概要
Databrick(Spark)にて、TPC-H、および、TPC-DSのデータを生成する方法を共有します。
DatabircksがGithub上で公開しているコードを利用するため、TPCにて公開されているコードより古いバージョンを利用する手順となっております。
詳細は下記のGithub pagesのページをご確認ください。
コードを実行したい方は、下記のdbcファイルを取り込んでください。
https://github.com/manabian-/databricks_tecks_for_qiita/blob/main/tecks/generate_data_tpch_and_tpcds/generate_data_tpch_and_tpcds.dbc
TPC-Hのデータを生成する手順
1. スケールファクター等の変数をセット
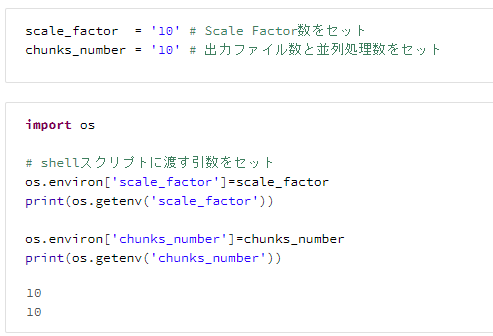
scale_factor = '10' # Scale Factor数をセット
chunks_number = '10' # 出力ファイル数と並列処理数をセット
import os
# shellスクリプトに渡す引数をセット
os.environ['scale_factor']=scale_factor
print(os.getenv('scale_factor'))
os.environ['chunks_number']=chunks_number
print(os.getenv('chunks_number'))
2. TPC-Hのセットアップとデータの生成
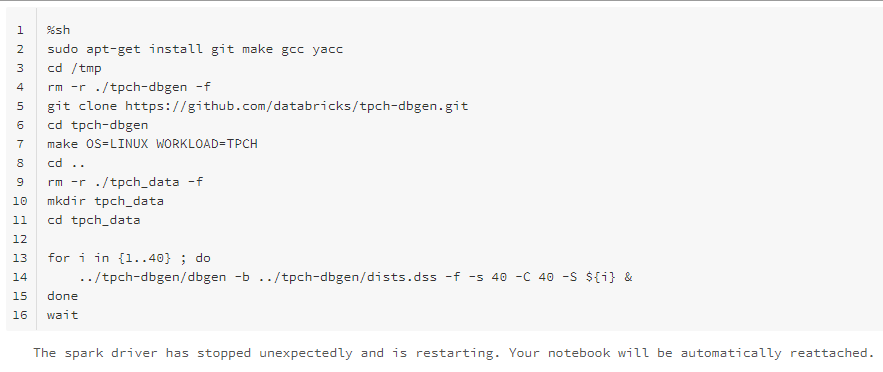
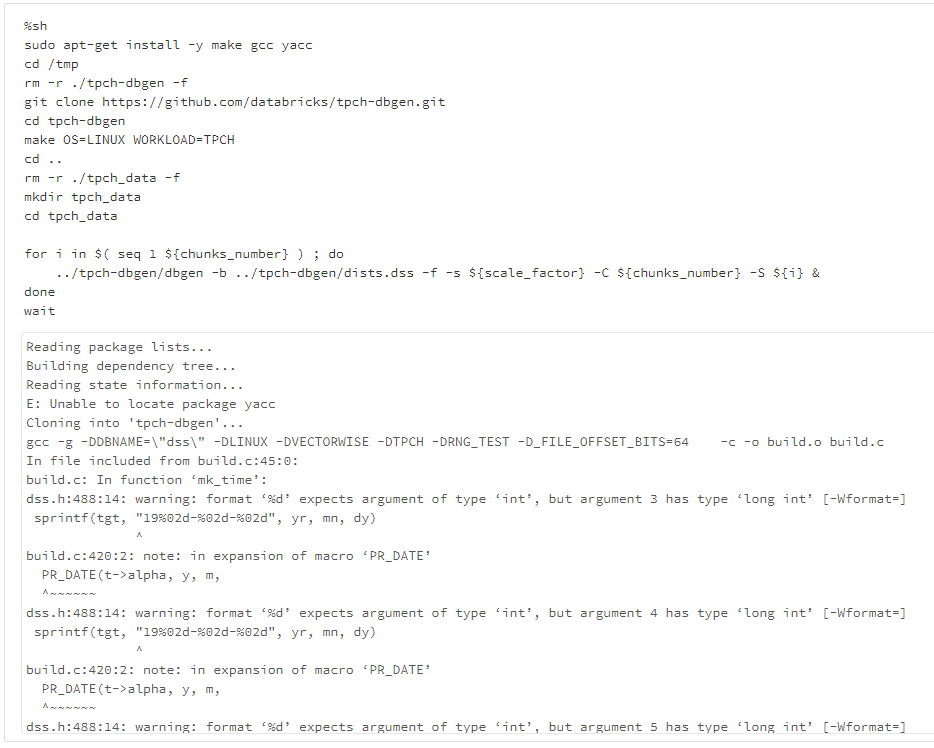
%sh
sudo apt-get install -y make gcc yacc
cd /tmp
rm -r ./tpch-dbgen -f
git clone https://github.com/databricks/tpch-dbgen.git
cd tpch-dbgen
make OS=LINUX WORKLOAD=TPCH
cd ..
