概要
初投稿です。
G検定で出ると噂の畳み込み計算をなんとか自働化できないかとチャレンジしました。
こんなの人間ががんばる計算ではないと思います。
内部的には
- PySimpleGUI (本当はKivyを使いたかった)
- OpenCVを使用したマウスドラッグによる領域指定
- TesseractOCRによる文字認識
をなど使用していますので、これら個別にも参考になれたらなと思います。
win32apiを使用しているのでそのままではUNIXでは動かないです。
Kivyの方がかっこいいし慣れているのでそっちを使いたかったのですが、勉強のためにPySimpleGUIを使ってみました。
でもKivyはモダンでクールなのでお勧めです。
必要モジュール
- PySimpleGUI
- numpy
- opencv
- scipy
- pywin32
- pyocr
バージョン依存はないと思います。
あとTesseractOCRを別途インストールして環境変数に追加する必要があります。
使い方
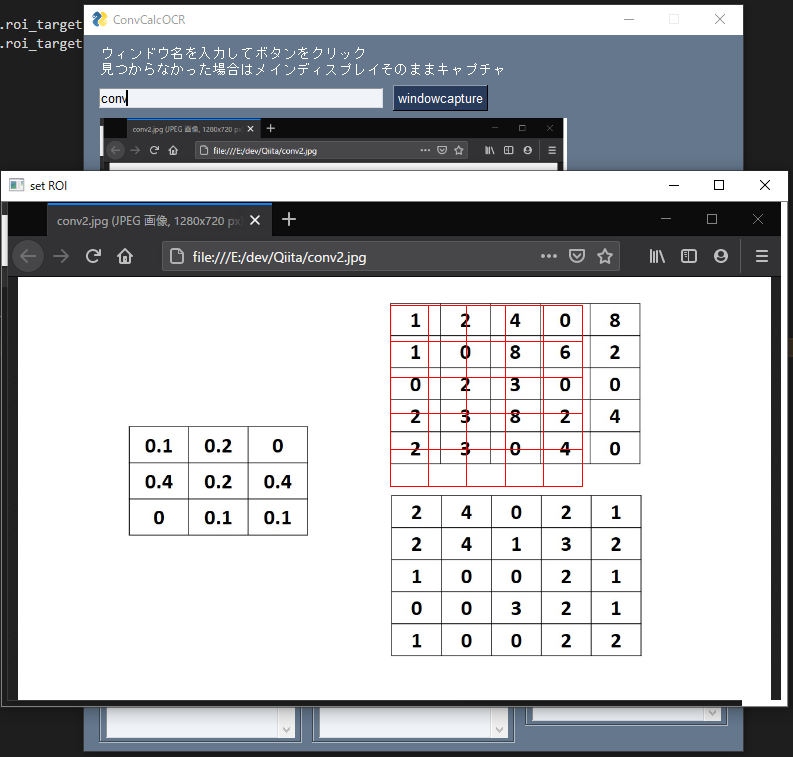
- 読み取りたい対象のウィンドウ名を上の欄に入力し、右のボタンを押すと画面が右下に表示される。Chrome内のタブ名を入力しても黒い画面が出るので、Firefox内のタブ名を入力した方がいいです。(ChromeDriverが無いとアクセスできない?)
