概要
COPY INTO は、Databricks においてテーブルにデータを簡易的に取り込むための SQL コマンドです。Auto Loader 機能と比較されることが多く、以下のようなメリットとデメリットがあります。
-
メリット
- 単一の SQL で実行できることから SQL 開発者にとって使いやすい。
- Auto Loader で必要とされるチェックポイントの設定が不要。
- ファイルの再取り込みが容易。
-
デメリット
-
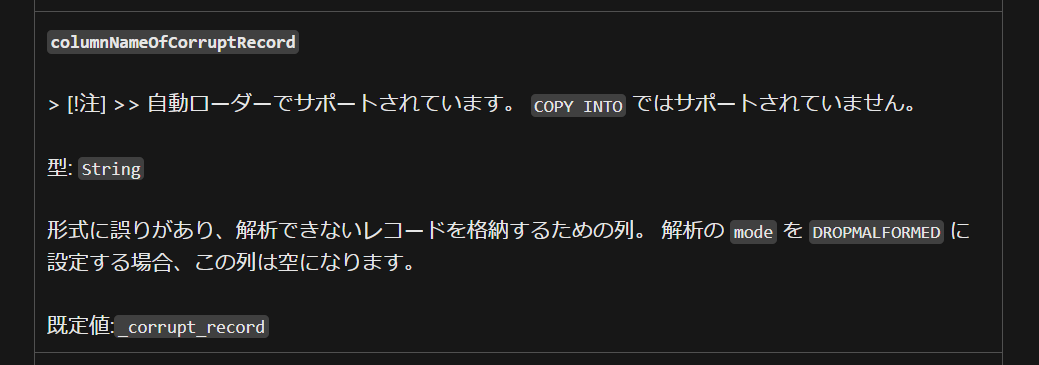
columnNameOfCorruptRecord機能が利用できないこと。 - 単一の SQL 文として実行する必要があり、関数化した際の SQL 文字列を生成するプログラムが複雑となる。
- PySpark で実装した監査列の付与などの関数を利用できない。
-
データエンジニアリングを実施する際には、columnNameOfCorruptRecord 機能が利用できないことが致命的であることから、なるべく Auto Loader を利用することをおすすめします。この機能は、ファイルの読み込み時にエラーが発生した際に、エラーが発生した行を特定するための列を追加する機能です。想定外のデータが連携されたときに特定することが容易となります。
引用元:COPY INTO - Azure Databricks - Databricks SQL | Microsoft Learn
私は COPY INTO のプログラムの多くを Auto Loader に変更することとしましたが、COPY INTO に関して調査した内容を共有します。
事前準備
まず、データを格納するためのスキーマを作成します。以下のコードは、hive_metastore.copy_into_01という名前のスキーマを作成します。スキーマがすでに存在する場合は、そのスキーマを使用します。
%sql
CREATE SCHEMA IF NOT EXISTS hive_metastore.copy_into_01;
COPY INTO の基本的な実行
次に、テーブルを作成し、データを取り込む基本的な手順を示します。以下のコードは、hive_metastore.copy_into_01.table_01という名前のテーブルを作成し、そのテーブルにデータを取り込むためのCOPY INTOコマンドを実行します。テーブルがすでに存在する場合は、そのテーブルを削除してから新たに作成します。
