概要
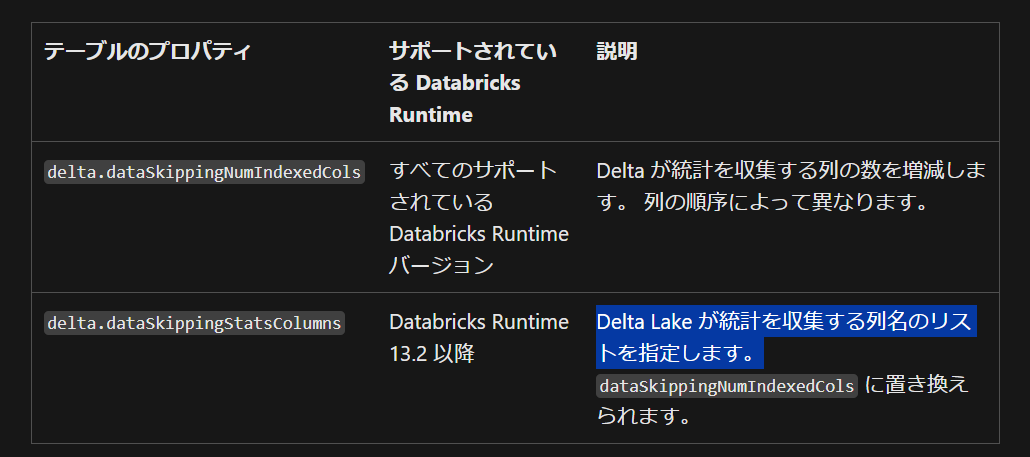
Databricks(Delta Lake)では、従来では統計情報を取得する際にはカラム位置を考慮する必要がありましたが、Databricks Runtime 13.2 (Delta Lake 3.0.0)移行ではdelta.dataSkippingStatsColumnsプロパティによりカラム名を指定できるようになりました。
データスキップは、クエリのパフォーマンスを向上させるために不可欠なプロセスです。このプロセスでは、関連性のないデータの読み込みを避けることで、クエリの実行時間を短縮します。統計情報は、このデータスキップの効率を高めるために重要な役割を果たします。

引用元:Delta Lake に対するデータのスキップ - Azure Databricks | Microsoft Learn
デフォルトでは前から 32 列の統計情報を取得するような仕様です。統計情報の取得対象のカラムを最適化する際には、ALTER 文によりカラム順を変更してから下記プロパティの値を設定する必要がありました。監査列をクエリで利用することがよくあり、本来は最後に配置したいにもかかわらず、統計情報を取得するために前の方に移動する必要がありました。

引用元:Delta テーブルのプロパティ リファレンス - Azure Databricks | Microsoft Learn
delta.dataSkippingStatsColumnsプロパティによりカラム名を指定できるようになったため、カラム順を変更する必要がなくなりました。
引用元:Delta Lake に対するデータのスキップ - Azure Databricks | Microsoft Learn