- filterボタンを押すとポップアップが出るので、グリッドが合うように畳み込みフィルター部分を選択する。
- targetボタンで畳み込みしたい対象を選択する。
- 各テキストボックスの読み取った数値が間違っていたら修正する。 (割と誤判定する)
- calculateボタンを押すと畳み込み計算結果が表示される。
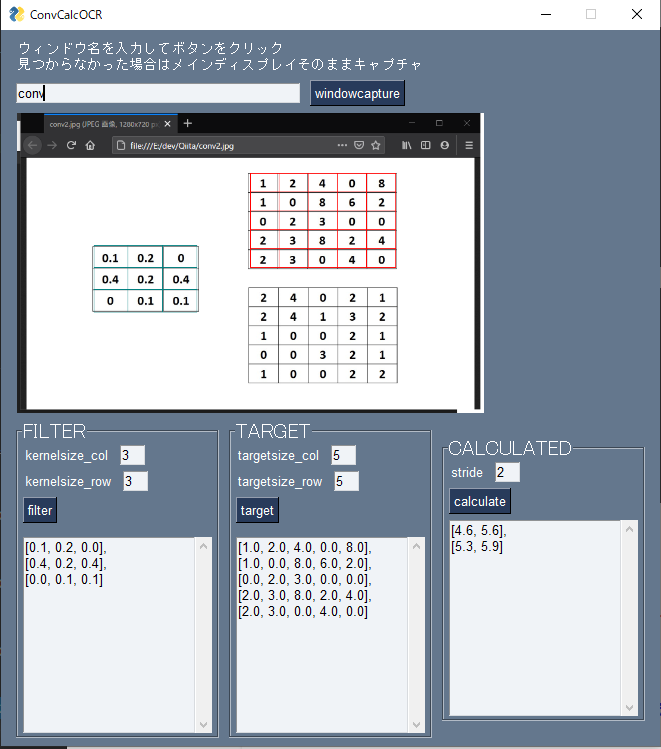
テスト用画像(Firefoxで開いてください)
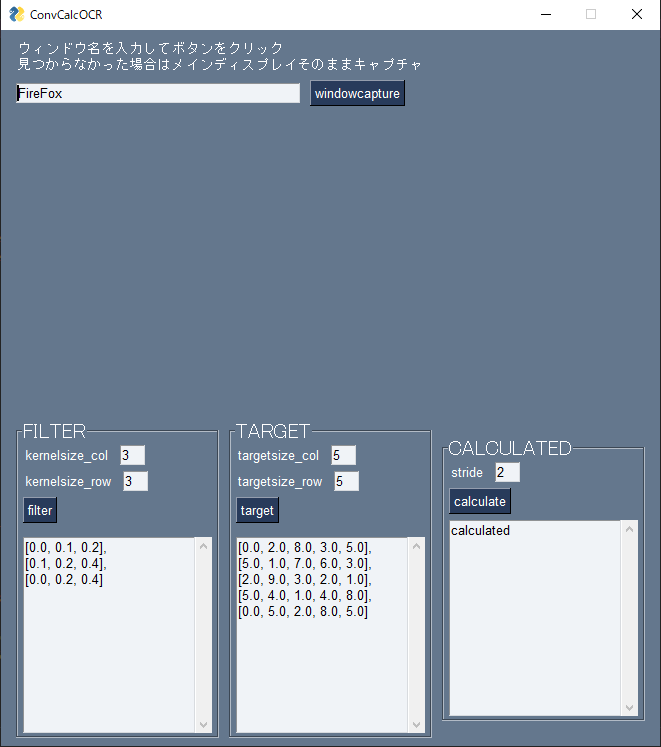
外観部分
PySimpleGUIでGUI部分を作ってます。
redefine_rectangle関数とdraw_shape関数はマウスドラッグで座標を取得する際の参考になるかもしれません。
import sys
import PySimpleGUI as sg
import numpy as np
import cv2
import win32gui
import win32ui
import win32con
import pyocr
import re
from PIL import Image
from scipy import signal
# win32apiを使用しているのでそのままではunixでは動かないです
class ConvCalc():
def __init__(self, **kwargs):
self.drawing = False
self.flag_drawing = False
self.flag_filter = True
self.roi_filter = [[0, 0], [50, 50]]
self.roi_target = [[0, 0], [50, 50]]
self.roi_temp = [[0, 0], [50, 50]]
self.image_filter = np.zeros((300, 300, 3), np.uint8)
self.image_target = np.zeros((300, 300, 3), np.uint8)
self.image_capture = np.zeros((300, 300, 3), np.uint8)
self.image_copy = np.zeros((300, 300, 3), np.uint8)
self.tool = None
# 矩形選択開始
def redefine_rectangle(self, cols, rows, color):
cv2.namedWindow("set ROI")
cv2.setMouseCallback("set ROI", self.draw_shape)
self.flag_drawing = True
while 1:
image_rect = rectangle_grid(self.image_copy.copy(),
tuple(self.roi_filter[0] if self.flag_filter else self.roi_target[0]),
tuple(self.roi_filter[1] if self.flag_filter else self.roi_target[1]),
color,
cols, rows,
1)
cv2.imshow("set ROI", image_rect)
cv2.waitKey(1)
# ×ボタン検知
ret = cv2.getWindowProperty('set ROI', cv2.WND_PROP_ASPECT_RATIO)
# 書き終わるか×ボタンでbreak ばつボタンは処理しないようにしようかな
if not self.flag_drawing or ret == -1.0:
# 分割画像作成
divided_image = divide_image(self.image_copy, self.roi_filter if self.flag_filter else self.roi_target, cols, rows, 0.08)
score_list = []
for c, divided in enumerate(divided_image):
txt = self.tool.image_to_string(
Image.fromarray(cv2.cvtColor(divided, cv2.COLOR_BGR2RGB)),
lang="eng",
# builder=pyocr.builders.TextBuilder(tesseract_layout=6),
builder=pyocr.tesseract.DigitBuilder(tesseract_layout=6),
)
score_list.append(float(fix_num(txt)))
# rowcolの次元にreshape
score_list_reshaped = fix_textbox(score_list, rows, cols)
# 認識した数値を反映
if self.flag_filter:
self.image_filter = image_rect
self.window['filterarray'].update(score_list_reshaped)
else:
self.image_target = image_rect
self.window['targetarray'].update(score_list_reshaped)
break
# 最終的な範囲を描画
self.image_capture = rectangle_grid(self.image_target.copy() if self.flag_filter else self.image_filter.copy(),
tuple(self.roi_filter[0] if self.flag_filter else self.roi_target[0]),
tuple(self.roi_filter[1] if self.flag_filter else self.roi_target[1]),
color,
cols, rows,
1)
cv2.destroyWindow("set ROI")
# サイズ0の時エラー出ないように気遣いながら描画する
def draw_shape(self, event, x, y, flag, param):
if event == cv2.EVENT_LBUTTONDOWN:
self.drawing = True
self.roi_temp[0][1] = y
self.roi_temp[0][0] = x
