概要
Databricks Auto Loaderを使用して、NullTypes (void) を含むカラムを持つデータフレームを書き込む際には、特定のエラーが発生することがあります。このエラーは、NullTypesのカラムに対して、明示的にデータ型を指定しなければならないことを示しています。エラーが発生する状況とその解決策について説明します。
com.databricks.sql.transaction.tahoe.DeltaAnalysisException: Delta doesn't accept NullTypes in the schema for streaming writes.
DataFrameWriter を使用してデータフレームを書き込む際には、NullTypes (void) のカラムも書き込むことができます。しかし、Databricks Auto Loaderでは、このようなカラムの書き込みができないため、注意が必要です。
エラーの発生方法と対応方法
事前準備
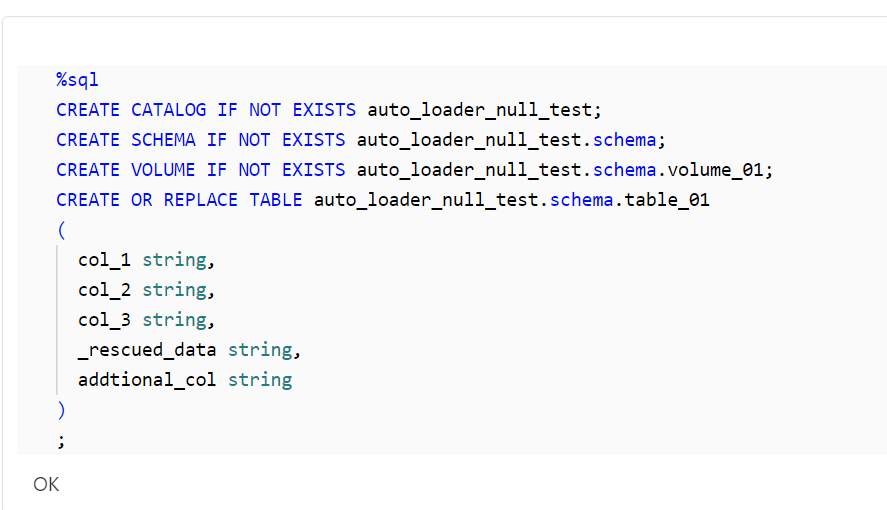
Databricks Unity Catalog 上に検証で利用するオブジェクトを作成します。
%sql
CREATE CATALOG IF NOT EXISTS auto_loader_null_test;
CREATE SCHEMA IF NOT EXISTS auto_loader_null_test.schema;
