概要
Azure Blob Storage 上のファイルを Python の Azure Storage SDK でコピーする 4 つの方法を紹介します。
-
upload_blob_from_urlによる方法 -
start_copy_from_urlによる方法 -
readallとupload_blobによる方法 -
stage_block_from_urlとcommit_block_listによる方法
各方法の特徴は次のとおりです。
| 方法 | 動作モデル | 主な制約 | 推奨される用途 |
|---|---|---|---|
upload_blob_from_url |
サーバー側で同期的にコピー | ソース BLOB のサイズは最大 5,000 MiB | 小〜中規模ファイルの確実なコピー |
start_copy_from_url |
サーバー側で非同期にコピー | 完了確認のためポーリングが必要 | 大容量ファイルのコピー |
readall + upload_blob
|
クライアント側でダウンロード後アップロード | 実行環境のメモリと帯域を消費 | 小さいファイルの検証用途のみ |
stage_block_from_url + commit_block_list
|
サーバー側でブロック単位にコピーし、最後にコミット | ブロック ID 管理と commit_block_list が必要 |
大容量ファイルをブロック単位で制御してコピー |
注意事項
1. upload_blob_from_url による方法 には次のサイズ制限がある点にも注意してください。
ソース BLOB のサイズは、最大 5,000 メガバイト (MiB) までです。

出所: URL からの BLOB の配置 (REST API) - Azure Storage | Microsoft Learn
2. start_copy_from_url利用時の注意事項として、 0 バイトのファイルが事前に作成されるという仕様があります。 Databricks などで取り込みを実施する場合に、 0 バイトのファイルがあるという前提で処理が実施されるリスクがあります。
For a block blob or an append blob, Blob Storage creates a committed blob of zero length before returning from this operation.

出所: Copy Blob (REST API) - Azure Storage | Microsoft Learn
ブロック BLOB または追加 BLOB の場合、Blob Storage はこの操作から戻る前に、長さ 0 のコミット済み BLOB を作成します。
