概要
Azure Event Grid の公式ドキュメントには「30 秒以内にエンドポイントが応答しない場合は再試行キューに入れる」と記載されています。しかし、Azure Functions をエンドポイントとして実際に検証したところ、30 秒を超えてもすぐにはリトライが発生しない動作を確認しました。
| # | 待機秒数 | リトライ発生 | Event Grid のステータス |
|---|---|---|---|
| 1 | 5 秒 | なし | Delivered |
| 2 | 50 秒 | なし | Delivered |
| 3 | 240 秒 | あり | Delivery Failed |
ただしドキュメントには「ベストエフォート方式で再試行キューから削除しようとする」と明記されており、重複配信の可能性も残ります。そのため、本番運用では 30 秒以内に処理を完了させる設計 が安全と考えられます。
ドキュメントが定めるリトライ仕様
Azure Event Grid のリトライ仕様について、公式ドキュメント(Azure Event Grid の配信と再試行の説明)には次の記述があります。
Event Grid は、メッセージの配信後、応答を 30 秒間待機します。30 秒後、エンドポイントが応答しない場合、Event Grid は再試行のためにメッセージをキューに入れます。

引用元: Azure Event Grid の配信と再試行の説明 - Azure Event Grid | Microsoft Learn
一方で、3 分以内に応答すれば再試行キューから削除されうるという記述もあります。