統計情報に関する情報は、テーブルのディレクトリ配下_delta_logフォルダにあるcrcファイルにて格納されます。crcファイルは json 形式でデータを保持しており、parquet ファイルごとの統計情報をstats列にて保持しています。

本記事では、delta.dataSkippingNumIndexedColsプロパティとdelta.dataSkippingStatsColumnsプロパティの検証に利用したコードとその結果を共有します。
検証コードと実行結果
事前準備
スキーマを作成します。
%sql
CREATE SCHEMA IF NOT EXISTS hive_metastore.stats_columns_test;
delta.dataSkippingNumIndexedColsプロパティにてカラム名指定による統計情報の取得
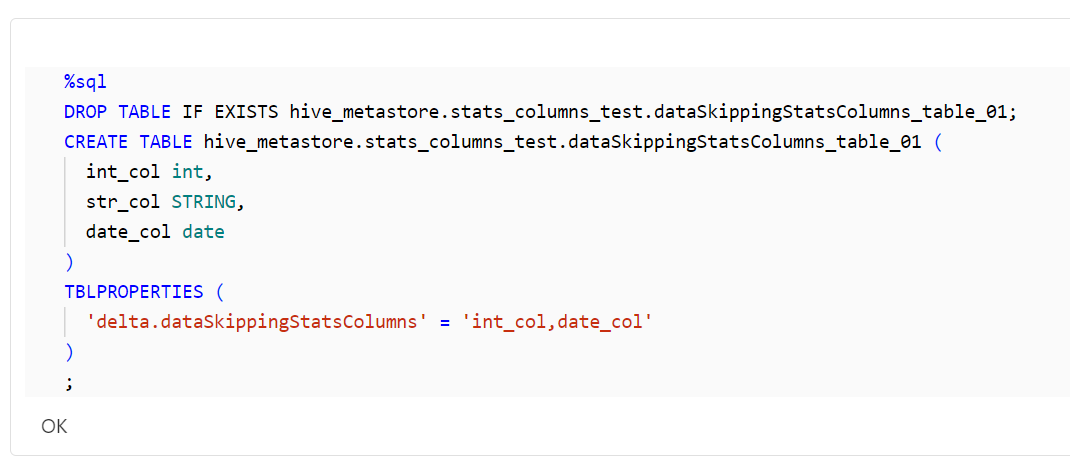
テーブルを作成します。
%sql
DROP TABLE IF EXISTS hive_metastore.stats_columns_test.dataSkippingStatsColumns_table_01;
CREATE TABLE hive_metastore.stats_columns_test.dataSkippingStatsColumns_table_01 (
int_col int,
str_col STRING,
date_col date
)
TBLPROPERTIES (
'delta.dataSkippingStatsColumns' = 'int_col,date_col'
)
;
データを挿入します。
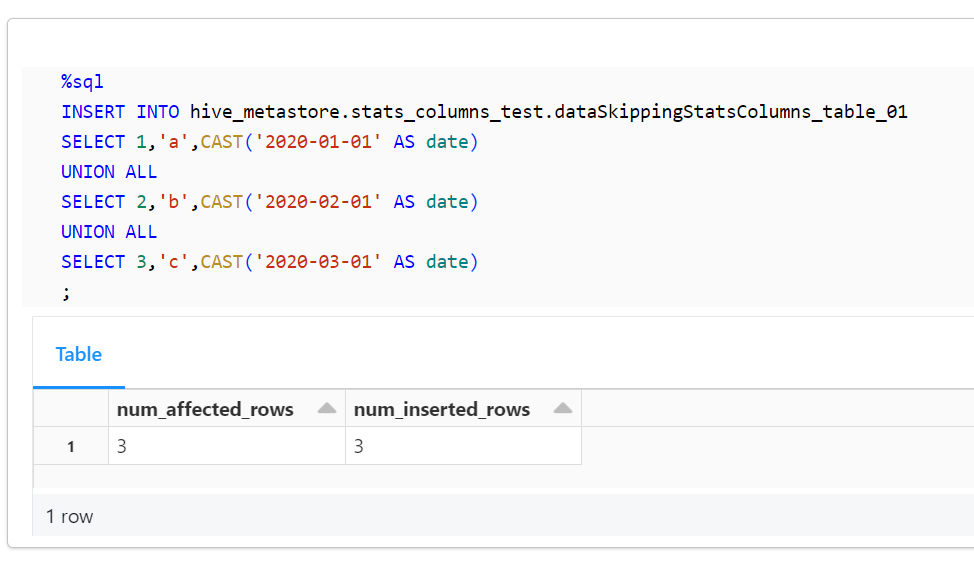
%sql