CREATE VOLUME IF NOT EXISTS auto_loader_null_test.schema.volume_01;
CREATE OR REPLACE TABLE auto_loader_null_test.schema.table_01
(
col_1 string,
col_2 string,
col_3 string,
_rescued_data string,
addtional_col string
)
;
ソースのファイルを配置します。
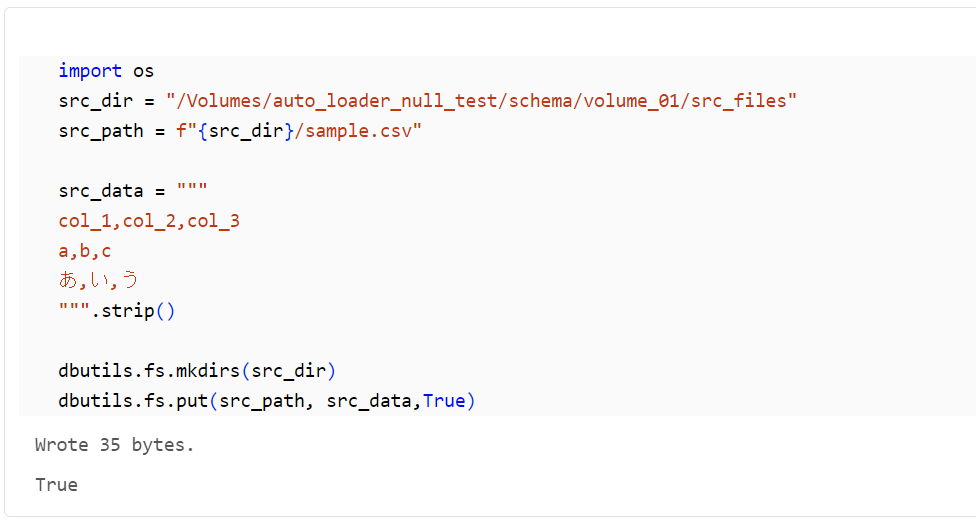
import os
src_dir = "/Volumes/auto_loader_null_test/schema/volume_01/src_files"
src_path = f"{src_dir}/sample.csv"
src_data = """
col_1,col_2,col_3
a,b,c
あ,い,う
""".strip()
dbutils.fs.mkdirs(src_dir)
dbutils.fs.put(src_path, src_data,True)
エラーの発生方法
cloudFiles フォーマットの readstream のデータフレームを作成します。
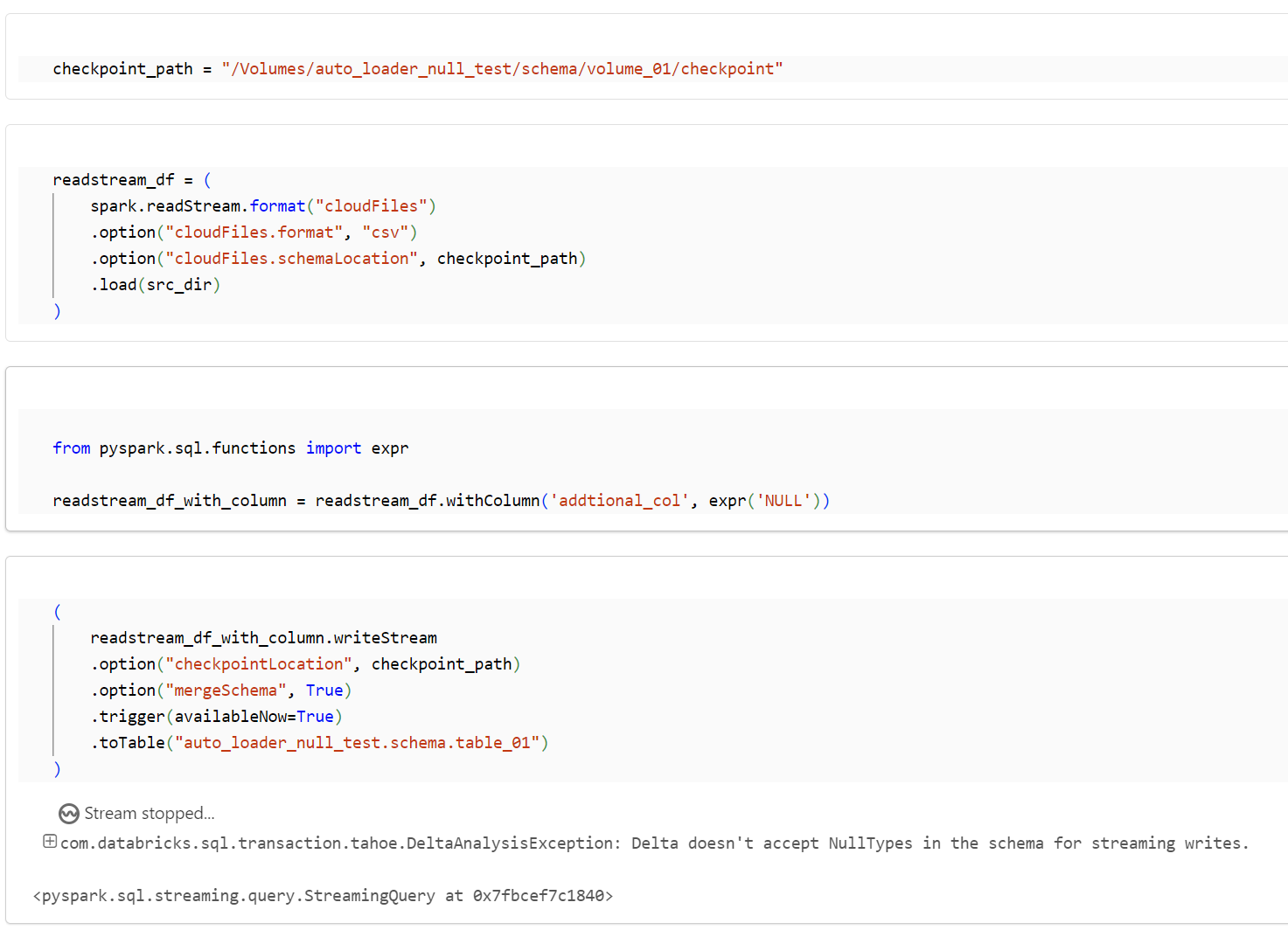
checkpoint_path = "/Volumes/auto_loader_null_test/schema/volume_01/checkpoint"
