概要
本記事では、GitHub Copilot を活用して Databricks の開発を効率化する方法について詳しく解説します。通常、Databricks Workspace 上で直接 GitHub Copilot を利用することはできません。しかし、ローカル環境で GitHub Copilot を使用し、そのコードを Databricks Workspace と同期することで、より生産的な開発が可能になります。この方法を用いることで、コーディングの効率化やエラーの早期発見が期待でき、開発全体の生産性向上につながります。
コードを Databricks Workspace に同期するには、Databricks 拡張機能を利用します。環境構築の手順については、以下の記事を参考にするとスムーズに進められます。
引用元: Databricks extension for Visual Studio Code v2 の環境構築方法 #Python - Qiita
開発の基本的な流れ
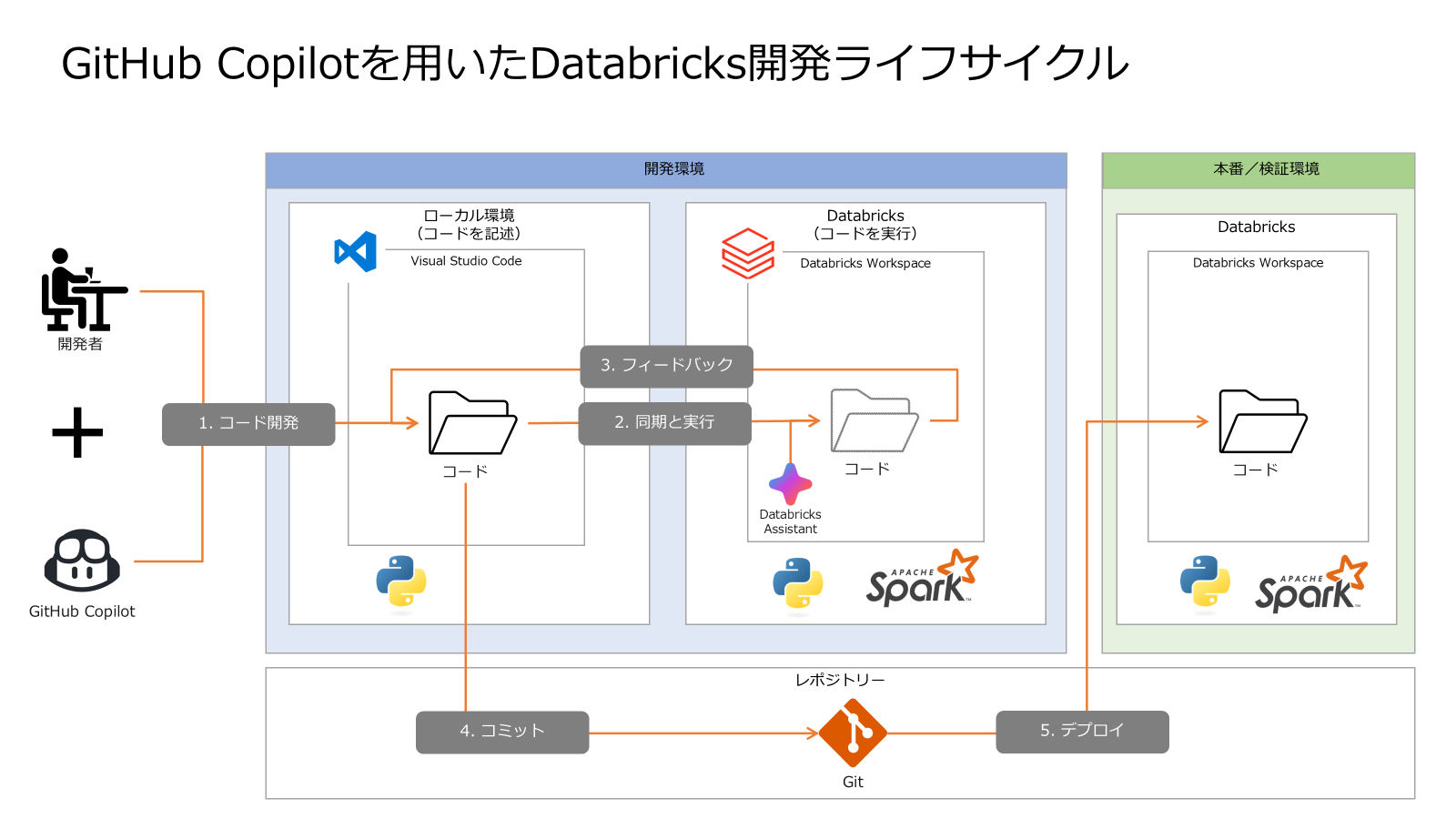
GitHub Copilot を活用した Databricks 開発の基本的な手順は以下の通りです。この流れを理解することで、効率的かつ効果的な開発が可能になります。
| ステップ | 内容 | 詳細 |
|---|---|---|
| 1. コード開発 | ローカル環境でのコード記述 | 開発者と GitHub Copilot の協働により、Visual Studio Code でコードを作成します。 |
| 2. 同期と実行 | Databricks でのコード実行 | 記述したコードを Databricks Workspace に同期し、コードを実行します。エラー修正には Databricks Assistant を活用します。 |
| 3. フィードバック | 実行結果の確認と修正 | 実行結果を詳細に確認し、必要に応じてコードを修正します。 |
| 4. コミット | Git リポジトリにコミット | 修正後のコードを Git リポジトリにコミットし、バージョン管理と共有を行います。 |
| 5. デプロイ | 本番/検証環境へのデプロイ | 完成したコードを検証環境や本番環境に反映し、最終的な検証や運用を行います。 |
