実行環境
- Windows10
- CPU :Intel(R)Core(TM)i5-4690 CPU @ 3.50GHz
- メモリ :16GB
- GPU :Geforce GTX 1070(GPUメモリ8GB)
- Visual Studio 2019
- CUDA10.1
- CuDnn10.1
- Python 3.6.10
- VOICEROID+ 結月ゆかり EX
環境準備
Windowsで環境を構築する場合は、Python、CUDAが上記のバージョンでないとエラー地獄に陥るので合わせること
Visual Studio
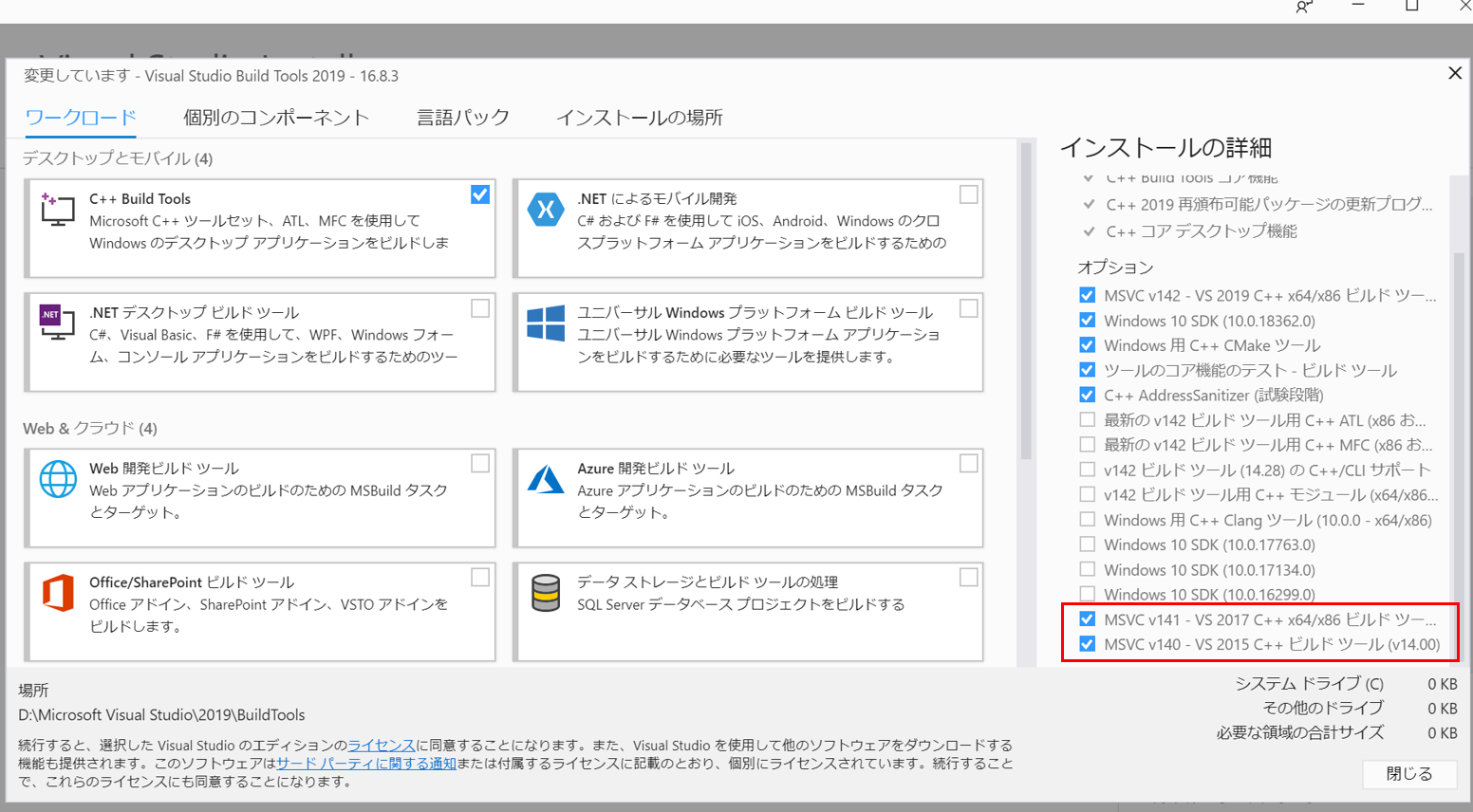
【重要】インストール時に以下を必ずチェックしておくこと。
MSVC v141~
MSVC v140~
私はcupyのインストール時に「error: Microsoft Visual C++ 14.1 is required」が出て詰みました。
CUDA + CuDNN
こちらを参考にインストール
Windows 10 に CUDA + cuDNN をインストール
Python(Anaconda)
conda create -n py36 python=3.6 anaconda
activate py36
環境変数
cupyのインストールエラー解消のため、色々と試行錯誤していましたので不要な設定もあるかも知れません。
| システム環境変数 | 値 |
|---|---|
| CUDNN_PATH | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1 |
| INCLUDE | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include; C:\Program Files (x86)\Windows Kits\10\Include\10.0.18362.0\ucrt; C:\Program Files (x86)\Windows Kits\10\Include\10.0.18362.0\shared; C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.16.27023\include |
| LIB | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib\x64; C:\Program Files (x86)\Windows Kits\10\Include\10.0.18362.0\ucrt; C:\Program Files (x86)\Windows Kits\10\Include\10.0.18362.0\um; C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.16.27023\lib |
| PYTHONPATH | D:\Users\xxxx\MYDesktop\yukarinライブラリ\deep_yukarin\yukarin; D:\Users\xxxx\MYDesktop\yukarinライブラリ\deep_yukarin\become-yukarin |
yukarin 第1段階学習
READMEに沿って実行、上手くいかなかった部分は変更してあります。
ライブラリインストール
cupyインストールで躓いた結果、pip install -r requirements.txtではなく下記の順番で個別にインストールしました。
pip install numba==0.48
pip install numpy
pip install -U "cupy < 6.0.0"
pip install -U "chainer < 6.0.0"
pip install -U "librosa < 0.7.0"
pip install pysptk
pip install pyworld
pip install matplotlib
pip install tensorflow
pip install tqdm
pip install git+https://github.com/neka-nat/tensorboard-chainer
