概要
Google Colab の Spark にて Apache Iceberg のCopy-On-Write (CoW) と Merge-On-Read (MoR) の動作検証結果を共有します。Iceberg ではテーブルの行レベル更新や削除の処理方式として Copy-On-Write と Merge-On-Read の 2 つをサポートしています。それぞれ次のような特徴があります。MoR 方式を選択した場合は定期的なコンパクション(Compaction)が必要になり、運用コストが上がる点に注意が必要です。
-
Copy-On-Write (CoW)
更新・削除が発生すると、該当のデータファイル全体をコピーして書き換え、新しいファイルを作成する方式。- メリット: 読み取り時は常に最新のファイルのみを参照すればよく、シンプルで高速
- デメリット: 書き込み時にファイルの再書き出しが必要になるため、更新負荷が高い
-
Merge-On-Read (MoR)
既存のデータファイルはそのまま残し、更新・削除データを新規ファイル(および削除ファイル)として書き込む方式。- メリット: 書き込み時は既存ファイルを直接書き換えないため高速
- デメリット: 読み取り時にマージ処理が必要となり、ファイル数が増えるほどパフォーマンスに影響する可能性がある
検証結果
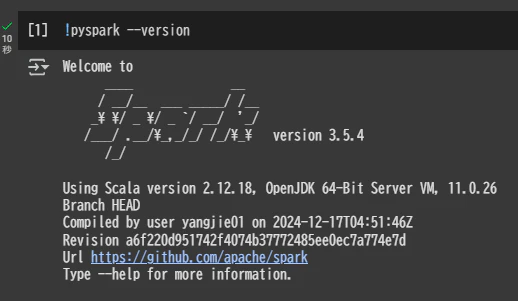
Spark のバージョンを確認
!pyspark --version
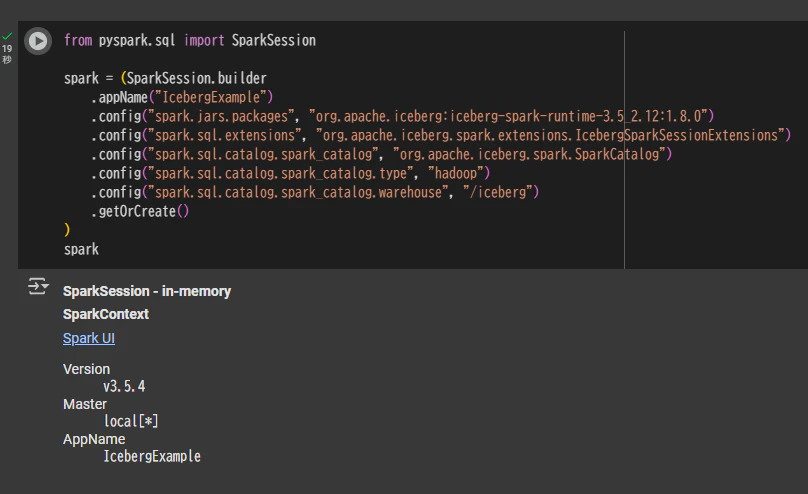
SparkSession を定義
Spark のバージョンに応じてspark.jars.packagesで指定するライブラリのバージョンを変更する必要あり。
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("IcebergExample")
.config("spark.jars.packages", "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.8.0")
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.config("spark.sql.catalog.spark_catalog", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.spark_catalog.type", "hadoop")
.config("spark.sql.catalog.spark_catalog.warehouse", "/iceberg")
.getOrCreate()
)
spark
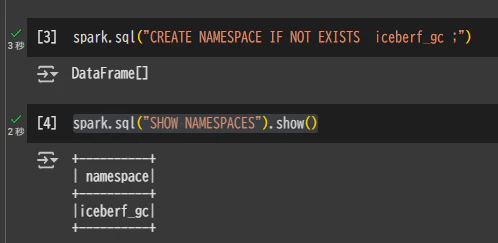
Namespace を作成
spark.sql("CREATE NAMESPACE IF NOT EXISTS iceberf_gc ;")
