概要
Databrickのノートブックを、Memsourceを用いて翻訳して、再度Databricksに取り込む手順を紹介します。
ノートブックをコードに変換してから翻訳を実施します。
事前準備
- Python 3 以降のインストール
- Databricks CLIのインストール
- Memsouceの契約とセットアップ
翻訳手順
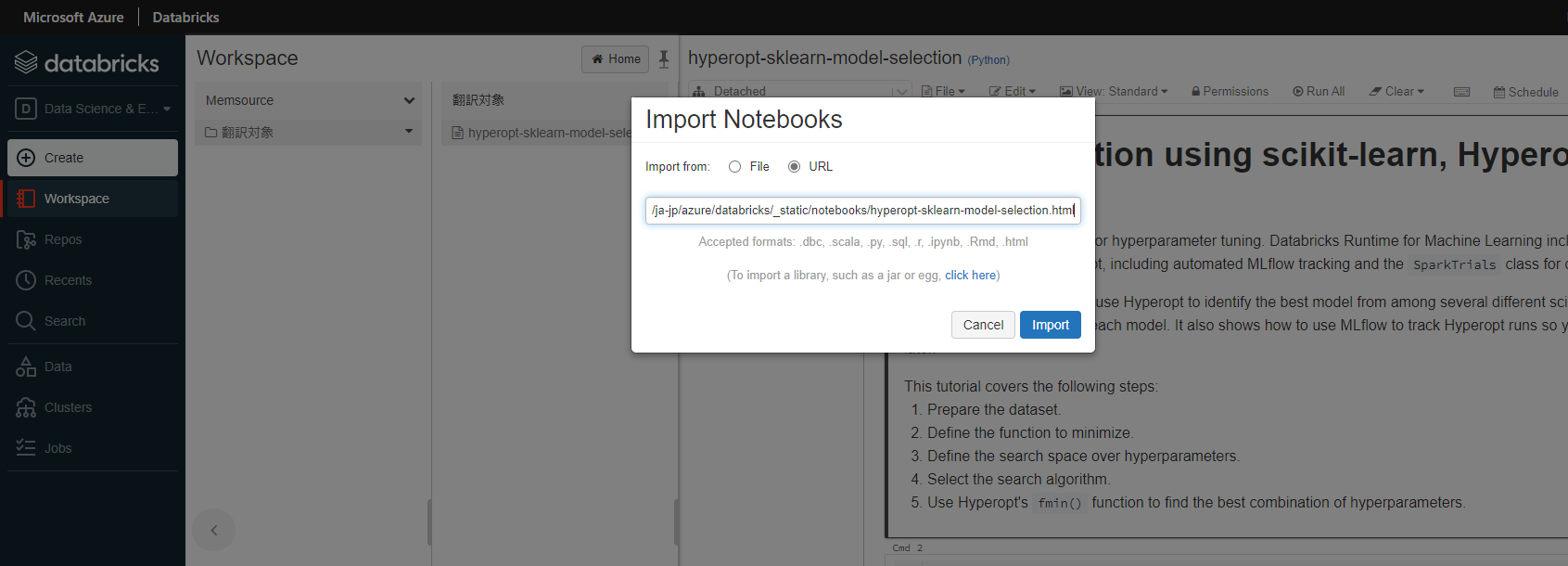
1. Databricksに翻訳対象のノートブックを取り込む
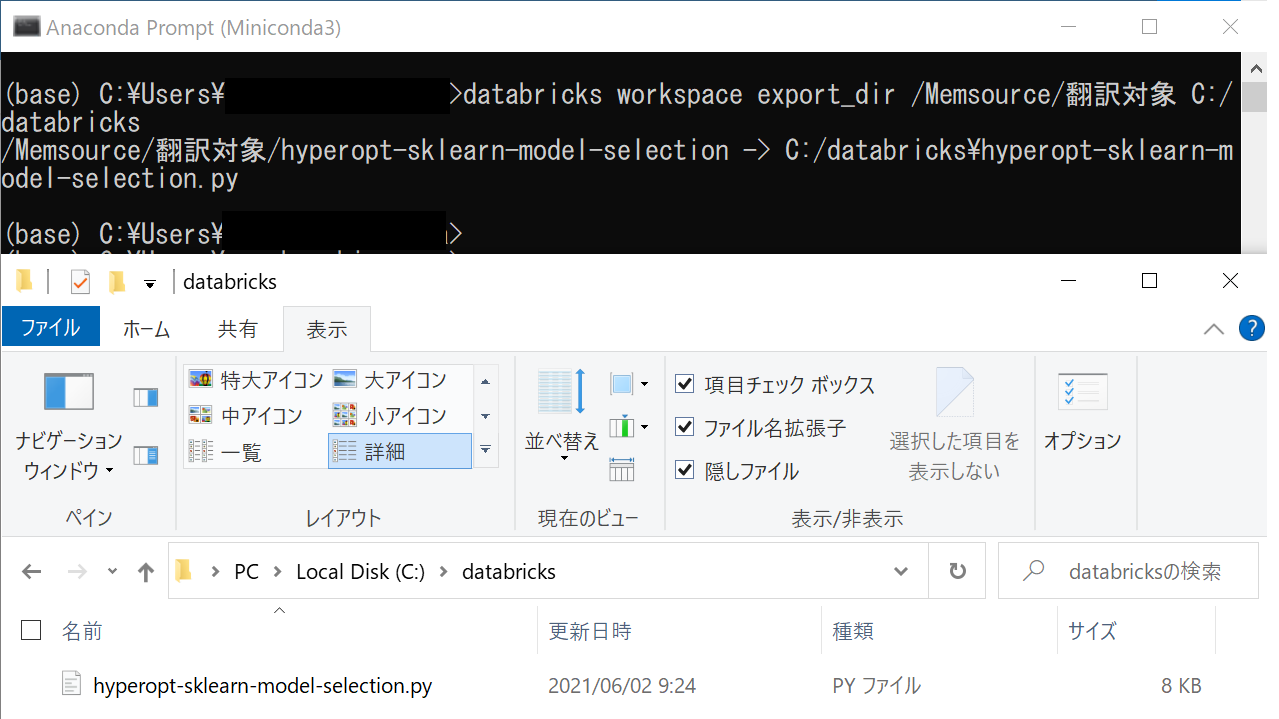
2. Databricks CLIを用いてノートブックをフォルダごとエクスポート
