概要
Databricks extension for Visual Studio Code v2 の環境構築方法を紹介します。Databricks extension for Visual Studio Code には、新バージョンであるバージョン 2 系統がリリースされました。明示的に v2 とされていませんが、バージョン 1 系統との差異があるため、ここでは v2 として扱います。
バージョン 1 系統を継続的に利用したい場合には、Visual Studio Code 上で過去のバージョンをインストールすることができます。


事前準備
ソフトウェアのインストール
下記のソフトウェアをインストールします。
- Visual Studio Code (VS Code)
- WSL (Ubuntu-22.04 のインストール)
ローカル環境の構築
WSL distro の複製
# Specify the source and target distro names
$src_wsl_distro_name = "Ubuntu-22.04"
$tgt_wsl_distro_name = "databricks-extension"

# Export wsl
$wsl_file_name = $src_wsl_distro_name + ".tar"
wsl --export $src_wsl_distro_name $wsl_file_name

# Import wsl
wsl --import $tgt_wsl_distro_name $tgt_wsl_distro_name $wsl_file_name

# Check wsl dstro list
wsl -l

# Delete distro file
Remove-Item $wsl_file_name

WSL distro におけるデフォルトユーザの設定
# login to wsl distro
wsl -d $tgt_wsl_distro_name -u root

default_user_name はインストール時のユーザ名を指定します。
# Set default user name
default_user_name=manabian

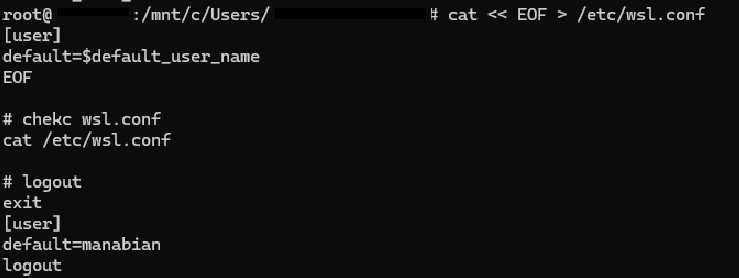
cat << EOF > /etc/wsl.conf
[user]
default=$default_user_name
EOF
# chekc wsl.conf
cat /etc/wsl.conf
# logout
exit
# reboot and re-login
wsl -t $tgt_wsl_distro_name

Miniconda のインストールと設定
# re-login
wsl -d $tgt_wsl_distro_name
# download miniconda
cd
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# install miniconda
bash Miniconda3-latest-Linux-x86_64.sh
インストール時の質問に対しては、次のように回答。
| # | 質問 | 回答 |
|---|---|---|
| 1 | Do you accept the license terms? | yes |
| 2 | Miniconda3 will now be installed into this location | ENTER |
| 3 | Do you wish the installer to initialize Miniconda3 by running conda init? | yes |

Miniconda の channel を conda-forge に変更
exit
# re-login
wsl -d $tgt_wsl_distro_name

現在のチャネル一覧を取得
conda config --get channels

# Add conda-forg channel
conda config --add channels conda-forge
# Delete default channel
conda config --remove channels default

default がなくなり、 conda-forge だけとなっていることを確認
conda config --get channels

Conda 環境の構築
conda create -n dbr-15 python=3.11 -c conda-forge

利用するクラスターのバージョンに合わせて、 python バージョンを変更する必要があります。

引用元:Databricks Connect for Python をインストールする - Azure Databricks | Microsoft Learn
conda activate dbr-15

Databricks extention に必要なライブラリをインストール
Databricks Connect をインストールします。手順作成後に気づいたのですが、ドキュメントにて VS Code に拡張機能をインストールした場合には、 Databricks Connect のインストールが不要である旨の記述をみつけました。本手順は省略可能である可能性があります。
pip install --upgrade "databricks-connect==15.4.*"

Visual Studio Code 用の Databricks 拡張機能には Databricks Connect が含まれているため、Visual Studio Code 用の Databricks 拡張機能をインストールしている場合は、Databricks Connect をインストールする必要はありません。
引用元:Databricks Connect とは - Azure Databricks | Microsoft Learn
Jupyter 関連のライブラリをインストールします。
pip install ipython ipykernel

pytest をインストールします。
pip install pytest

unzip をインストールします。
sudo apt update && sudo apt install -y unzip

Databricks CLI をインストールします。
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sudo sh

databricks auth login --host
databricks -v

Databricks プロジェクトの作成と設定
作業用ディレクトリを作成
cd
mkdir source
cd source

VS code の設定
VS Code を起動します。
code .