上記の翻訳
3. readall と upload_blob による方法 は、ファイル全体を実行環境のメモリに読み込むため、Azure Functions など利用可能なリソースに上限があるサービスでの実行は非推奨です。本記事では Databricks 上で検証しています。
4. stage_block_from_url と commit_block_list による方法では未コミットのファイル数が
A blob can have a maximum of 100,000 uncommitted blocks at any time. If this maximum is exceeded, the service returns status code 409 (RequestEntityTooLargeBlockCountExceedsLimit).

出所: Put Block From URL (REST API) - Azure Storage | Microsoft Learn
事前準備
コピー元・コピー先となる 2 つのコンテナーを用意し、ソースファイルを配置したうえで、Databricks 上に Azure Storage SDK の BlobClient を初期化します。
Azure Storage に 2 つのコンテナーとソースファイルを準備
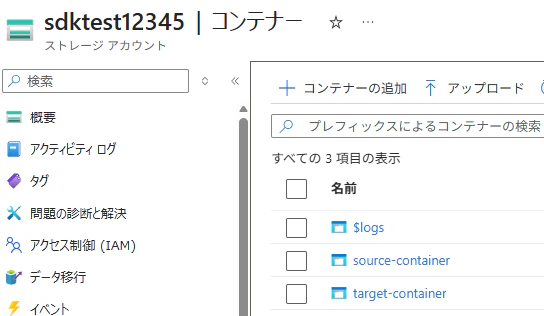
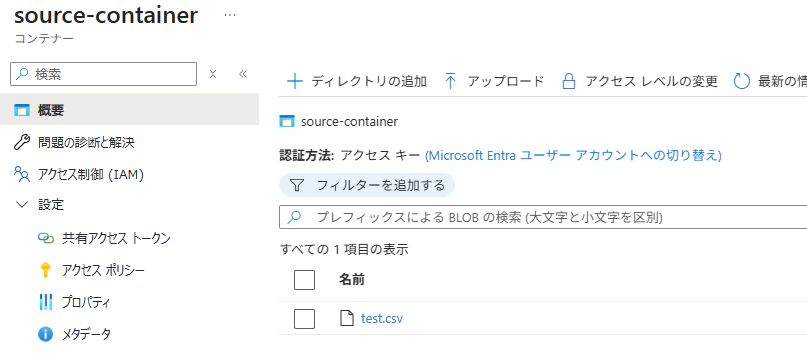
source-container と target-container という 2 つのコンテナーを作成します。
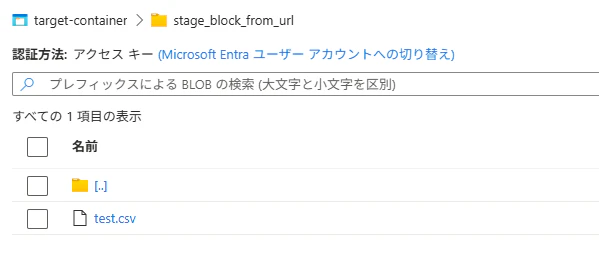
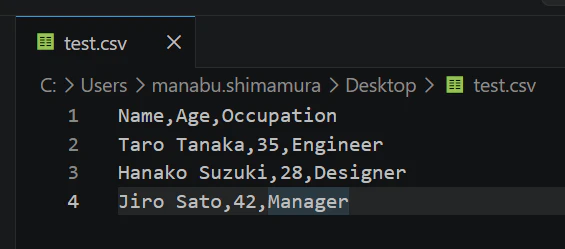
下記の CSV ファイルを test.csv という名称で source-container に配置します。
Name,Age,Occupation
Taro Tanaka,35,Engineer
Hanako Suzuki,28,Designer
Jiro Sato,42,Manager
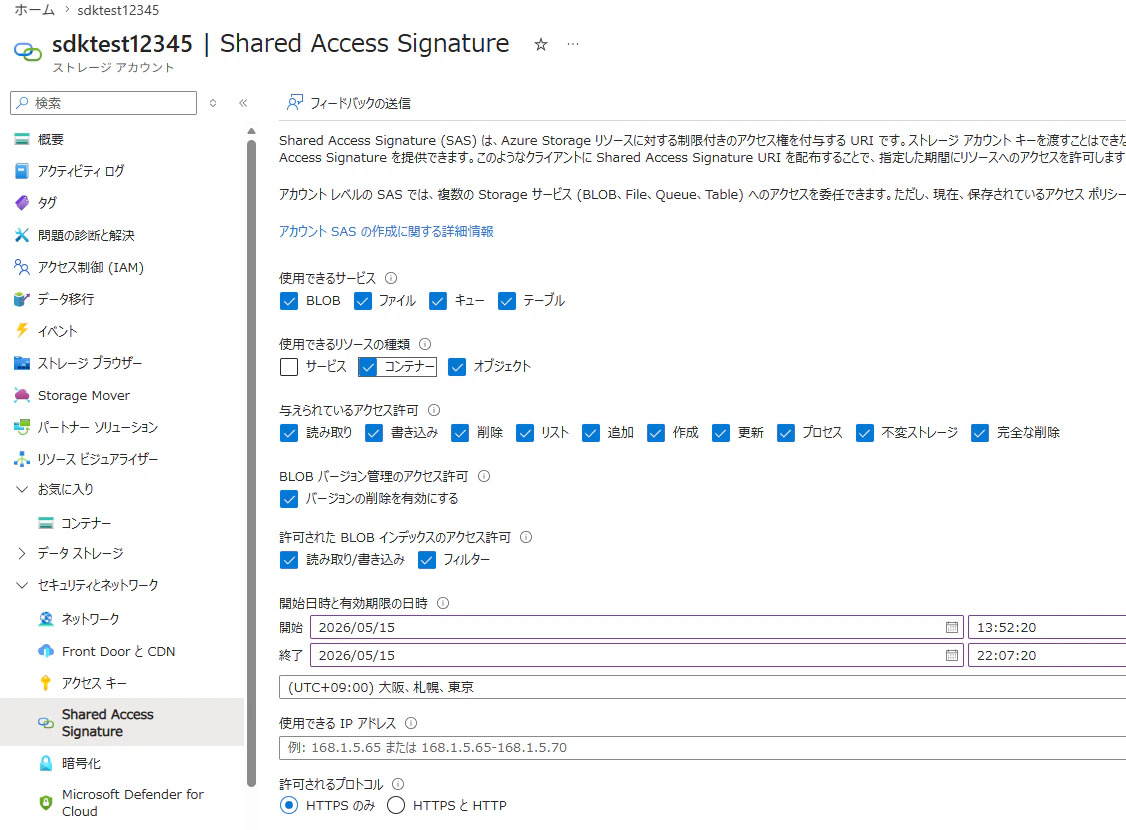
Azure Storage の SAS キーを取得
Databricks にライブラリをインストールし、ソースの BlobClient をインスタンス化
必要なライブラリをインストールします。
%pip install azure-storage-blob azure-identity -q