databricks workspace export_dir /Memsource/翻訳対象 C:/databricks
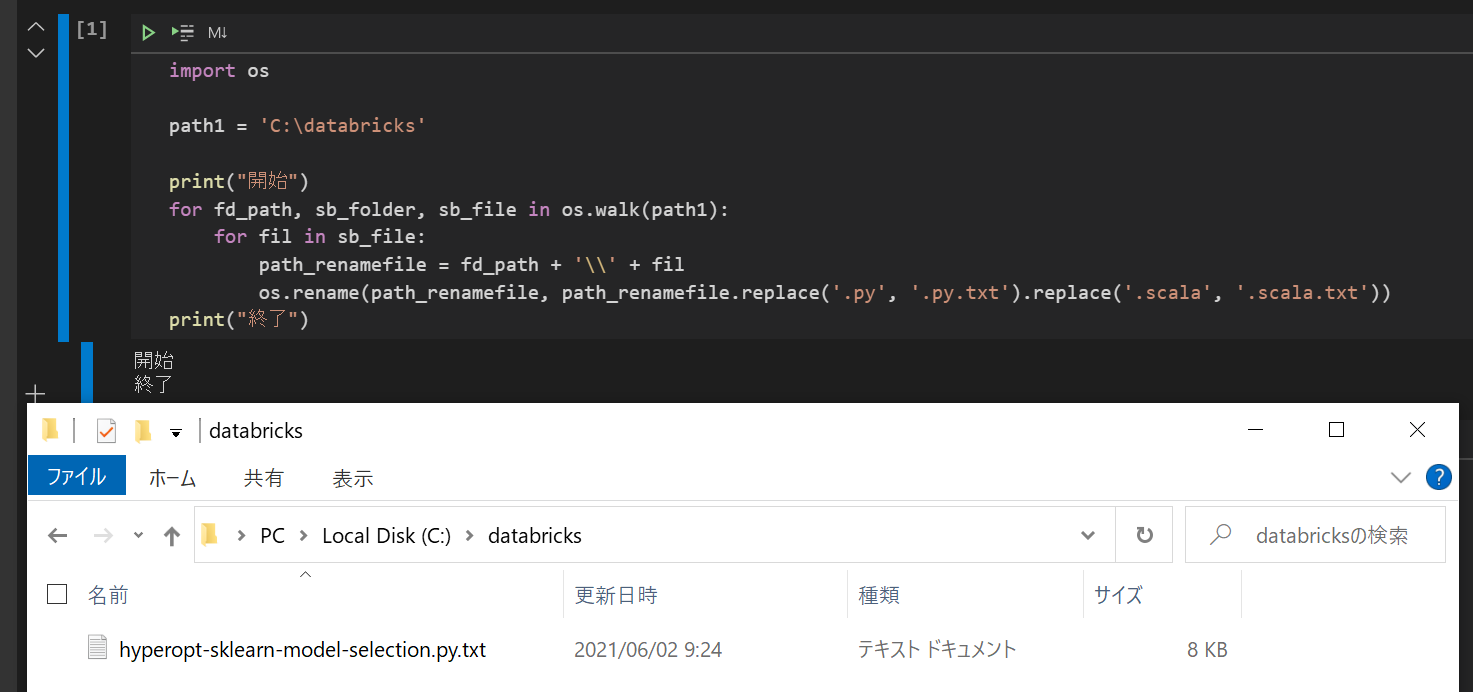
3. Pythonにて拡張子をtxtに変更
import os
path1 = 'C:\databricks'
print("開始")
for fd_path, sb_folder, sb_file in os.walk(path1):
for fil in sb_file:
path_renamefile = fd_path + '\\' + fil
os.rename(path_renamefile, path_renamefile.replace('.py', '.py.txt').replace('.scala', '.scala.txt'))