elif event == cv2.EVENT_MOUSEMOVE:
if self.flag_filter: # もっとスマートな方法ないですか?
if not (self.roi_filter[0][0] == x or self.roi_filter[0][1] == y) and self.drawing == True:
self.roi_filter = fix_coordinate(self.roi_temp[0][1], self.roi_temp[0][0], y, x)
else:
if not (self.roi_target[0][0] == x or self.roi_target[0][1] == y) and self.drawing == True:
self.roi_target = fix_coordinate(self.roi_temp[0][1], self.roi_temp[0][0], y, x)
elif event == cv2.EVENT_LBUTTONUP:
self.drawing = False
if self.flag_filter:
if not (self.roi_filter[0][0] == x or self.roi_filter[0][1] == y):
self.roi_filter = fix_coordinate(self.roi_temp[0][1], self.roi_temp[0][0], y, x)
else:
if not (self.roi_target[0][0] == x or self.roi_target[0][1] == y):
self.roi_target = fix_coordinate(self.roi_temp[0][1], self.roi_temp[0][0], y, x)
self.flag_drawing = False
# https://qiita.com/dario_okazaki/items/656de21cab5c81cabe59
def main(self):
# セクション1 - オプションの設定と標準レイアウト
sg.theme('Dark Blue 3')
# filter frame
filter_box = sg.Frame('FILTER', font='Any 15', layout=[
[sg.Text('kernelsize_col'), sg.Input("3", size=(3,None), key='kernelsize_0')],
[sg.Text('kernelsize_row'), sg.Input("3", size=(3,None), key='kernelsize_1')],
[sg.Button('filter', key='filter')],
[sg.Image(filename='', key='image_filter')],
[sg.Multiline('[0.0, 0.1, 0.2],\n[0.1, 0.2, 0.4],\n[0.0, 0.2, 0.4]', size=(24, 12), key='filterarray')],
])
target_box = sg.Frame('TARGET', font='Any 15', layout=[
[sg.Text('targetsize_col'), sg.Input("5", size=(3,None), key='targetsize_0')],
[sg.Text('targetsize_row'), sg.Input("5", size=(3,None), key='targetsize_1')],
[sg.Button('target', key='target')],
[sg.Image(filename='', key='image_target')],
[sg.Multiline('[0.0, 2.0, 8.0, 3.0, 5.0],\n[5.0, 1.0, 7.0, 6.0, 3.0],\n[2.0, 9.0, 3.0, 2.0, 1.0],\n[5.0, 4.0, 1.0, 4.0, 8.0],\n[0.0, 5.0, 2.0, 8.0, 5.0]',size=(24, 12), key='targetarray')],
])
calculated_box = sg.Frame('CALCULATED', font='Any 15', layout=[
[sg.Text('stride'), sg.Input("2", size=(3,None), key='stride')],
[sg.Button('calculate', key='calculate')],
[sg.Multiline('calculated',size=(24, 12),key='text_calculated')],
])
layout = [
# [sg.Text('Type the window name and press the button to capture it.\nIf it couldnt find the one, it will capture a whole area of a primary display.')],
[sg.Text('ウィンドウ名を入力してボタンをクリック\n見つからなかった場合はメインディスプレイそのままキャプチャ')],
[sg.Input("FireFox", size=(40,None), key='windowname'), sg.Button('windowcapture', key='windowcapture')],
[sg.Image(filename='', key='image_capture', size=(600,300), )],
[filter_box, target_box, calculated_box],
]
# セクション 2 - ウィンドウの生成
self.window = sg.Window('ConvCalcOCR', layout)
# init OCR
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
self.tool = tools[0]
print("Will use tool '%s'" % (self.tool.get_name()))
# セクション 3 - イベントループ
while True:
event, values = self.window.read()
if event is None:
print('exit')
break
