概要
日本ディープラーニング協会のDeep Learning資格試験(E資格)の対策講座であるラビットチャレンジの学習環境を、無償でブラウザにより利用可能なDatabricks Community Editionで実施したので、共有します。
ラビットチャレンジとは
Study-AI株式会社が提供している自己学習を主体的に進めることが前提で提供されている、月額3000円で提供されている格安の対策口座です。

引用元:ラビット★チャレンジ Deep Learning (ai999.careers)
Databricks Community Edition
Sparkによるビッグデータ処理やPythonやRによるデータ分析を実施可能なデータ統合データプラットフォーム(レイクハウス)のサービスであるDatabricksの無償環境です。

引用元:Databricks - 統合データ分析
なぜDatabricksを利用するのか
Databricksで学習しておくことで、実際の業務で利用可能するためです。
Databricksは、AWSやAzureなどのマルチクラウドで提供されており、仮想ネットワーク上にデプロイできることからエンタープライズレベルのセキュリティ要件を満たすことができます。
Anacondaは有償化されてしまい利用は難しいですし、Google Colabはセキュリティという観点で業務では利用できませんでした。
必要そうな環境
下記の環境が必要であり、最新版のDatabricks RuntimeだとKearas(スタンドアロン)がインストールされていないため、Databricks Runtime 6.4 MLを利用するのがよさそうです
- Python
- Pandas
