前書き
前回のEncoder編に続いて書きます。Encoder編は下記のリンクを参照してください。
Encoder編で取り上げた内容は次の2件でした。
- Transformerの全体的な構造紹介
- TransformerのEncoder理解
そして本編であるDecoder編では次の3件について説明します。
- TransformerのDecoder理解
- EncoderとDecoderの結合
- Transformerの学習
Encoder編と同様に、本記事ではコードを用いた説明は行っておりません。数字だけを利用した例でTransformerの構造を説明します。
TransformerのDecoder理解
英語入力文章「I am good」を入力すると、フランス語ターゲット文章「Je vais bien」を生成する翻訳機を作ると仮定します。翻訳機を作るには、まず入力文である「I am good」をEncoderに入力する必要があります。Encoderは入力文章の表現を学習します。Encoder編でEncoderが入力文章を学習する方法を詳しく扱いました。次にこのEncoderの結果値を持ってきて、Decoderに入力値として使用します。Decoderは次の図のようにEncoderの表現を入力値として使用し、ターゲット文である「Je vais bien」を生成します。

Encoderを扱う時、EncoderはN個を累積して積むことができると説明しました。Encoderと同様に、DecoderもN個を積み重ねることができます。N = 2で例を挙げます。下の図ように、1つのDecoder出力値は、その上にあるDecoderの入力値として送信されます。また、Encoderの入力文章表現(Encoderの出力値)がすべてのDecoderに送信されることが分かります。つまり、Decoderは以前Decoderの入力値とEncoderの表現(Encoderの出力値)、2つを入力データとして受け取ります。

それでは、Decoderが文章を生成する方法について説明します。time stepのt=1なら、Decoderの入力値は文章の始まりを知らせる<sos>を入力します。この入力値を受け取ったDecoderは、ターゲット文章の最初の単語である「Je」を生成します。

time step=2の場合、これまでの入力値に前段階(t-1) Decoderで生成した単語を追加して文章の次の単語を生成します。つまり、下の図のようにDecoderは<sos>と「Je」を入力してもらい、ターゲット文章である次の単語を生成します。

time step=3の場合、前の段階と同じ方法で進めます。この時、Decoderの入力は<sos>、「Je」,「vais」で、この入力値を活用して次の単語を生成します。time step=3では「Je vais bien」が生成されます。
Decoderは、すべての段階で前の段階で新たに生成した単語を組み合わせて入力値を生成し、これを利用して次の単語を予測する方法を進めます。したがって、t=4の場合は<sos>、「Je」,「vais」,「bien」を入力して次の単語を予測します。