%sql
DROP TABLE IF EXISTS hive_metastore.copy_into_01.table_01;
CREATE TABLE hive_metastore.copy_into_01.table_01 (
instant STRING,
dteday STRING,
season STRING,
yr STRING,
mnth STRING,
holiday STRING,
weekday STRING,
workingday STRING,
weathersit STRING,
temp STRING,
atemp STRING,
hum STRING,
windspeed STRING,
casual STRING,
registered STRING,
cnt STRING
);
以下のコードは、COPY INTOコマンドを使用して、指定したファイルからデータを取り込みます。この例では、CSV形式のファイルからデータを取り込んでいます。
%sql
COPY INTO hive_metastore.copy_into_01.table_01
FROM 'dbfs:/databricks-datasets/bikeSharing/data-001/day.csv'
FILEFORMAT = CSV
FORMAT_OPTIONS ('DELIMITER' = ',', 'header' = 'true');

カラム名の変更(スキーマ展開なし)
次に、カラム名を変更する方法を示します。以下のコードにて、新たにテーブルを作成します。そのテーブルにデータを取り込む際に、元のファイルのカラム名を変更することを想定しています。
%sql
DROP TABLE IF EXISTS hive_metastore.copy_into_01.table_02;
CREATE TABLE hive_metastore.copy_into_01.table_02(
n_nationkey string,
n_name string,
n_regionkey string,
n_comment string
);
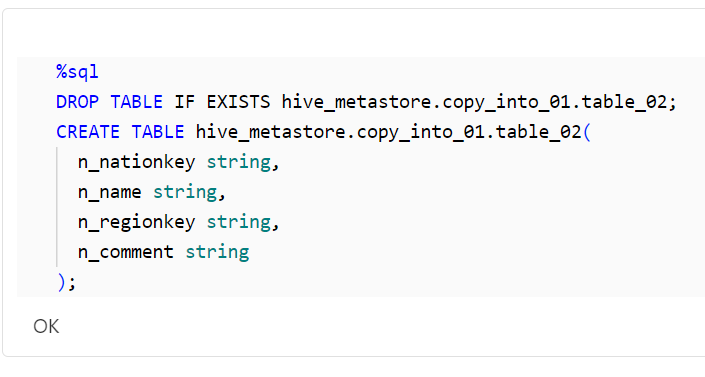
以下のコードは、COPY INTOコマンドを使用して、指定したファイルからデータを取り込みます。この例では、元のファイルのカラム名を変更してデータを取り込んでいます。
%sql