エンドポイントが 3 分以内に応答した場合、Event Grid はベスト エフォート方式でイベントを再試行キューから削除しようとしますが、それでも重複が受信される可能性があります。

引用元: Azure Event Grid の配信と再試行の説明 - Azure Event Grid | Microsoft Learn
つまり、「30 秒経過 = 即リトライ確定」ではなく、3 分以内なら取り消される余地がある という、ややグレーな仕様になっています。今回の検証では、この境界の挙動を具体的に確かめました。
検証環境
利用したリソース
| リソース | 用途 |
|---|---|
| Azure Storage | イベント発生源となる Blob ストレージ |
| Azure Functions | Event Grid トリガー関数(エンドポイント) |
| Azure Event Grid | Blob 作成イベントを Functions にルーティング |
Azure Functions のコード
WAIT_SECONDS 環境変数で待機時間を変更できる、シンプルな Event Grid トリガー関数を用意します。受信したイベントの内容をログに出力したあと、指定秒数だけ time.sleep して応答を遅延させます。
import json
import logging
import os
import time
from datetime import datetime, timezone
import azure.functions as func
app = func.FunctionApp()
WAIT_SECONDS = os.getenv("WAIT_SECONDS", "50")
@app.function_name(name="BlobCreatedEventGridProbe")
@app.event_grid_trigger(arg_name="event")
def blob_created_event_grid_probe(event: func.EventGridEvent) -> None:
wait_seconds = int(WAIT_SECONDS)
event_time = event.event_time
if event_time is not None and event_time.tzinfo is None:
event_time = event_time.replace(tzinfo=timezone.utc)
elif event_time is not None:
event_time = event_time.astimezone(timezone.utc)
data = event.get_json()
blob_url = data.get("url") if isinstance(data, dict) else None
log_record = {
"probe": "event-grid-blob-created-latency",
"utc_now": datetime.now(timezone.utc).isoformat(),