- Numbpy
- tensolflow
- Kerasa(スタンドアロン)
Databricks Runtime 6.4 MLにインストールされているライブラリは、下記のドキュメントを参考にしてください
Databricks環境構築
Databricks Community Editonの申し込みます。
Try Databricksから申し込みを実施します。

引用元:Try Databricks
下記にて、"COMMUNITY EDITION"を選択します。
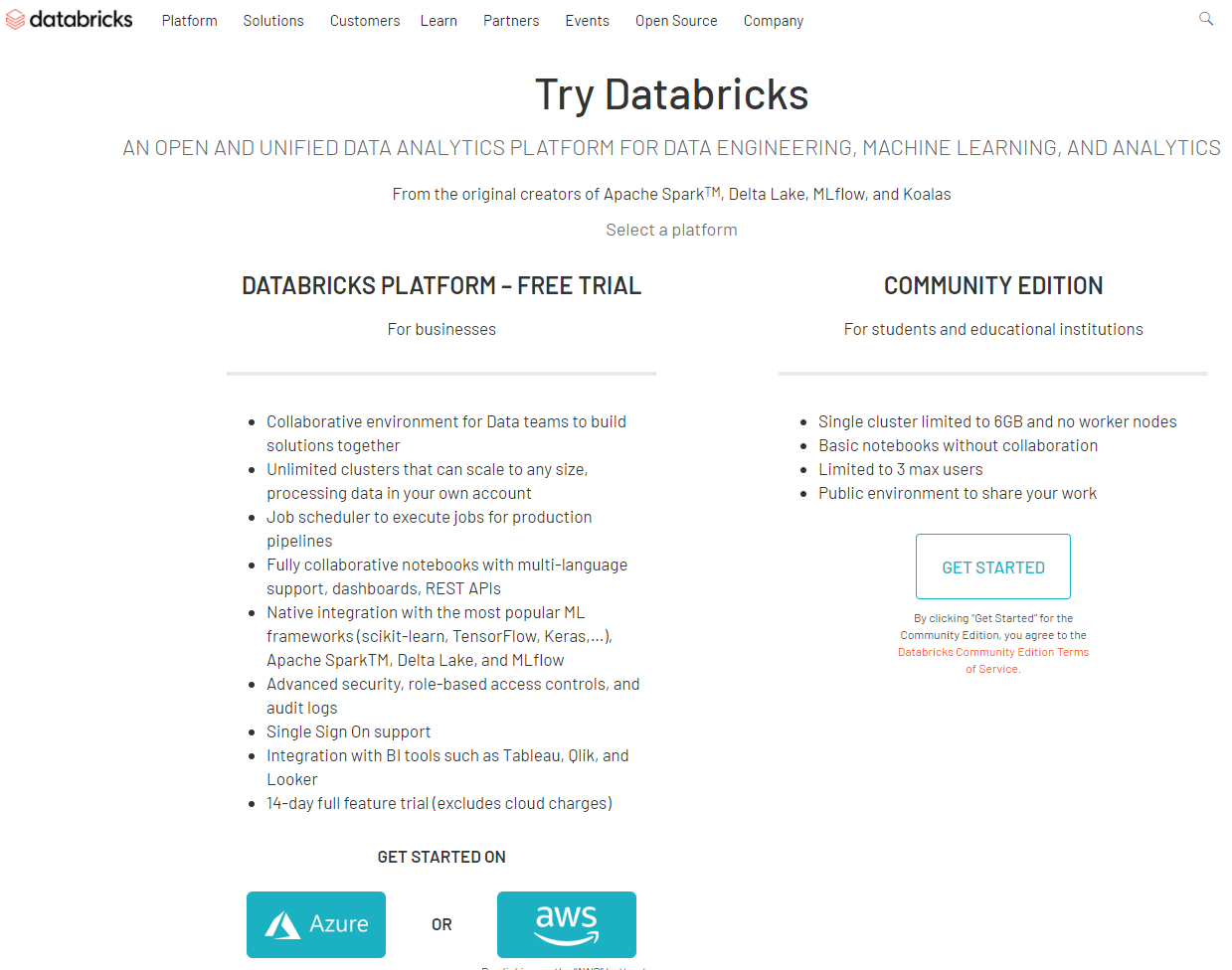
引用元:Try Databricks
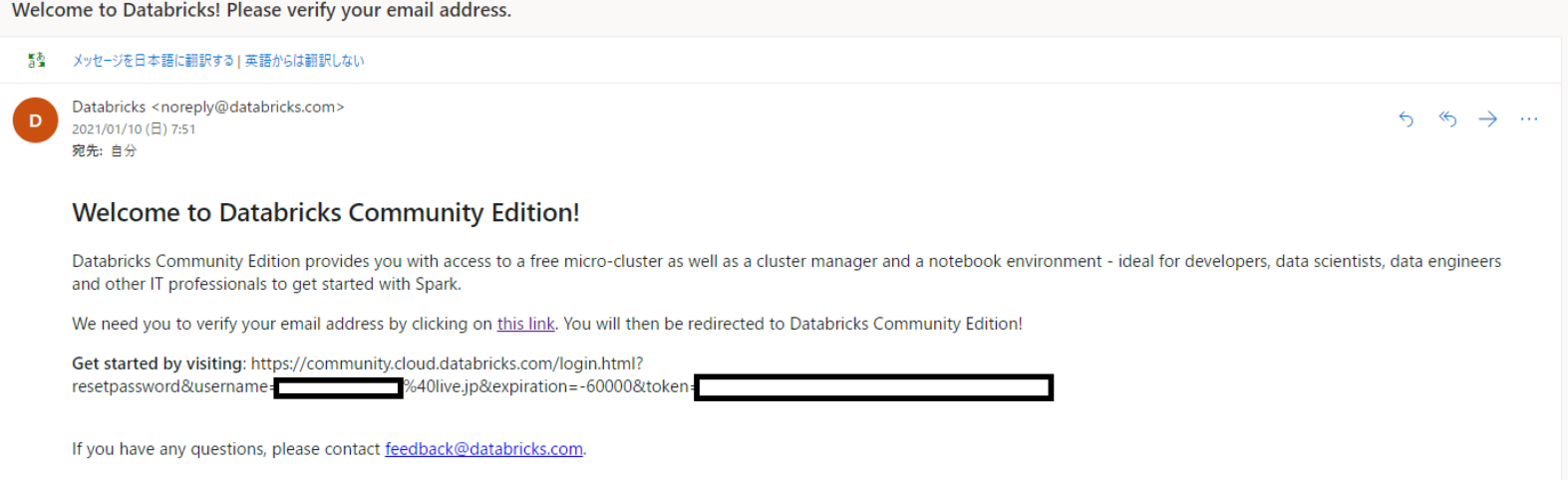
届いたメールのリンクを設定します。
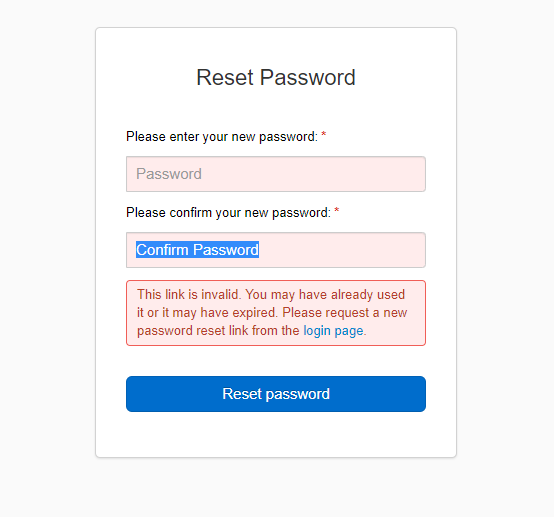