elif event == 'windowcapture':
self.image_capture = cv2.cvtColor(WindowCapture(values['windowname']), cv2.COLOR_BGRA2BGR)
self.image_copy = self.image_target = self.image_filter = self.image_capture.copy()
img = scale_box(self.image_capture, 600, 300)
imgbytes = cv2.imencode('.png', img)[1].tobytes()
self.window['image_capture'].update(data=imgbytes)
elif event == 'filter':
self.flag_filter = True # もっとスマートな方法ないですか?
self.redefine_rectangle(int(values['kernelsize_0']), int(values['kernelsize_1']), (128, 128, 0))
img = scale_box(self.image_capture, 600, 300)
imgbytes = cv2.imencode('.png', img)[1].tobytes()
self.window['image_capture'].update(data=imgbytes)
elif event == 'target':
self.flag_filter = False
self.redefine_rectangle(int(values['targetsize_0']), int(values['targetsize_1']), (0, 0, 255))
img = scale_box(self.image_capture, 600, 300)
imgbytes = cv2.imencode('.png', img)[1].tobytes()
self.window['image_capture'].update(data=imgbytes)
elif event == 'calculate':
calculated = strideConv(values['targetarray'], values['filterarray'], int(values['stride']))
calculated = np.round(calculated, decimals=2) # 計算誤差で小数点以下が多くなることがあるため
calculated_shape = np.array(calculated).shape
self.window['text_calculated'].update(fix_textbox(calculated.tolist(), calculated_shape[0], calculated_shape[1]))
# セクション 4 - ウィンドウの破棄と終了
self.window.close()
実行結果
グリッド型の矩形描画
マウスドラッグした範囲を合わせやすいようにグリッド付きで描画する
# グリッド付き長方形
def rectangle_grid(img, pt1, pt2, color, cols, rows, thickness=1, lineType=cv2.LINE_8, shift=None):
space_x = abs(pt2[0] - pt1[0]) / cols
space_y = abs(pt2[1] - pt1[1]) / rows
for col in range(cols+1):
img = cv2.line(img, (int(pt1[0]+col*space_x), pt1[1]), (int(pt1[0]+col*space_x), pt2[1]), color, thickness, lineType)
for row in range(rows+1):
img = cv2.line(img, (pt1[0], int(pt1[1]+row*space_y)), (pt2[0], int(pt1[1]+row*space_y)), color, thickness, lineType)
return img
マウスドラッグによる範囲指定の補正
マウスドラッグで範囲を指定する際には、描画し始めに画像サイズが0になり発生するエラーや座標計算時の足し引きでマイナスにならないようにする (参考にしたページメモしてませんでした。すみません。)
# マイナス座標対応
def fix_coordinate(iy, ix, y, x):
x_sorted = sorted([ix, x])
y_sorted = sorted([iy, y])
# relu
return [[np.maximum(0, x_sorted[0]), np.maximum(0, y_sorted[0])],
[np.maximum(0, x_sorted[1]), np.maximum(0, y_sorted[1])]]
画像分割
画像を任意の数分割し、ついでにeroderatio割合だけ周囲を削ることで問題文中の表の枠線を画像から削除する
# 画像分割
def divide_image(image, roi, cols, rows, eroderatio):
# クロップ
cropped = image[roi[0][1]:roi[1][1], roi[0][0]:roi[1][0]]
# https://pystyle.info/opencv-split-and-concat-images/
chunks = []
for row_cropped in np.array_split(cropped, rows, axis=0):
for chunk in np.array_split(row_cropped, cols, axis=1):
# 文字と判定してしまいがちな枠線削除
erode = int(eroderatio*min(chunk.shape[:2]))
chunk = chunk[erode:chunk.shape[0]-erode, erode:chunk.shape[1]-erode]
chunks.append(chunk)
return chunks
読み取った数値の修正
「.」や「-」などが正常に読み取れないことが多いため、これらは一旦無視しG検定では整数部は1桁のみと仮定して整形する
# 整数部は1桁だと仮定して整形
def fix_num(num):