"event_id": event.id,
"event_type": event.event_type,
"event_time": event_time.isoformat() if event_time else None,
"subject": event.subject,
"blob_url": blob_url,
"data": data,
}
logging.info(
"EVENTGRID_PROBE %s",
json.dumps(log_record, ensure_ascii=False),
)
# 指定秒数だけ応答を遅延させる
logging.info("Waiting for %d seconds before returning response...", wait_seconds)
time.sleep(wait_seconds)
logging.info("処理が完了しました。%d 秒待機しました。", wait_seconds)
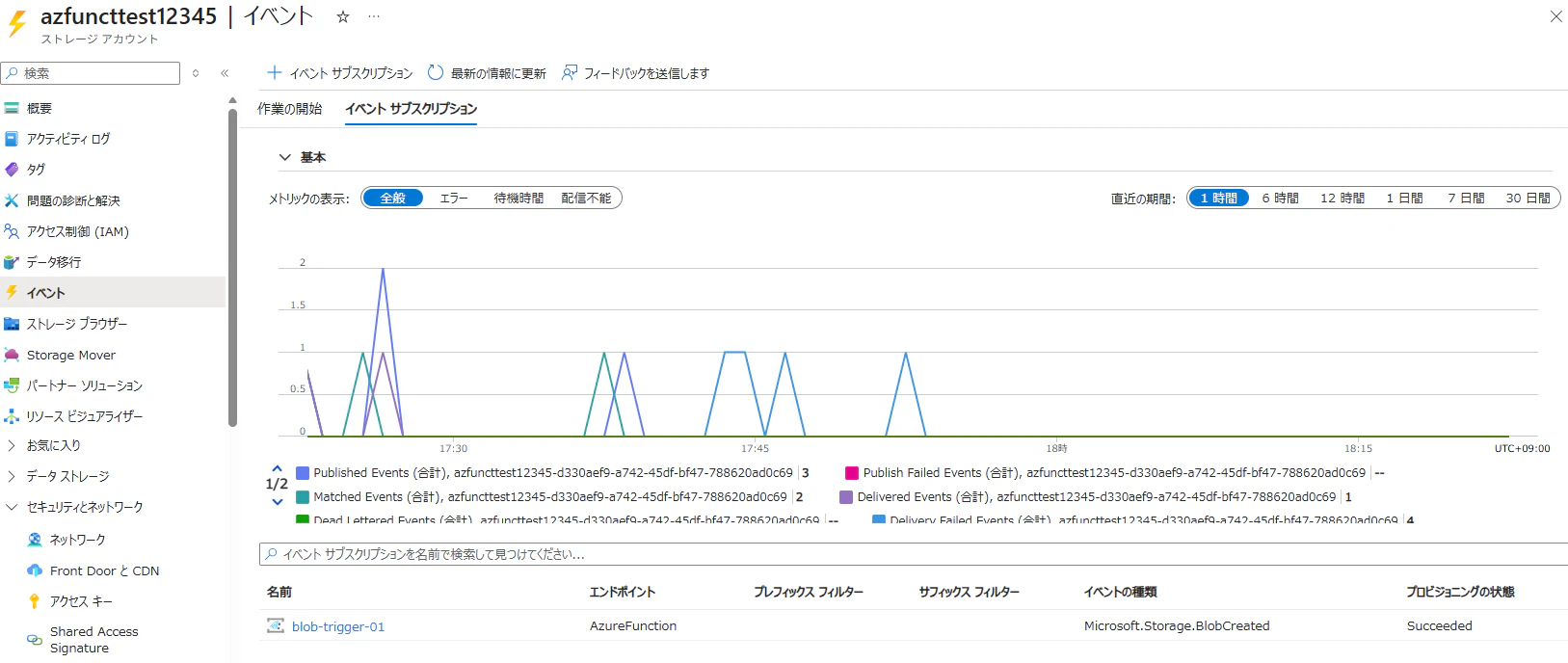
Event Grid サブスクリプションの設定
Blob 作成イベントを上記 Functions にルーティングするよう、Event Grid サブスクリプションを構成します。
検証ケースとその結果
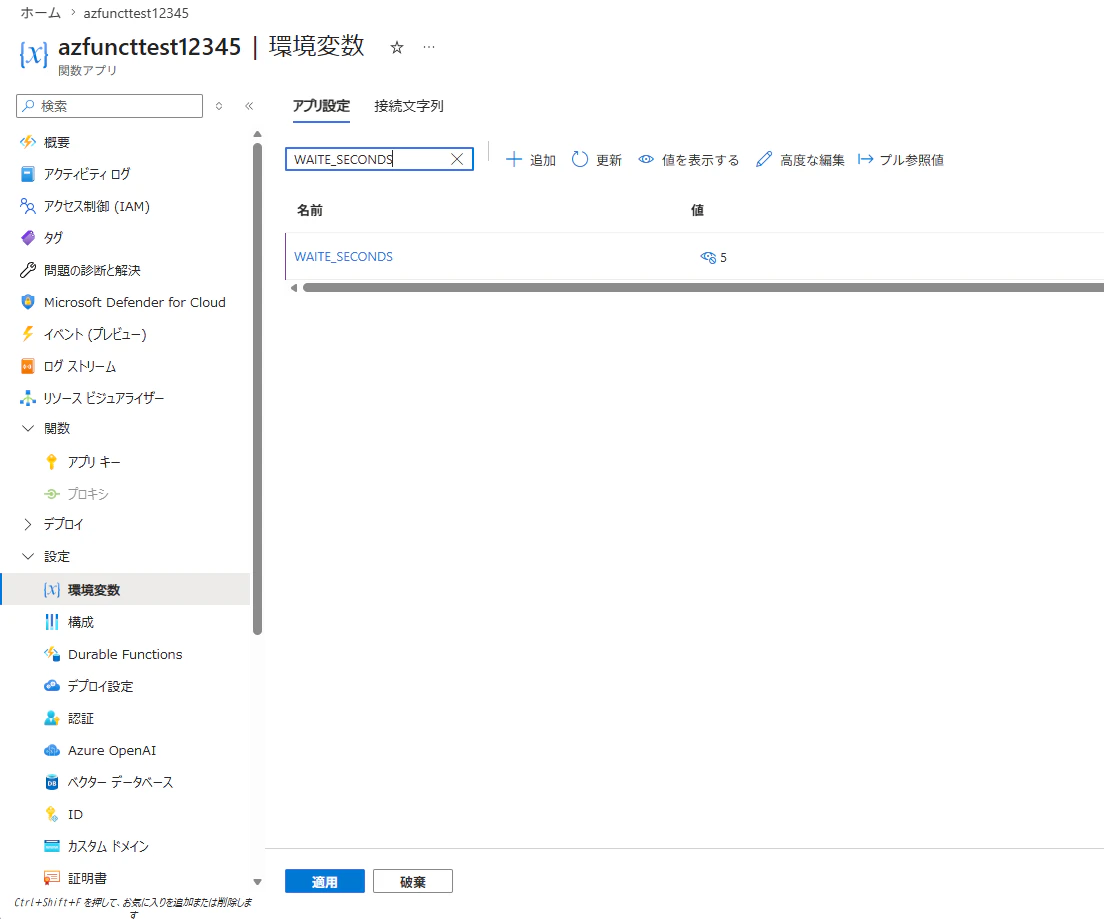
ケース 1:5 秒待機
WAIT_SECONDS を 5 に設定して Blob を作成します。短時間で応答が返るため、想定通り Delivered Events として処理されました。