readstream_df = (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("cloudFiles.schemaLocation", checkpoint_path)
.load(src_dir)
)
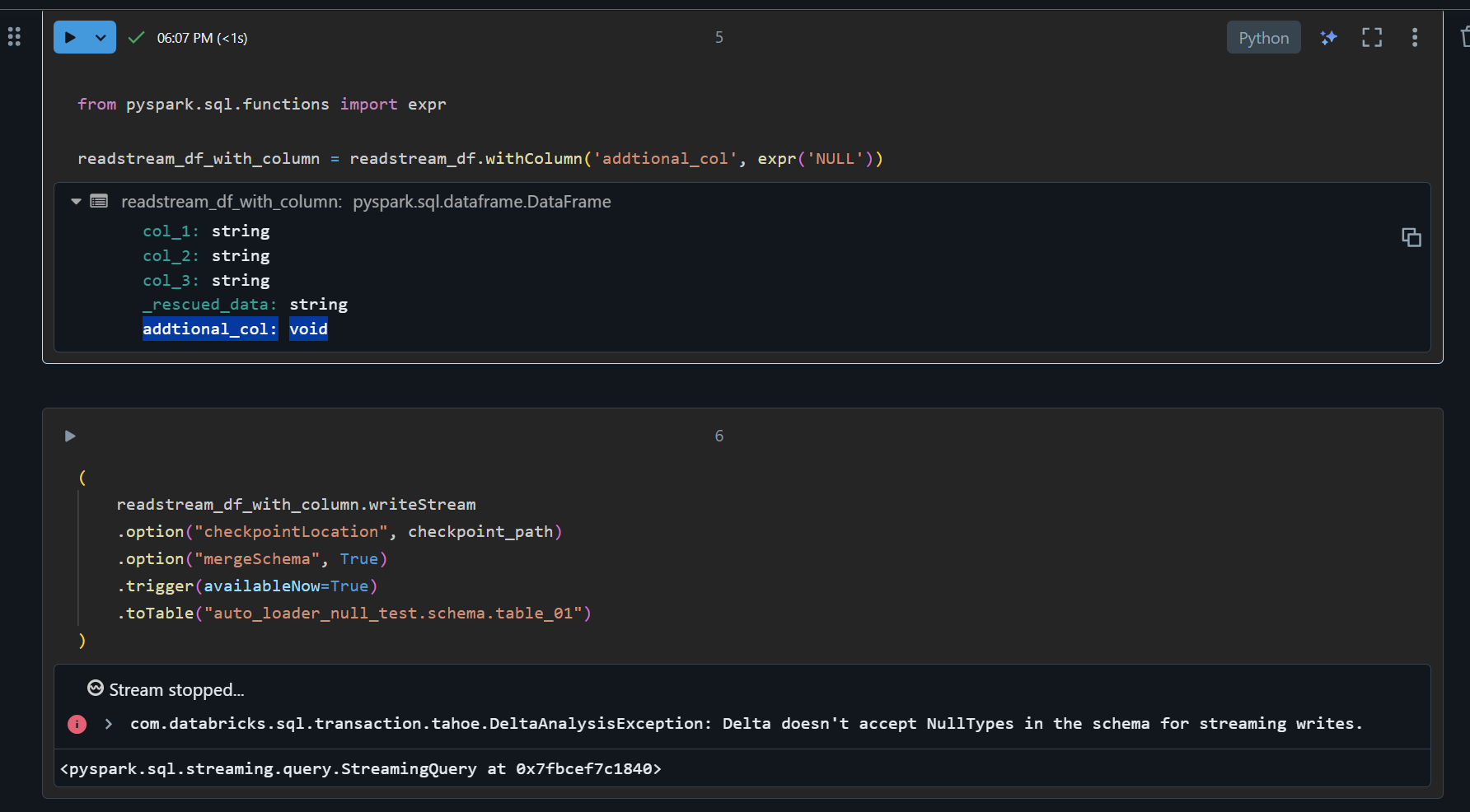
NullTypes (void) のカラムを追加します。
from pyspark.sql.functions import expr
readstream_df_with_column = readstream_df.withColumn('addtional_col', expr('NULL'))
書き込みを実行するとエラーとなります。
(
readstream_df_with_column.writeStream
.option("checkpointLocation", checkpoint_path)
.option("mergeSchema", True)
.trigger(availableNow=True)
.toTable("auto_loader_null_test.schema.table_01")
)
com.databricks.sql.transaction.tahoe.DeltaAnalysisException: Delta doesn't accept NullTypes in the schema for streaming writes.