INSERT INTO hive_metastore.stats_columns_test.dataSkippingStatsColumns_table_01
SELECT 1,'a',CAST('2020-01-01' AS date)
UNION ALL
SELECT 2,'b',CAST('2020-02-01' AS date)
UNION ALL
SELECT 3,'c',CAST('2020-03-01' AS date)
;
テーブルのディレクトリ(Loacation)を取得します。
tgt_table_name = "hive_metastore.stats_columns_test.dataSkippingStatsColumns_table_01"
# テーブルの Location を取得
result = spark.sql(f"DESCRIBE EXTENDED {tgt_table_name}").collect()
table_location = next(row.data_type for row in result if row.col_name == "Location")
print(table_location)

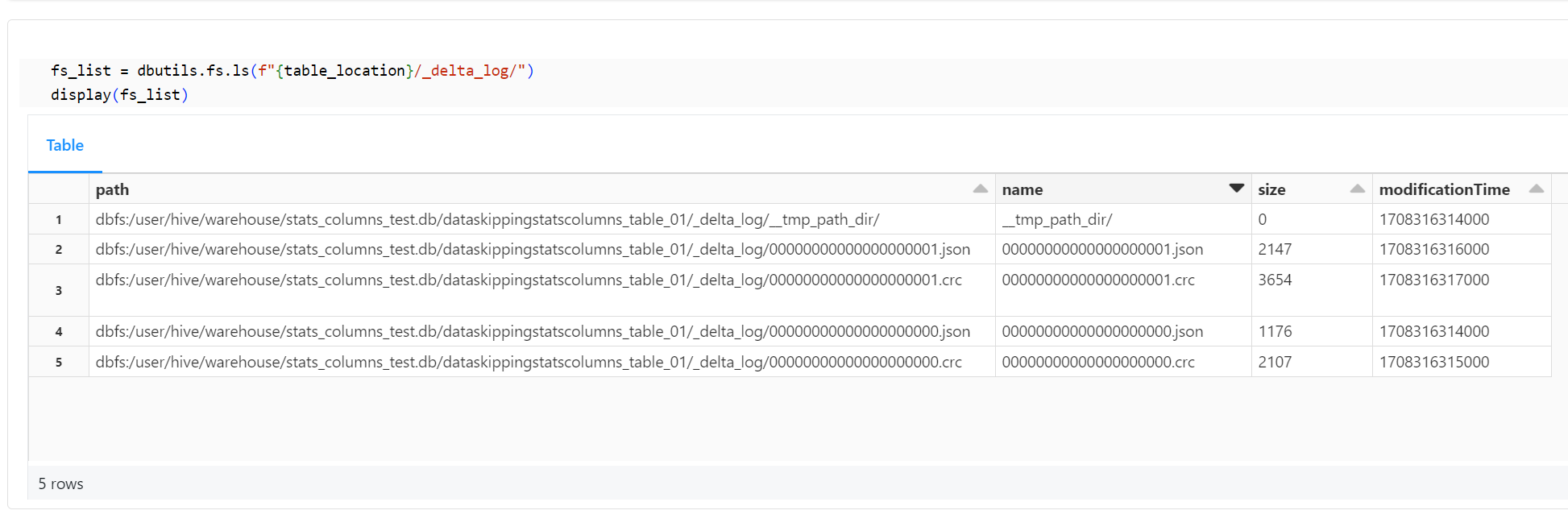
テーブルのディレクトリ(Loacation)配下にある_delta_logフォルダのオブジェクトを表示します。crc ファイルの最新が00000000000000000001.crcであることを確認できます。
fs_list = dbutils.fs.ls(f"{table_location}/_delta_log/")
display(fs_list)
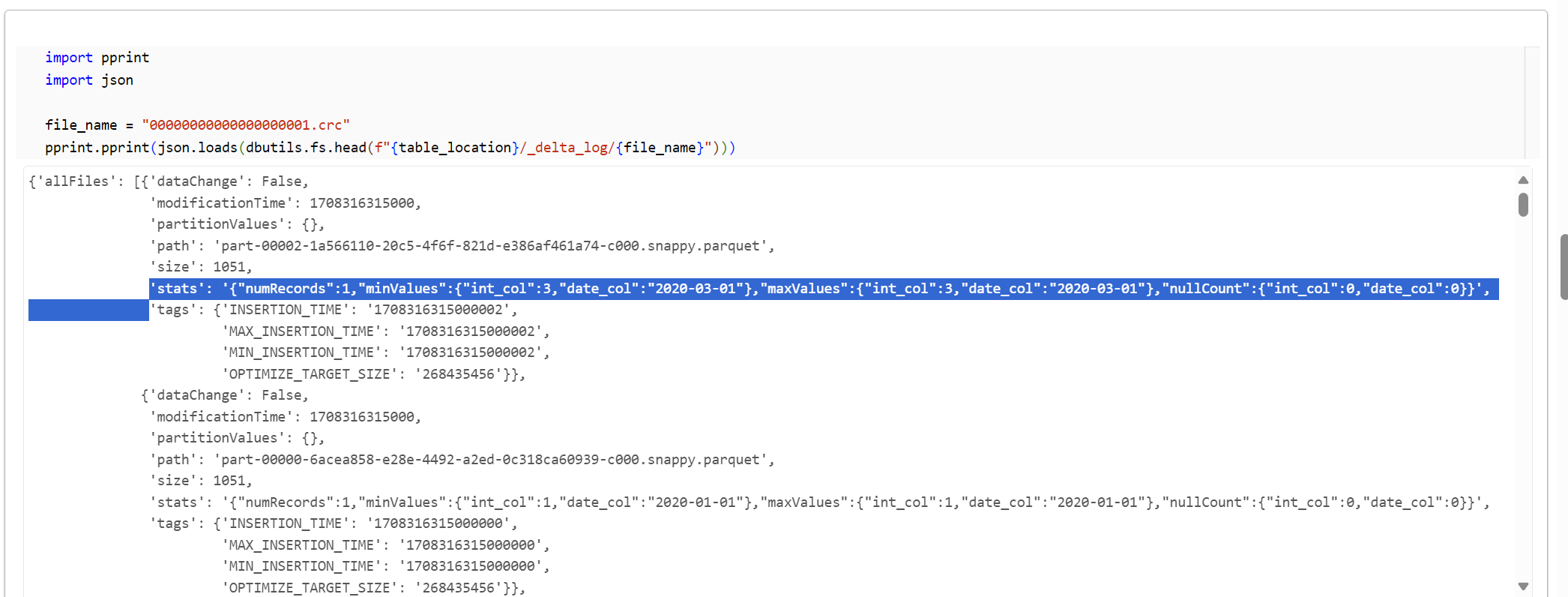
00000000000000000001.crcのデータを表示します。
