概要
ノートブック型 Spark サービス(主にDatabricks)における PySpark に対する単体テストの実践について説明する。
本記事のコードを含むノートブックを以下のリンクに保存しておりますので、興味がある方は Databricks 等の環境にインポートして実行してみてください。
本記事の位置付け
次の開発ガイドシリーズにおけるテスト分野の1記事であり、リンク先には記事にて記事の全体像を整理している。
| GroupID | 分野 |
|---|---|
| T10 | Spark概要 |
| T20 | データエンジニアリング |
| T30 | データ品質チェック |
| T40 | データサイエンス |
| T50 | メタデータデプロイ |
| T60 | テスト |
| T70 | DevOps |
1. 単体テスト概要
1-1. 単体テストとは
単体(ユニット)テストとは、ソフトウェアを構成する小さな単位(ユニット)に対して詳細設計の仕様の充足度を確認するテストです。他システムや他モジュールに依存しないようにテストを実施することが多いが、Databricks や Synapse などの多機能サービス上でのソフトウェア開発ではスコープが広範囲となる特徴がある。テストのしやすさに合わせて、ソフトウェアアーキテクチャを検討することが重要。
単体テストは、主に3つの概念に分けられる。同時実行対象のテストケース群を、テストスイートと呼ぶこともある。
| # | 概念 | 概要 |
|---|---|---|
| 1 | テストフィクスチャ | テストの事前処理やテストの事後処理。 |
| 2 | テストケース | テスト対象の処理へのインプットを行い、そのアウトプットを確認。 |
| 3 | テストランナー | テスト実行の管理を行い、テスト結果を提供。 |
テスト結果の出力ファイルの種類には、テスト結果のファイルだけでなく、コードカバレッジのファイルがある。コードカバレッジとは、テスト対象のプログラム全体の中でテストが実施されたプログラムの割合を指す。Azure DevOps や Github Action などの CI/CD(Continuous Integration(継続的インテグレーション)/ Continuous Delivery(継続的デリバリー))サービス上に発行することもでき、継続的に品質保証を行う際に必要となる。CI/CD サービスごとに発行できるファイル形式は異なり、Azure DevOps でサポートされているファイル形式は次のものがある。
| # | テスト結果の出力ファイル | ファイル形式 |
|---|---|---|
| 1 | テスト結果のファイル | - JUnit - NUnit - VSTest - xUnit - cTest |
| 2 | コードカバレッジのファイル | - Cobertura - JaCoCo |
Python では unittest と pytest というライブラリがよく利用されており、テストケース(テストフィクスチャを含む)とテストランナーの組み合わせは次のようになる。pytest から unittest のテストケースを実行できる。unittest では、標準機能ではテスト結果のファイルとコードカバレッジのファイルを出力できず、追加のライブラリが必要となる。pytest では、テスト結果を出力できるが、コードカバレッジのファイルを出力できないため、pytest-cov などのライブラリが必要となる。
| # | テストケースとテストランナーの組み合わせ |
|---|---|
| 1 | unittest にてテストケースを作成して、unittest によりテストランナーとして実行 |
| 2 | unittest にてテストケースを作成して、pytest によりテストランナーとして実行 |
| 3 | pytest にてテストケースを作成して、pytest によりテストランナーとして実行 |
Pyspark でテストを実施する際には、テストの実行環境とテストの実行対象を確認することが重要。単体テストを外部環境に依存しないようにコンテナー等で構築した Spark 上で実施する方法もあるが、Spark プロバイダー固有機能を検証するためにはSpark プロバイダー上で実施しなくてはいけないことがある。
- テストの実行環境
- ローカル Spark 環境
- サーバー
- コンテナー
- Spark プロバイダーへ接続した外部環境
- Databricks connect
- Spark プロバイダー
- Databricks Workspace
- Databricks Workflow
- Synapse workspace
- ローカル Spark 環境
- テストの実行対象
- Python ファイル(.py)
- ノートブック
- Python のライブラリ
1-2. Databricks における単体テスト概要
Databricks Repos のファイル管理仕様、Databricks Workspace 上ではノートブックであるが Git 上では Python ファイルとして管理される仕様、を活用して、次のような単体テストの実施方針を定めた。ノートブック形式で pytest を実行する方法、および、ノートブック形式でコードカバレッジのファイルを出力する方法を、確立できていないため、pytest と unittest を併用している。CI/CD 時には、主に pytest にてテストを行うが、ノートブック形式での検証を行うために unittest においてもテストを行う。
- 基本方針
- テストケース(テストフィクスチャを含む)の利用方針
- unittest にて実装。
- テストランナーの利用方針
- 開発時
- Databricks Workspace 上で unittest によるテスト実行を行い、ローカル環境上で pytest によるテスト実行を行う。
- Databricks Workspace 上で unittest によるテスト実行
- ノートブックで実行できることを保証するために実施
- ローカル環境上で pytest によるテスト実行
- CI/CD 上で実行できることを保証するために実施
- Databricks Connect 経由で実施しており、サポート対象外機能の検証をテスト実行対象から除外
- Databricks Workspace 上で unittest によるテスト実行
- Databricks Workspace 上で unittest によるテスト実行を行い、ローカル環境上で pytest によるテスト実行を行う。
- CI/CD 時
- Databricks Workflows上で、pytest による Python スクリプト形式でのテスト実行、および、unittest によるノートブック形式でのテスト実行を行う。
- pytest による Python スクリプト形式でのテスト実行
- Databricks の DBFS 上に Git レポジトリからコードを配置し、Databricks Workflows(Python script Type)にて テストを実行。
- テスト結果のファイルとコードカバレッジのファイルを発行
- unittest によるノートブック形式でのテスト実行
- Databricks の Repos 上に Git レポジトリのコードを配置し、Databricks Workflows(Notebook Type)にて テストを実行。
- テスト結果のファイルを発行
- pytest による Python スクリプト形式でのテスト実行
- Databricks Workflows上で、pytest による Python スクリプト形式でのテスト実行、および、unittest によるノートブック形式でのテスト実行を行う。
- 開発時
- テストケース(テストフィクスチャを含む)の利用方針
Databricks 上でテストの実行を並列化する際には、pytest-xdist などのライブラリを利用するのではなく、SparkSession が共有されないように並列化する必要がある。ノートブックと Databricks Workflows(Python script Type)で次のようにテストを並列で実行する。
- ノートブック上におけるテストの並列実行方法
-
dbutils.notebook.runをconcurrent.futuresにより並列で実行 -
unittest.TestCaseのサブクラスであるグローバル変数(テストケース)を取得 - 並列数に応じて 手順2 の変数を按分
- 手順3 のテストケースを実行
-
- Databricks Workflows(Python script Type)上におけるテストの並列実行方法
- 手順 2 以降を実行する並列数と同数のタスクを作成
-
–-collect-onlyオプションをつけた pytest コマンドによりテストケースを取得 - 並列数に応じて 手順2 の変数を按分
- 手順3 のテストケースを実行
2. unittest の基本的な利用方法
2-1. unittest によるテスト実行
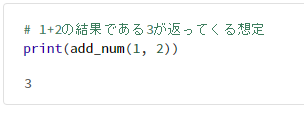
# 2つの引数を加算する関数を定義
def add_num(a, b):
return a + b