上の図のように、Decoderでトークンを生成することでターゲット文章の生成が完了します。
Encoderの場合、入力文をEmbedding行列に変換した後、ここに位置エンコーディングを加えた値を入力します。同様に、Decoderも入力値をすぐに入力するのではなく、位置エンコーディングを追加した値をDecoderの入力値として使用します。
例えば、下の図ように各time stepの入力をEmbeddingに変換する場合、位置エンコーディング値を追加した後、Decoderに入力します。
Decoderでは、以前のtime stepでDecoderが生成した単語のEmbeddingを計算するため、「出力Embedding」と定義します。
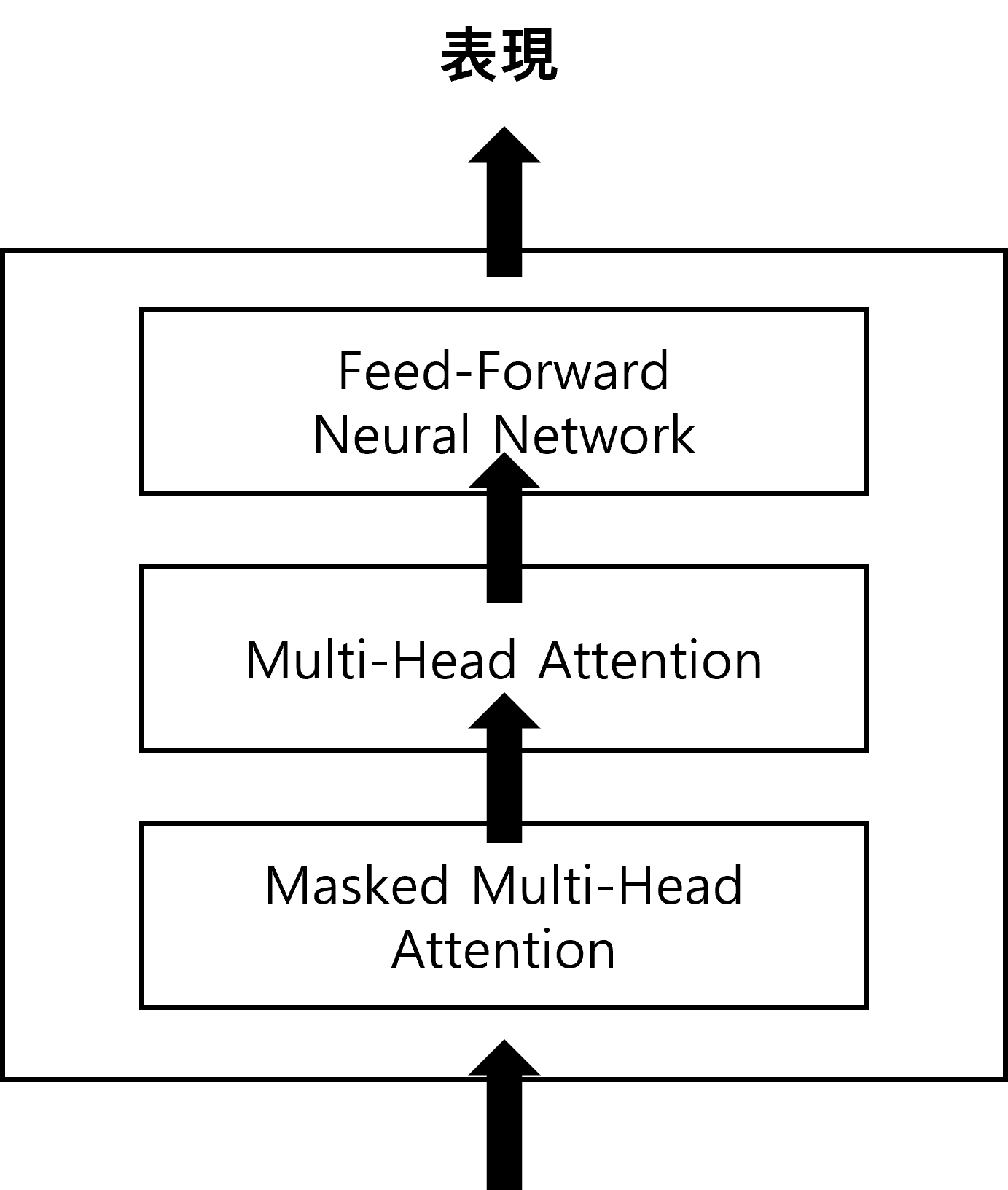
これからはDecoderの細部構造を説明します。1つのDecoderブロックは、次のような要素で構成されます。
Decoderブロックは、サブレイヤー3つで構成されたEncoderブロックと類似した構造です。
- Masked Multi-Head Attention
- Multi-head Attention
- Feed-Forward Neural Network
DecoderブロックはEncoderブロックと同様に、サブレイヤーにMulti-head AttentionとFeed-Forward Neural Networkを含みます。しかし、Encoderと違って2つの形態のMulti-head Attentionを使用します。そのうちの一つは、Attention部分がmaskedされた形です。それではDecoderの各構成要素を説明します。
Masked Multi-Head Attention
モデルを学習する時は、すでにターゲット文章を知っているので、Decoderに基本的にターゲット文章全体を入力すればいいのですが、若干の修正作業が必要です。Decoderで文章を入力する時、最初は<sos>トークンを入力し、トークンが生成されるまで前の段階で予測した単語を追加する形で入力を繰り返します。したがって、ターゲット文章の一番前に<sos>トークンを追加してからDecoderに入力します。
「I am good」を「Je vais bien」に翻訳すると仮定します。ターゲット文章の一番前に<sos>トークンを追加した「<sos>Je vais bien」をDecoderに入力すると、Decoderから「Je vais bien 」を出力します。