COPY INTO hive_metastore.copy_into_01.table_02
FROM (
SELECT
_C0 AS n_nationkey,
_C1 AS n_name,
_C2 AS n_regionkey,
_C3 AS n_comment
FROM
'dbfs:/databricks-datasets/tpch/data-001/nation/nation.tbl'
)
FILEFORMAT = CSV FORMAT_OPTIONS ('DELIMITER' = '|')
;
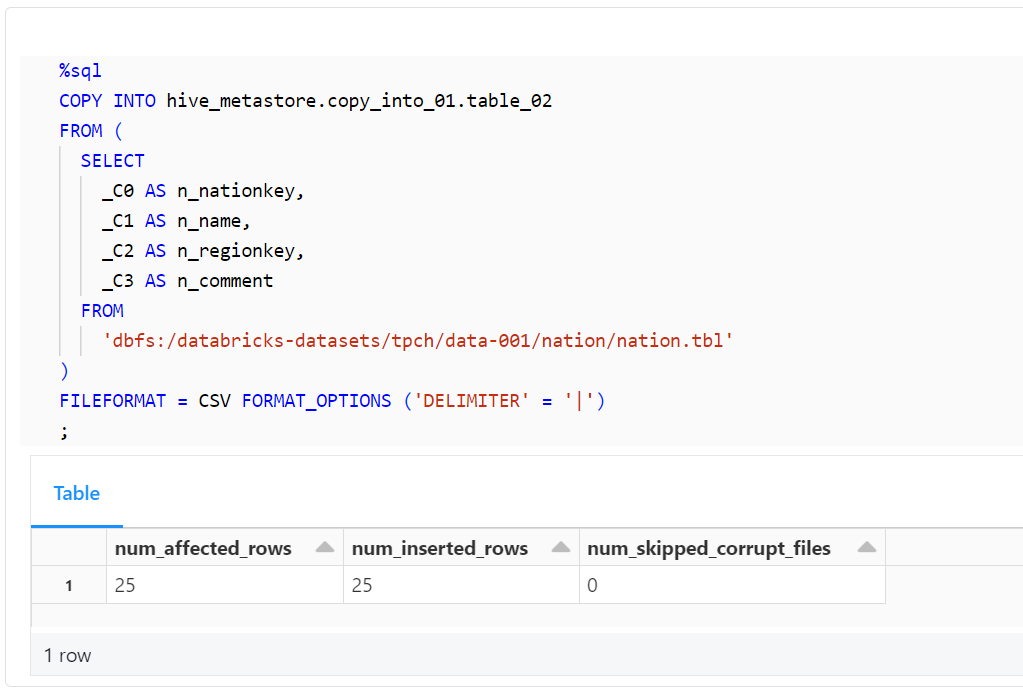
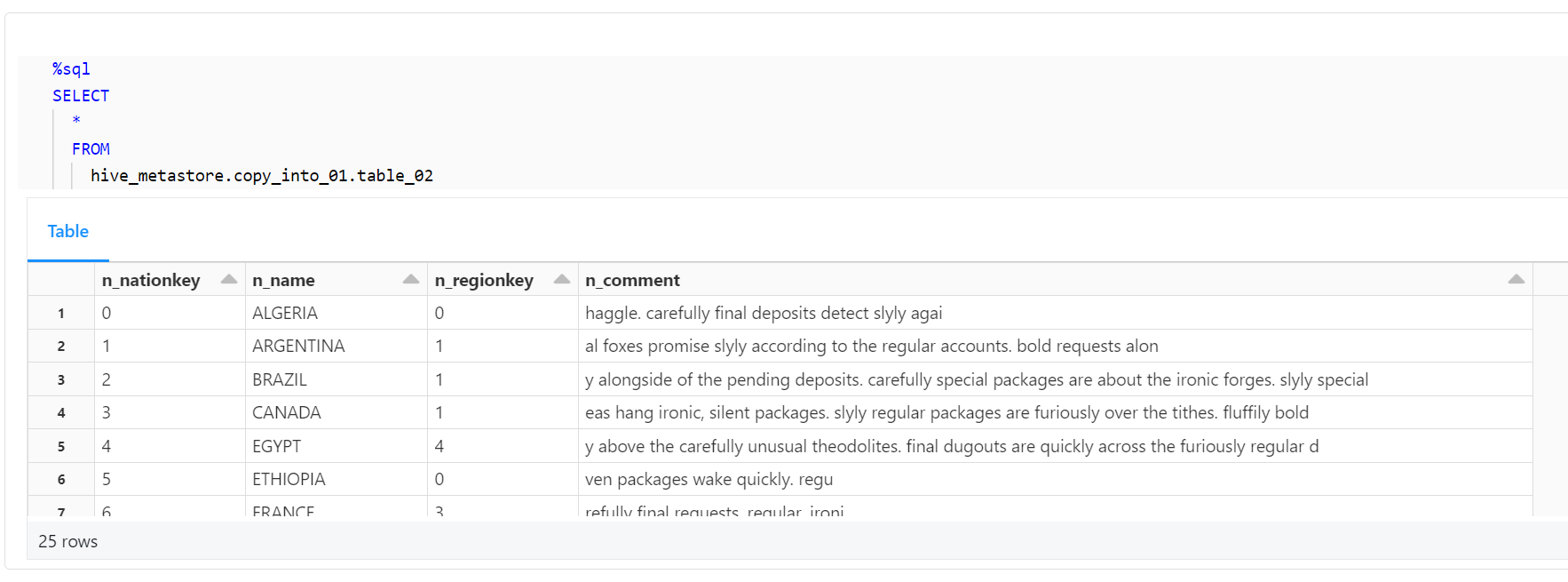
最後に、以下のコードを使用して、テーブルに正しくデータが取り込まれ、カラム名が正しく変更されたことを確認します。
%sql
SELECT
*
FROM
hive_metastore.copy_into_01.table_02
カラム名の変更とスキーマ展開を実施
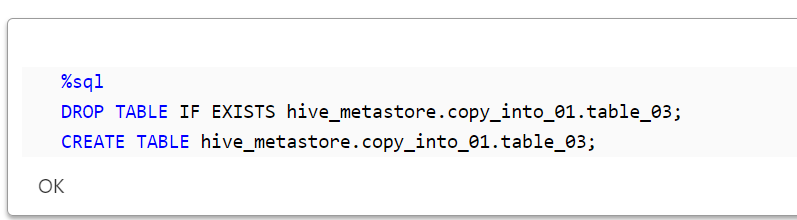
このセクションでは、カラム名の変更とスキーマ展開を行います。まず、新たなテーブルを作成します。
%sql
DROP TABLE IF EXISTS hive_metastore.copy_into_01.table_03;
CREATE TABLE hive_metastore.copy_into_01.table_03;
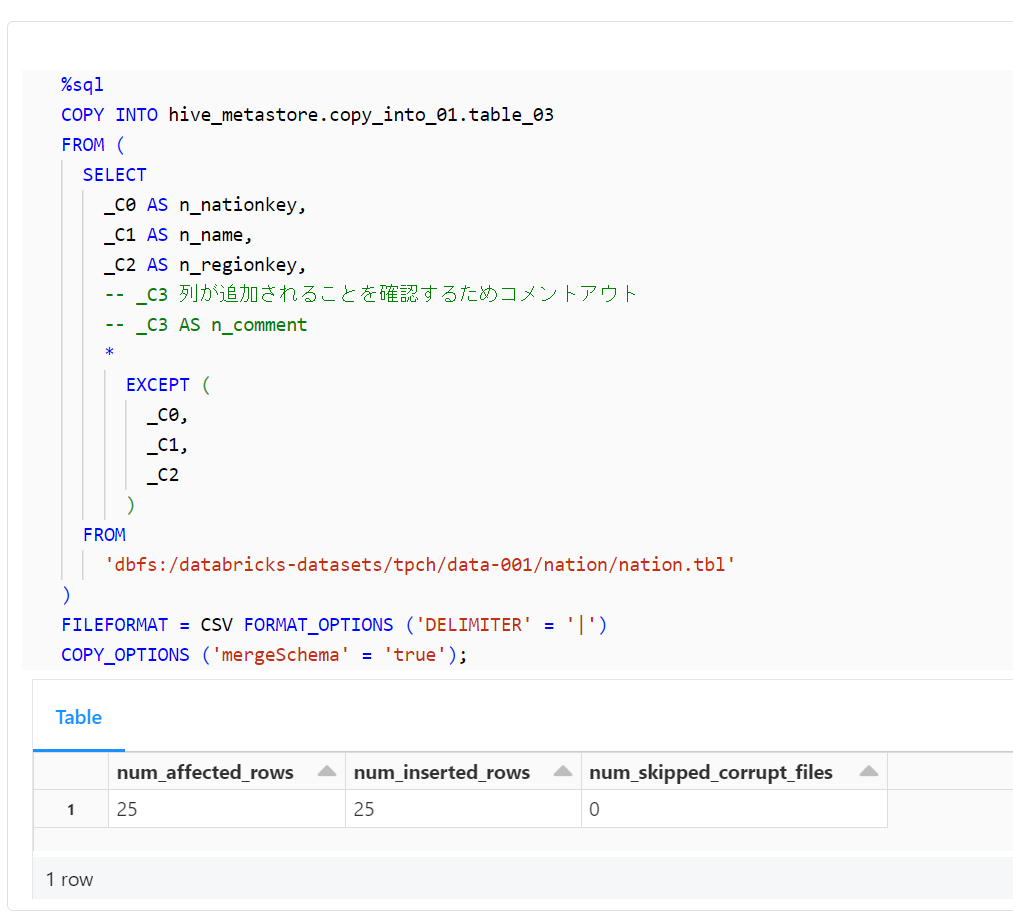
次に、COPY INTOコマンドを使用してデータを取り込みます。この際、元のファイルのカラム名を変更し、スキーマを展開します。
%sql
COPY INTO hive_metastore.copy_into_01.table_03
FROM (
SELECT
_C0 AS n_nationkey,
_C1 AS n_name,
_C2 AS n_regionkey,
-- _C3 列が追加されることを確認するためコメントアウト
-- _C3 AS n_comment
*
EXCEPT (
_C0,
_C1,
_C2
)
FROM
'dbfs:/databricks-datasets/tpch/data-001/nation/nation.tbl'
)
FILEFORMAT = CSV FORMAT_OPTIONS ('DELIMITER' = '|')