# 1+2の結果である3が返ってくる想定
print(add_num(1, 2))
# テストケースを定義
import unittest
class test__add_num(unittest.TestCase):
"""`add_num`関数に対する単体テスト"""
def test__add_num__001(self):
"""successes(正常系テスト)"""
self.assertTrue(add_num(1, 1) == 2)
def test__add_num__002(self):
"""successes(異常系テスト)"""
# 文字を引数とすることでエラーとなる想定
with self.assertRaises(TypeError):
add_num(1, 'ABC')
def test__add_num__003(self):
"""failures"""
self.assertTrue(add_num(1, 1) == 1)
def test__add_num__004(self):
"""errors"""
self.assertTrue(1 + "a")
@unittest.skip("スキップ用")
def test__add_num__005(self):
"""skipped"""
assert a
@unittest.expectedFailure
def test__add_num__006(self):
"""expectedFailure"""
self.assertTrue(add_num(1, 1) == 1)
@unittest.expectedFailure
def test__add_num__007(self):
"""unexpectedSuccesses"""
self.assertTrue(add_num(1, 1) == 2)

# テストスイートにセット
suite = unittest.TestLoader().loadTestsFromTestCase(
test__add_num,
)
# テストランナーにセット
runner = unittest.TextTestRunner(
verbosity=2,
)
# テストランナーを実行
test_result = runner.run(suite)

# 実行後に取得できる主な値を表示
print(
f"""
# テスト全般
testsRun : {test_result.testsRun}
wasSuccessful : {test_result.wasSuccessful()}
testMethodPrefix : {unittest.loader.TestLoader.testMethodPrefix}
# テストの失敗関連
faulures_number : {len(test_result.failures)}
failures : {test_result.failures}
_testMethodName : {test_result.failures[0][0]._testMethodName}
_testMethodDoc : {test_result.failures[0][0]._testMethodDoc.strip()}
failures_message : {test_result.failures[0][1]}
# テストのスキップ関連
skipped_number : {len(test_result.skipped)}
skipped : {test_result.skipped}
_testMethodName : {test_result.skipped[0][0]._testMethodName}
_testMethodDoc : {test_result.skipped[0][0]._testMethodDoc.strip()}
skipped_message : {test_result.failures[0][1]}
# エラー関連
skipped_number : {len(test_result.errors)}
errors : {test_result.errors}
_testMethodName : {test_result.errors[0][0]._testMethodName}
_testMethodDoc : {test_result.errors[0][0]._testMethodDoc.strip()}
errors_message : {test_result.failures[0][1]}
# その他
expectedFailures : {test_result.expectedFailures}
unexpectedSuccesses : {test_result.unexpectedSuccesses}
""".strip()
)