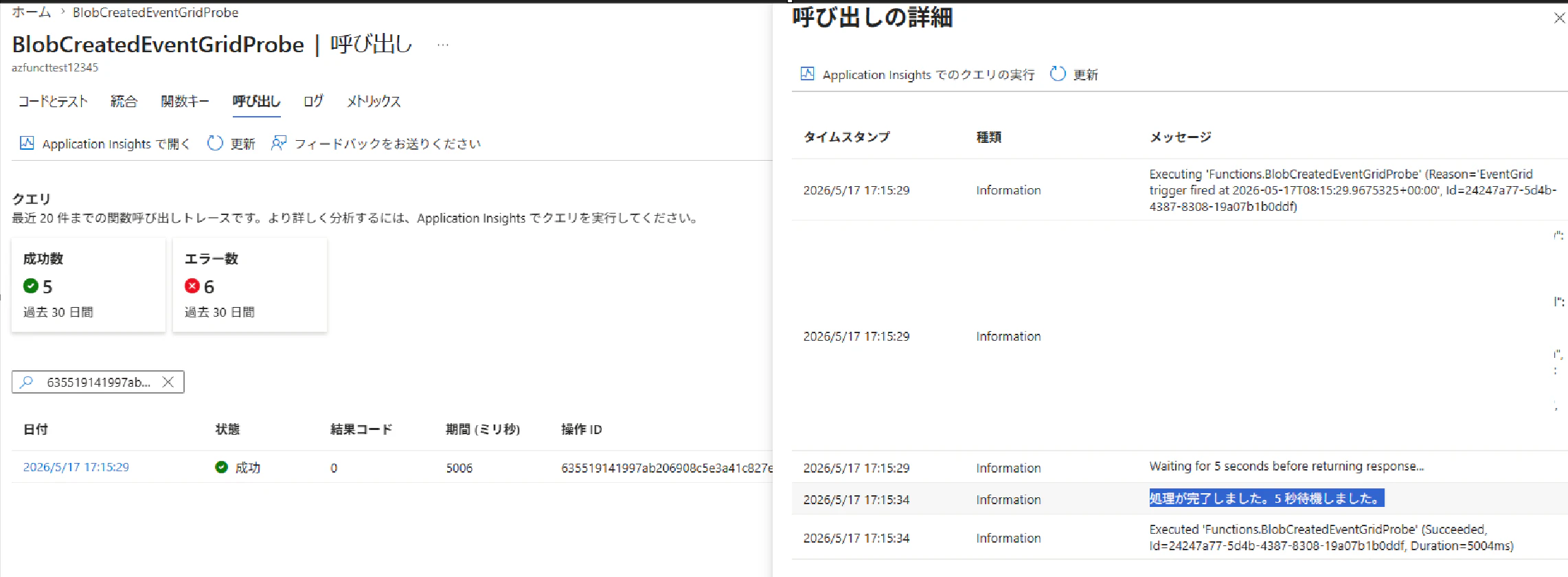
ケース 2:50 秒待機 — リトライ閾値ちょうど
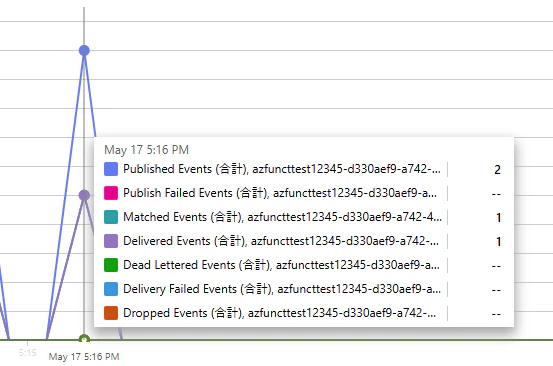
WAIT_SECONDS を 50 に設定すると、ドキュメント上の「リトライ閾値」とちょうど同じタイミングで応答することになります。このケースでも結果は Delivered Events で、リトライは発生しませんでした。
つまり、ドキュメントに書かれた「30 秒後にキューに入れる」というのは、ただちにリトライ配信が走ることを意味しないことが確認できます。

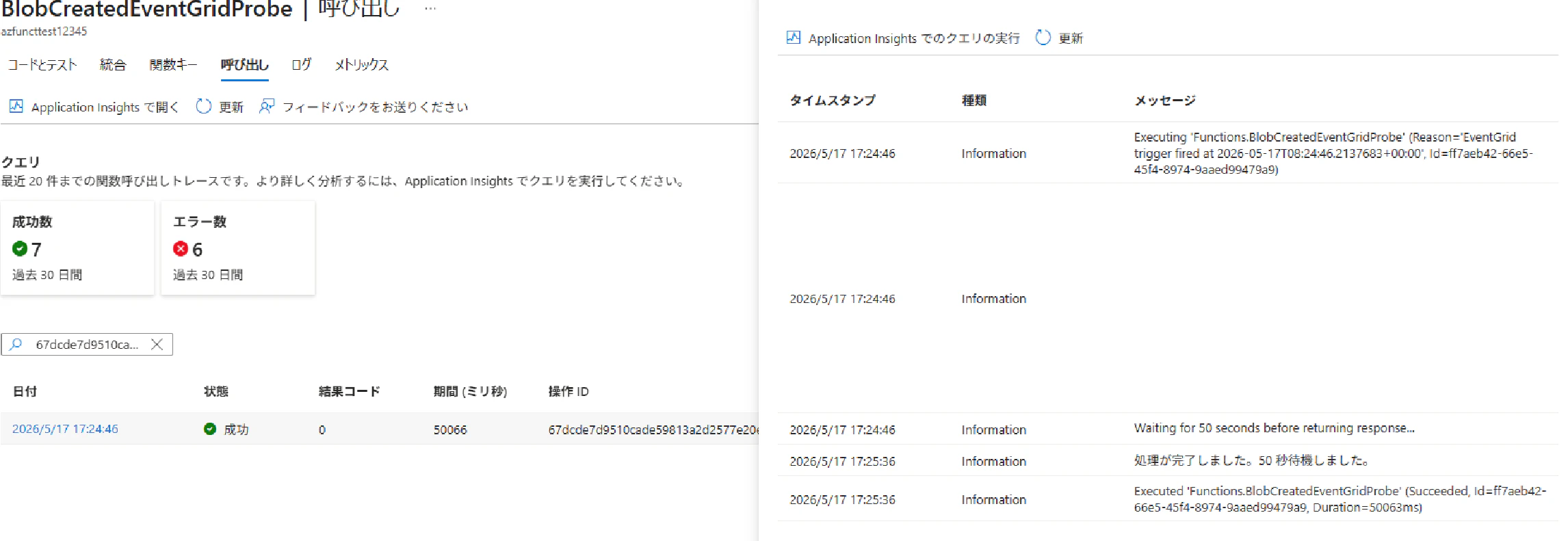
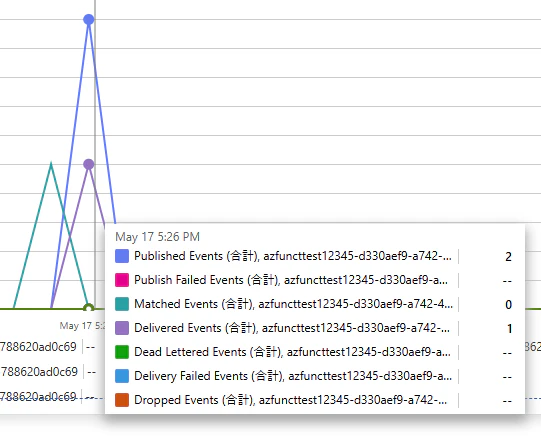
ケース 3:240 秒待機 — 3 分の壁を超える
WAIT_SECONDS を 240(= 4 分)に設定すると、Delivery Failed Events に分類され、リトライが発動しました。
ここで注目すべきは、Azure Functions 側では関数が正常終了している点です。それにもかかわらず Event Grid 側からは失敗扱いとなり、ドキュメント記載のリトライスケジュールに従って再配信が繰り返される結果となりました。
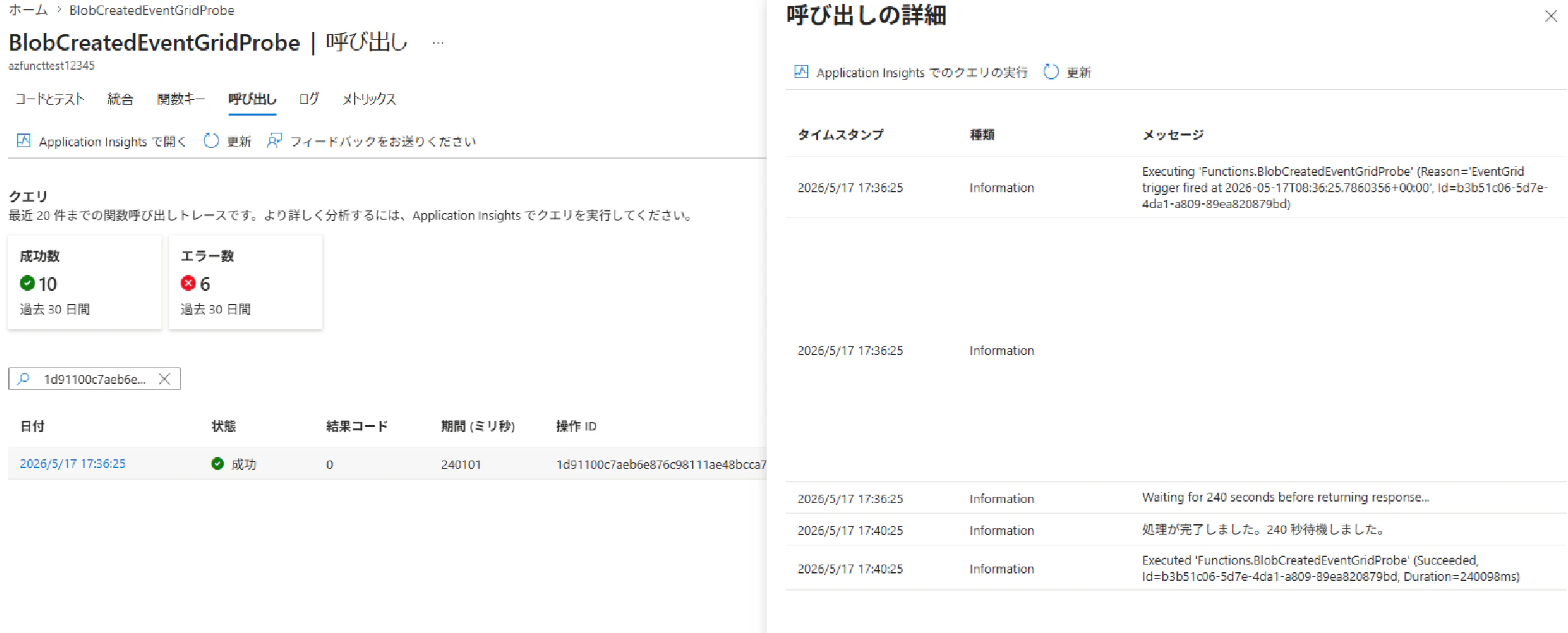
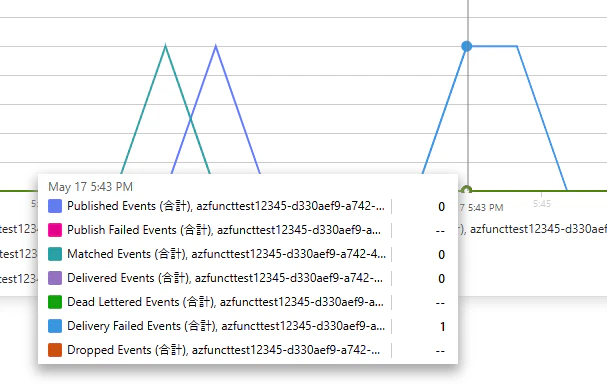