COPY_OPTIONS ('mergeSchema' = 'true');
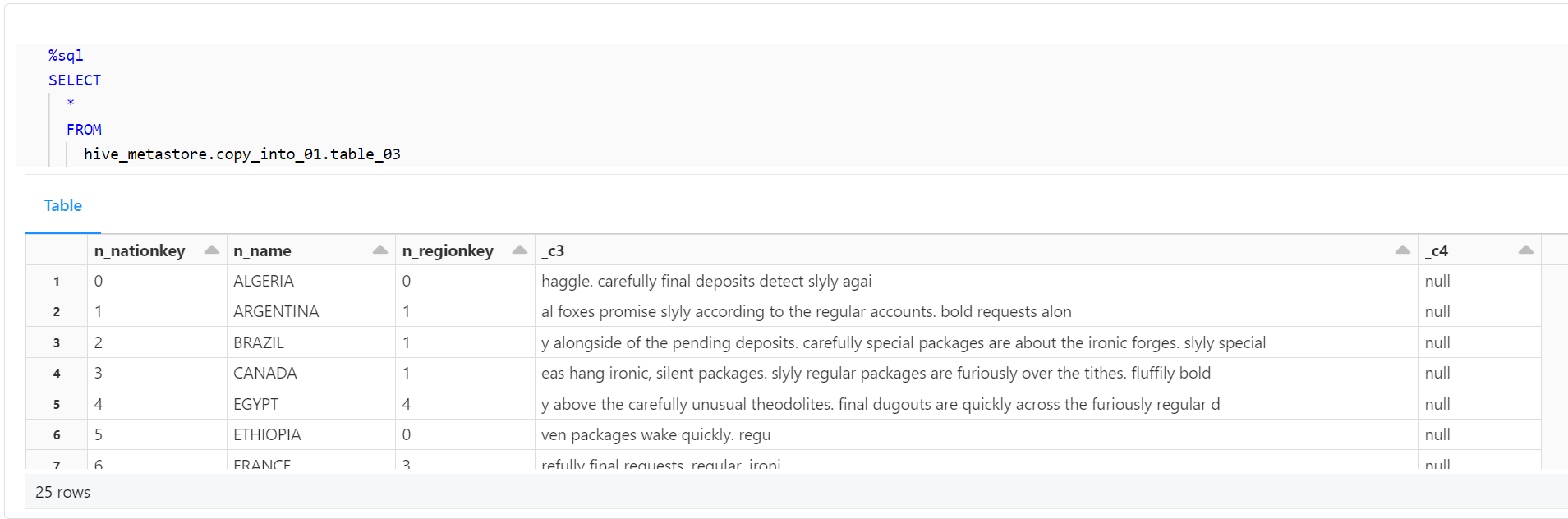
最後に、テーブルに正しくデータが取り込まれ、カラム名が正しく変更されたことを確認します。
%sql
SELECT
*
FROM
hive_metastore.copy_into_01.table_03
ファイルメタデータ列を追加
次に、ファイルメタデータ列を追加します。新たなテーブルを作成し、そのテーブルにデータを取り込む際に、ファイルメタデータ列を追加します。
%sql
DROP TABLE IF EXISTS hive_metastore.copy_into_01.table_04;
CREATE TABLE hive_metastore.copy_into_01.table_04;
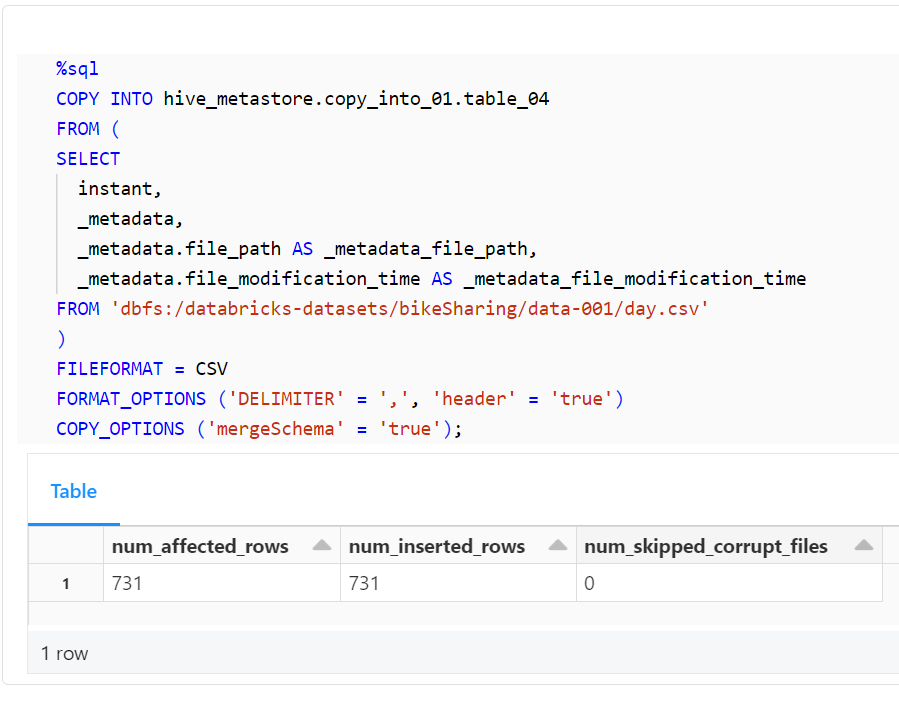
以下のコードは、COPY INTOコマンドを使用して、指定したファイルからデータを取り込みます。この例では、元のファイルのカラム名を変更し、スキーマを展開し、さらにファイルメタデータ列を追加してデータを取り込んでいます。
%sql
COPY INTO hive_metastore.copy_into_01.table_04
FROM (
SELECT
instant,
_metadata,
_metadata.file_path AS _metadata_file_path,
_metadata.file_modification_time AS _metadata_file_modification_time
FROM 'dbfs:/databricks-datasets/bikeSharing/data-001/day.csv'
)
FILEFORMAT = CSV
FORMAT_OPTIONS ('DELIMITER' = ',', 'header' = 'true')
COPY_OPTIONS ('mergeSchema' = 'true');
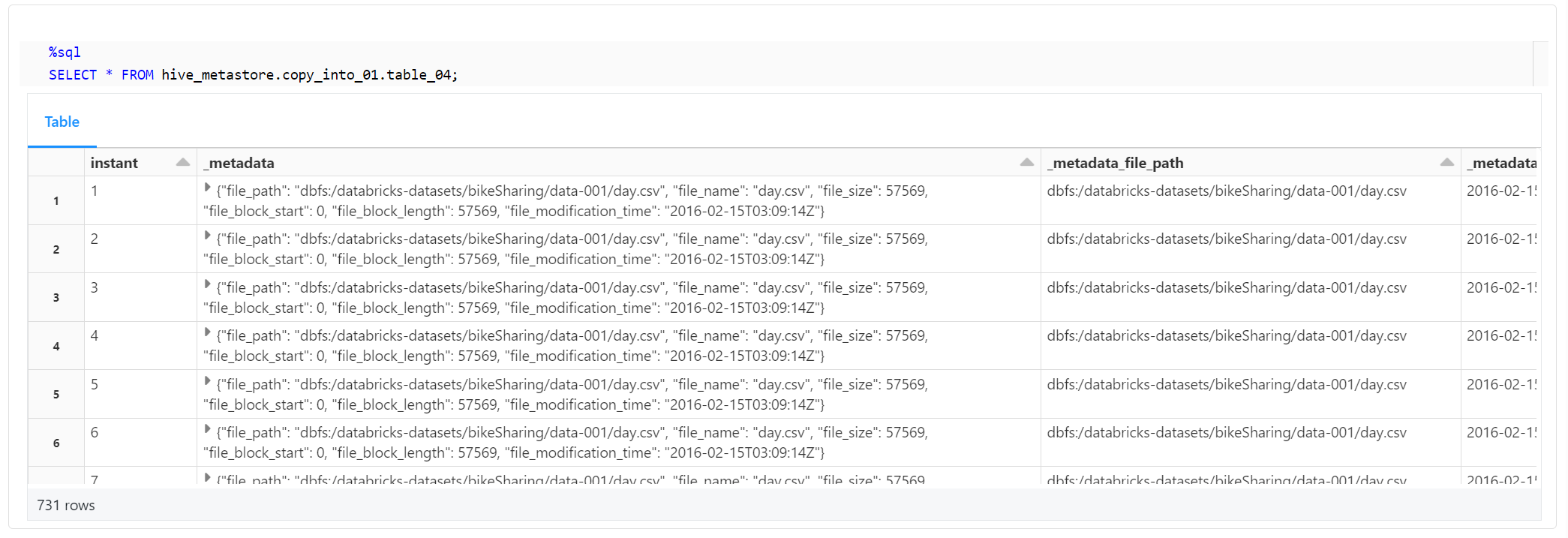
最後に、以下のコードを使用して、テーブルに正しくデータが取り込まれ、カラム名が正しく変更され、ファイルメタデータ列が正しく追加されたことを確認します。
%sql
SELECT * FROM hive_metastore.copy_into_01.table_04;