Databricks extension を WSL にインストールします。

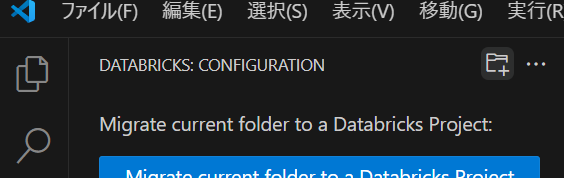
Databricks プロジェクトを作成
VS Code にて左側タブにある Databricks -> フォルダとプラスのロゴ(Initialize a new project)を選択します。
Databricks Workspace の URL を入力します。
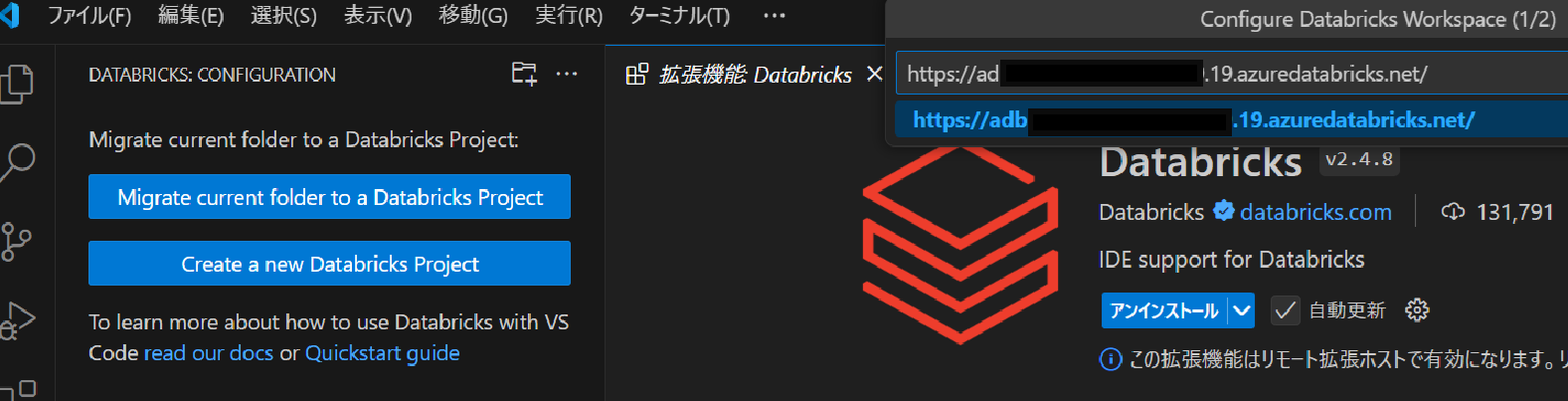
認証方法を選択します。私は OAuth を選択しました。

DEFAULT と入力します。

<暫定対応ここから>
上記方法で初回の検証時は動作したのですが、 OAuth 認証が想定通りにいかず CLI にてプロファイルを作成する下記手順を実施しました。
databricks auth login --host {workspace_url}