fixed_num = re.sub("\\D", "", num) # 数字以外削除
if fixed_num == '' or fixed_num == '-': # "-"が数字扱いになってた
return 0.0
else:
fixed_num = fixed_num[0] + '.' + fixed_num[1:]
return fixed_num
読み取った数値の画面表示
OCRで読み取った数値のListには改行がなくそのままでは表示が崩れるため、分解して改行コードを挿し込む。
# 表示部用の整形
def fix_textbox(score_list, rows, cols):
score_array = np.reshape(np.array(score_list), (rows, cols))
score_list_reshaped= ["{}".format(l) for l in score_array.tolist()]
return ',\n'.join(score_list_reshaped)
畳み込み計算
OCRで読み取った数値は、画面表示用にListの括弧を消してあるので戻してからscipyで計算する
# 畳み込み計算
# https://stackoverflow.com/questions/48097941/strided-convolution-of-2d-in-numpy/48098534
def strideConv(v1, v2, s):
arr = np.array(eval('[' + v1 + ']'))
arr2 = np.array(eval('[' + v2 + ']'))
return signal.convolve2d(arr, arr2[::-1, ::-1], mode='valid')[::s, ::s]
コード全体
import sys
import PySimpleGUI as sg
import numpy as np
import cv2
import win32gui
import win32ui
import win32con
import pyocr
import re
from PIL import Image
from scipy import signal
# win32apiを使用しているのでそのままではunixでは動かないです
class ConvCalc():
def __init__(self, **kwargs):
self.drawing = False
self.flag_drawing = False
self.flag_filter = True
self.roi_filter = [[0, 0], [50, 50]]
self.roi_target = [[0, 0], [50, 50]]
self.roi_temp = [[0, 0], [50, 50]]
self.image_filter = np.zeros((300, 300, 3), np.uint8)
self.image_target = np.zeros((300, 300, 3), np.uint8)
self.image_capture = np.zeros((300, 300, 3), np.uint8)
self.image_copy = np.zeros((300, 300, 3), np.uint8)
self.tool = None
# 矩形選択開始
def redefine_rectangle(self, cols, rows, color):
cv2.namedWindow("set ROI")
cv2.setMouseCallback("set ROI", self.draw_shape)
self.flag_drawing = True
while 1:
image_rect = rectangle_grid(self.image_copy.copy(),
tuple(self.roi_filter[0] if self.flag_filter else self.roi_target[0]),
tuple(self.roi_filter[1] if self.flag_filter else self.roi_target[1]),
color,
cols, rows,
1)
cv2.imshow("set ROI", image_rect)
cv2.waitKey(1)
# ×ボタン検知
ret = cv2.getWindowProperty('set ROI', cv2.WND_PROP_ASPECT_RATIO)
# 書き終わるか×ボタンでbreak ばつボタンは処理しないようにしようかな
if not self.flag_drawing or ret == -1.0:
# 分割画像作成
divided_image = divide_image(self.image_copy, self.roi_filter if self.flag_filter else self.roi_target, cols, rows, 0.08)
score_list = []
for c, divided in enumerate(divided_image):
txt = self.tool.image_to_string(
Image.fromarray(cv2.cvtColor(divided, cv2.COLOR_BGR2RGB)),
lang="eng",
# builder=pyocr.builders.TextBuilder(tesseract_layout=6),
builder=pyocr.tesseract.DigitBuilder(tesseract_layout=6),
)
score_list.append(float(fix_num(txt)))
# rowcolの次元にreshape
score_list_reshaped = fix_textbox(score_list, rows, cols)
# 認識した数値を反映
if self.flag_filter:
self.image_filter = image_rect
self.window['filterarray'].update(score_list_reshaped)
else:
self.image_target = image_rect
self.window['targetarray'].update(score_list_reshaped)
break
# 最終的な範囲を描画
self.image_capture = rectangle_grid(self.image_target.copy() if self.flag_filter else self.image_filter.copy(),
