概要
Databricks Certified Data Engineer Associate 模擬試験が次のリンク先にて公開されているのですが、json 内の Array 型カラムへのクエリ実行に関する問題のサンプルコードを共有します。
次の問題が SQL によるクエリを選択する問題となっており、実際の挙動のイメージがつかない場合には本記事を参考に理解を深めてください。
- Question 20
- Question 21
サンプルコード
Question 20
模擬試験の Question 20 にて次のような問題があります。
Question 20
A junior data engineer has ingested a JSON file into a table raw_table with the following
schema:
cart_id STRING,
items ARRAY<item_id:STRING>
The junior data engineer would like to unnest the items column in raw_table to result in a
new table with the following schema:
cart_id STRING,
item_id STRING
Which of the following commands should the junior data engineer run to complete this
task?
A. SELECT cart_id, filter(items) AS item_id FROM raw_table;
B. SELECT cart_id, flatten(items) AS item_id FROM raw_table;
C. SELECT cart_id, reduce(items) AS item_id FROM raw_table;
D. SELECT cart_id, explode(items) AS item_id FROM raw_table;
E. SELECT cart_id, slice(items) AS item_id FROM raw_table;
引用元:PracticeExam-DataEngineerAssociate (databricks.com)
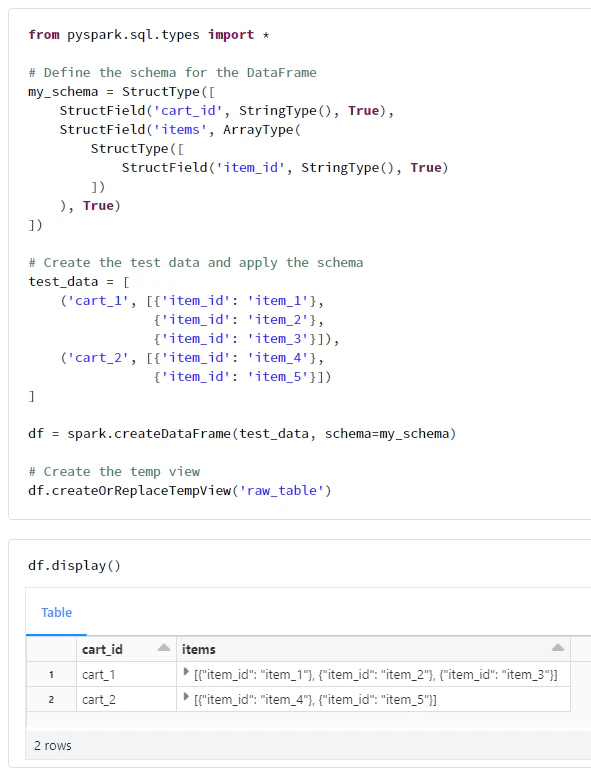
問題と同じカラムをもつ一時ビューを作成します。
from pyspark.sql.types import *
# Define the schema for the DataFrame
my_schema = StructType([
StructField('cart_id', StringType(), True),
StructField('items', ArrayType(
StructType([
StructField('item_id', StringType(), True)
])
), True)
])
# Create the test data and apply the schema
test_data = [
('cart_1', [{'item_id': 'item_1'},
{'item_id': 'item_2'},
{'item_id': 'item_3'}]),
('cart_2', [{'item_id': 'item_4'},
{'item_id': 'item_5'}])
]
df = spark.createDataFrame(test_data, schema=my_schema)
# Create the temp view
df.createOrReplaceTempView('raw_table')
df.display()
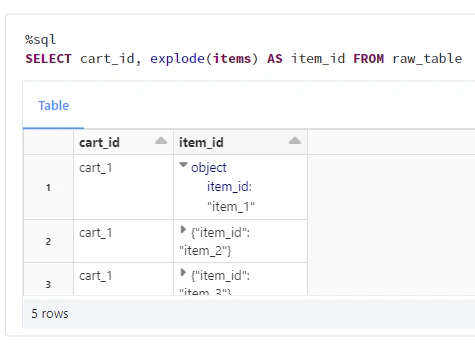
答えとなるクエリを実行します。
%sql
SELECT cart_id, explode(items) AS item_id FROM raw_table
Question 21
模擬試験の Question 21 にて次のような問題があります。
Question 21
A data engineer has ingested a JSON file into a table raw_table with the following schema:
transaction_id STRING,
payload ARRAY<customer_id:STRING, date:TIMESTAMP, store_id:STRING>
The data engineer wants to efficiently extract the date of each transaction into a table with
the following schema:
transaction_id STRING,
date TIMESTAMP
Which of the following commands should the data engineer run to complete this task?