2-2. PySpark にて unittest による単体テストの実施
PySpark にて unittest を利用する場合には、次のステップを実施。必要に応じて、データベース作成やテーブル作成を省略。
- テスト用データベースを作成
- テスト用テーブルを作成
- テストケースにて、インプットのデータフレームと想定結果のデータフレームを作成
- テストケースにて、3のデータフレームを引数として関数を呼び出す
- テストケースにて、4の実行結果を確認
-
tearDownClassにて、1で作成したデータベースを削除
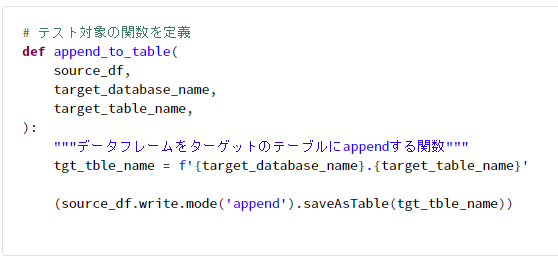
# テスト対象の関数を定義
def append_to_table(
source_df,
target_database_name,
target_table_name,
):
"""データフレームをターゲットのテーブルにappendする関数"""
tgt_tble_name = f'{target_database_name}.{target_table_name}'
(source_df.write.mode('append').saveAsTable(tgt_tble_name))
import unittest
import random
import string
from pyspark.sql import Row, SparkSession
class test__append_to_table(unittest.TestCase):
"""`append_to_table`関数に対する単体テスト"""
def tearDown(self):
spark = SparkSession.builder.getOrCreate()
# 6. tearDownClassにて、1で作成したデータベースを削除
spark.sql(f'DROP DATABASE IF EXISTS {self.database_name} CASCADE')
def test__append_to_table__001(self):
"""
001 テーブルデータがない状態で、データが追加されることを確認
"""
spark = SparkSession.builder.getOrCreate()
# 1. テスト用データベースを作成
db_name_suffix = ''.join([random.choice(string.ascii_lowercase) for i in range(10)])
self.database_name = f'_ut_db__append_to_table_001_{db_name_suffix}'
spark.sql(f'DROP DATABASE IF EXISTS {self.database_name} CASCADE')
spark.sql(f'CREATE DATABASE IF NOT EXISTS {self.database_name}')
# テスト用データベースをカレントデータベースとして設定
spark.catalog.setCurrentDatabase(self.database_name)
# 2. テスト用テーブルを作成
table_name = '_ut_table___append_to_table'
spark.sql(
f'''
create TABLE {self.database_name}.{table_name}
(
string_column string,
int_column long
)
USING delta
'''
)
## 3. テストケースにて、インプットのデータフレームと想定結果のデータフレームを作成
input_data = [
Row(string_column='aaa', int_column=1),
Row(string_column='bbb', int_column=2),
Row(string_column='ccc', int_column=3),
]
input_schema = """
string_column string,
int_column long
"""
input_df = spark.createDataFrame(input_data, input_schema)
## 期待値のデータフレームを作成
expected_data = [
Row(string_column='aaa', int_column=1),
Row(string_column='bbb', int_column=2),
Row(string_column='ccc', int_column=3),
]
expected_schema = """
string_column string,
int_column long
"""
expected_df = spark.createDataFrame(expected_data, expected_schema)
# 4. テストケースにて、3のデータフレームを引数として関数を呼び出す
append_to_table(
source_df=input_df,
target_database_name=self.database_name,
target_table_name=table_name,
)
# 5. テストケースにて、4の実行結果を確認
result_df = spark.table(table_name)
view_result = f'_result_{table_name}'
view_expected = f'_expected_{table_name}'
result_df.createOrReplaceTempView(view_result)
expected_df.createOrReplaceTempView(view_expected)
df = spark.sql(
f'''
SELECT * FROM {view_result} EXCEPT SELECT * FROM {view_expected}
UNION ALL
SELECT * FROM {view_expected} EXCEPT SELECT * FROM {view_result}
'''
)
self.assertTrue(df.count() == 0)
def test__append_to_table__002(self):
"""002 テーブルデータが存在する状態で、データが追加されることを確認"""
spark = SparkSession.builder.getOrCreate()
# 1. テスト用データベースを作成
db_name_suffix = ''.join([random.choice(string.ascii_lowercase) for i in range(10)])
self.database_name = f'_ut_db__append_to_table_002_{db_name_suffix}'
spark.sql(f'DROP DATABASE IF EXISTS {self.database_name} CASCADE')
spark.sql(f'CREATE DATABASE IF NOT EXISTS {self.database_name}')
# テスト用データベースをカレントデータベースとして設定
spark.catalog.setCurrentDatabase(self.database_name)
# 2. テスト用テーブルを作成
table_name = '_ut_table___append_to_table'
spark.sql(
f'''
create TABLE {self.database_name}.{table_name}(
string_column string,
int_column long
)
USING delta
'''
)
## 3. テストケースにて、インプットのデータフレームと想定結果のデータフレームを作成
input_data_01 = [
Row(string_column='aaa', int_column=1),
Row(string_column='bbb', int_column=2),
Row(string_column='ccc', int_column=3),
]
input_schema_01 = """
string_column string,
int_column long
"""
input_df_01 = spark.createDataFrame(input_data_01, input_schema_01)
input_data_02 = [
Row(string_column='ddd', int_column=4),
Row(string_column='eee', int_column=5),
]
input_schema_02 = """
string_column string,
int_column long
"""
input_df_02 = spark.createDataFrame(input_data_02, input_schema_02)
## 期待値のデータフレームを作成
expected_data = [
Row(string_column='aaa', int_column=1),
Row(string_column='bbb', int_column=2),
Row(string_column='ccc', int_column=3),
Row(string_column='ddd', int_column=4),
Row(string_column='eee', int_column=5),
]
expected_schema = """
string_column string,
int_column long
"""
expected_df = spark.createDataFrame(expected_data, expected_schema)
# 4. テストケースにて、3のデータフレームを引数として関数を呼び出す
append_to_table(
source_df=input_df_01,
target_database_name=self.database_name,
target_table_name=table_name,
)
append_to_table(
source_df=input_df_02,
target_database_name=self.database_name,
target_table_name=table_name,
)
# 5. テストケースにて、4の実行結果を確認
result_df = spark.table(table_name)
view_result = f'_result_{table_name}'
view_expected = f'_expected_{table_name}'
result_df.createOrReplaceTempView(view_result)
expected_df.createOrReplaceTempView(view_expected)
df = spark.sql(
f'''
SELECT * FROM {view_result} EXCEPT SELECT * FROM {view_expected}
UNION ALL
SELECT * FROM {view_expected} EXCEPT SELECT * FROM {view_result}
'''
)
self.assertTrue(df.count() == 0)