ブラウザにて、認証を実施します。

Databricks extension にて作成したプロファイルを選択します。
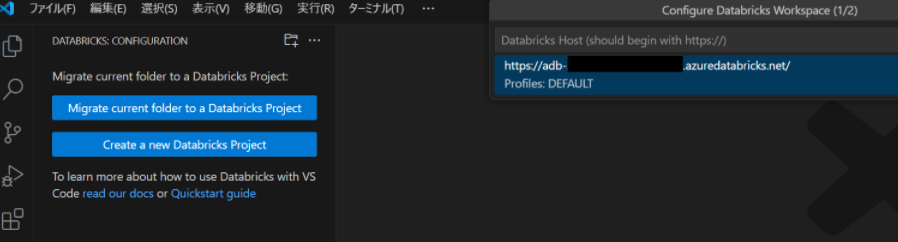
<暫定対応ここまで>
プロジェクトを作成するディレクトリを指定します。
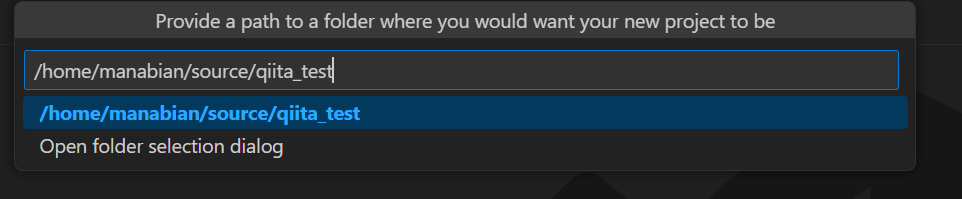
VS Code の Editor 画面にて、 Databricks Project の設定値を入力します。default-python のテンプレートにて、任意の名前を設定した上で、それ以外の項目を yes と入力します。


Databricks プロジェクトの作成が完了した旨のメッセージ表示後、 Enter を入力して Databricks プロジェクトの作成画面を閉じます。
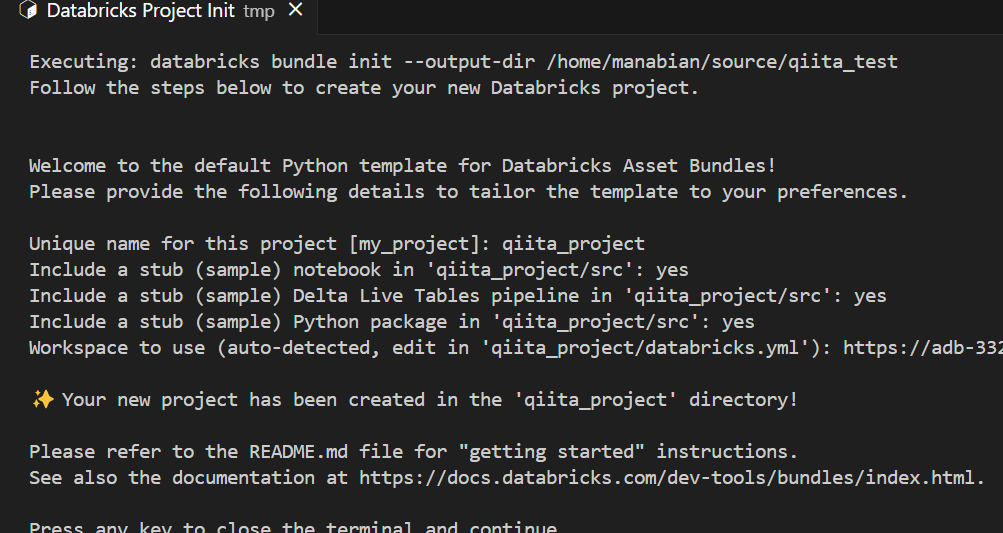
クラスターの設定
VS Code 左側タブにある Databricks -> Select a clusterを選択し、利用する Databricks クラスターを選択します。