spark.sql("SHOW NAMESPACES").show()
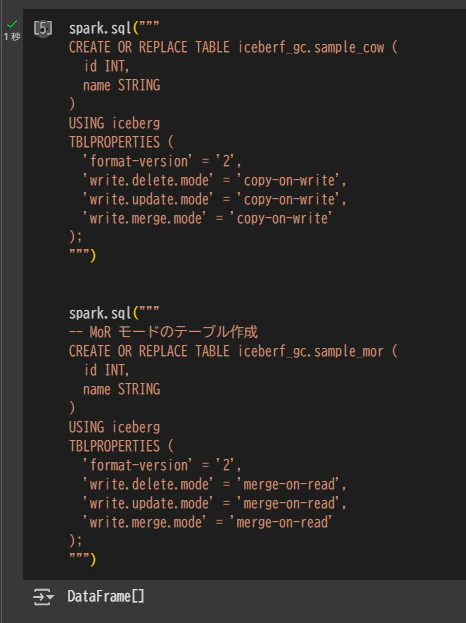
テーブルを作成
spark.sql("""
CREATE OR REPLACE TABLE iceberf_gc.sample_cow (
id INT,
name STRING
)
USING iceberg
TBLPROPERTIES (
'format-version' = '2',
'write.delete.mode' = 'copy-on-write',
'write.update.mode' = 'copy-on-write',
'write.merge.mode' = 'copy-on-write'
);
""")
spark.sql("""
-- MoR モードのテーブル作成
CREATE OR REPLACE TABLE iceberf_gc.sample_mor (
id INT,
name STRING
)
USING iceberg
TBLPROPERTIES (
'format-version' = '2',
'write.delete.mode' = 'merge-on-read',
'write.update.mode' = 'merge-on-read',
'write.merge.mode' = 'merge-on-read'
);
""")
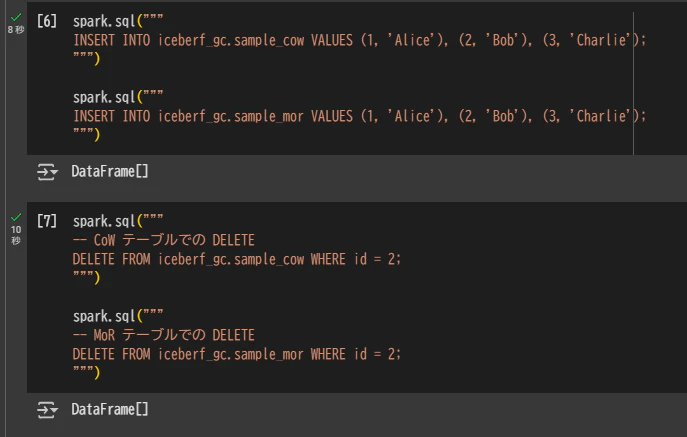
データの挿入とデータの削除を実施
spark.sql("""
INSERT INTO iceberf_gc.sample_cow VALUES (1, 'Alice'), (2, 'Bob'), (3, 'Charlie');
""")
spark.sql("""
INSERT INTO iceberf_gc.sample_mor VALUES (1, 'Alice'), (2, 'Bob'), (3, 'Charlie');
""")
spark.sql("""
-- CoW テーブルでの DELETE
DELETE FROM iceberf_gc.sample_cow WHERE id = 2;
""")
spark.sql("""
-- MoR テーブルでの DELETE
DELETE FROM iceberf_gc.sample_mor WHERE id = 2;
""")
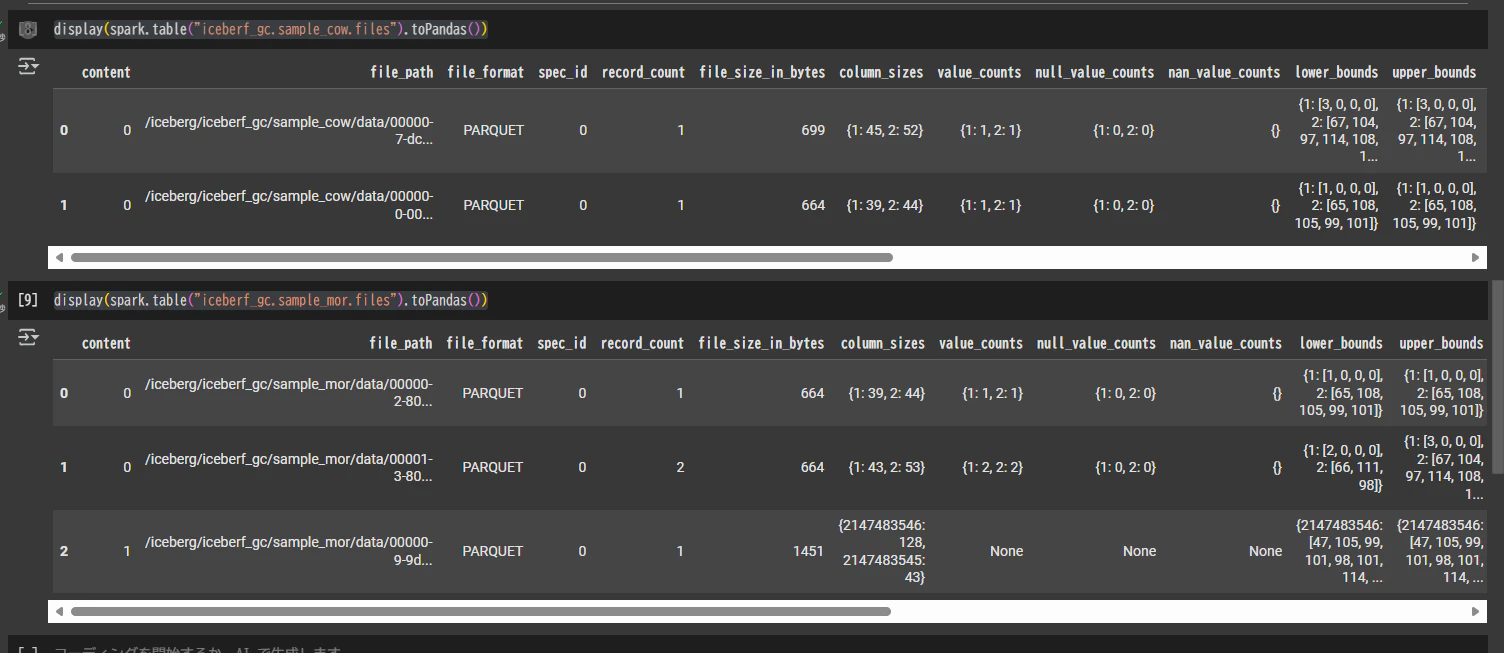
2 つのテーブルの files を確認
display(spark.table("iceberf_gc.sample_cow.files").toPandas())
display(spark.table("iceberf_gc.sample_mor.files").toPandas())
2 つのテーブルの data ディレクトリを確認
!ls /iceberg/iceberf_gc/sample_cow/data
!ls /iceberg/iceberf_gc/sample_mor/data