import pprint
import json
file_name = "00000000000000000001.crc"
pprint.pprint(json.loads(dbutils.fs.head(f"{table_location}/_delta_log/{file_name}")))
delta.dataSkippingStatsColumnsプロパティにてカラム名指定による統計情報の取得
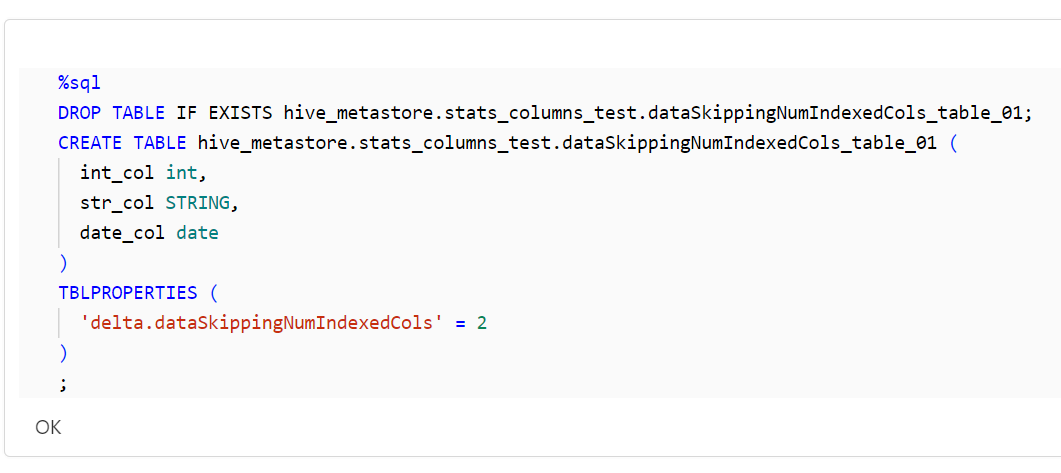
テーブルを作成します。
%sql
DROP TABLE IF EXISTS hive_metastore.stats_columns_test.dataSkippingNumIndexedCols_table_01;
CREATE TABLE hive_metastore.stats_columns_test.dataSkippingNumIndexedCols_table_01 (
int_col int,
str_col STRING,
date_col date
)
TBLPROPERTIES (
'delta.dataSkippingNumIndexedCols' = 2
)
;
カラム順を変更します。
%sql
ALTER TABLE hive_metastore.stats_columns_test.dataSkippingNumIndexedCols_table_01
CHANGE COLUMN date_col date_col date AFTER int_col;
-- カラム順が変更されていることを確認
DESC hive_metastore.stats_columns_test.dataSkippingNumIndexedCols_table_01;