src 配下にある notebook.ipynb を開き、Python カーネルを本手順で作成した python 環境を指定した上で実行できることを確認します。

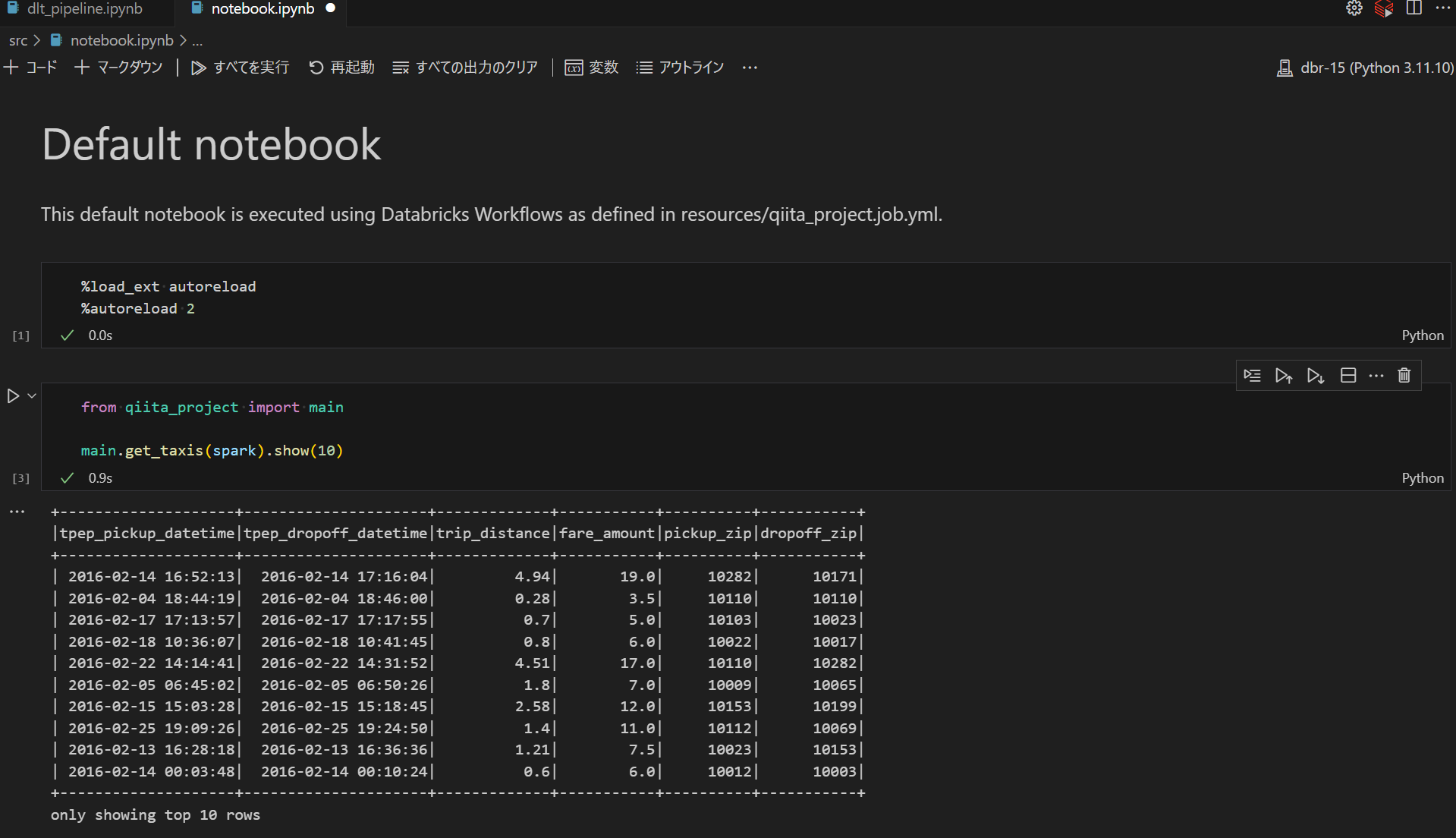
コードの実行
Databricks Workspace 上でコードを実行できることを確認
Databricks -> 読み込みロゴ(Start Synchronization)を選択する。