開発の詳細
1. コード開発
まず、ローカル環境で GitHub Copilot を活用してコードを記述します。Visual Studio Code を使用することで、コード補完やエラーチェックなどの機能を最大限に活用できます。以前の記事で紹介したように、以下の3種類のコードとそれに対するテストコードを作成します。
- Utilities(ユーティリティ): 共通で使用する関数やクラスをまとめたコード。
- Runner Notebook: 処理の設定値を保持したノートブック。
- Executor Notebook: 実際の処理を行うノートブック。
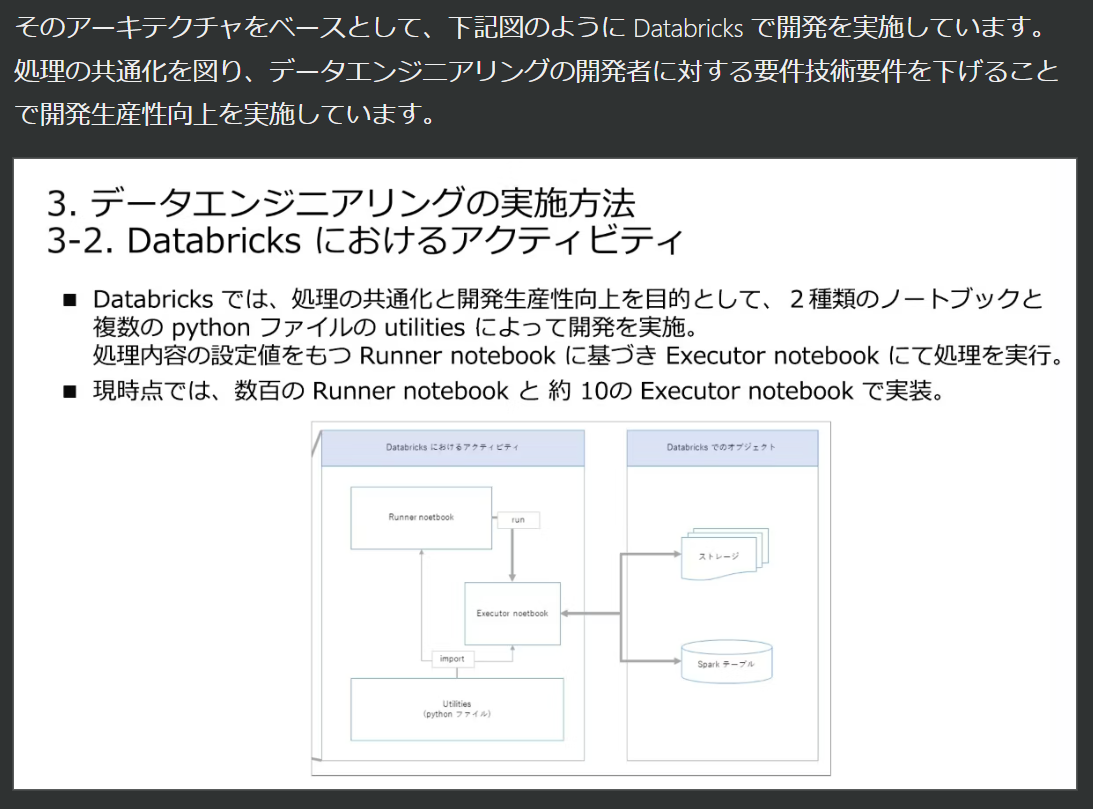
引用元:誰も教えてくれないメダリオンアーキテクチャのデザインメソッド:JEDA データエンジニア分科会 #1 #Python - Qiita
ユーティリティやテストコードはローカル環境内で完結することが多く、素早く開発とテストが行えます。一方、Runner ノートブックや Executor ノートブックについては、Databricks 環境での実行が必要になるため、後述のフィードバックステップでコードを反映していきます。
ノートブック形式のコードをゼロから記述するのは大変な作業になることがあります。そのため、ローカル環境と Databricks Workspace を行き来しながら、効率的に開発を進めることをおすすめします。
2. 同期と実行
ローカル環境で記述したコードを Databricks Workspace に同期し、実際にコードを実行します。同期には Visual Studio Code の Databricks 拡張機能を利用します。この拡張機能により、コードの変更がリアルタイムで Databricks Workspace に反映されるため、タイムラグを感じることなく開発を進められます。
コードを実行する際、期待通りに動作しないこともあります。その場合、エラーメッセージを確認し、問題の箇所を特定します。Typo(タイプミス)などの単純なエラーであれば、Databricks Assistant が自動的に修正提案を行ってくれる場合があります。これにより、エラー修正の時間を大幅に短縮できます。
3. フィードバック