ここからはDecoderがターゲット文章全体を入力し、一段階移動した形の文章を出力する理由について説明します。
Decoderに入力文を入力する際、入力文をEmbedding(出力Embedding行列)に変換した後、位置エンコーディングを追加してDecoderに入力することは説明しました。ここでDecoderの入力行列をXとします。

この記事で例として挙げる値は、式で計算される場合を除けば、すべて任意の値です。
行列XをDecoderに入力すると、最初のレイヤーはmasked multi-head attentionになります。Encoderで使用したmulti-head attentionと基本原理は同じですが、一つ異なる点があります。
Self-Attentionを実装すると、最初にQuery, Key, Value行列が生成されます。Multi-head Attentionを計算すると、h個のQ, K, V行列が生成されます。したがって、ヘッドiの場合、行列Xにそれぞれ加重行列$w_{i}^{Q}$, $w_{i}^{K}$, $w_{i}^{V}$を掛けて$Q_{i}$, $K_{i}$, $V_{i}$行列を得ることができました。
それではmasked multi-head attentionを見てみましょう。Decoderの入力文章は「<sos> Je vais bien」です。Self-Attentionは、各単語の意味を理解するために各単語と文章内の全体単語を連結しました。しかし、Decoderでは文章を生成する際、前の段階で生成した単語だけを入力文として入れました。例えばt=2でDecoderの入力単語は「<sos>, Je」でした。つまり、このようなDecoderの特性を活かしてモデル学習を進める必要があります。したがって、Self-Attentionは単語との関連性を「Je」だけを考慮し、モデルがまだ予測していない右側のすべての単語をmaskingして学習を進めます。
<sos>次の単語を予測するとします。この場合、モデルは<sos>までしか見ることができず、<sos>の右側にあるすべての単語にmasking作業をします。その次に、「Je」の単語を予測します。この時、モデルは「Je」までの単語だけを表示するので、「Je」の右側にあるすべての単語をmaskingします。これまで説明した内容を整理すると、次のようになります。

単語masking作業は、Self-Attentionで入力される単語だけに集中して単語を正確に生成する効果があります。ここからは、maskingの具体的な実装方法について説明します。iヘッドのAttention行列$Z_{i}$は次の式で求められます。
- $Z_{i} = softmax(\frac{Q_{i}·{K_{i}}^{T}}{\sqrt{d_{k}}})K_{i}$
Attention行列を求める最初のステップは、QueryとKey行列の間の内積を計算することです。下の図は、QueryとKey行列の間の内積値を求めた任意の結果です。

次に、$Q_{i}{K_{i}}^{T}$行列をKeyベクトルの次元である${\sqrt{d_{k}}}$で分けます。その結果値は以下の通りです。
今の例ではベクトルの次元は64なので、64の平方根である8で$Q_{i}{K_{i}}^{T}$を分けます。

上記の行列にSoftmax関数を適用して正規化作業を行います。Softmax関数を適用する前に、行列値に対するmasking処理が必要です。例えば、上記行列の最初の行で<sos>の次の単語を予測する場合、モデルでは<sos>の右側にあるすべての単語を参照してはいけません。つまり、<sos>の右側にあるすべての単語を$-\infty$でmaskingします。
$-\infty$で値を入力するとモデル学習中に発散する場合があり、実際に実装する際には非常に小さい値でmaskingします。

2行目で「Je」次の単語を予測するため、モデルでは「Je」の右側にある単語を参照してはいけません。つまり、「Je」の右側にあるすべての単語を$-\infty$にmaskingします。

このような方法でvais右側の単語も処理します。

次に、Softmax関数を適用した行列とValue行列($V_{i}$)を掛けて、最終的にAttention行列(Z_{i})を求めます。Multi-head Attentionの場合、h個のAttention行列を求め、それらを互いに連結(concatenate)した後に新しいweight matrix${W_{}}^{0}$を掛けて最終的にAttention行列Mを求めます。
- M = concatenate($Z_{1}$, $Z_{2}$... $Z_{h}$)${W_{}}^{0}$
このように求めたAttention行列Mを、次のサブレイヤーにある別の形態のMulti-head Attentionの入力値として入れます。
Multi-head Attention
下の図の赤い部分はEncoderとDecoderを結合したTransformerモデルの姿です。この時、DecoderのMulti-head Attentionは入力データ2つを受け取ります。1つは以前のサブレイヤーの出力値で、もう1つはEncoderの表現です。