print("終了")
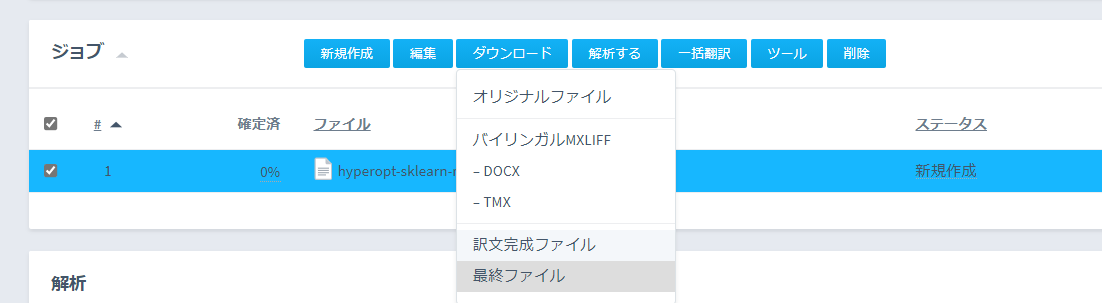
4. Memsourceに取り込み翻訳を実施
フォルダ階層を保持したい場合には、フォルダごとzipによる圧縮したファイルを取り込みを実施してください。

5. Memsourceから翻訳後のファイルをエクスポート
6. 拡張子のtxtを削除
import os
path1 = 'C:\databricks\取り込み'
print("開始")
for fd_path, sb_folder, sb_file in os.walk(path1):
for fil in sb_file:
path_renamefile = fd_path + '\\' + fil