# テストスイートにセット
suite = unittest.TestLoader().loadTestsFromTestCase(
test__append_to_table,
)
# テストランナーにセット
runner = unittest.TextTestRunner(
verbosity=2,
)
# テストランナーを実行
runner.run(suite)

2-3. 複数のテストケースをまとめて実行する方法
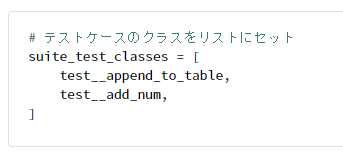
# テストケースのクラスをリストにセット
suite_test_classes = [
test__append_to_table,
test__add_num,
]
# 1. ループ処理で実行する方法
for suite_test_class in suite_test_classes:
suite = unittest.TestLoader().loadTestsFromTestCase(
suite_test_class,
)
# テストランナーにセット
runner = unittest.TextTestRunner(
verbosity=2,
)
# テストランナーを実行
runner.run(suite)

# 2. まとめて実行する方法
test_suite = unittest.TestSuite()
for suite_test_class in suite_test_classes:
test_suite.addTest(unittest.makeSuite(suite_test_class))
runner = unittest.TextTestRunner(
verbosity=2,
)
# テストランナーを実行
test_result = runner.run(test_suite)

2-4. unittest.mock によりテストダブル(モック等)を用いてテストを実施する方法
外部環境に依存するオブジェクト(他モジュール、REST APIの呼び出し、現在の日付等)の単体テストを実施する場合に利用する。
注意事項
- Databricks ノートブック上で定義したモジュールは、
from importで呼び出したモジュールが__main__下にて定義されること。
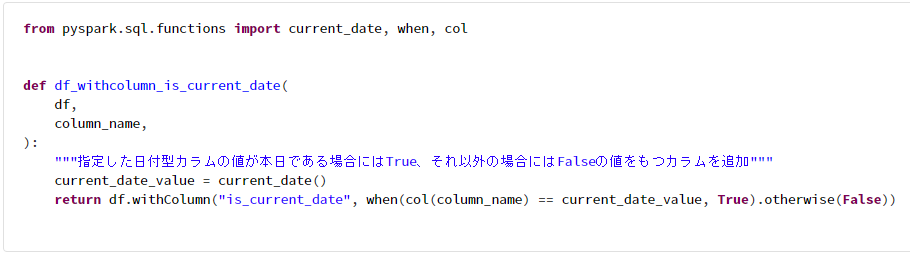
from pyspark.sql.functions import current_date, when, col
def df_withcolumn_is_current_date(
df,
column_name,
):
"""指定した日付型カラムの値が本日である場合にはTrue、それ以外の場合にはFalseの値をもつカラムを追加"""
current_date_value = current_date()
return df.withColumn("is_current_date", when(col(column_name) == current_date_value, True).otherwise(False))
import datetime
import unittest
from unittest import mock
from pyspark.sql import Row
class TestMock(unittest.TestCase):
@mock.patch('__main__.current_date', return_value=datetime.date(2021, 3, 30))
def test_df_withcolumn_current_date_001(self, mock_get):
""" """
# --- 事前準備 ---
## インプットとなるデータフレームを作成
input_data = [
(datetime.date(2021, 3, 30),),
(datetime.date(2021, 3, 31),),
]
input_schema = """
date date
"""
input_df = spark.createDataFrame(input_data, input_schema)
## 期待値のデータフレームを作成
expected_data = [
Row(date=datetime.date(2021, 3, 30), is_current_date=True),
Row(date=datetime.date(2021, 3, 31), is_current_date=False),
]
expected_schema = """
date date,