Encoderの表現値をR、以前のサブレイヤーであるMasked Multi-head Attentionの結果として出たAttention行列をMとします。ここでEncoderの結果とDecoderの結果の間に相互作用が起こります。これをEncoder-Decoder Attention layerと呼びます。
Multi-head Attention Layerは、最初のステップでMulti-head Attentionで使用するQuery、Key、Value行列を生成します。Encoder編で行列にweight matrixを掛けてQuery、Key、Value行列を作ることができると言いました。しかし、今回は入力値が2つ(Encoder表現R、以前のサブレイヤー出力値M)です。つまり、今回は少し方法が変わります。
以前のサブレイヤーの出力値であるAttention行列Mを利用してQuery行列を生成し、Encoder表現値であるRを活用してKey、Value行列を生成します。現在、Multi-head Attentionを使用しているため、ヘッドiを基準に次の2つの手順に従います。
- Attention行列Mにweight matrix$W_{i}^{Q}$を掛けてQuery行列$Q_{i}$生成
- Encoder表現値Rにweight matrix$W_{i}^{K}$, $W_{i}^{V}$をそれぞれ掛け、Key, Value行列$K_{i}$, $V_{i}$生成


覚えていますか?ここで例として使用する値はすべて任意の値で意味がありません。
Query行列はMを用いて生成し、Key, Value行列はRを用いて生成する理由は簡単です。一般的にQuery行列はターゲット文章の表現を含むため、ターゲット文章に対する値であるMの値を参照します。KeyとValue行列は入力文章の表現を持つため、Rの値を参照します。この方法のメリットは、Self-Attentionを段階的に計算しながら詳しく説明します。
Self-Attentionの第一段階は、Query、Key行列間の内積を計算することです。前述したように、Query行列はMの値を、Key行列はRの値を参照しました。上で求めたQueryとKey行列間の内積を求めた結果は下の図とおりです。