dbutils.library.restartPython()

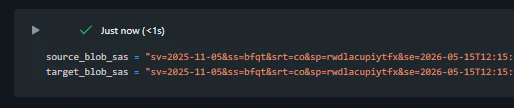
取得した SAS キーを変数にセットします。
source_blob_sas = ""
target_blob_sas = ""
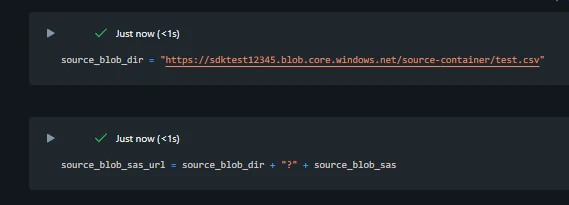
ソースの URL と SAS キーを組み合わせた URL を作成します。
source_blob_dir = "https://sdktest12345.blob.core.windows.net/source-container/test.csv"
source_blob_sas_url = source_blob_dir + "?" + source_blob_sas
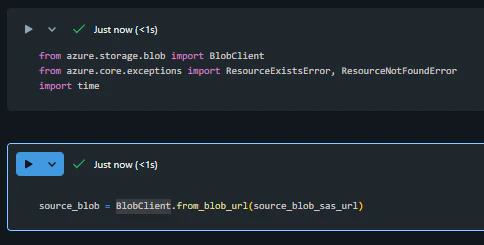
ソースの BlobClient をインスタンス化します。
from azure.storage.blob import BlobClient
from azure.core.exceptions import ResourceExistsError, ResourceNotFoundError
import time
source_blob = BlobClient.from_blob_url(source_blob_sas_url)
検証
1. upload_blob_from_url による方法
upload_blob_from_url は、Azure 側でソース URL から直接コピーを実行する同期 API です。呼び出しが完了した時点でコピーも完了しているため、後処理が簡潔になります。一方で、前述のとおりソース BLOB のサイズは最大 5,000 MiB に制限されます。
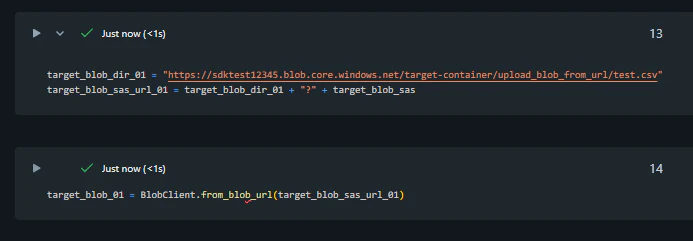
コピー先の BlobClient をインスタンス化します。
target_blob_dir_01 = "https://sdktest12345.blob.core.windows.net/target-container/upload_blob_from_url/test.csv"
target_blob_sas_url_01 = target_blob_dir_01 + "?" + target_blob_sas
target_blob_01 = BlobClient.from_blob_url(target_blob_sas_url_01)
ファイルをコピーします。
target_blob_01.upload_blob_from_url(source_blob_sas_url, overwrite=True)
