGP画像がない、または不適切な場合のみ、`<img>` タグから企業ロゴを探す
- インラインSVGの除外
インラインSVG(data:image/svg...)を含めると404エラーになるため、自動除外:
- **⚠️ インラインSVGは絶対に使用しない**
(data:image/svg... で始まるURLは除外)
これらの改善で、生成精度が大幅に向上しました。
Day 4: WebSite対応
ECサイトなど、サイト内検索機能があるサイトでは、WebSiteスキーマも追加生成することで、Googleの「サイトリンク検索ボックス」表示に対応できます。
実装:
### WebSite (検索機能があるサイト)
- **@type:** "WebSite"
- **name:** サイト名
- **url:** 入力されたURL
- **potentialAction:**
- **@type:** "SearchAction"
- **target:**
- **@type:** "EntryPoint"
- **urlTemplate:** 検索URLパターン
(例: "https://example.com/search?q={search_term_string}")
サイトの検索URL構造を自動解析し、SearchActionを設定します。
Day 5: sameAs厳格化(最難関)
ここで最大の課題に直面しました。
最大の課題: sameAs厳格化
問題発覚
Anthropic社のサイトで生成テストしたところ、以下の結果に:
"sameAs": [
"https://www.anthropic.com/", // ← 自分自身のURL!
"https://claude.ai/",
"https://twitter.com/AnthropicAI"
]
自分自身のURLがsameAsに含まれてしまっていました。
なぜ問題なのか
sameAsは「外部の権威あるソースへのリンク」を示すプロパティです。自分自身のURLを含めると:
- Schema.orgの定義から逸脱
- Googleがエンティティを正しく理解できない
- E-E-A-T(専門性・権威性・信頼性)の評価が下がる
解決策の試行錯誤
最初は単純に「入力URLと同じ値を除外」と指示していました:
- **sameAs:**
- 入力されたURL (${url}) と同じ値を含めないこと
しかし、これだけでは不十分でした。なぜなら:
-
https://www.anthropic.com/(入力URL) -
https://www.anthropic.com(末尾スラッシュなし) -
https://anthropic.com/(wwwなし) -
https://anthropic.com(両方なし)
これらは実質的に同じURLですが、文字列として完全一致しないため、除外されませんでした。
最終的な解決策
Geminiと相談しながら、以下の厳格な比較ルールを追加:
- **🚨 厳格な除外ルール:**
* 抽出した各URLが、入力されたサイトのメインURL (${url}) と
完全に一致していないか検証すること
* 末尾のスラッシュ (`/`) の有無、`www` の有無を無視して比較
* 実質的に同一URLであれば必ず除外すること
* 例: 入力URLが `https://www.anthropic.com/` の場合、
以下は全て除外:
- `https://www.anthropic.com/`
- `https://www.anthropic.com`
- `https://anthropic.com/`
- `https://anthropic.com`
結果
修正後、再度Anthropicサイトでテスト:
"sameAs": [
"https://twitter.com/AnthropicAI" // ✅ 外部リンクのみ!