エラーへの対応方法
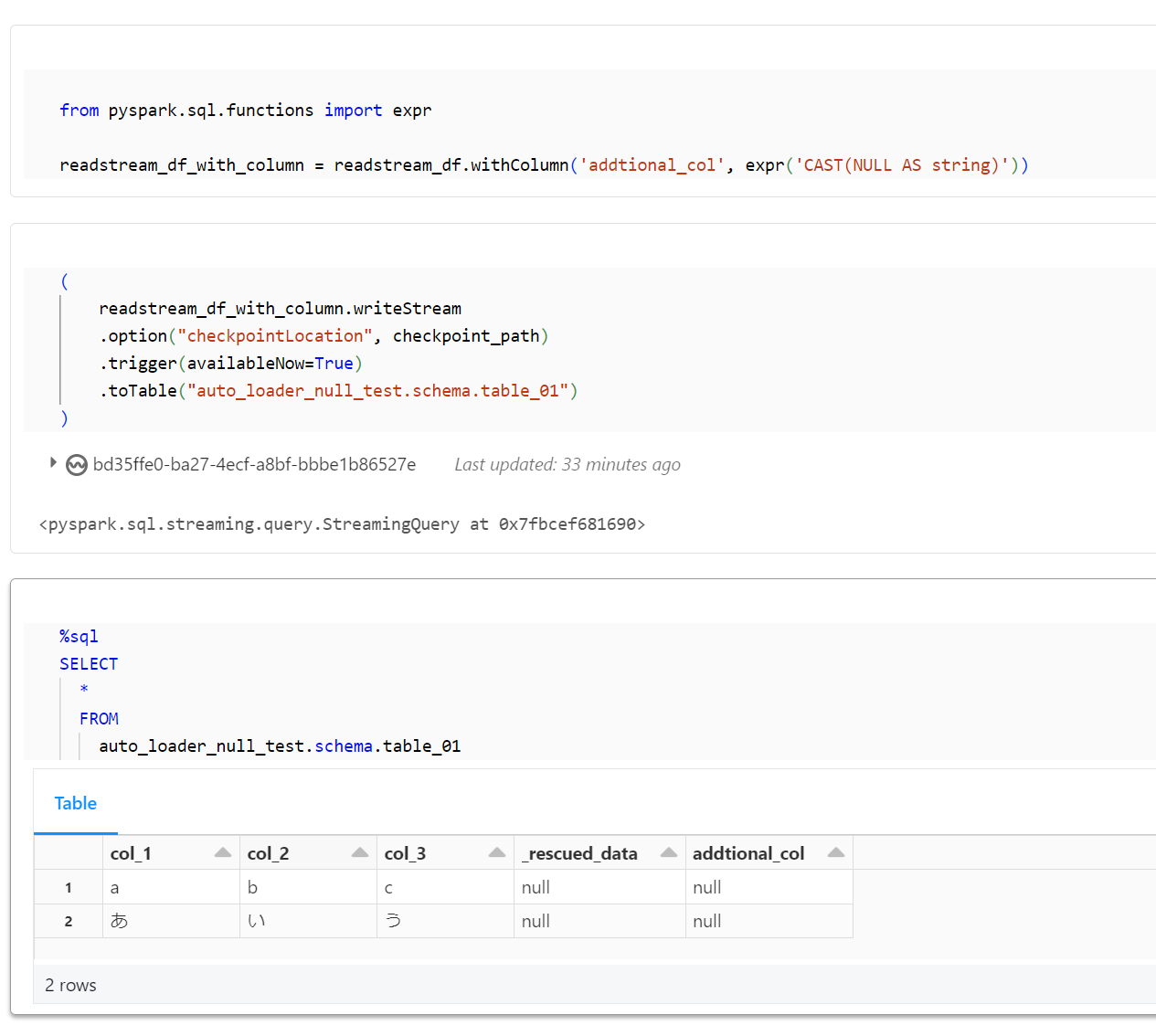
カラムを追加する際に、CAST によりデータ型を明示するように変更します。
from pyspark.sql.functions import expr
readstream_df_with_column = readstream_df.withColumn('addtional_col', expr('CAST(NULL AS string)'))
正常に書き込みが完了することを確認します。
(
readstream_df_with_column.writeStream
.option("checkpointLocation", checkpoint_path)