tuple(self.roi_filter[0] if self.flag_filter else self.roi_target[0]),
tuple(self.roi_filter[1] if self.flag_filter else self.roi_target[1]),
color,
cols, rows,
1)
cv2.destroyWindow("set ROI")
# サイズ0の時エラー出ないように気遣いながら描画する
def draw_shape(self, event, x, y, flag, param):
if event == cv2.EVENT_LBUTTONDOWN:
self.drawing = True
self.roi_temp[0][1] = y
self.roi_temp[0][0] = x
elif event == cv2.EVENT_MOUSEMOVE:
if self.flag_filter: # もっとスマートな方法ないですか?
if not (self.roi_filter[0][0] == x or self.roi_filter[0][1] == y) and self.drawing == True:
self.roi_filter = fix_coordinate(self.roi_temp[0][1], self.roi_temp[0][0], y, x)
else:
if not (self.roi_target[0][0] == x or self.roi_target[0][1] == y) and self.drawing == True:
self.roi_target = fix_coordinate(self.roi_temp[0][1], self.roi_temp[0][0], y, x)
elif event == cv2.EVENT_LBUTTONUP:
self.drawing = False
if self.flag_filter:
if not (self.roi_filter[0][0] == x or self.roi_filter[0][1] == y):
self.roi_filter = fix_coordinate(self.roi_temp[0][1], self.roi_temp[0][0], y, x)
else:
if not (self.roi_target[0][0] == x or self.roi_target[0][1] == y):
self.roi_target = fix_coordinate(self.roi_temp[0][1], self.roi_temp[0][0], y, x)
self.flag_drawing = False
# https://qiita.com/dario_okazaki/items/656de21cab5c81cabe59
def main(self):
# セクション1 - オプションの設定と標準レイアウト
sg.theme('Dark Blue 3')
# filter frame
filter_box = sg.Frame('FILTER', font='Any 15', layout=[
[sg.Text('kernelsize_col'), sg.Input("3", size=(3,None), key='kernelsize_0')],
[sg.Text('kernelsize_row'), sg.Input("3", size=(3,None), key='kernelsize_1')],
[sg.Button('filter', key='filter')],
[sg.Image(filename='', key='image_filter')],
[sg.Multiline('[0.0, 0.1, 0.2],\n[0.1, 0.2, 0.4],\n[0.0, 0.2, 0.4]', size=(24, 12), key='filterarray')],
])
target_box = sg.Frame('TARGET', font='Any 15', layout=[
[sg.Text('targetsize_col'), sg.Input("5", size=(3,None), key='targetsize_0')],
[sg.Text('targetsize_row'), sg.Input("5", size=(3,None), key='targetsize_1')],
[sg.Button('target', key='target')],
[sg.Image(filename='', key='image_target')],
[sg.Multiline('[0.0, 2.0, 8.0, 3.0, 5.0],\n[5.0, 1.0, 7.0, 6.0, 3.0],\n[2.0, 9.0, 3.0, 2.0, 1.0],\n[5.0, 4.0, 1.0, 4.0, 8.0],\n[0.0, 5.0, 2.0, 8.0, 5.0]',size=(24, 12), key='targetarray')],
])
calculated_box = sg.Frame('CALCULATED', font='Any 15', layout=[
[sg.Text('stride'), sg.Input("2", size=(3,None), key='stride')],
[sg.Button('calculate', key='calculate')],
[sg.Multiline('calculated',size=(24, 12),key='text_calculated')],
])
layout = [
# [sg.Text('Type the window name and press the button to capture it.\nIf it couldnt find the one, it will capture a whole area of a primary display.')],
[sg.Text('ウィンドウ名を入力してボタンをクリック\n見つからなかった場合はメインディスプレイそのままキャプチャ')],
[sg.Input("FireFox", size=(40,None), key='windowname'), sg.Button('windowcapture', key='windowcapture')],