os.rename(path_renamefile, path_renamefile.replace('.txt', ''))
print("終了")
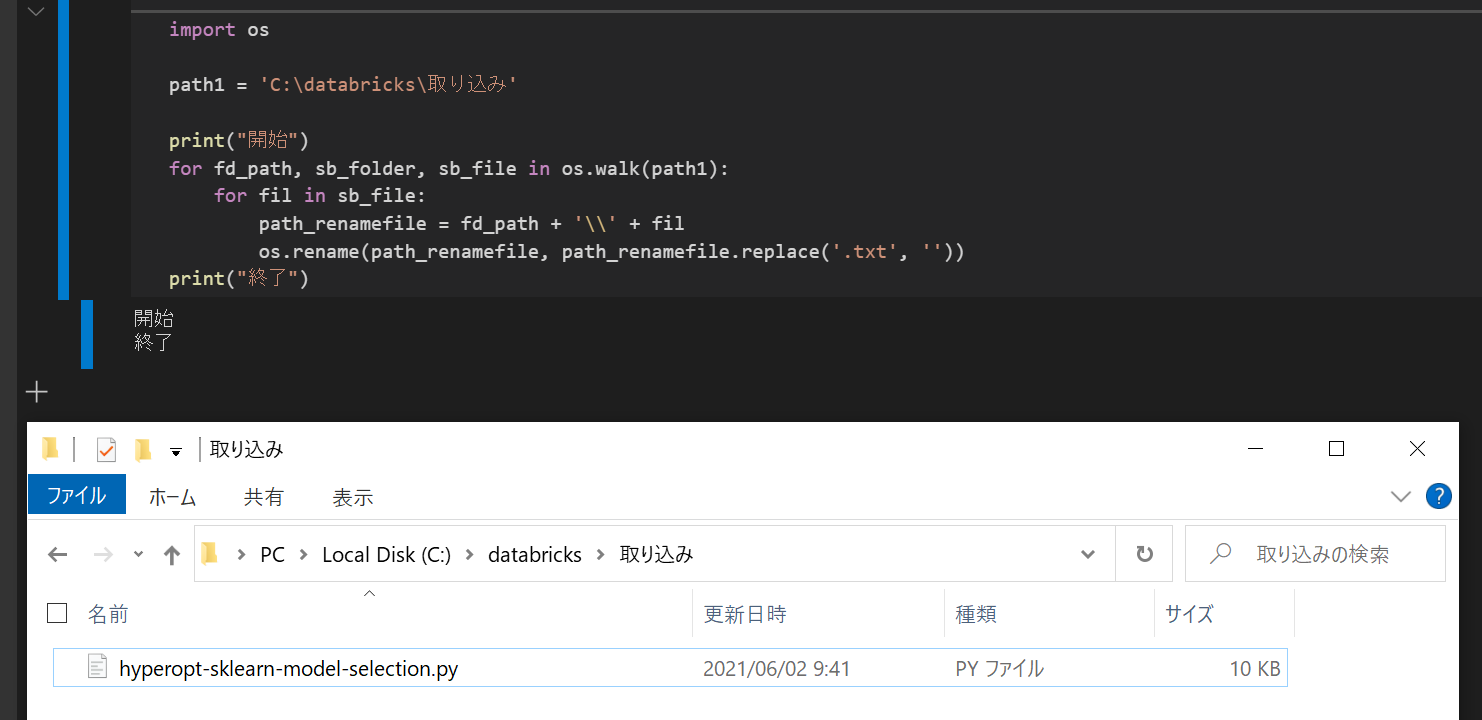
7. Databricks CLIを用いて翻訳後のファイルをインポート
databricks workspace import_dir C:/databricks/取り込み /Memsource/翻訳後 -o

8. Databricks Workspaceにてノートブックを確認
注意事項
1. "# MAGIC"ではじまる部分が、翻訳されること
最初に、"# MAGIC"のチェックを実施してください。

2. 箇条書きにおける末尾の空白が削除されること
半角のスペースを追加してください。