.trigger(availableNow=True)
.toTable("auto_loader_null_test.schema.table_01")
)
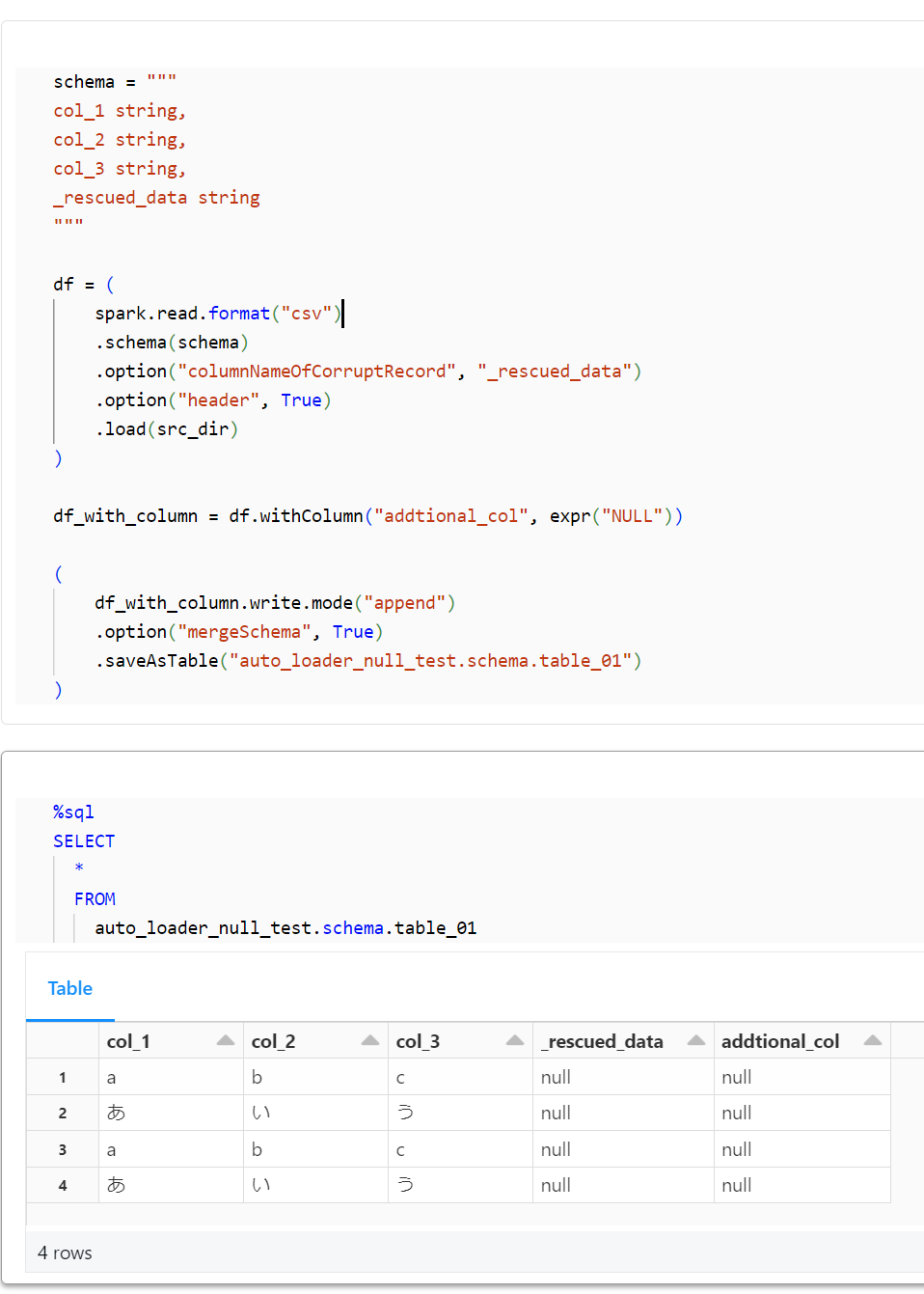
DataFrameWriter における動作確認
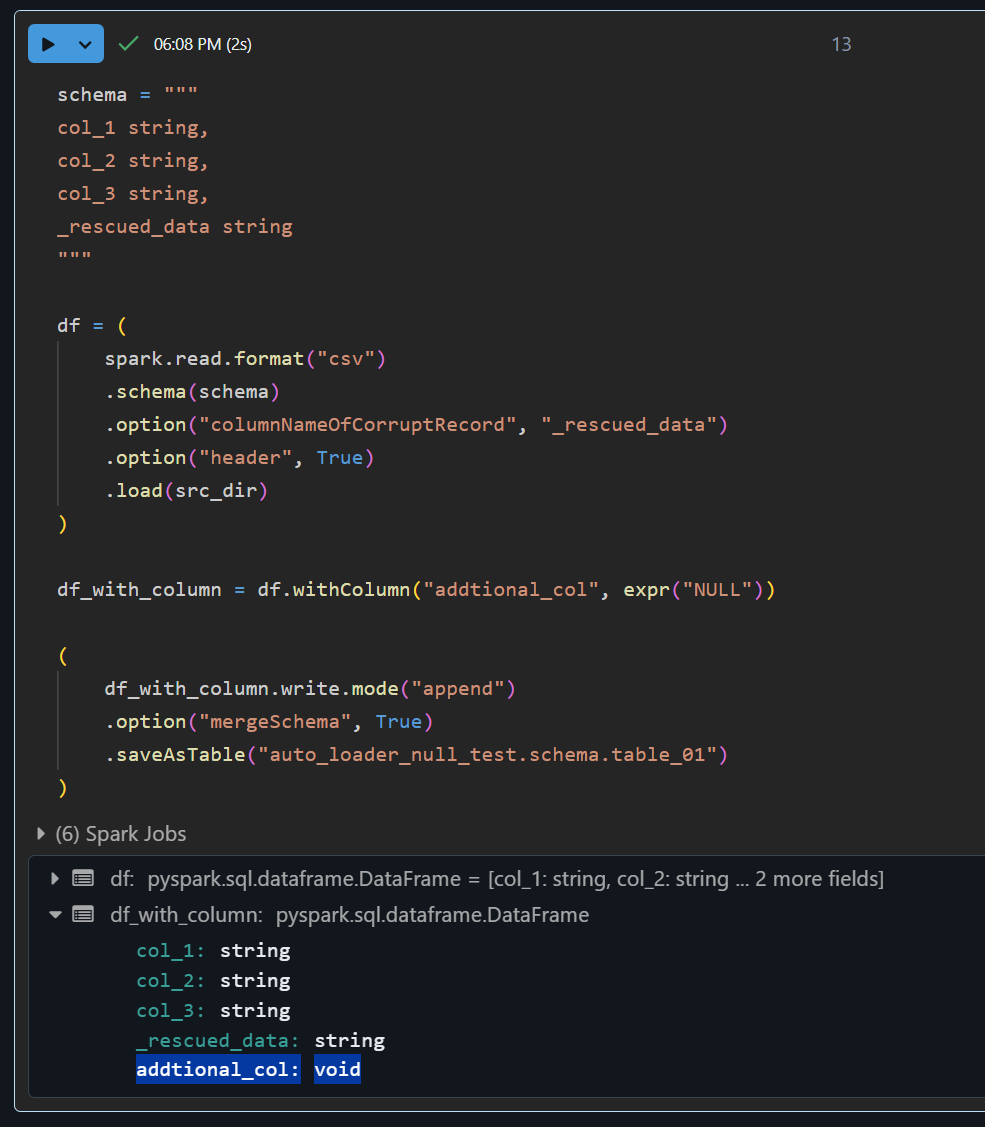
正常通りに書き込める事を確認します。
schema = """
col_1 string,
col_2 string,
col_3 string,
_rescued_data string
"""
df = (
spark.read.format("csv")
.schema(schema)
.option("columnNameOfCorruptRecord", "_rescued_data")
.option("header", True)
.load(src_dir)
)
df_with_column = df.withColumn("addtional_col", expr("NULL"))
(
df_with_column.write.mode("append")
.option("mergeSchema", True)
.saveAsTable("auto_loader_null_test.schema.table_01")
)
本手順で作成したリソースの削除
%sql
DROP CATALOG auto_loader_null_test CASCADE;