is_current_date boolean
"""
expected_df = spark.createDataFrame(expected_data, expected_schema)
input_df = df_withcolumn_is_current_date(input_df, 'date')
# --- テスト対象関数の呼び出し ---
result_df = df_withcolumn_is_current_date(input_df, 'date')
# --- 結果確認 ---
view_result = f'_result_unittest'
view_expected = f'_expected_unittest'
result_df.createOrReplaceTempView(view_result)
expected_df.createOrReplaceTempView(view_expected)
df = spark.sql(
f'''
SELECT * FROM {view_result} EXCEPT SELECT * FROM {view_expected}
UNION ALL
SELECT * FROM {view_expected} EXCEPT SELECT * FROM {view_result}
'''
)
self.assertTrue(df.count() == 0)
def test_df_withcolumn_current_date_002(self):
""" """
# --- 事前準備 ---
## インプットとなるデータフレームを作成
input_data = [
(datetime.date(2021, 3, 30),),
(datetime.date(2021, 3, 31),),
]
input_schema = """
date date
"""
input_df = spark.createDataFrame(input_data, input_schema)
## 期待値のデータフレームを作成
expected_data = [
Row(date=datetime.date(2021, 3, 30), is_current_date=False),
Row(date=datetime.date(2021, 3, 31), is_current_date=True),
]
expected_schema = """
date date,
is_current_date boolean
"""
expected_df = spark.createDataFrame(expected_data, expected_schema)
# --- テスト対象関数の呼び出し ---
with mock.patch('__main__.current_date', return_value=datetime.date(2021, 3, 31)):
result_df = df_withcolumn_is_current_date(input_df, 'date')
# --- 結果確認 ---
view_result = f'_result_unittest'
view_expected = f'_expected_unittest'
result_df.createOrReplaceTempView(view_result)
expected_df.createOrReplaceTempView(view_expected)
df = spark.sql(
f'''
SELECT * FROM {view_result} EXCEPT SELECT * FROM {view_expected}
UNION ALL
SELECT * FROM {view_expected} EXCEPT SELECT * FROM {view_result}
'''
)
self.assertTrue(df.count() == 0)
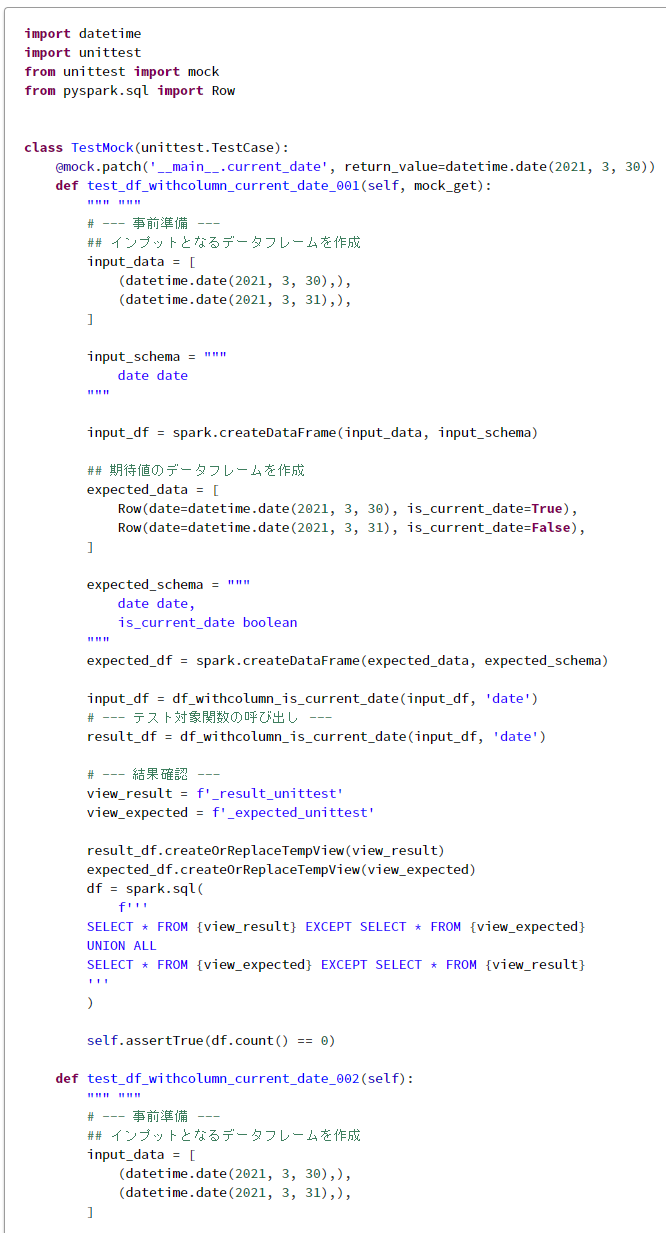
# テストスイートにセット
suite = unittest.TestLoader().loadTestsFromTestCase(TestMock)
# テストランナーにセット
runner = unittest.TextTestRunner(
verbosity=2,
)
# テストランナーを実行
runner.run(suite)
2-5. テスト結果のファイルの出力
unittest-xml-reporting ライブラリにより、テスト結果のJUnit 形式のファイルを出力できる。
%pip install unittest-xml-reporting -q