データを挿入します。
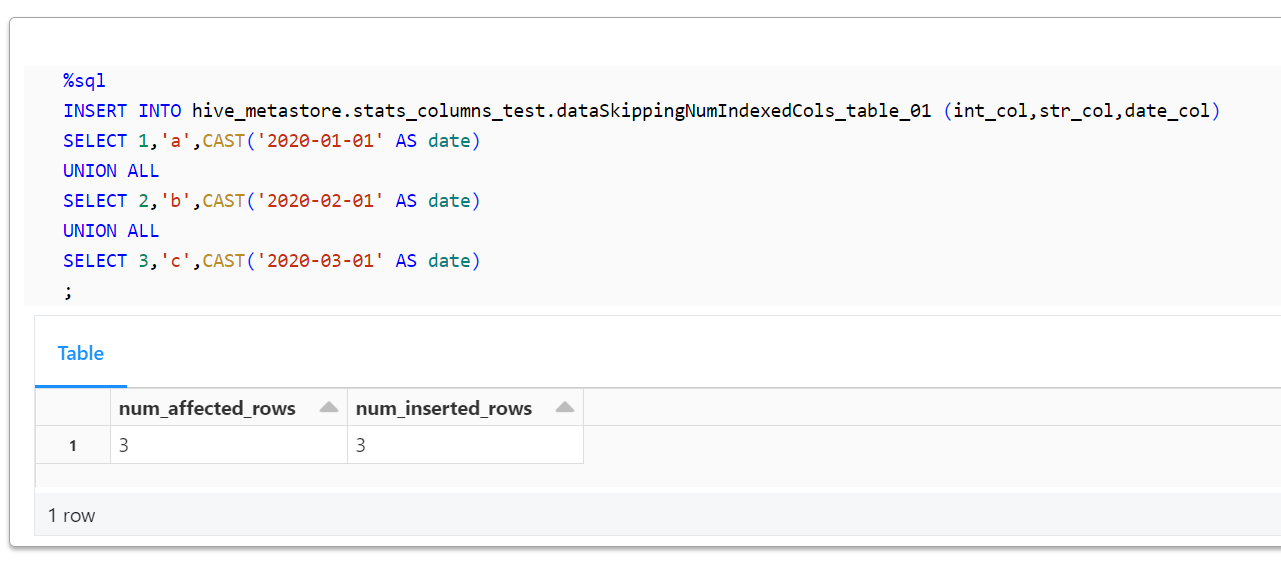
%sql
INSERT INTO hive_metastore.stats_columns_test.dataSkippingNumIndexedCols_table_01 (int_col,str_col,date_col)
SELECT 1,'a',CAST('2020-01-01' AS date)
UNION ALL
SELECT 2,'b',CAST('2020-02-01' AS date)
UNION ALL
SELECT 3,'c',CAST('2020-03-01' AS date)
;
テーブルのディレクトリ(Loacation)を取得します。
tgt_table_name = "hive_metastore.stats_columns_test.dataSkippingNumIndexedCols_table_01"
# テーブルの Location を取得
result = spark.sql(f"DESCRIBE EXTENDED {tgt_table_name}").collect()
table_location = next(row.data_type for row in result if row.col_name == "Location")
print(table_location)

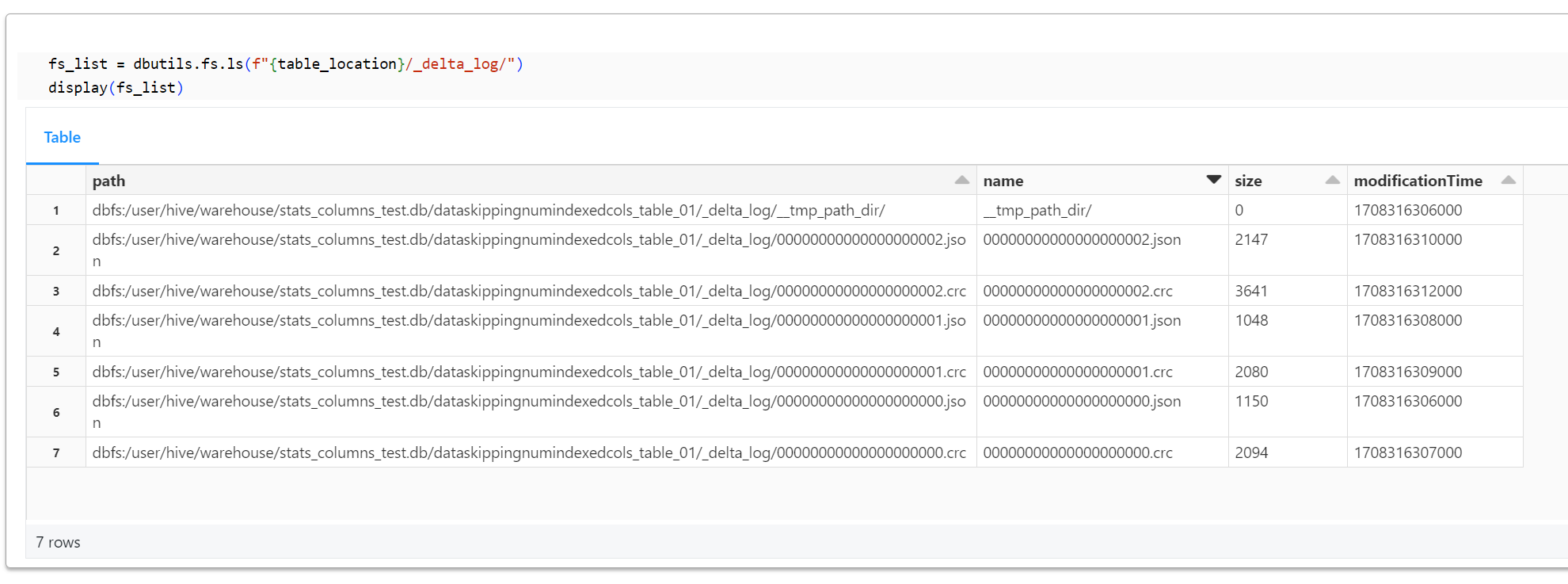
テーブルのディレクトリ(Loacation)配下にある_delta_logフォルダのオブジェクトを表示します。crc ファイルの最新が00000000000000000002.crcであることを確認できます。