横にある Open link externally を選択し、 Databricks Workspace に接続します。

ローカル上にあるコードが Databricks Workspace に同期されていることを確認します。
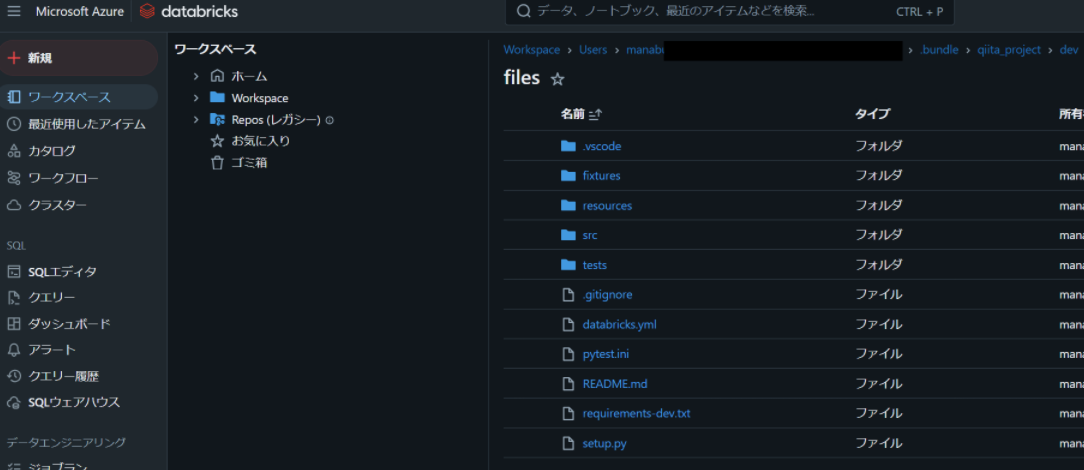
Databricks ノートブックを実行できることを確認します。
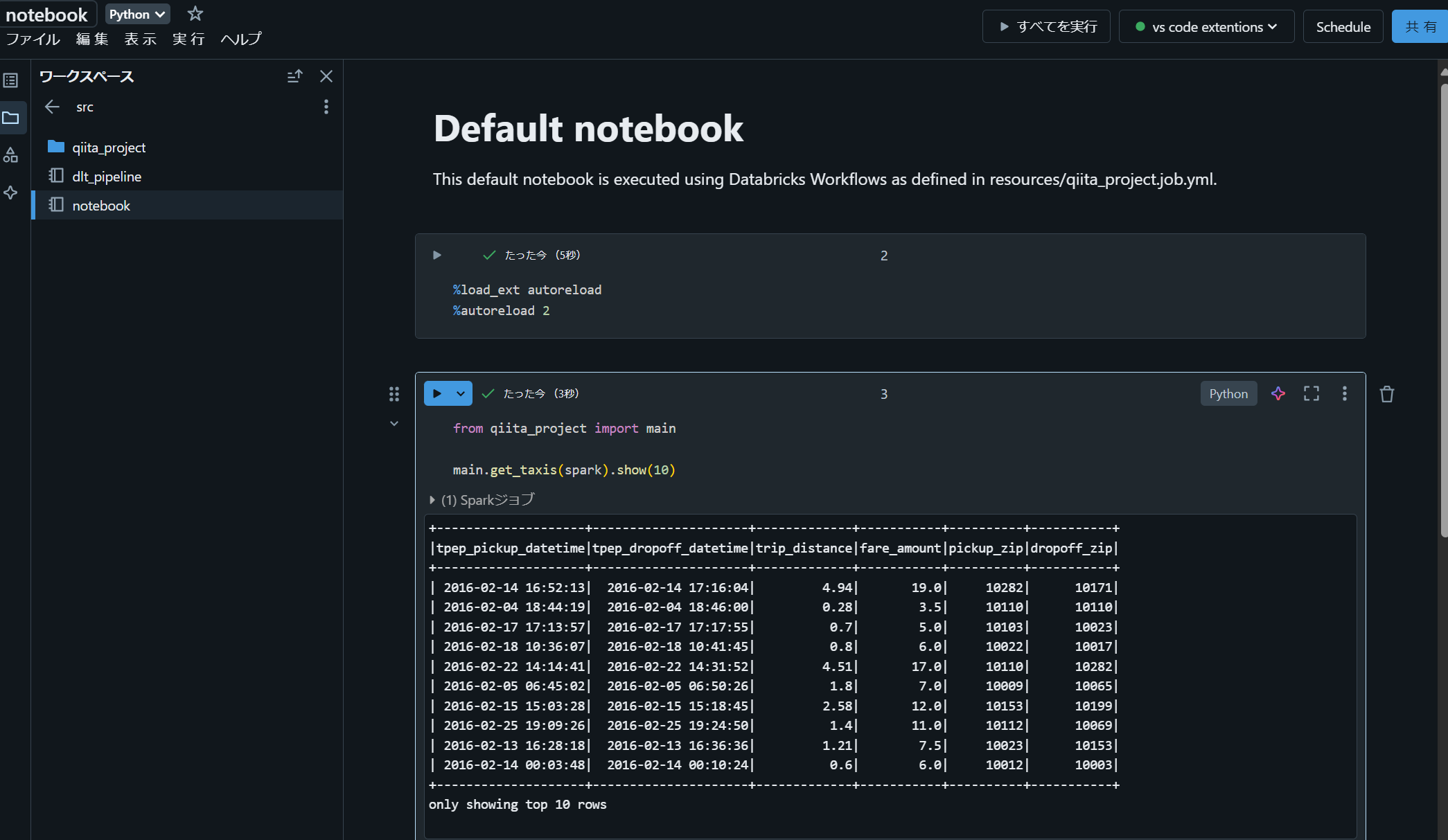
本手順では同期先が通常のフォルダになってしまうため、 Git フォルダに変更する暫定対応方法を下記の記事で紹介しています。
VS Code 上で Python コード を実行できることを確認
VS Code 上で下記コードを記述した demo.py というファイルを作成し、コードを実行できることを確認します。実行する際には右上の Databricks のロゴにて選択できる Run current file with Databricks Connect を選択します。
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)