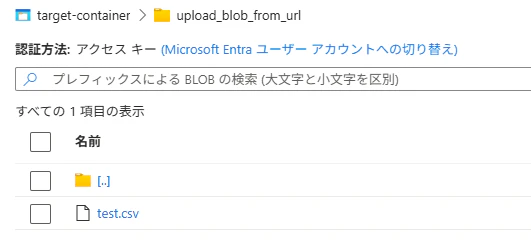
Azure Storage にファイルがコピーされていることを確認します。
2. start_copy_from_url による方法
start_copy_from_url は非同期 API で、呼び出しはコピー処理の開始要求のみを行います。完了確認には get_blob_properties でコピーステータスをポーリングする必要があります。サイズ制限が緩いため、大容量ファイルのコピーに適しています。
コピー先の BlobClient をインスタンス化します。
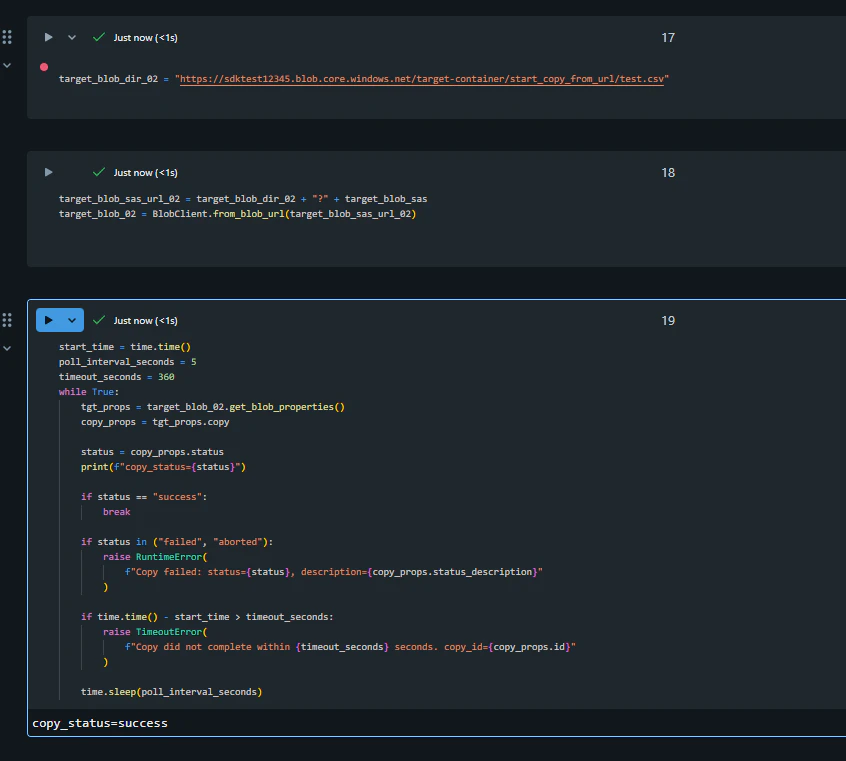
target_blob_dir_02 = "https://sdktest12345.blob.core.windows.net/target-container/start_copy_from_url/test.csv"
target_blob_sas_url_02 = target_blob_dir_02 + "?" + target_blob_sas
target_blob_02 = BlobClient.from_blob_url(target_blob_sas_url_02)
コピーを開始し、完了するまでステータスをポーリングします。
copy_result = target_blob_02.start_copy_from_url(source_blob_sas_url)
start_time = time.time()
poll_interval_seconds = 5
timeout_seconds = 360
while True:
tgt_props = target_blob_02.get_blob_properties()
copy_props = tgt_props.copy
status = copy_props.status
print(f"copy_status={status}")
if status == "success":
break
if status in ("failed", "aborted"):
raise RuntimeError(
f"Copy failed: status={status}, description={copy_props.status_description}"
)
if time.time() - start_time > timeout_seconds:
raise TimeoutError(