関数化
テーブルを作成
まず、新たなテーブルを作成します。
%sql
DROP TABLE IF EXISTS hive_metastore.copy_into_01.table_05;
CREATE TABLE hive_metastore.copy_into_01.table_05;
関数を定義
以下のコードは、COPY INTOコマンドを生成するための関数を定義します。この関数は、コピーの設定パラメータの辞書と監査カラムとその値のリストを引数に取り、COPY INTOコマンドを生成します。本関数は開発途中のものであるため、自己責任で利用してください。
import inspect
# 開発途中の関数であるため、バグがある可能性あり
def create_sql_for_copy_into(
copy_conf: dict,
additional_cols_and_values: list,
) -> str:
"""
ファイルからSparkテーブルにデータをコピーするためのSQLを作成します。
Args:
copy_conf (dict): コピーの設定パラメータの辞書。
additional_cols_and_values (list): 監査カラムとその値のリスト。
Returns:
str: ファイルからSparkテーブルにデータをコピーするためのSQL。
"""
tgt_tble_name = copy_conf["tgt_tbl_name"]
file_format = copy_conf["fileformat"]
path = copy_conf["path"]
# validate
validate_for_sql = ""
validate = copy_conf.get("validate", "")
if validate != "":
validate_for_sql = f"VALIDATE {validate}"
# files
files_for_sql = ""
files = copy_conf.get("files", "")
if files != "":
files_for_sql = f"files {files}"
# Format options
format_options = copy_conf["format_options"]
format_options_list = []
for option_key, option_value in format_options.items():