fs_list = dbutils.fs.ls(f"{table_location}/_delta_log/")
display(fs_list)
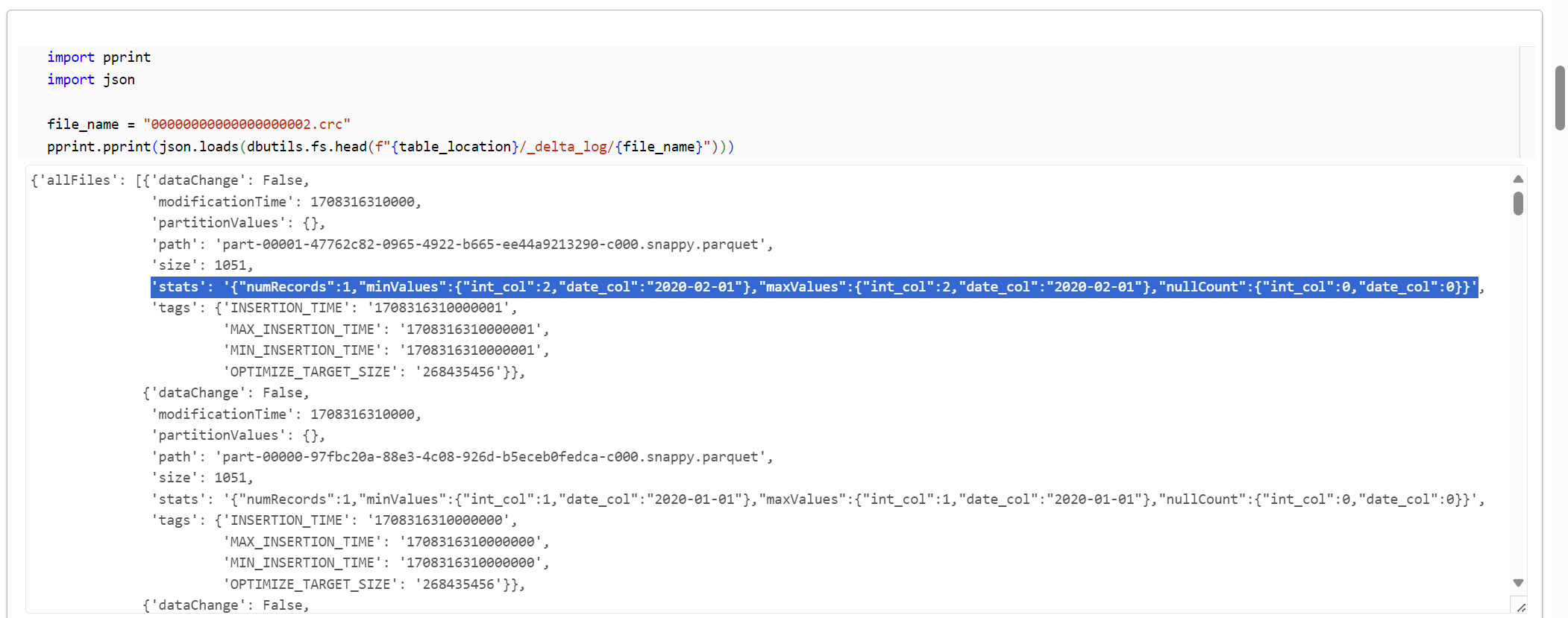
00000000000000000002.crcのデータを表示します。
import pprint
import json
file_name = "00000000000000000002.crc"
pprint.pprint(json.loads(dbutils.fs.head(f"{table_location}/_delta_log/{file_name}")))
その他の検証
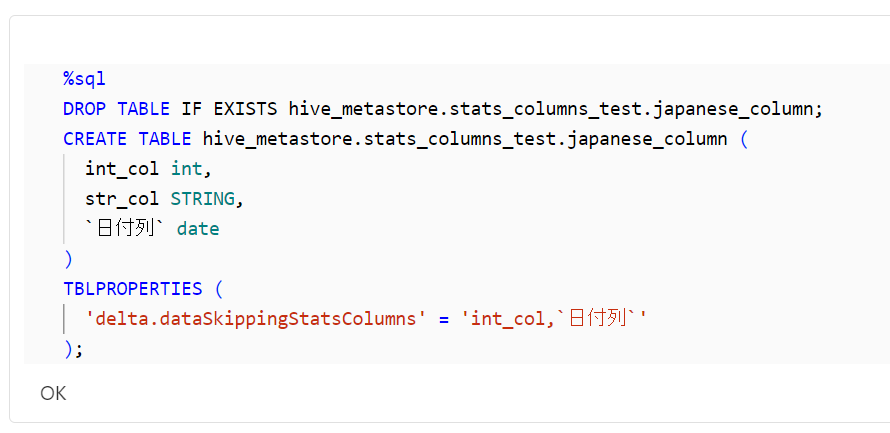
delta.dataSkippingStatsColumnsプロパティにて日本語カラムの指定可否
日本語のカラム名でも、想定通りに統計情報を取得できていること確認できました。
%sql
DROP TABLE IF EXISTS hive_metastore.stats_columns_test.japanese_column;
CREATE TABLE hive_metastore.stats_columns_test.japanese_column (
int_col int,
str_col STRING,
`日付列` date
)
TBLPROPERTIES (
'delta.dataSkippingStatsColumns' = 'int_col,`日付列`'
);
%sql
INSERT INTO hive_metastore.stats_columns_test.japanese_column (int_col,`日付列`,str_col)
SELECT 1,CAST('2020-01-01' AS date),'a'
