概要
Databricks(Spark)にてPythonによりテーブルのサイズを確認する方法を紹介します。
DatabricksのドキュメントにてScalaでテーブルサイズを確認する方法が紹介されており、Python(PySpark)に置き換えました。
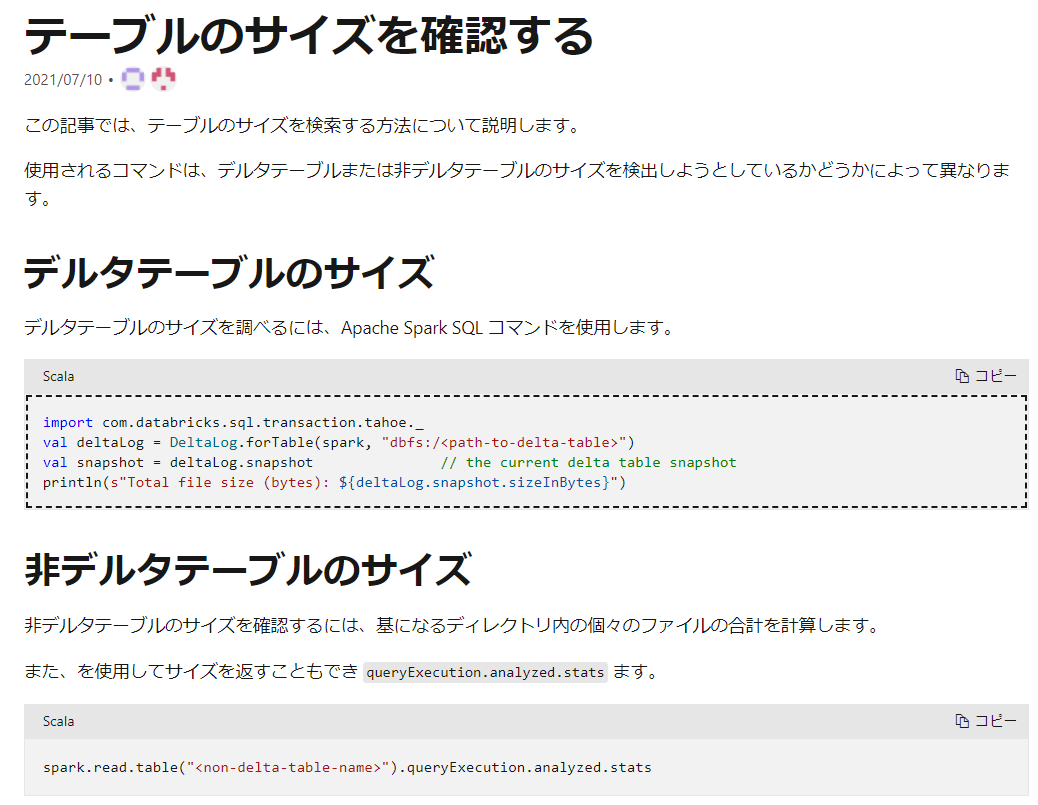
引用元:テーブルのサイズの検索-Azure Databricks - Workspace | Microsoft Docs
Delta lake形式とその他の形式で取得方法が異なり、Delta Lake形式ではdescribe detailを利用するように変更しております。おそらくOSSのdelta lakeを利用している場合にもデータが取得できるはずです。
Delta Lake形式におけるデータフレーム・テーブルのサイズを確認する方法
Scalaでの実行例
%scala
import com.databricks.sql.transaction.tahoe._
val table_size = DeltaLog.forTable(spark, "dbfs:/tmp/qiita/flights/summary-data/delta").snapshot.sizeInBytes
println(s"Total file size (bytes): ${table_size}")

テーブル名を指定する方法
# テーブル名を指定する方法
table_name = 'flights_summary_data'
table_size = spark.sql(f'describe detail {table_name}').select('sizeInBytes').first()[0]
print(f"Total file size (bytes): {table_size}")

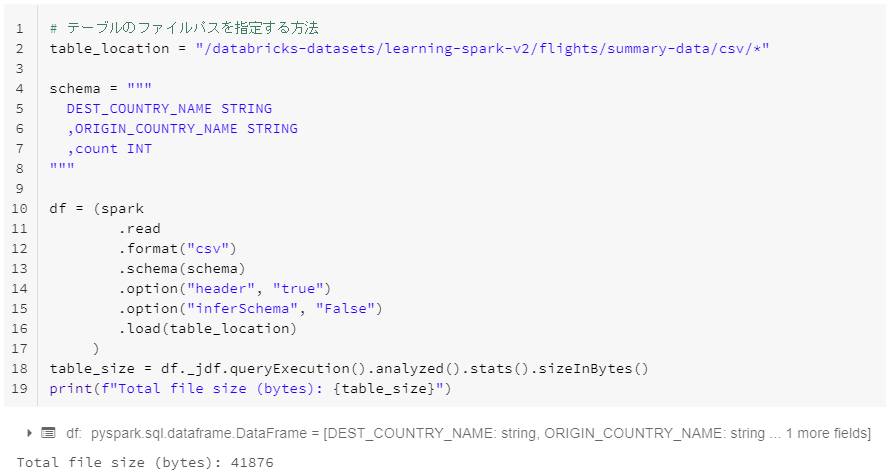
テーブルのファイルパスを指定する方法
# テーブルのファイルパスを指定する方法
table_location = '"dbfs:/tmp/qiita/flights/summary-data/delta"'
table_size = spark.sql(f'describe detail {table_location}').select('sizeInBytes').first()[0]
print(f"Total file size (bytes): {table_size}")