出力結果がターミナルに表示され、正常に動作していることを確認します。

VS Code 上で Jupyter 形式のノートブックを実行できることを確認
VS Code 上で下記コードを記述した demo2.ipynb というファイルを作成し、コードを実行できることを確認します。
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)

ノートブック実行に関するドキュメントにて、 SparkSession の定義は不要であることが記述されていました。

VS Code 上で Python 形式でノートブックとして実行できることを確認
VS Code 上で下記コードを記述した demo3.py というファイルを作成し、コードを実行できることを確認します。Python ファイルを、インタラクティブにノートブックのように実行するには、コードの上に表示されているセルの実行を選択します。

Test タブを実行できることを確認
VS Code 上で下記の値を記述した .env というファイルを作成します。{profile_name}にはプロファイル名(例:DEFAULT)を、{databricks_cluster_id}には Databricks クラスターの ID を設定します。
DATABRICKS_CONFIG_PROFILE={profile_name}
DATABRICKS_CLUSTER_ID={databricks_cluster_id}
VS Code のテストタブにあるテストを実行し、正常終了することを確認します。
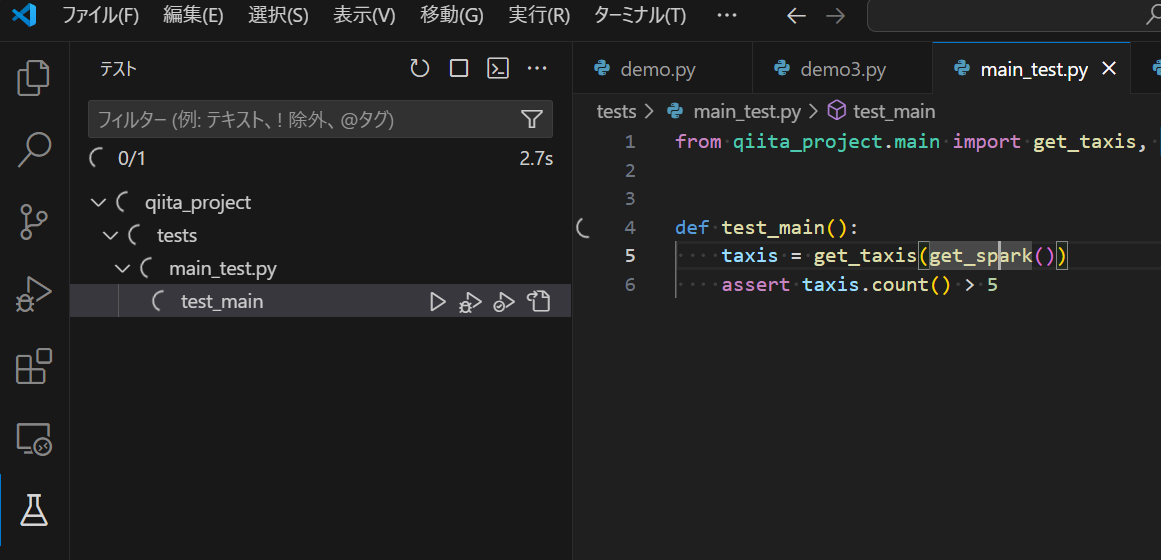

Databricks クラスターへの接続方法として、DATABRICKS_CONFIG_PROFILE 環境変数による方法を実施しています。

引用元:Databricks Connect for Python をインストールする - Azure Databricks | Microsoft Learn
DatabricksSessionクラスとSparkSessionクラスを切り替える方法として、下記の方法がドキュメントにて紹介されています。この基準を行うことで、ローカル(VS Code)上と Databricks Workspace 上のいずれの場合でもコードを実行できそうです。
def get_spark() -> SparkSession:
try:
from databricks.connect import DatabricksSession
return DatabricksSession.builder.getOrCreate()
except ImportError:
return SparkSession.builder.getOrCreate()
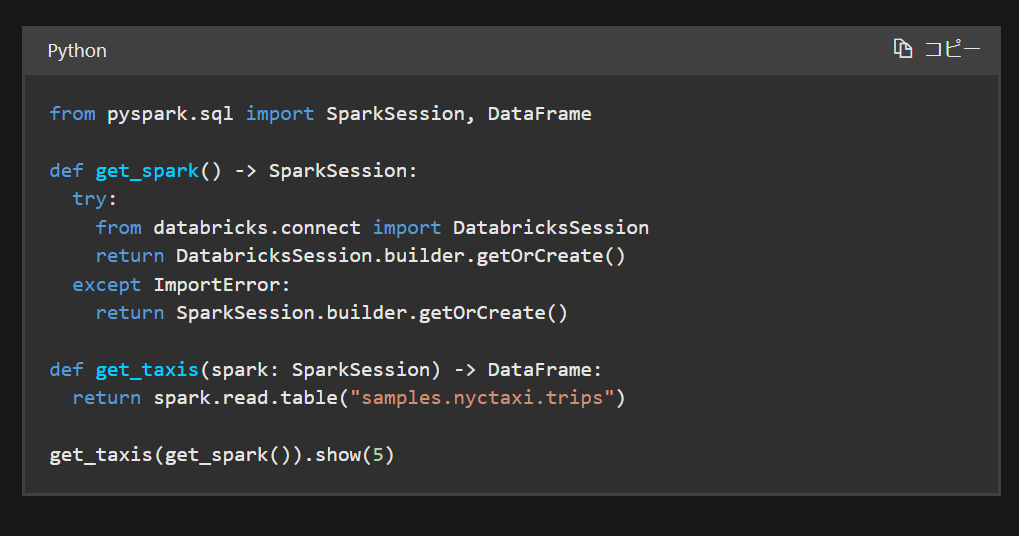
引用元:Databricks Connect for Python のコード例 - Azure Databricks | Microsoft Learn