パスワードを設定します。
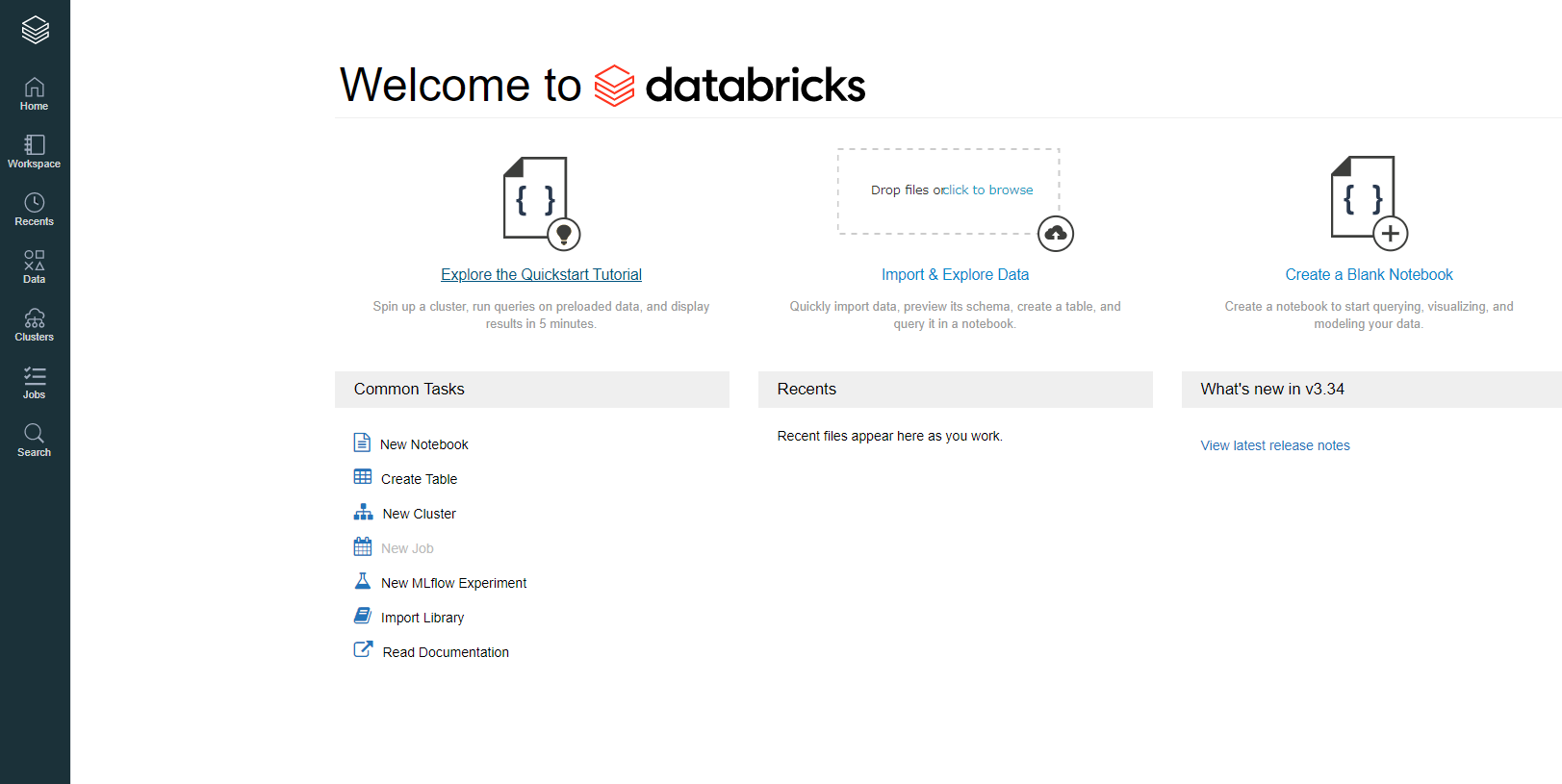
Databricksに接続できることを確認します。
講座を学習する際の手順
インポートするファイルをインポートします。フォルダーで取り込めないため、コマンドラインで一括で取り込んだほうが楽かもしれません。
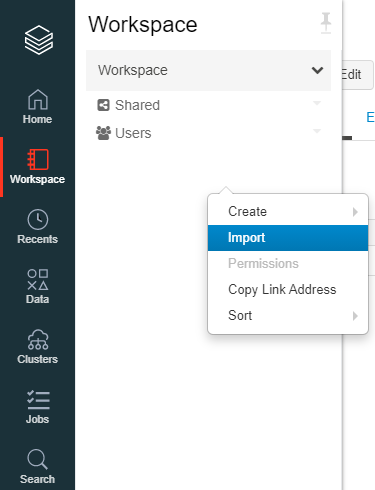
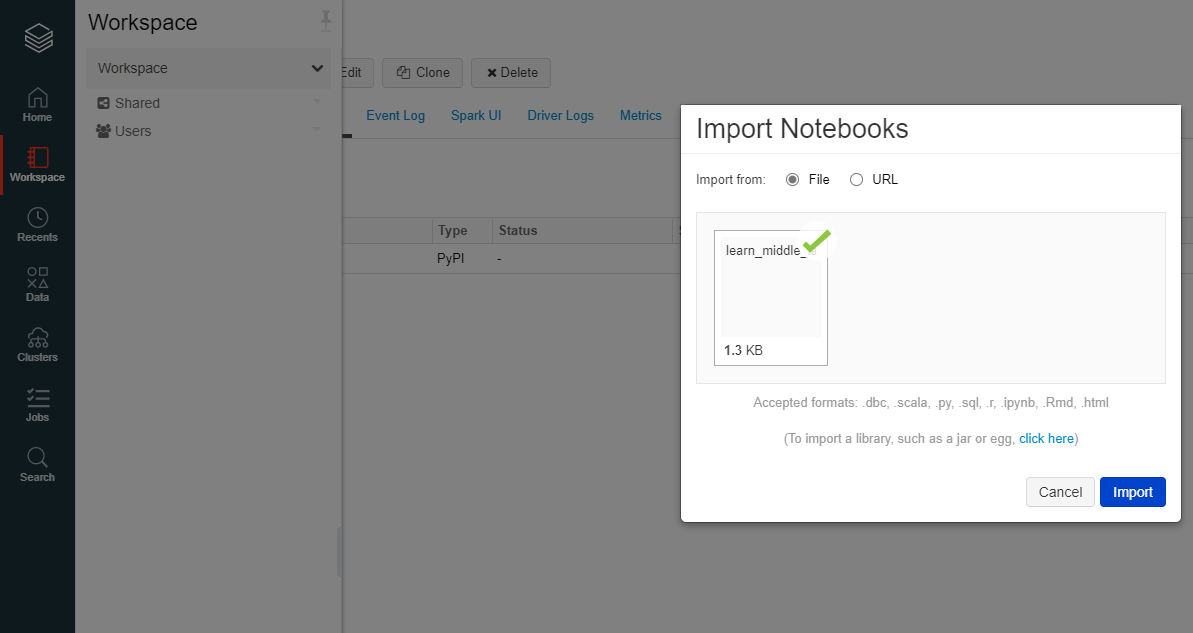
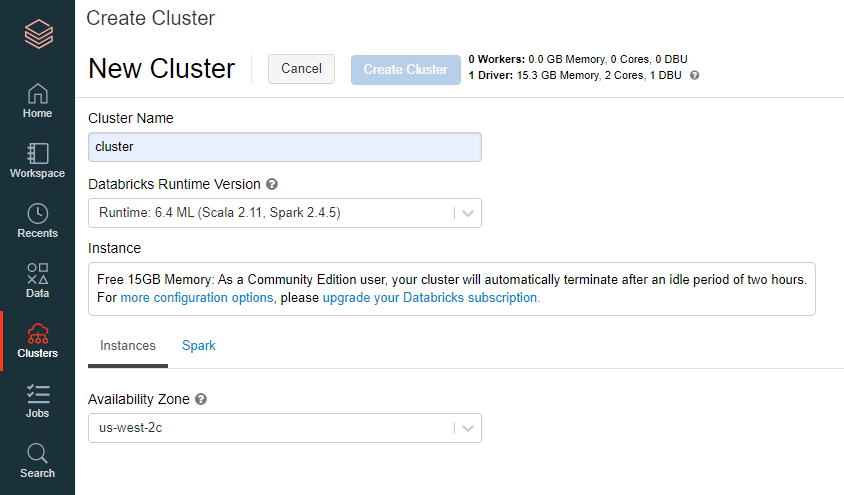
"Clustres"を右クリック後、"Cluster Name"に適当な名前を、"Databricks Runtime Version"を"Databricks