format_options_list.append(f"'{option_key}' = '{option_value}'")
format_options_for_sql = "\n ,".join(format_options_list)
# Copy Options
default_copy_otions = {
"mergeSchema": "true",
"force": "true",
}
copy_options = copy_conf.get("copy_options", default_copy_otions)
copy_options_list = []
for copy_option_key, copy_option_value in copy_options.items():
copy_options_list.append(f"'{copy_option_key}' = '{copy_option_value}'")
copy_options_for_sql = "\n ,".join(copy_options_list)
# Rename cols
col_info = {}
except_col_names = []
should_rename = copy_conf.get("should_rename", False)
renamed_cols = copy_conf.get("renamed_cols", {})
if should_rename:
if isinstance(renamed_cols, dict):
for bef_col_n, aft_col_n in renamed_cols.items():
except_col_names.append(bef_col_n)
col_info[aft_col_n] = bef_col_n
else:
raise Exception("`renamed_cols`は予期しないデータ型です。")
# Except renamed cols
cols_for_sql = "*"
if len(except_col_names) > 0:
cols_for_sql = ""
cols_for_sql += "*\n "
cols_for_sql += " EXCEPT (\n "
cols_for_sql += "\n ,".join([f"{exc_col}" for exc_col in except_col_names])
cols_for_sql += "\n )"
# With audit cols
should_with_audit_cols = copy_conf.get("should_with_audit_cols", True)
if should_with_audit_cols:
col_info = col_info | additional_cols_and_values
if col_info:
cols_for_sql += "\n ,"
cols_for_sql += "\n ,".join([f"{col_v} AS {col_n}" for col_n, col_v in col_info.items()])
sql = f"""
COPY INTO {tgt_tble_name}
FROM (
SELECT
{cols_for_sql}
FROM
'{path}'
)
FILEFORMAT = {file_format}
{validate_for_sql}
{files_for_sql}
FORMAT_OPTIONS (
{format_options_for_sql}
)
COPY_OPTIONS (
{copy_options_for_sql}
)
"""
sql = inspect.cleandoc(sql)
return sql

以下のコードは、上で定義した関数を使用して、COPY INTOコマンドを生成します。
copy_conf = {
"tgt_tbl_name": "hive_metastore.copy_into_01.table_05",
"fileformat": "csv",
"path": "dbfs:/databricks-datasets/bikeSharing/data-001/day.csv",
"validate": "",
"files": "",
"format_options": {"delimiter": ",", "header": "true"},
"copy_options": {"mergeSchema": "true"},
"should_rename": True,
# リネームのサンプルとして下記を実施
"renamed_cols": {
"casual": "casual",
"registered": "registered",
"cnt": "cnt",
},
"should_with_audit_cols": True,