f"Copy did not complete within {timeout_seconds} seconds. copy_id={copy_props.id}"
)
time.sleep(poll_interval_seconds)
Azure Storage にファイルがコピーされていることを確認します。
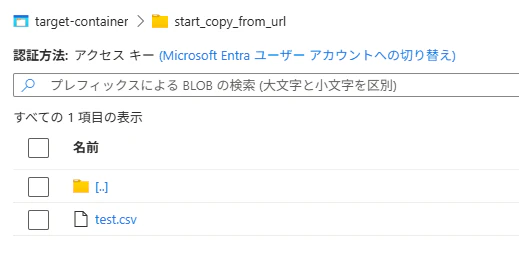
3. readall と upload_blob による方法
この方法では、download_blob().readall() でソースをクライアント側のメモリに全量読み込んだうえで、upload_blob でコピー先にアップロードします。Azure 側でのサーバー間コピーではなくクライアント経由のデータ転送となるため、ファイルサイズに応じてメモリ消費と通信量が増加する点に注意してください。
コピー先の BlobClient をインスタンス化します。
target_blob_dir_03 = "https://sdktest12345.blob.core.windows.net/target-container/upload_blob/test.csv"
target_blob_sas_url_03 = target_blob_dir_03 + "?" + target_blob_sas
target_blob_03 = BlobClient.from_blob_url(target_blob_sas_url_03)
ファイルをコピーします。
data = source_blob.download_blob().readall()
target_blob_03.upload_blob(data, overwrite=True)
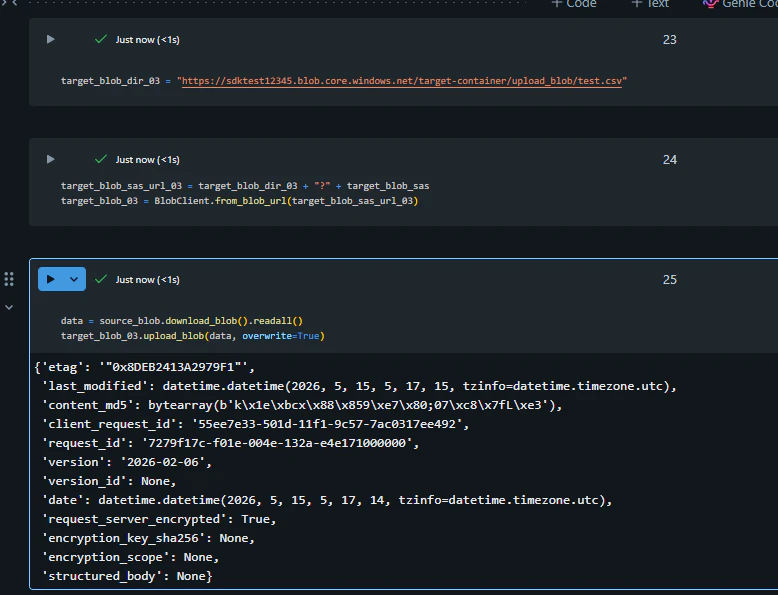
Azure Storage にファイルがコピーされていることを確認します。

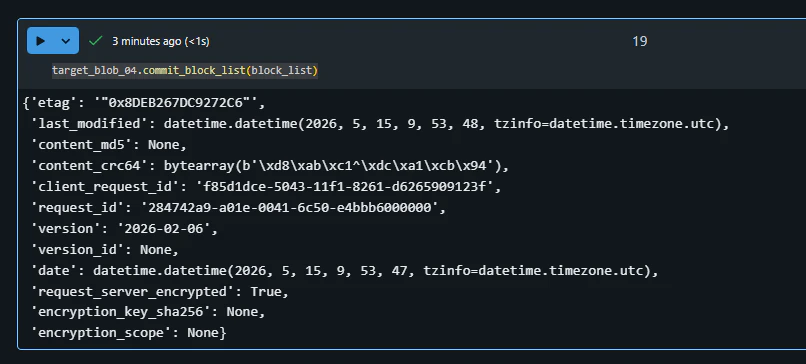
4. stage_block_from_url と commit_block_list による方法
stage_block_from_url は、コピー元 URL から読み取ったデータをコピー先 Blob のブロックとしてステージングする API です。
upload_blob_from_url と異なり、1 回の API 呼び出しで Blob 全体を確定するのではなく、ブロック単位で stage_block_from_url を実行し、最後に commit_block_list で Blob として確定します。
大容量ファイルをブロック単位で制御しながらサーバー側コピーしたい場合に有効です。
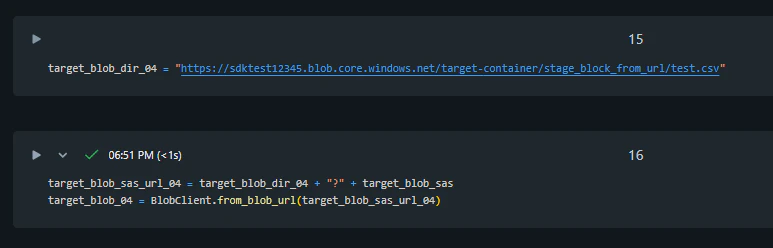