[sg.Image(filename='', key='image_capture', size=(600,300), )],
[filter_box, target_box, calculated_box],
]
# セクション 2 - ウィンドウの生成
self.window = sg.Window('ConvCalcOCR', layout)
# init OCR
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
self.tool = tools[0]
print("Will use tool '%s'" % (self.tool.get_name()))
# セクション 3 - イベントループ
while True:
event, values = self.window.read()
if event is None:
print('exit')
break
elif event == 'windowcapture':
self.image_capture = cv2.cvtColor(WindowCapture(values['windowname']), cv2.COLOR_BGRA2BGR)
self.image_copy = self.image_target = self.image_filter = self.image_capture.copy()
img = scale_box(self.image_capture, 600, 300)
imgbytes = cv2.imencode('.png', img)[1].tobytes()
self.window['image_capture'].update(data=imgbytes)
elif event == 'filter':
self.flag_filter = True # もっとスマートな方法ないですか?
self.redefine_rectangle(int(values['kernelsize_0']), int(values['kernelsize_1']), (128, 128, 0))
img = scale_box(self.image_capture, 600, 300)
imgbytes = cv2.imencode('.png', img)[1].tobytes()
self.window['image_capture'].update(data=imgbytes)
elif event == 'target':
self.flag_filter = False
self.redefine_rectangle(int(values['targetsize_0']), int(values['targetsize_1']), (0, 0, 255))
img = scale_box(self.image_capture, 600, 300)
imgbytes = cv2.imencode('.png', img)[1].tobytes()
self.window['image_capture'].update(data=imgbytes)
elif event == 'calculate':
calculated = strideConv(values['targetarray'], values['filterarray'], int(values['stride']))
calculated = np.round(calculated, decimals=2) # 計算誤差で小数点以下が多くなることがあるため
calculated_shape = np.array(calculated).shape
self.window['text_calculated'].update(fix_textbox(calculated.tolist(), calculated_shape[0], calculated_shape[1]))
# セクション 4 - ウィンドウの破棄と終了
self.window.close()
# グリッド付き長方形
def rectangle_grid(img, pt1, pt2, color, cols, rows, thickness=1, lineType=cv2.LINE_8, shift=None):
space_x = abs(pt2[0] - pt1[0]) / cols
space_y = abs(pt2[1] - pt1[1]) / rows
for col in range(cols+1):
img = cv2.line(img, (int(pt1[0]+col*space_x), pt1[1]), (int(pt1[0]+col*space_x), pt2[1]), color, thickness, lineType)
for row in range(rows+1):
img = cv2.line(img, (pt1[0], int(pt1[1]+row*space_y)), (pt2[0], int(pt1[1]+row*space_y)), color, thickness, lineType)
return img
# 画像分割
def divide_image(image, roi, cols, rows, eroderatio):
# クロップ
cropped = image[roi[0][1]:roi[1][1], roi[0][0]:roi[1][0]]
# https://pystyle.info/opencv-split-and-concat-images/
chunks = []
for row_cropped in np.array_split(cropped, rows, axis=0):
for chunk in np.array_split(row_cropped, cols, axis=1):
# 文字と判定してしまいがちな枠線削除
erode = int(eroderatio*min(chunk.shape[:2]))
chunk = chunk[erode:chunk.shape[0]-erode, erode:chunk.shape[1]-erode]
chunks.append(chunk)
return chunks
# マイナス座標対応
def fix_coordinate(iy, ix, y, x):
x_sorted = sorted([ix, x])
y_sorted = sorted([iy, y])
# relu
return [[np.maximum(0, x_sorted[0]), np.maximum(0, y_sorted[0])],