}
additional_cols_and_values = {
"metadata_file_path": "_metadata.file_path",
"metadata_file_modification_time": "_metadata.file_modification_time",
}
sql = create_sql_for_copy_into(copy_conf, additional_cols_and_values)
print(sql)
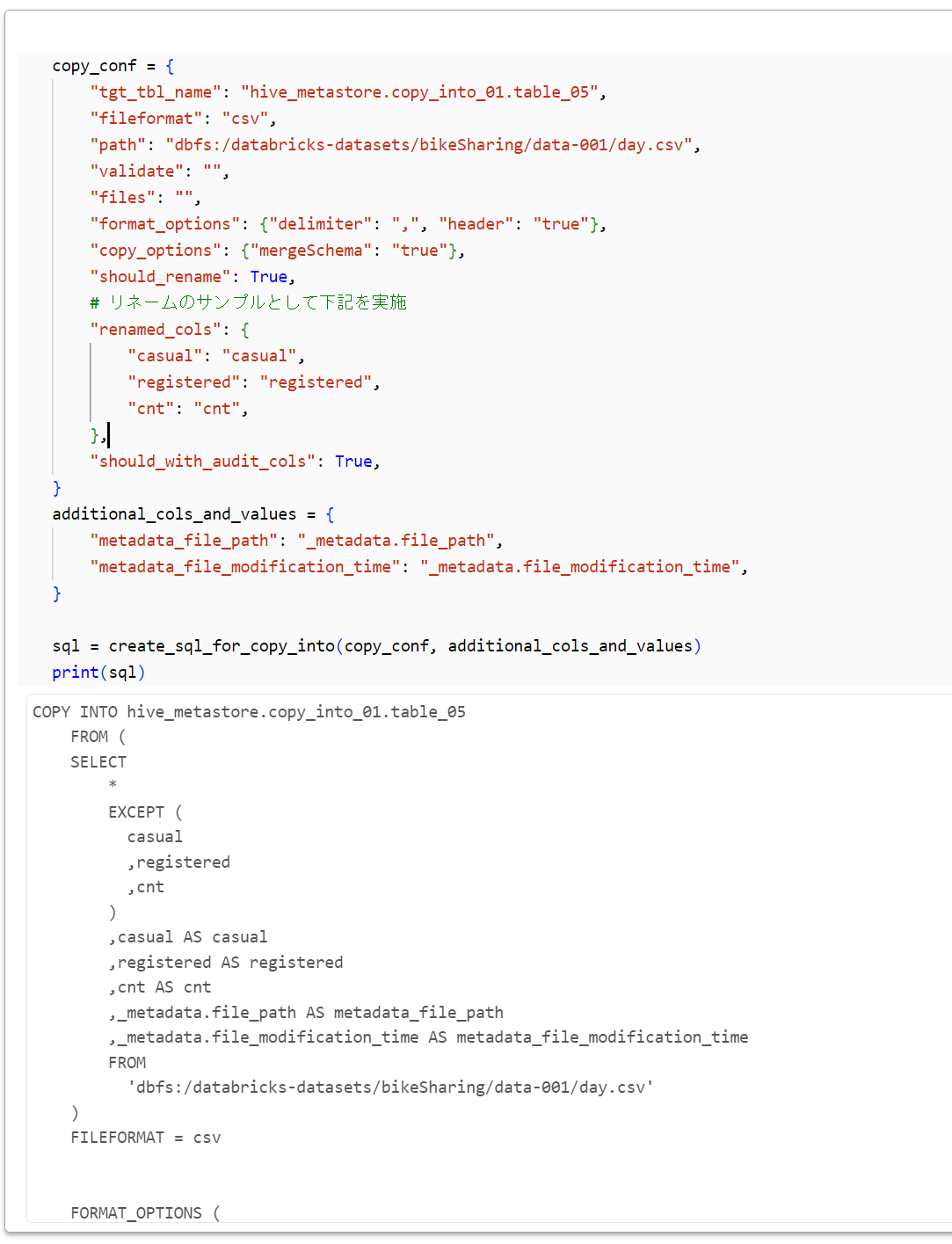
下記が出力されます。
COPY INTO hive_metastore.copy_into_01.table_05
FROM (
SELECT
*
EXCEPT (
casual
,registered
,cnt
)
,casual AS casual
,registered AS registered
,cnt AS cnt
,_metadata.file_path AS metadata_file_path
,_metadata.file_modification_time AS metadata_file_modification_time
FROM
'dbfs:/databricks-datasets/bikeSharing/data-001/day.csv'
)
FILEFORMAT = csv
FORMAT_OPTIONS (
'delimiter' = ','
,'header' = 'true'
)
COPY_OPTIONS (
'mergeSchema' = 'true'
)
生成した SQL の実行と結果確認
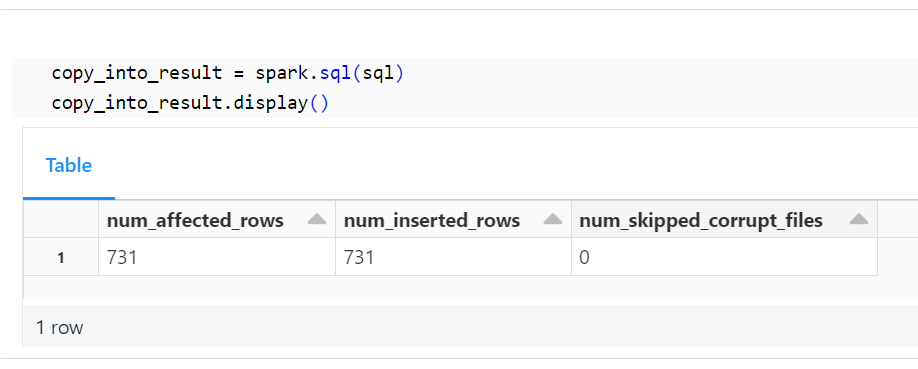
以下のコードを使用して、テーブルに正しくデータが取り込まれたことを確認します。
copy_into_result = spark.sql(sql)
copy_into_result.display()
最後に、以下のコードを使用して、テーブルに正しくデータが取り込まれたことを確認します。
%sql
SELECT * FROM hive_metastore.copy_into_01.table_05;
リソースの削除
以下のコードを使用して、作成したリソースを削除します。
%sql
DROP SCHEMA hive_metastore.copy_into_01 CASCADE;