pip install git+https://github.com/Hiroshiba/become-yukarin
pip uninstall cupy
pip uninstall chainer
pip install cupy-cuda101==6.2.0
pip install chainer==6.2.0
作業ディレクトリ作成
音声データはinput_wav、target_wavに格納
mkdir input_wav
mkdir input_feature
mkdir target_wav
mkdir target_feature
mkdir aligned_indexes
mkdir model_stage1
mkdir test_wav
mkdir output
音響特徴量ファイル出力、アライメント、周波数の統計量
python scripts/extract_acoustic_feature.py -i "input_wav\*" -o "input_feature"
python scripts/extract_acoustic_feature.py -i "target_wav\*" -o "target_feature"
python scripts/extract_align_indexes.py -i1 "input_feature\*.npy" -i2 "target_feature\*.npy" -o "aligned_indexes"
python scripts/extract_f0_statistics.py -i "input_feature/*.npy" -o "input_statistics.npy"
python scripts/extract_f0_statistics.py -i "target_feature/*.npy" -o "target_statistics.npy"
第1段階学習
sample_config.jsonからconfig.jsonを作成、編集
copy sample_config.json config.json
"input_glob": "input_feature\\*.npy",
"target_glob": "target_feature\\*.npy",
"indexes_glob": "aligned_indexes\\*.npy",
python train.py config.json model_stage1
※私の環境では250000回すまでに7時間強かかりました。
テスト
python scripts/voice_change.py --model_dir "model_stage1" --config_path "model_stage1\config.json" --input_statistics "input_statistics.npy" --target_statistics "target_statistics.npy" --output_sampling_rate 24000 --disable_dataset_test --test_wave_dir "test_wav" --output_dir "output" --model_iteration 130000
第1段階学習後の変換音声はガビガビでとても聞けたものではありませんでした。
become-yukarin 第2段階学習
READMEに沿って実行、上手くいかなかった部分は変更してあります。
作業ディレクトリ作成
音声データはinput_wav_2ndに格納
mkdir input_wav_2nd
mkdir output_2nd
mkdir model_stage2
ライブラリインストール
pip install world4py
pip install dill
音響特徴量ファイル出力
python scripts/extract_spectrogram_pair.py -i input_wav_2nd -o output_2nd
第2段階学習
config_sr.jsonをコピー、編集
copy recipe\config_sr.json config_sr.json
"input_glob": "output_2nd\\*.npy",
"batchsize": 2,
pickleでエラーとなるのでmultiprocessingreduction.pyを編集