UNION ALL
SELECT 2,CAST('2020-02-01' AS date),'b'
UNION ALL
SELECT 3,CAST('2020-03-01' AS date),'c'

tgt_table_name = "hive_metastore.stats_columns_test.japanese_column"
import pprint
import json
# テーブルの Location を取得
result = spark.sql(f"DESCRIBE EXTENDED {tgt_table_name}").collect()
table_location = next(row.data_type for row in result if row.col_name == "Location")
print(table_location)
file_name = "00000000000000000001.crc"
pprint.pprint(json.loads(dbutils.fs.head(f"{table_location}/_delta_log/{file_name}")))

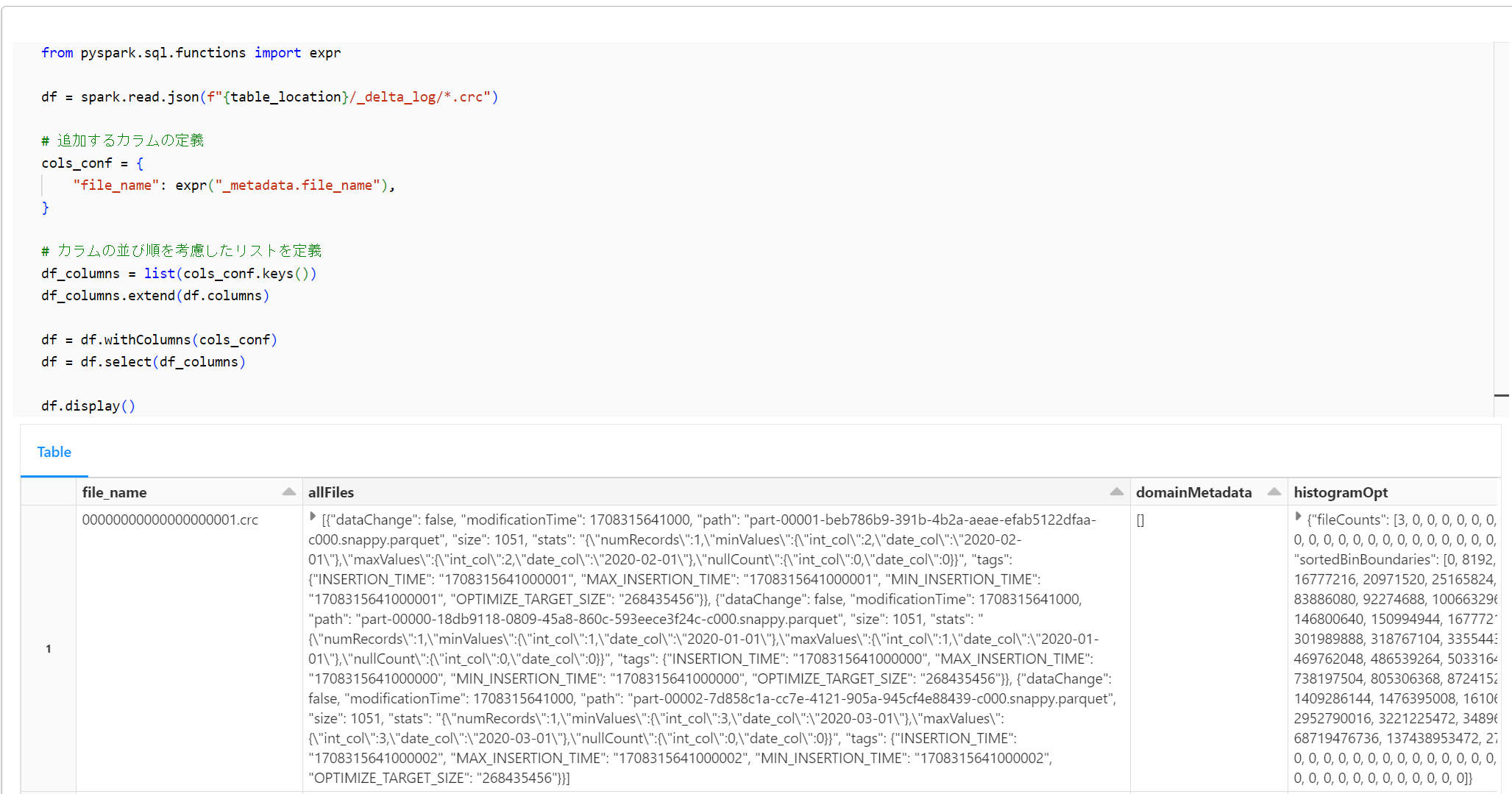
crc ファイルをデータフレームで表示
下記のコード群にて、crc ファイルをデータフレームとして表示します。
tgt_table_name = "hive_metastore.stats_columns_test.dataSkippingStatsColumns_table_01"
# テーブルの Location を取得
result = spark.sql(f"DESCRIBE EXTENDED {tgt_table_name}").collect()