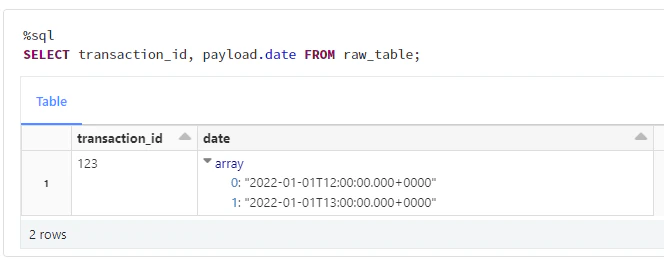
A. SELECT transaction_id, explode(payload) FROM raw_table;
B. SELECT transaction_id, payload.date FROM raw_table;
C. SELECT transaction_id, date FROM raw_table;
D. SELECT transaction_id, payload[date] FROM raw_table;
E. SELECT transaction_id, date from payload FROM raw_table;
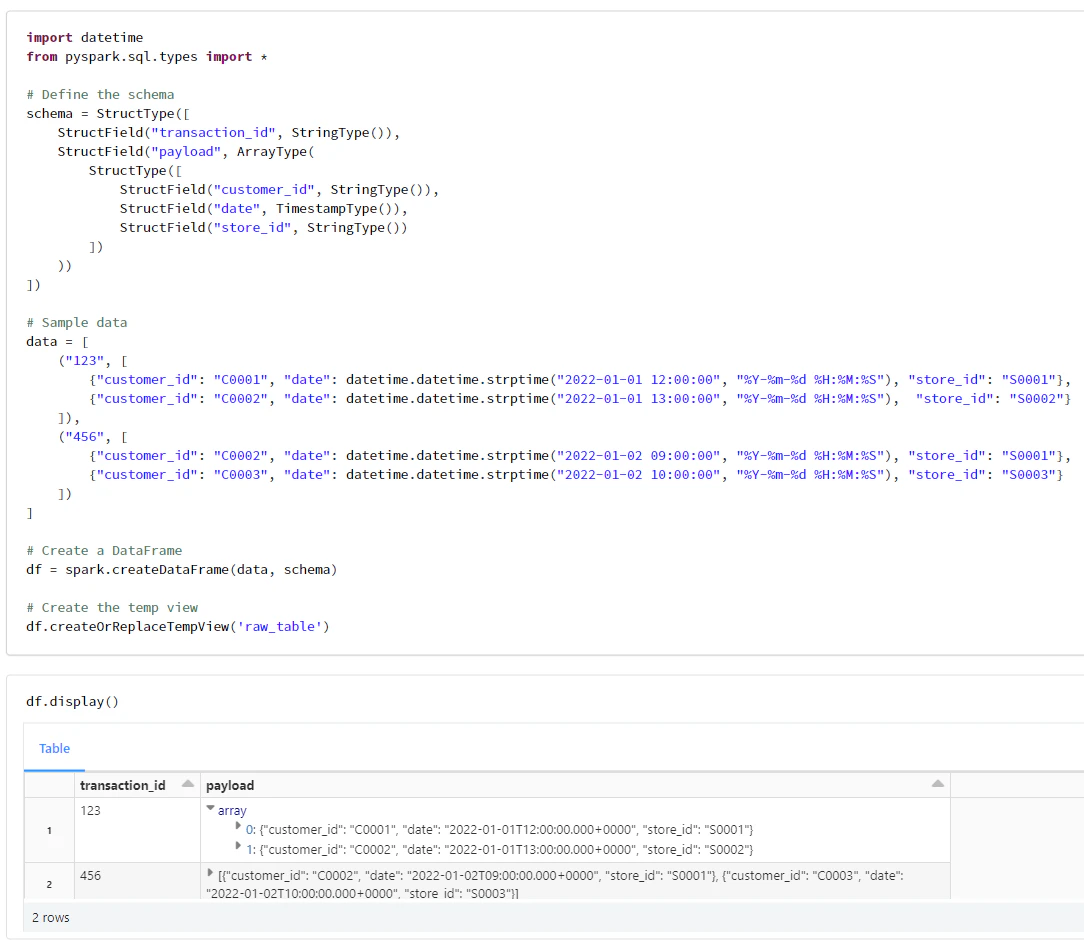
問題と同じカラムをもつ一時ビューを作成します。
import datetime
from pyspark.sql.types import *
# Define the schema
schema = StructType([
StructField("transaction_id", StringType()),
StructField("payload", ArrayType(
StructType([
StructField("customer_id", StringType()),
StructField("date", TimestampType()),
StructField("store_id", StringType())
])
))
])
# Sample data
data = [
("123", [
{"customer_id": "C0001", "date": datetime.datetime.strptime("2022-01-01 12:00:00", "%Y-%m-%d %H:%M:%S"), "store_id": "S0001"},
{"customer_id": "C0002", "date": datetime.datetime.strptime("2022-01-01 13:00:00", "%Y-%m-%d %H:%M:%S"), "store_id": "S0002"}
]),
("456", [
{"customer_id": "C0002", "date": datetime.datetime.strptime("2022-01-02 09:00:00", "%Y-%m-%d %H:%M:%S"), "store_id": "S0001"},
{"customer_id": "C0003", "date": datetime.datetime.strptime("2022-01-02 10:00:00", "%Y-%m-%d %H:%M:%S"), "store_id": "S0003"}
])
]
# Create a DataFrame
df = spark.createDataFrame(data, schema)
# Create the temp view
df.createOrReplaceTempView('raw_table')
df.display()
答えとなるクエリを実行します。
%sql
SELECT transaction_id, payload.date FROM raw_table;