import dill as pickle
python train_sr.py config_sr.json model_stage2
※私の環境では10000回すまでに7時間かかりましたのでそこで諦めました。
テスト
yukarinのディレクトリに戻り、第2段階学習モデルをコピー
xcopy /e ..\become-yukarin\model_stage2 model_stage2
先ほど編集したmultiprocessingreduction.pyを元に戻す
import pickle
以下のエラーが出たため、voice_change_with_second_stage.py一部修正
ValueError: 'reverse' is not a valid value for origin; supported values are 'upper', 'lower'
plt.imshow(numpy.log(f_in.sp).T, aspect='auto', origin='lower')
plt.imshow(numpy.log(f_low.sp).T, aspect='auto', origin='lower')
plt.imshow(numpy.log(s_high).T, aspect='auto', origin='lower')
plt.imshow(numpy.log(f_true.sp).T, aspect='auto', origin='lower')
python scripts/voice_change_with_second_stage.py --voice_changer_model_dir "model_stage1" --voice_changer_config "model_stage1\config.json" --voice_changer_model_iteration 130000 --super_resolution_model "model_stage2\predictor_10000.npz" --super_resolution_config "model_stage2\config.json" --input_statistics "input_statistics.npy" --target_statistics "target_statistics.npy" --out_sampling_rate 24000 --disable_dataset_test --dataset_target_wave_dir "" --test_wave_dir "test_wav" --output_dir "output_2nd" --gpu 0
第2段階学習後の変換音声はひどいネカマボイスといった感じでしたが第1段階と比べると格段によくなっていました。
感想
四苦八苦しましたが、一応最後まで実施できました。
結果としては結月ゆかりにはなれませんでしたが、
収録した音声データの精度が悪い + VOICEROID+ EXだとサンプリングレートが22050Hz(VOICEROID2だと44100Hzらしい) + 第2段階学習不足など色々と改善の余地はありました。
補足
個人的に困った点
VoiceroidController.exe -o v-0.wav おはよう
VoiceroidController.exe -o v-1.wav こんちには
・
・
・
VoiceroidController.exe -o v-99.wav おやすみ
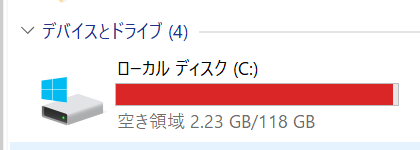
学習中のCドライブ
学習中に一時的にファイルを作成しているのか数GB単位で空き容量が減っていった。
Cドライブの容量が貧弱すぎたため、以下のエラーが発生。
※Visual StudioのWindows 10 SDKを削除する事でなんとか容量を確保した。
ImportError: DLL load failed: ページング ファイルが小さすぎるため、この操作を完 了できません。
参考リンク
『Yukarinライブラリ』become-yukarin, yukarin コマンド解説
Windowsで誰でも好きなキャラの声になれるyukarinライブラリを動かしてみた。