rm -r ./tpch_data -f
mkdir tpch_data
cd tpch_data
for i in $( seq 1 ${chunks_number} ) ; do
../tpch-dbgen/dbgen -b ../tpch-dbgen/dists.dss -f -s ${scale_factor} -C ${chunks_number} -S ${i} &
done
wait
3. 生成したデータを確認
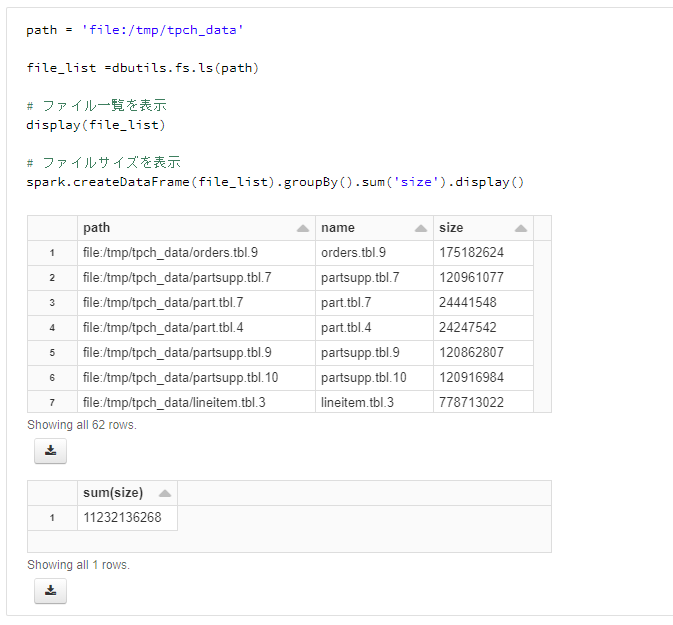
path = 'file:/tmp/tpch_data'
file_list =dbutils.fs.ls(path)
# ファイル一覧を表示
display(file_list)
# ファイルサイズを表示
spark.createDataFrame(file_list).groupBy().sum('size').display()
TPC-DSのデータを生成する手順
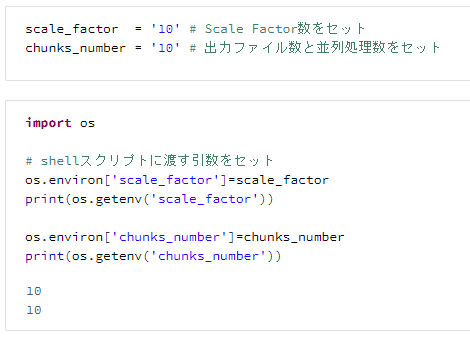
1. スケールファクター等の変数をセット
scale_factor = '10' # Scale Factor数をセット
chunks_number = '10' # 出力ファイル数と並列処理数をセット
import os
# shellスクリプトに渡す引数をセット
os.environ['scale_factor']=scale_factor
print(os.getenv('scale_factor'))
os.environ['chunks_number']=chunks_number
print(os.getenv('chunks_number'))
2. TPC-DSのセットアップとデータの生成
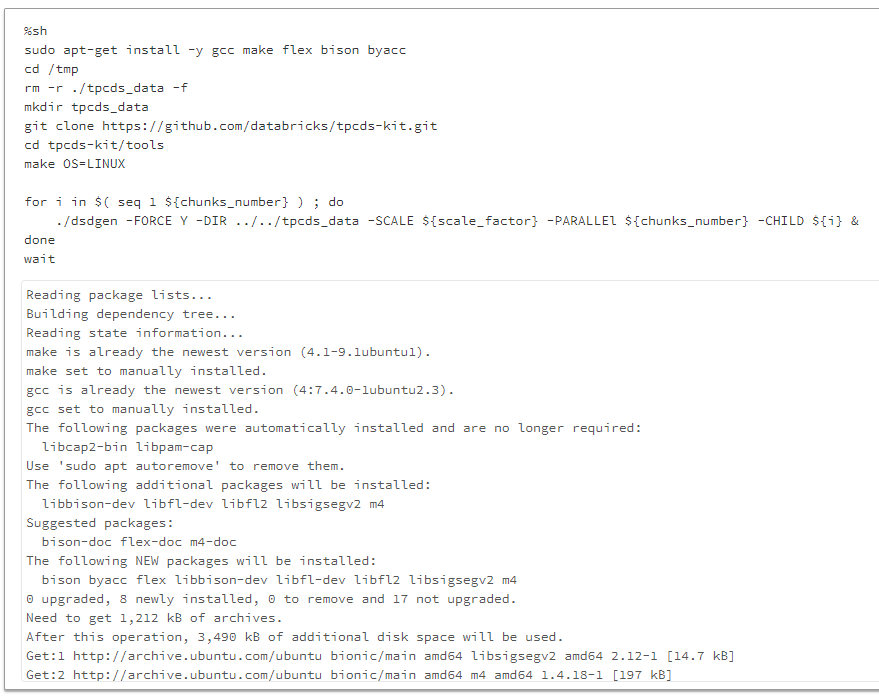
%sh