# 2つの引数を加算する関数を定義
def add_num(a, b):
return a + b

import unittest
class test__add_num(unittest.TestCase):
"""`add_num`関数に対する単体テスト"""
def test__add_num__001(self):
"""正常系テスト"""
self.assertTrue(add_num(1, 1) == 2)
def test__add_num__002(self):
"""異常系テスト"""
# 文字を引数とすることでエラーとなる想定
with self.assertRaises(TypeError):
add_num(1, 'ABC')
def test__add_num__003(self):
"""テストの失敗"""
assert add_num(1, 1) == 1
def test__add_num__004(self):
"""テストのエラー"""
1 + "a"
@unittest.skip("スキップ用")
def test__add_num__005(self):
"""テストコードのミス"""
assert a

test_report_dir = '/FileStore/ut/junit/test_reports'

# importの追加
import xmlrunner
# テストスイートにセット
suite = unittest.TestLoader().loadTestsFromTestCase(test__add_num)
# テストランナーにセット
runner = xmlrunner.XMLTestRunner(
output=test_report_dir,
verbosity=2,
)
# テストランナーを実行
test_result = runner.run(suite)

# XMLファイルを表示
ut_result_file = dbutils.fs.ls(f"file:{test_report_dir}")[0][0]
print(dbutils.fs.head(ut_result_file))

# 実行後に取得できる主な値を表示
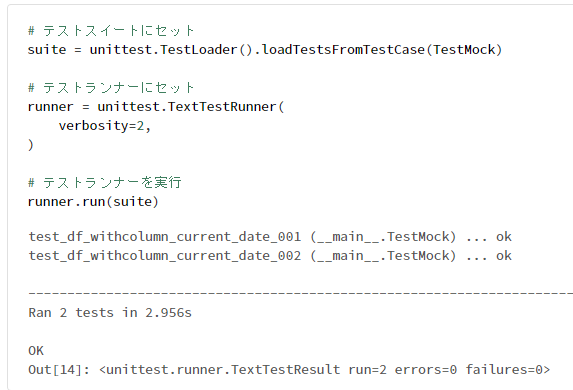
print(
f"""
# テスト全般
testsRun : {test_result.testsRun}
wasSuccessful : {test_result.wasSuccessful()}
testMethodPrefix : {unittest.loader.TestLoader.testMethodPrefix}
# テストの失敗関連
faulures_number : {len(test_result.failures)}
failures : {test_result.failures}
# テストのスキップ関連
skipped_number : {len(test_result.skipped)}
skipped : {test_result.skipped}
# エラー関連
skipped_number : {len(test_result.errors)}
errors : {test_result.errors}
expectedFailures : {test_result.expectedFailures}
# その他
unexpectedSuccesses : {test_result.unexpectedSuccesses}
unexpectedSuccesses : {test_result.unexpectedSuccesses}
""".strip()
)
2-6. unittest にてテストケースを取得
import unittest
# 2つの引数を加算する関数を定義
def add_num(a, b):
return a + b
class test__add_num__001(unittest.TestCase):
"""`add_num`関数に対する単体テスト"""
def test__add_num__001(self):
"""正常系テスト"""
self.assertTrue(add_num(1, 1) == 2)
class test__add_num__002(unittest.TestCase):
"""`add_num`関数に対する単体テスト"""
def test__add_num__001(self):
"""正常系テスト"""
self.assertTrue(add_num(1, 1) == 2)
class test__add_num__003(unittest.TestCase):
"""`add_num`関数に対する単体テスト"""
def test__add_num__001(self):
"""正常系テスト"""
self.assertTrue(add_num(1, 1) == 2)