Delta Lake形式以外(Parquet・CSV・Json等)におけるデータフレーム・テーブルのサイズを確認する方法
Scalaでの実行例
%scala
spark.read.table("flights_summary_data_parquet").queryExecution.analyzed.stats.sizeInBytes

テーブル名を指定する方法
# テーブル名を指定する方法
table_name = 'flights_summary_data_parquet'
table_size = spark.read.table(table_name)._jdf.queryExecution().analyzed().stats().sizeInBytes()
print(f"Total file size (bytes): {table_size}")

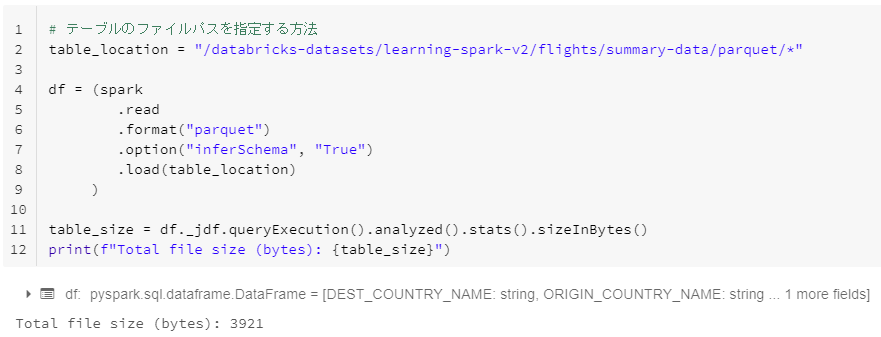
テーブルのファイルパスを指定する方法
# テーブルのファイルパスを指定する方法
table_location = "/databricks-datasets/learning-spark-v2/flights/summary-data/parquet/*"
df = (spark
.read
.format("parquet")
.option("inferSchema", "True")
.load(table_location)
)
table_size = df._jdf.queryExecution().analyzed().stats().sizeInBytes()
print(f"Total file size (bytes): {table_size}")
その他
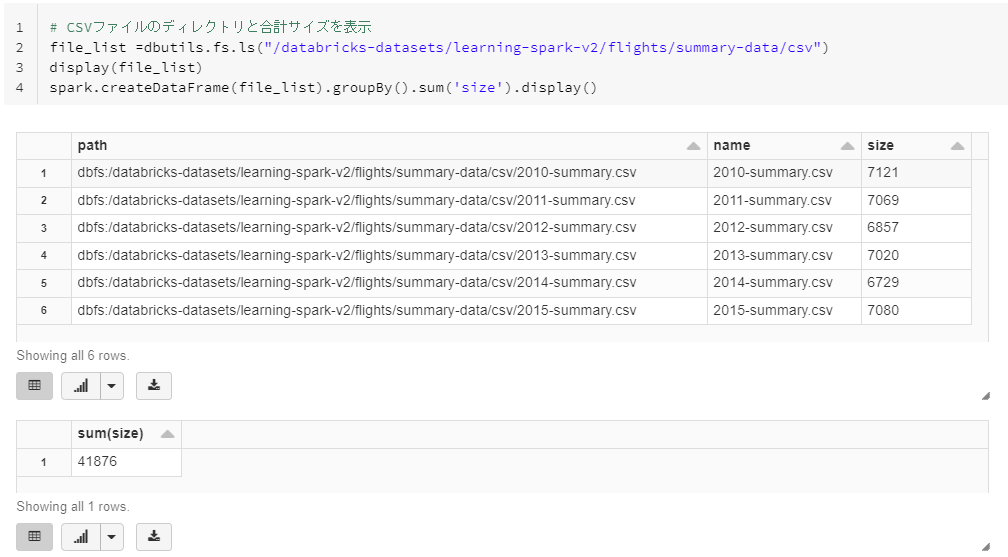
CSV形式のデータフレームのサイズを確認する方法
# CSVファイルのディレクトリと合計サイズを表示
file_list =dbutils.fs.ls("/databricks-datasets/learning-spark-v2/flights/summary-data/csv")
display(file_list)
spark.createDataFrame(file_list).groupBy().sum('size').display()
# テーブルのファイルパスを指定する方法
table_location = "/databricks-datasets/learning-spark-v2/flights/summary-data/csv/*"
schema = """
DEST_COUNTRY_NAME STRING
,ORIGIN_COUNTRY_NAME STRING
,count INT
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("header", "true")
.option("inferSchema", "False")
.load(table_location)
)
table_size = df._jdf.queryExecution().analyzed().stats().sizeInBytes()
print(f"Total file size (bytes): {table_size}")