上記の行列$Q_{i}·{K_{i}}^{T}$から次の事実を知ることができます。
- 行列の1行目でQueryベクトル$q_{1}$(<sos>)とすべてのKeyベクトル$k_{1}$(I), $k_{2}$(am), $k_{3}$(good)との間の内積を計算します。1行目は、ターゲット単語<sos>が入力文章のすべての単語(I, am, good)とどれだけ似ているかを計算するものと解釈できます。
- 2行目はQueryベクトル$q_{2}$(Je)とすべてのKeyベクトル$k_{1}$(I), $k_{2}$(am), $k_{3}$(good)との間の内積を計算します。2行目はターゲット単語「Je」が入力文章のすべての単語(I, am, good)とどれだけ似ているかを計算します。
- 残りの行でも上記と同じ方法を適用します。$Q_{i}·{K_{i}}^{T}$はQuery行列(ターゲット文章表現)とKey行列(入力文章表現)の間の類似度を計算します。
Multi-head Attentionの次のステップは、$Q_{i}·{K_{i}}^{T}$を$\sqrt{d_{k}}$で割ることです。その後、Softmax関数を適用すると、$softmax(\frac{Q_{i}·{K_{i}}^{T}}{\sqrt{d_{k}}})$であるスコア行列が得られます。
その次には、スコア行列にvalue行列Vをかけた$softmax(\frac{Q_{i}·{K_{i}}^{T}}{\sqrt{d_{k}}})V_{i}$であるAttention行列$Z_{i}$を得ることができます。
Attention行列$Z_{i}$は次のように表現できます。
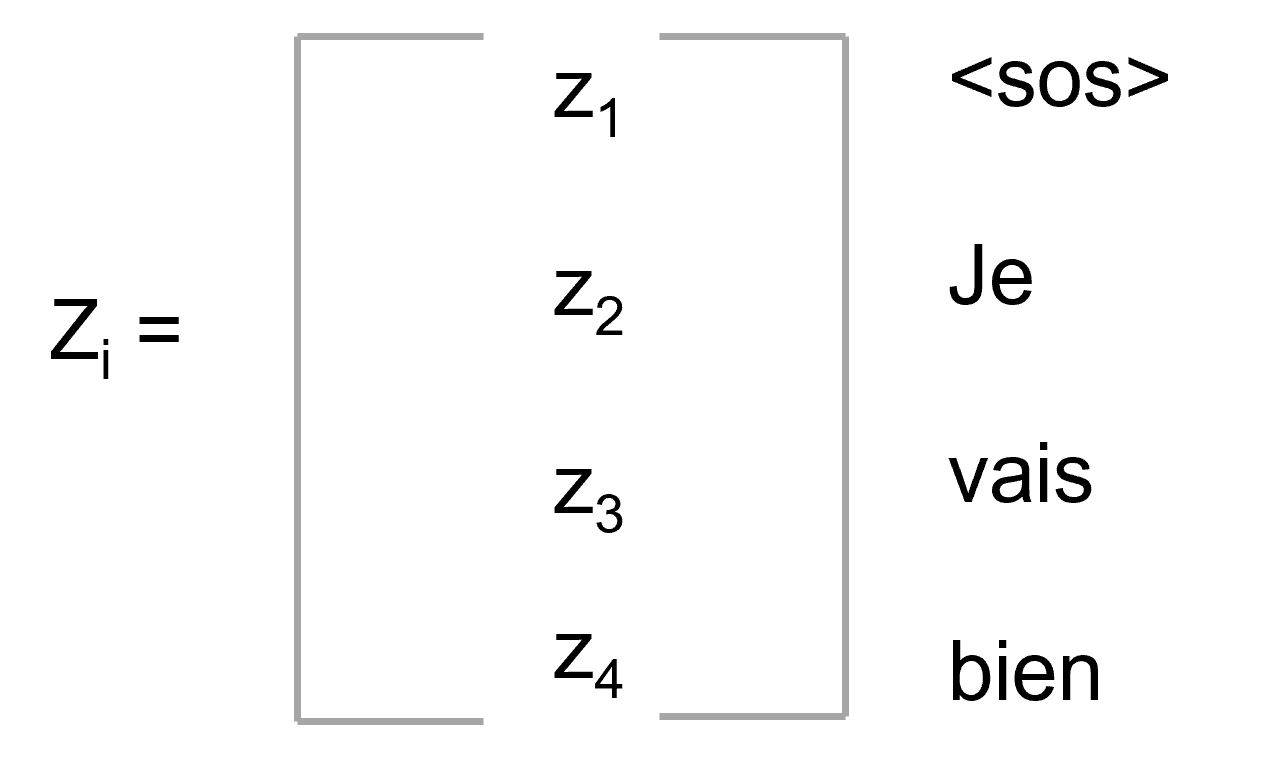
ターゲット文章のAttention行列$Z_{i}$の場合、各スコアに対するweightを反映したベクトル値の和で計算されます。例えば、単語「Je」, $Z_{2}$のSelfベクトル値を計算すると仮定します。

単語「Je」のSelf-Attentionである$Z_{2}$は、scoreに対するweightを反映したベクトル値の和で計算されます。したがって、$Z_{2}$の95%はベクトル値$v_{1}$(I)と2%のベクトル値$v_{2}$(am)、3%のベクトル値$v_{3}$(good)を含みます。モデルでは、ターゲット単語「Je」が入力単語「I」を意味すると解釈できます。
同じ方法でh個のヘッドに対してAttention行列を求めた後、これを連結し、加重行列${W_{}}^{0}$をかけると最終Attention行列が求められます。
- Multi-head Attention = concatenate($Z_{1}$, $Z_{2}$, ..., $Z_{h}$)${W_{}}^{0}$
次は、Attention行列の結果をDecoderの次のサブレイヤーであるFeed-Forward Neural Networkに入力します。Position-wise Feed-Forward Neural NetworkとAdd&NormはEncoderと同じなので、ここでは説明しません。
LinearとSoftmaxレイヤー
Decoderがターゲット文に対する表現を学習すると、下の赤い部分のように最上位Decoderから得た出力値をLinearおよびSoftmaxレイヤーに送ります。