tgt_ut_cases = []
current_globals = globals().copy()
for current_obj_value in current_globals.values():
if isinstance(current_obj_value, type) and issubclass(current_obj_value, unittest.TestCase):
tgt_ut_cases.append(current_obj_value)
import pprint
pprint.pprint(tgt_ut_cases)

3. pytest の基本的な利用方法
3-1. pytest によるテスト実行
%pip install pytest -q
# ローカルファイルシステム上にテストケースのコードを配置
test_code = '''
import unittest
# 2つの引数を加算する関数を定義
def add_num(a, b):
return a + b
class test__add_num__001(unittest.TestCase):
"""`add_num`関数に対する単体テスト"""
def test__add_num__001(self):
"""正常系テスト"""
self.assertTrue(add_num(1, 1) == 2)
class test__add_num__002(unittest.TestCase):
"""`add_num`関数に対する単体テスト"""
def test__add_num__001(self):
"""正常系テスト"""
self.assertTrue(add_num(1, 1) == 2)
class test__add_num__003(unittest.TestCase):
"""`add_num`関数に対する単体テスト"""
def test__add_num__001(self):
"""正常系テスト"""
self.assertTrue(add_num(1, 1) == 2)
'''
import os
test_code_path = '/databricks/driver/test_pytest'
dbutils.fs.mkdirs(f'file:{test_code_path}')
dbutils.fs.put(f'file:{test_code_path}/test_sample_code.py', test_code, True)
print(dbutils.fs.head(f'file:{test_code_path}/test_sample_code.py', 313))
# テストケースを配置したディレクトリをカレントディレクトリとする
os.chdir(test_code_path)

import pytest
pytest_pre_args = [
"-v",
"--pyargs",
f"{test_code_path}",
]
pytest.main(pytest_pre_args)

3-2. pytest にてテストケースを取得
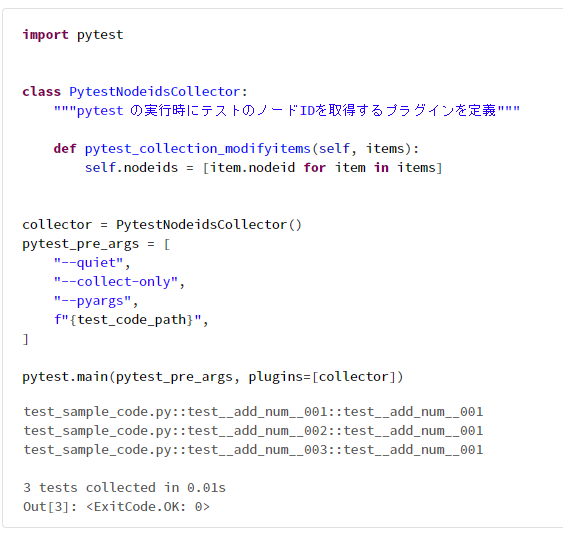
import pytest
class PytestNodeidsCollector:
"""pytest の実行時にテストのノードIDを取得するプラグインを定義"""
def pytest_collection_modifyitems(self, items):
self.nodeids = [item.nodeid for item in items]
collector = PytestNodeidsCollector()
pytest_pre_args = [
"--quiet",
"--collect-only",
"--pyargs",
f"{test_code_path}",
]
pytest.main(pytest_pre_args, plugins=[collector])
# 取得したテストケースを表示
import pprint
pprint.pprint(collector.nodeids)