sudo apt-get install -y gcc make flex bison byacc
cd /tmp
rm -r ./tpcds_data -f
mkdir tpcds_data
git clone https://github.com/databricks/tpcds-kit.git
cd tpcds-kit/tools
make OS=LINUX
for i in $( seq 1 ${chunks_number} ) ; do
./dsdgen -FORCE Y -DIR ../../tpcds_data -SCALE ${scale_factor} -PARALLEl ${chunks_number} -CHILD ${i} &
done
wait
3. 生成したデータを確認
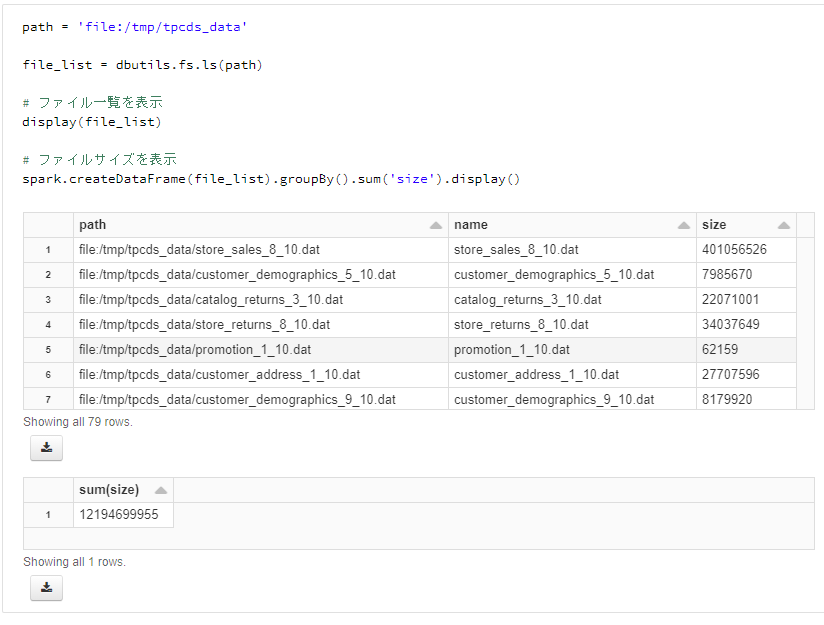
path = 'file:/tmp/tpcds_data'
file_list = dbutils.fs.ls(path)
# ファイル一覧を表示
display(file_list)
# ファイルサイズを表示
spark.createDataFrame(file_list).groupBy().sum('size').display()
注意事項
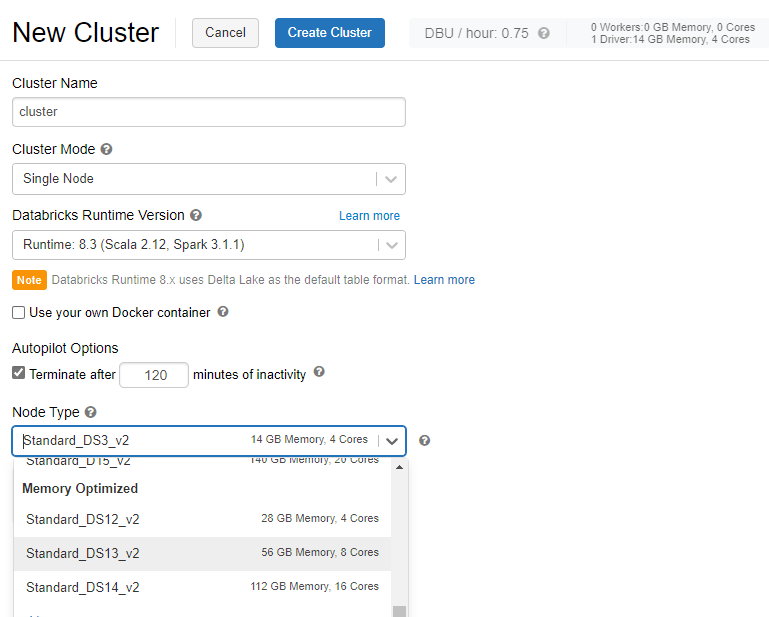
注意事項1 クラスターを構築する際には、Cluster Modeをsingle Nodeに、Node TypeをMomory OptimizedのVMに設定することがおすすめ
注意事項2 メモリのSwapやCPU負荷が高い場合には処理がエラーとなる場合があるため、VMサイズアップが要検討
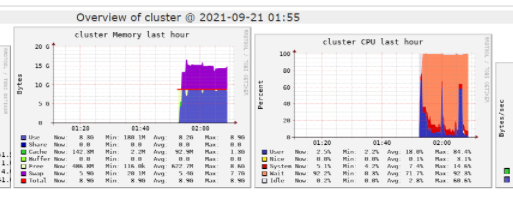
下記のようなエラーが発生します。
The spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.