]
完璧に動作しました! 🎉
この厳格な比較ルールにより、どんなサイトでも自己参照URLを確実に除外できるようになりました。
現在の対応状況
完全対応
Organization (企業・組織サイト)
- 企業サイト、団体サイトに最適
- sameAs厳格化により、自己参照URL問題を完全解決
- SNSリンク、連絡先、所在地など、SEO価値の高い情報を優先抽出
WebSite (サイト内検索)
- ECサイト、ポータルサイトのサイト内検索に対応
- SearchAction設定により、Googleの「サイトリンク検索ボックス」表示を実現
実用レベル
Article (ブログ・ニュース記事)
- note, Zenn, Qiita等で動作確認済み
- 必須フィールド(headline, author, datePublished等)を正確に抽出
- 一部サイトでheadlineが長くなる場合があるが、Google的には許容範囲
近日対応予定
Product (商品ページ)
現在、商品ページでもOrganizationスキーマが生成される課題があります。これは判定ロジックの優先順位の問題で、技術的には解決可能です。
修正方針:
- ページの主要コンテンツ(価格、在庫、商品説明)を先に判定
- Productスキーマをメインとして生成
- 企業情報があればOrganizationも追加生成
対応予定: 数日以内に修正し、本記事に追記予定です。
FAQ (よくある質問ページ)
- プロンプト実装済み
- 検証が完了次第、正式対応
技術的な学び
1. Gemini APIとの協業
開発中、Gemini本人に相談しながら進めたのが非常に効果的でした。
- Schema.orgの仕様についてGeminiが詳しい
- プロンプト設計のフィードバックをもらえる
- 実際の生成結果を見てもらい、改善提案をもらう
特に「sameAs厳格化」は、Geminiからの提案がなければ実現できませんでした。
2. プロンプトエンジニアリングの重要性
LLMを使った開発では、プロンプト設計が9割です。
良いプロンプトの条件:
- 具体的な指示(「〜を含める」より「〜を優先的に抽出」)
- エッジケースを明示(「〜の場合は除外」)
- 出力形式を厳密に指定(JSON構造を例示)
今回は7回のバージョンアップで、プロンプトを段階的に改善していきました。
3. JSON出力モードの活用
Gemini 2.0ではresponseMimeType: "application/json"を指定できます:
const model = genAI.getGenerativeModel({
model: "gemini-2.0-flash",
generationConfig: {
temperature: 0.2,
responseMimeType: "application/json",
},
});
これにより、JSONパースエラーが大幅に減少しました。
コスト・運用
完全無料運用
使用サービス:
- Gemini API: 無料枠 (1日1,500回、月45,000回)
- Vercel: Hobby プラン (無料)
月間予想:
- 想定ユーザー: 500人
- 1人あたり使用回数: 月3回
- 合計: 1,500回/月
→ 完全に無料枠で運用可能!
有料化する場合の試算
将来的にユーザーが増えた場合:
Gemini 2.0 Flash 料金:
- 入力: $0.075 / 100万トークン
- 出力: $0.30 / 100万トークン
1リクエストあたり:
- 入力: 2,000トークン ($0.00015)
- 出力: 1,000トークン ($0.0003)
- 合計: 約¥0.07
月10,000リクエストでも約¥700
非常に低コストでスケール可能です。
苦労した点まとめ
- sameAs厳格化: 最も時間がかかったが、最も重要な改善
- 画像URL抽出: OGP優先、SVG除外のロジック確立
- JSONパースエラー: Geminiの出力がたまにマークダウン形式になる
- WebSite判定: 検索URL構造の自動解析ロジック
今後の展開
Phase 1: 直近の改善 (数日〜1週間)
- Product対応: 商品ページの判定ロジック改善
- FAQ対応: 検証完了次第、正式対応
- 初期ユーザーからのフィードバック対応
Phase 2: フィードバック収集 (0-3ヶ月)
- ユーザーの使い方を観察
- バグ修正、UI/UX改善
- 要望の多い機能を優先実装
Phase 3: 機能拡張 (3-6ヶ月)
- 一括生成機能 (sitemap.xml対応)
- 複数スキーマタイプの同時生成
- カスタムスキーマ対応
Phase 4: マネタイズ検討 (6ヶ月〜)
- 無料プラン: 月10回
- 有料プラン: ¥1,980/月 (月100回)
- WordPress/Shopifyプラグイン開発
まとめ
5日間の開発で学んだこと:
- LLM×個人開発の可能性: Gemini APIで高度な機能を短期間で実装
- プロンプト設計の重要性: 7回の改善で精度が大幅向上
- Geminiとの協業: AIに相談しながら開発する新しいスタイル
- コスト効率: 無料枠で月45,000回まで対応可能
特にsameAs厳格化の実装は、単なる「動くツール」から「SEOの専門知識を反映した高品質なツール」へのステップアップでした。
完全無料で公開していますので、ぜひ使ってみてください!
ツールURL:
https://schema-generator-one.vercel.app/
GitHubリポジトリ:
https://github.com/sonicdaydream/schema-generator
フィードバックや改善提案など、お待ちしています!
📝 追記予定
Product対応(商品ページ)の実装が完了次第、本記事に追記します。数日以内を予定していますので、続報をお待ちください!
参考資料
最後まで読んでいただき、ありがとうございました!
いいねやストック、コメントいただけると嬉しいです😊