table_location = next(row.data_type for row in result if row.col_name == "Location")
print(table_location)

from pyspark.sql.functions import expr
df = spark.read.json(f"{table_location}/_delta_log/*.crc")
# 追加するカラムの定義
cols_conf = {
"file_name": expr("_metadata.file_name"),
}
# カラムの並び順を考慮したリストを定義
df_columns = list(cols_conf.keys())
df_columns.extend(df.columns)
df = df.withColumns(cols_conf)
df = df.select(df_columns)
df.display()
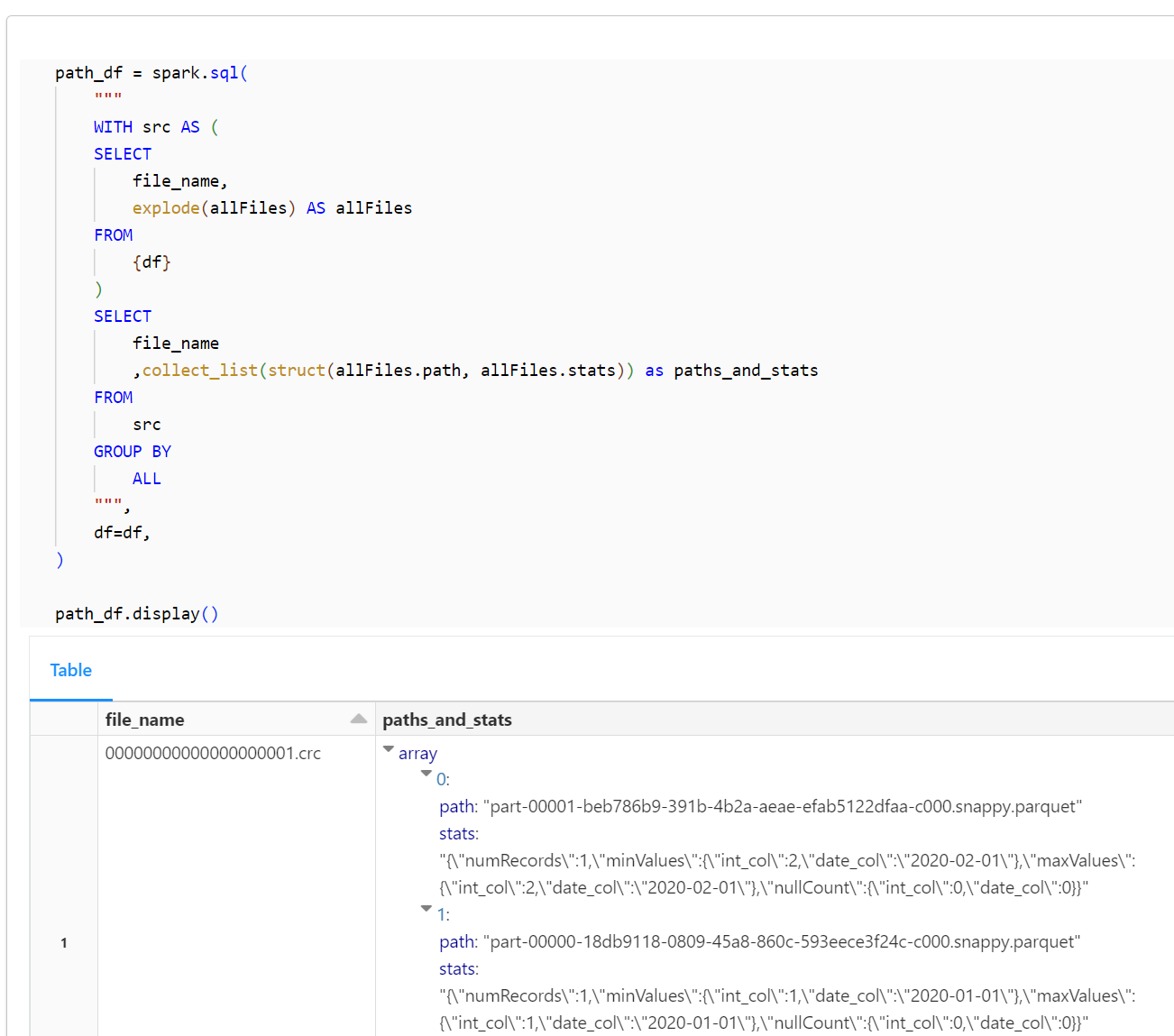
path_df = spark.sql(
"""
WITH src AS (
SELECT
file_name,
explode(allFiles) AS allFiles
FROM
{df}
)
SELECT
file_name
,collect_list(struct(allFiles.path, allFiles.stats)) as paths_and_stats
FROM
src
GROUP BY
ALL
""",
df=df,
)
path_df.display()
事後処理
スキーマを削除します。
%sql
DROP SCHEMA hive_metastore.stats_columns_test CASCADE;