リトライスケジュールはドキュメントにも明記されており、何度も処理が走る点に注意が必要です。

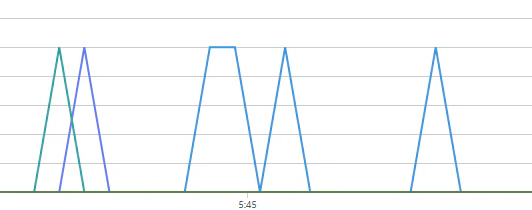

引用元: Azure Event Grid の配信と再試行の説明 - Azure Event Grid | Microsoft Learn
検証から得られる設計上の示唆
今回の検証結果は、Event Grid を組み込んだシステムを設計するうえで以下を意味します。
-
「30 秒」はキュー投入の閾値であって、即時リトライの閾値ではない
ドキュメント上の 30 秒は、あくまで Event Grid 内部で再試行キューに入れるタイミング。3 分以内に応答すれば、ベストエフォートではあるものの再配信を回避できる可能性があります。 -
3 分を超える処理は重複配信が確定的に発生する
240 秒のケースのように、関数自体が正常終了していても Event Grid から見れば失敗扱いとなり、リトライがスケジュールされてしまいます。長時間処理をそのままトリガー関数に書くと、冪等性のない処理が複数回走る リスクがあります。 -
本番では「30 秒以内に応答を返す設計」を基本とする
重複配信を確実に避けたいのであれば、ドキュメントの定める 30 秒以内で処理を完了させるのが安全。それが難しい場合は、トリガー関数では受信確認だけを行い、実処理を Queue Storage や Service Bus にオフロードするパターンが有効です。また、下流側で冪等性を担保しておくと、ベストエフォートで取り消し切れなかった重複にも耐えられます。