Runtime 6.4 ML(Scala 2.11 Spark 2.4.5)"を入力し、"Create Cluster"を選択。
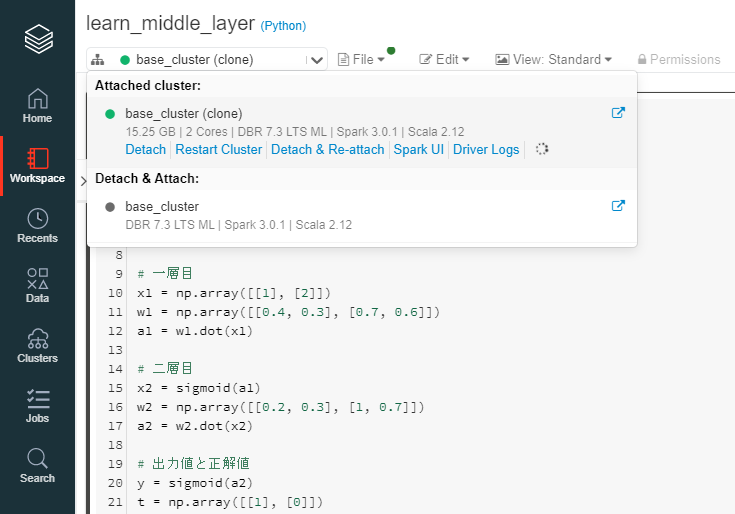
ノートブックを開き、クラスターをアタッチして、ノートブックを実行します。
本手順で学習する場合の注意事項
1. Community Editionでは、GPUを利用することはできないこと
2. 学習前に毎回クラスターをクローンにより作成する必要があること
3. 学習コードのインポートをGUIで実施する場合にフォルダー単位で実施する必要があること
4. matplot、seabornにおけるグラフが表示されない場合、下記のコードを実行する必要がある。
%matplotlib inline
下記のドキュメントにて説明されてます。