コピー先の BlobClient をインスタンス化します。
target_blob_dir_04 = "https://sdktest12345.blob.core.windows.net/target-container/stage_block_from_url/test.csv"
target_blob_sas_url_04 = target_blob_dir_04 + "?" + target_blob_sas
target_blob_04 = BlobClient.from_blob_url(target_blob_sas_url_04)
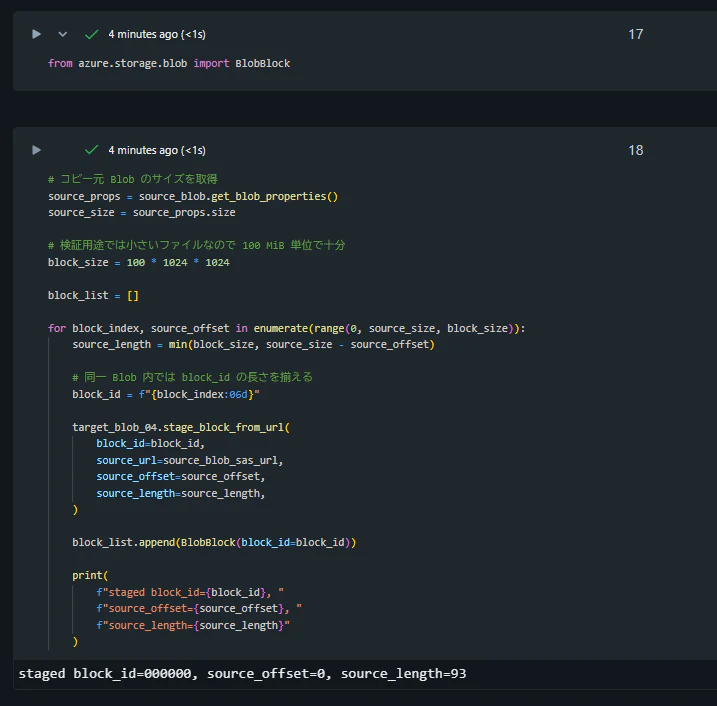
from azure.storage.blob import BlobBlock
# コピー元 Blob のサイズを取得
source_props = source_blob.get_blob_properties()
source_size = source_props.size
# 検証用途では小さいファイルなので 100 MiB 単位で十分
block_size = 100 * 1024 * 1024
block_list = []
for block_index, source_offset in enumerate(range(0, source_size, block_size)):
source_length = min(block_size, source_size - source_offset)
# 同一 Blob 内では block_id の長さを揃える
block_id = f"{block_index:06d}"
target_blob_04.stage_block_from_url(
block_id=block_id,
source_url=source_blob_sas_url,
source_offset=source_offset,
source_length=source_length,
)
block_list.append(BlobBlock(block_id=block_id))
print(
f"staged block_id={block_id}, "
f"source_offset={source_offset}, "
f"source_length={source_length}"
)
現時点ではファイルが作成されません。
commit_block_listメソッドを実行後に、ファイルが追加されることを確認します。
target_blob_04.commit_block_list(block_list)