Linearレイヤーの場合、その大きさがseq_lenサイズと同じlogit形式です。文章が次のように3つの要素で構成されていると仮定します。
- sequence = [bien, Je, vais]
Linearレイヤーが返すlogitは、サイズが3のベクトル形態になります。Softmax関数を使ってlogit値を確率値に変換した後、Decoderで最も高い確率値を持つindexの単語で出力します。
Decoderの入力単語が<sos>と「Je」である場合、Decoderは入力単語を見て次の単語を予測します。予測のため、Decoderでは最上位出力値を取得し、Linearレイヤーに入力します。このLinearレイヤーでsequenceサイズと同じサイズのlogitベクトルを生成します。logit値が次のようになると仮定します。
- logit = [50, 60, 66]
このlogit値にsoftmax関数を適用すると確率値が得られます。
- prob = [0.001, 0.002, 0.997]
probでindexが2の場合、確率値は0.997で最も高いです。したがって、sequenceでindexが2の「vias」がターゲット文章の次の単語と予測されます。このような方法で、Decoderはターゲット文章の次の単語を予測します。
これまでDecoderのすべての構成要素を説明しました。それでは、すべての要素を統合したときにどのように動作するかを説明します。
Decoderのすべての構成要素統合
下の図はDecoderだけを表現した形です。

上の図からDecoderの流れを6つにまとめることができます。
- Decoderに対する入力文をEmbedding行列に変換した後、位置エンコーディング情報を追加してDecoder(Decoder1)に入力。
- Decoderは入力値を持ってきてMasked Multi-head Attentionレイヤーに送り、出力でAttention行列Mを出力。
- Attention行列M、Encoding表現Rを入力してもらい、Multi-head Attentionレイヤー(Encoder-Decoder Attentionレイヤー)に値を入力し、出力で新しいAttention行列を生成。
- Encoder-Decoder Attentionレイヤーから出力したAttention行列を次のサブレイヤーであるFeed Forward Neural Networkに入力する。Feed Forward Neural Networkではこの入力値を受け取り、Decoderの表現で値を出力。
- 次に、Decoder1の出力値を次のDecoder2の入力値として使用する。
- Decoder2はDecoder1で行ったプロセスと同様に進め、ターゲット文に対するDecoder表現を出力。
DecoderはN個のDecoderを積むことができます。この時、最上位Decoderから得た出力(Decoder表現)はターゲット文章の表現になります。次に、ターゲット文章のDecoder表現をLinearおよびSoftmaxレイヤーに入力し、最後に予測された単語を得られます。
今までEncoderとDecoderがどのような原理で作動するのかを説明しました。最後にEncoderとDecoderを結合して、最終的なTransformerモデルがどのように動作するかを説明します。
EncoderとDecoderの結合
完全なTransformerアーキテクチャは次のとおりです。

上の図からも分かるように、入力文(Inputs)を入力すると、Encoderでは該当文章に対する表現を学習させ、その結果値をDecoderに送ってDecoderでターゲット文章を生成します。
Transformer学習
loss functionを最小化する方向でTransformerネットワークは学習されます。上でDecoderがsequenceに対する確率分布を予測し、確率が最も高い単語を選択すると説明しました。つまり、正しい文章を生成するには、予測確率分布と実際の確率分布との差を最大限に減らす必要があります。そのためには、二つの分布の違いを知る必要があります。この時、cross-entropyを使うと分布の違いが分かります。したがって、loss functionをcross-entropy lossと定義し、予測確率分布と実際確率分布を最大限減らすようにモデルを学習します。この時、optimizerはAdamを使います。
この過程でoverfittingを防止するために各サブレイヤーの出力にdropoutを適用し、Embeddingおよび位置エンコーディングの合計を求める時もdropoutを適用します。
学習過程について数学的に説明するには新しい記事を書かなければならないので、詳しい説明は省略します。
最後に
これまでTransformerを数学的に解説しました。足りない部分もありましたが、読んでくださってありがとうございました!Decoder編はEncoder編と重複する部分もありまして、省略した内容もありました。
追加解説が必要な部分がございましたら、いつでもご連絡してください。