Databricks Workspace 上での実行結果を詳細に確認します。結果が期待通りでない場合や、さらなる最適化が必要な場合は、ローカル環境でコードを修正し、再度同期します。
特にノートブックのコードについては、Databricks Workspace 上で修正した方が効率的な場合も多いです。その理由は、Databricks の特定の機能やデータセットに直接アクセスできるためです。このような場合、Workspace 上で修正したコードをエクスポートし、ローカル環境に反映させることで、コードの一貫性を保つことができます。
4. コミット
テストが成功し、安定したコードが完成したら、Git リポジトリにコミットします。バージョン管理を徹底することで、過去の変更履歴を追跡でき、チーム内でのコード共有もスムーズになります。
本記事では単一のリポジトリで運用しているように記述していますが、実際のプロジェクトでは複数のリポジトリを利用することが一般的です。例えば、共通処理のコードを管理するリポジトリと、各メンバーが開発するノートブックを管理するリポジトリを分けることで、責任範囲を明確にできます。
5. デプロイ
最後に、完成したコードを検証環境や本番環境にデプロイします。デプロイの際には、Databricks Workspace 上でのコード実行結果を再度確認し、問題がないことを確実にします。
デプロイ後、実際のデータを用いて最終的な検証を行います。このステップでは、パフォーマンスやセキュリティ、データ整合性など、多角的な視点で検証を行うことが重要です。また、テスト実行用のコードやドキュメントもリポジトリに含めておくことで、将来的なメンテナンスや他の開発者への引き継ぎが容易になります。
まとめ
GitHub Copilot と Databricks の組み合わせにより、Databricks 開発プロセスを大幅に効率化できます。ローカル環境でのコーディングと Databricks Workspace での実行を連携させることで、各環境の強みを活かした開発が可能です。さらに、Git を用いたバージョン管理やチーム開発のベストプラクティスを取り入れることで、プロジェクト全体の品質と生産性を向上させることができます。
今後も新しいツールや機能を積極的に取り入れ、最適な開発フローを追求していきましょう。