[np.maximum(0, x_sorted[1]), np.maximum(0, y_sorted[1])]]
# 整数部は1桁だと仮定して整形
def fix_num(num):
fixed_num = re.sub("\\D", "", num) # 数字以外削除
if fixed_num == '' or fixed_num == '-': # "-"が数字扱いになってた
return 0.0
else:
fixed_num = fixed_num[0] + '.' + fixed_num[1:]
return fixed_num
# 表示部用の整形
def fix_textbox(score_list, rows, cols):
score_array = np.reshape(np.array(score_list), (rows, cols))
score_list_reshaped= ["{}".format(l) for l in score_array.tolist()]
return ',\n'.join(score_list_reshaped)
# 画像リサイズ
# https://pystyle.info/opencv-resize/#outline__3_5
def scale_box(img, width, height):
"""指定した大きさに収まるように、アスペクト比を固定して、リサイズする。
"""
h, w = img.shape[:2]
aspect = w / h
if width / height >= aspect:
nh = height
nw = round(nh * aspect)
else:
nw = width
nh = round(nw / aspect)
return cv2.resize(img, dsize=(nw, nh))
# 畳み込み計算
# https://stackoverflow.com/questions/48097941/strided-convolution-of-2d-in-numpy/48098534
def strideConv(v1, v2, s):
arr = np.array(eval('[' + v1 + ']'))
arr2 = np.array(eval('[' + v2 + ']'))
return signal.convolve2d(arr, arr2[::-1, ::-1], mode='valid')[::s, ::s]
# ウィンドウキャプチャ
# https://qiita.com/danupo/items/e196e0e07e704796cd42
def WindowCapture(window_name: str, bgr2rgb: bool = False):
# 現在アクティブなウィンドウ名を探す
process_list = []
def callback(handle, _):
process_list.append(win32gui.GetWindowText(handle))
win32gui.EnumWindows(callback, None)
# ターゲットウィンドウ名を探す
for process_name in process_list:
if window_name in process_name:
hnd = win32gui.FindWindow(None, process_name)
break
else:
# 見つからなかったら画面全体を取得
hnd = win32gui.GetDesktopWindow()
# ウィンドウサイズ取得
x0, y0, x1, y1 = win32gui.GetWindowRect(hnd)
width = x1 - x0
height = y1 - y0
# ウィンドウのデバイスコンテキスト取得
windc = win32gui.GetWindowDC(hnd)
srcdc = win32ui.CreateDCFromHandle(windc)
memdc = srcdc.CreateCompatibleDC()
# デバイスコンテキストからピクセル情報コピー, bmp化
bmp = win32ui.CreateBitmap()
bmp.CreateCompatibleBitmap(srcdc, width, height)
memdc.SelectObject(bmp)
memdc.BitBlt((0, 0), (width, height), srcdc, (0, 0), win32con.SRCCOPY)
# bmpの書き出し
if bgr2rgb is True:
img = np.frombuffer(bmp.GetBitmapBits(True), np.uint8).reshape(height, width, 4)
img = cv2.cvtColor(img, cv2.COLOR_bgr2rgb)
else:
img = np.fromstring(bmp.GetBitmapBits(True), np.uint8).reshape(height, width, 4)
# 後片付け
# srcdc.DeleteDC()
memdc.DeleteDC()
# win32gui.ReleaseDC(hnd, windc)
win32gui.DeleteObject(bmp.GetHandle())
return img
if __name__ == '__main__':
ConvCalc().main()
参考
- https://qiita.com/dario_okazaki/items/656de21cab5c81cabe59
- https://pystyle.info/opencv-split-and-concat-images/
- https://pystyle.info/opencv-resize/#outline__3_5
- https://stackoverflow.com/questions/48097941/strided-convolution-of-2d-in-numpy/48098534
- https://qiita.com/danupo/items/e196e0e07e704796cd42
最後に
- 至らない所が多いと思いますので気軽にご指摘ください。
- G検定で畳み込み計算は何問出るのでしょうか。
- これ作っている時間勉強した方が良かった気が。
- 次はKivyの記事を作ってみたいです。
追記
2020.11.7の試験では畳み込み計算1問も出ませんでした![]()