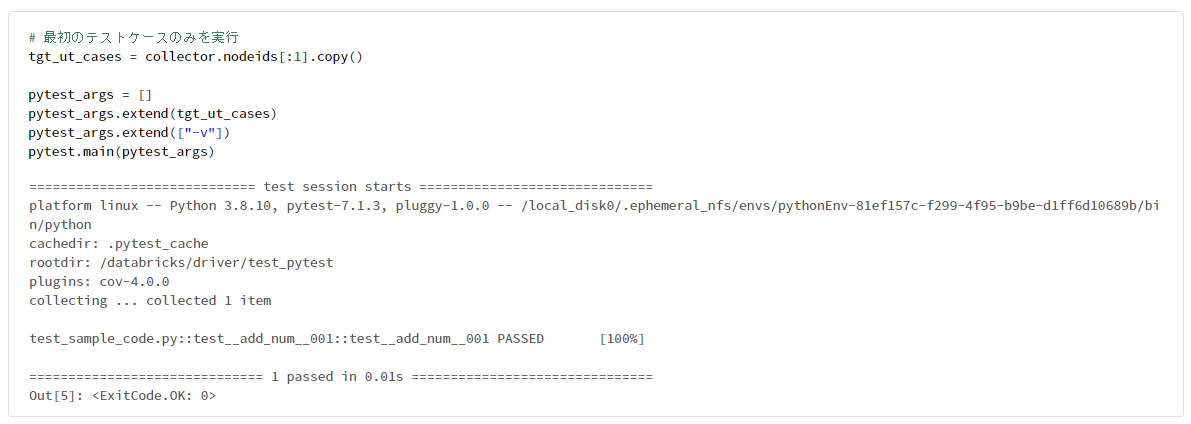
# 最初のテストケースのみを実行
tgt_ut_cases = collector.nodeids[:1].copy()
pytest_args = []
pytest_args.extend(tgt_ut_cases)
pytest_args.extend(["-v"])
pytest.main(pytest_args)
# ローカル ファイル システム上のファイルを削除
dbutils.fs.rm(f'file:{test_code_path}', True)
4. PySparkにおける単体テストのテクニック
4-1. 単体テスト用データの作成
単体テストのデータを用意する方法として、次の3種類がある。詳細は、PySpark 開発時に知っておくべき7つのテーマ 4. 変数からデータフレームを作成にて記載。
- 辞書型リストを用いる方法
- 多次元リストを用いる方法
-
pyspark.sql.Rowメソッドを用いる方法
4-2. ノートブック型 Spark 環境外部からテストを実行する際のテクニック集
1. テストを実施する際には、3つの環境に応じてテストを実施。
| # | 環境 | 判断方法 |
|---|---|---|
| 1 | Databricks Notebook |
importによりライブラリを呼び出していないこと。 |
| 2 | Databricks Python script Type workflows |
importによりライブラリを呼び出していること、および、spark.master のSpark Config 値が local でないこと |
| 3 | ローカル環境(Databricks Connect) |
importによりライブラリを呼び出していること、および、spark.master のSpark Config 値が local であること。 |
2. SparkSession や dbutils を定義
SparkSession を定義
from pyspark.sql import SparkSession
SparkSession.builder.getOrCreate()
SparkSession を取得
from pyspark.sql import SparkSession
spark = SparkSession.getActiveSession()
Databricks に利用できる dbutils を定義
try:
from pyspark.dbutils import DBUtils
except ImportError:
pass
dbutils = DBUtils(spark)
3. テストケースの Python ファイルから src ディレクトリへの相対パスを sys.pathに追加。
# モジュールをノートブックから取得するか。Falseとなる場合には、python ファイルを import する場合。
call_modules_from_noteboks = True
# ローカル開発時に利用するモジュールの呼び出し
try:
sys.path.append(os.path.join(os.path.dirname(__file__), '../../../../src'))
from utilities.spark_utilities__v1 import SparkUtilities
from utilities.test_helper__v1 import TestHelper
from utilities.data_engineering__v1 import DataEngineering
call_modules_from_noteboks = False
except (NameError, ImportError):
pass
4. 変数(call_modules_from_noteboks)により、環境に応じて、unittest のパッチ( patch )対象メソッド名の切り替え
# ローカルで実行する場合とDatabricks Workspace 上で実行する場合で、パッチ対象のメソッド名を切り替える
if call_modules_from_noteboks:
self.patch_obj_001_name = '__main__.dbutils.notebook.entry_point.getDbutils'
else:
self.patch_obj_001_name = 'Dbult.notebook.entry_point.getDbutils'
pass
patch_objs = mock__get_org_id(SparkUtilities._spark_servies_databricks)
# テスト対象の関数の実行
################################
with patch(patch_objs.patch_obj_001_name) as patch_obj_001:
patch_obj_001.return_value = patch_return_value
result = SparkUtilities.get_org_id()
5. Databricks Connect がサポートしていない機能をテストする際には、unittest の unittest.skipIf デコレーターによりテスト対象外に設定
class _test_cases__spark_utilities:
def _get_has_executed_on_local(self):
spark = SparkSession.builder.getOrCreate()
# ローカル環境から実行されている場合には、 local ではじまる値を取得可能
return spark.conf.get("spark.master").startswith("local")
@unittest.skipIf(
_test_cases__spark_utilities()._get_has_executed_on_local() is True,
"display method is not suppoted from eternal Databricks",
)